This is the sharing session for my team, the goal is to quick ramp up the essential knowledges for linear regression case to experience how machine learning works during 1 hour. This sharing will recap basic important concepts, introduce runtime environments, and go through the codes on Notebooks of Azure Machine Learning Studio platform.
Do not worry about these theories if you can’t catch up, just take it as an intro.
Let’s start with the simplest linear model , you can also try more complex model if you get trouble in underfitting.
Question: How to initialize parameters?
The model’s ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model.

Solutions: References and resources, or Underfitting and Overfitting in machine learning and how to deal with it.
There is a dataset for training, it looks like: , , …, . The error of should be , we can add all errors of data to define our loss function:
Obviously the smaller loss, the better model. So our target function should be:
Average value would be better than total sum, then we get the actual function that needs to be computed:
Not big deal, just minimize the mean square error of our trivial linear model.
You may have heard “feature” before, for each of data , if the number of its features is , then the actual model should be:
Kind of verbose right? Let’s use to represent all feature weights to as well as the bias term , which called before. Same way, use to represent all the feature values to with is equal to 1. Then we can transform linear regression model to the vectorized form:
Thus our loss function of vectorized form is:
Notice that actually is -dimensional matrix.
In addition, deep learning depends on matrix calculations especially, it will take advantage of GPU to speed up model training.
As we already know the values of and , it’s easy to calculate the by Normal Equation:
Check out this online course video (about 16min) from Andrew Ng to learn more.
Yes we’re done. Our introduction is here 🤣🤣🤣 .
Question: How to deal with complex models? How about computation burden?
Gradient Descent is a generic optimization algorithm capable of finding optimal solution to a wide range of problems.
Gradient descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function.
Our loss function is differentiable indeed, so we can use it to find the local minimum (also the global minimum in this case). Let’s get it by one chart.
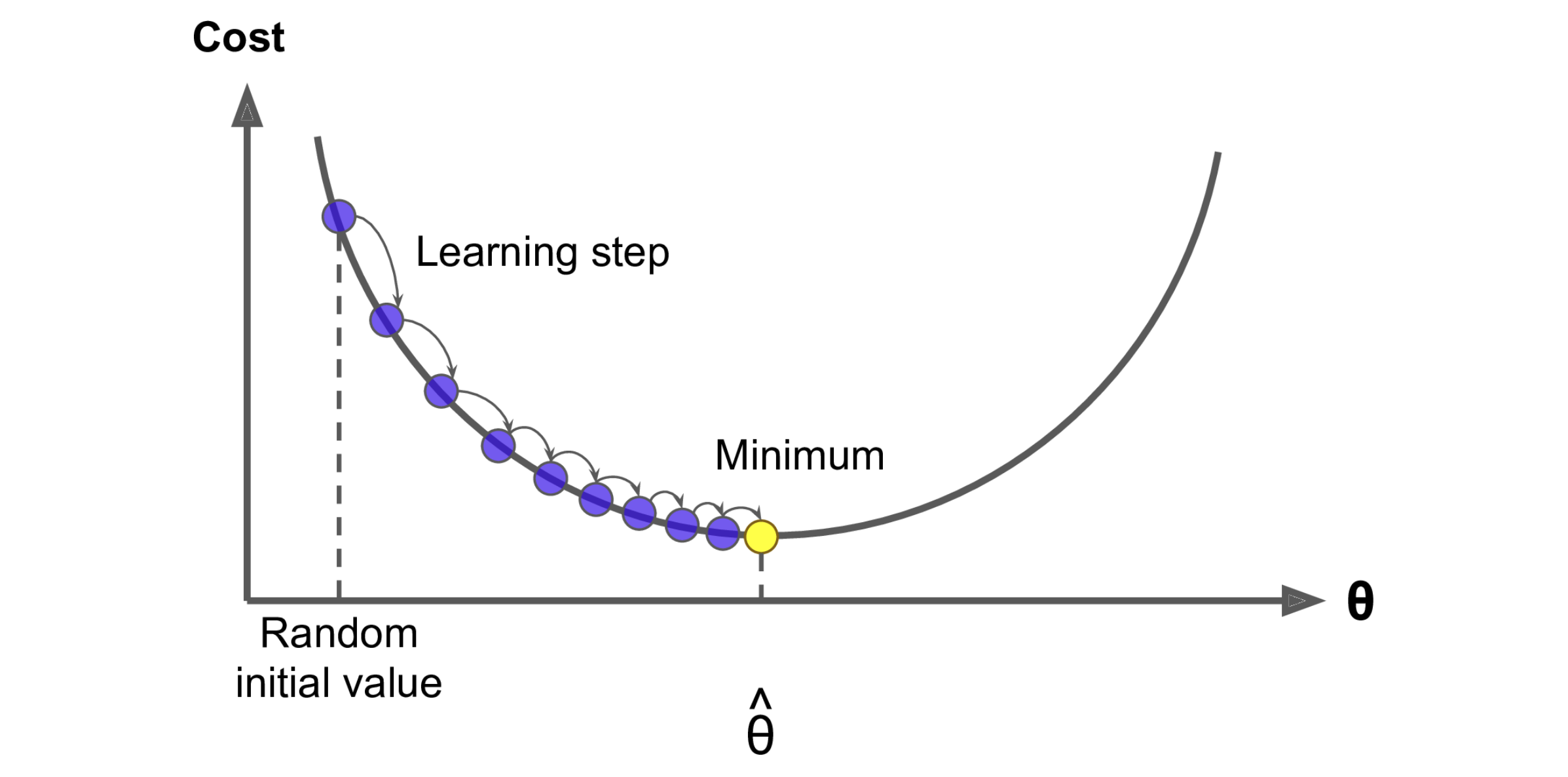
So here is the last equation in this post (I promise, typing these LaTeX expressions really wore me out 🥲 ), the gradient of our loss function:
Question: disadvantages of gradient descent?
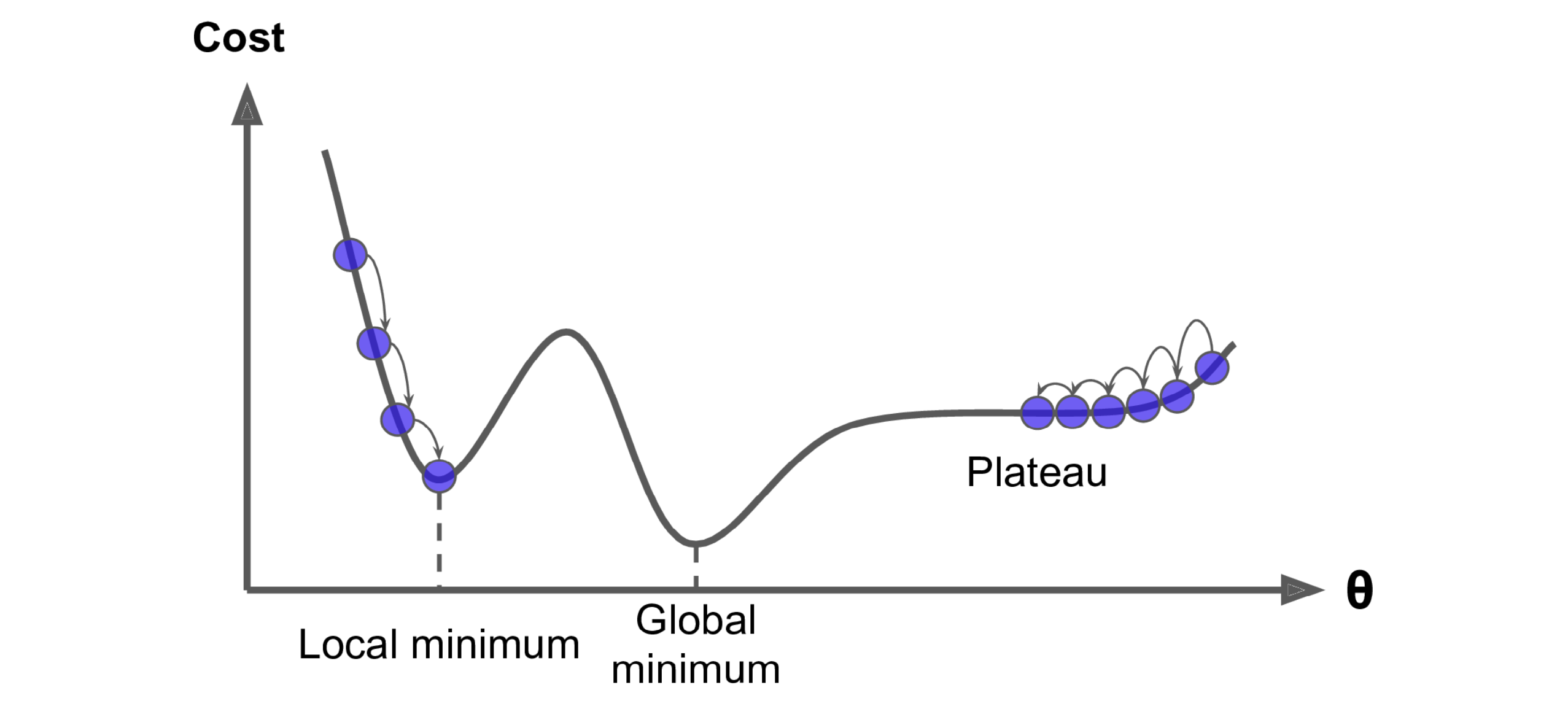
Probably it’s enough for us to dig into the code, so the recap should be stopped here. At last, giving this tips section for some practical training techniques.
I highly recommend using Conda to run your Python code even on Unix-like OS, and Miniconda is good to get start.
Conda as a package manager helps you find and install packages. If you need a package that requires a different version of Python, you do not need to switch to a different environment manager, because conda is also an environment manager. With just a few commands, you can set up a totally separate environment to run that different version of Python, while continuing to run your usual version of Python in your normal environment.
It’s cloud computing era, we can write and save our code on the cloud and run it at anytime with any web client. Two cloud platforms will be introduced here, I suggest you try both of them and enjoy your experiment.
More specifically, these two products are all based on Jupyter Notebook, which provides flexible Python runtime and Markdown document feature, it’s easy to run code snippet just like on the local terminal.
Here is a brief introduction of Notebooks of AML Studio, the advantages of this product are:
You can open ipynb file on Google Drive by this product, there are also several advantages:
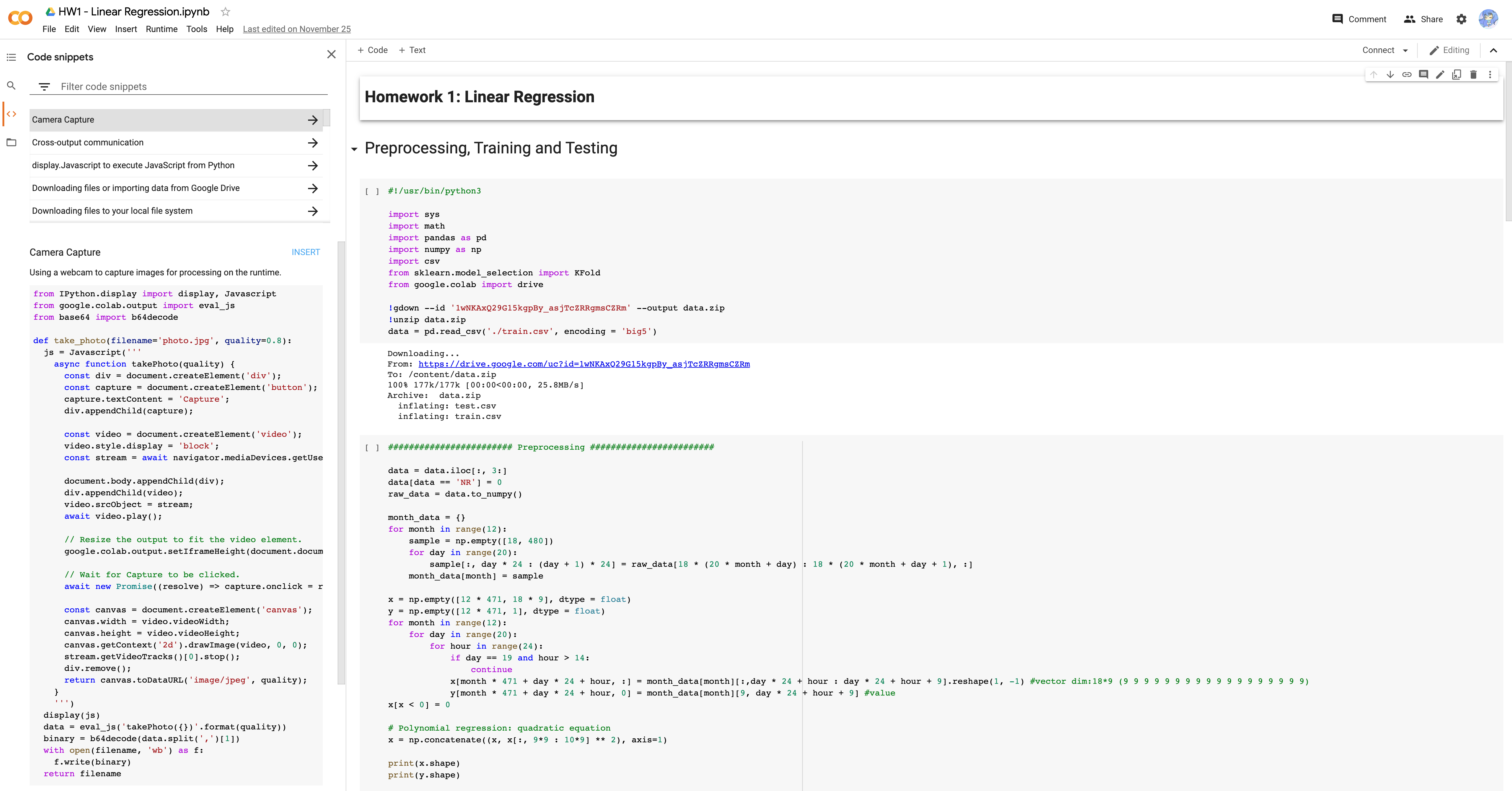
You can check sample code on Google Colab here, and codes below will has slight differences.
To predict the PM2.5 value of first ten hour by other nine hours data.
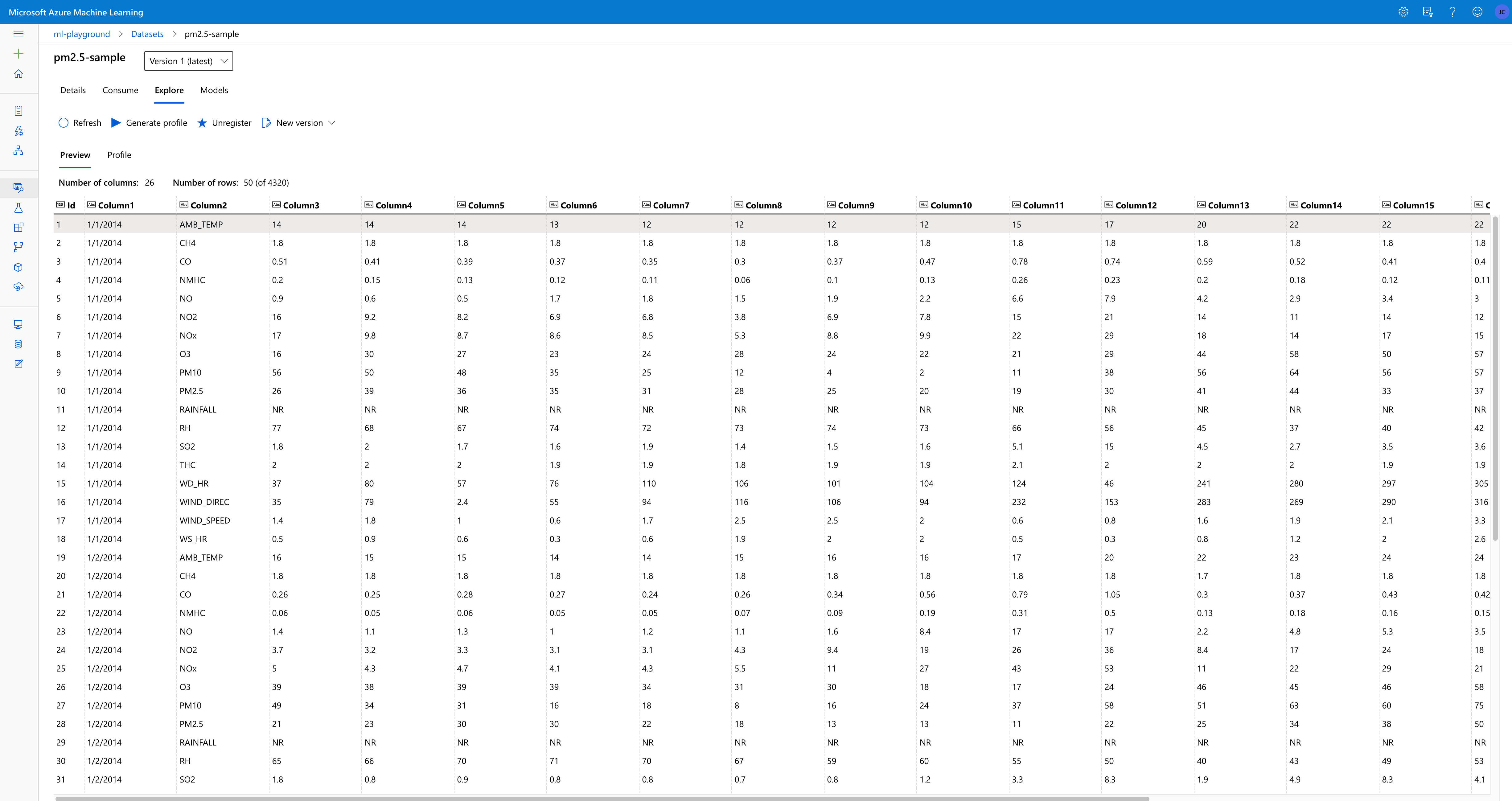
Original data structure looks like this:
| 00:00 | 01:00 | … | 23:00 | |
|---|---|---|---|---|
| Feature 1 of day 1 | ||||
| Feature 2 of day 1 | ||||
| … | ||||
| Feature 17 of day 1 | ||||
| Feature 18 of day 1 | ||||
| Feature 1 of day 2 | ||||
| Feature 2 of day 2 | ||||
| … |
24 columns represent 24 hours, 18 features with every first 20 days of month in one year, we have rows.
Our target data structure of will be:
| Feature 1 of 1st hour | Feature 1 of 2nd hour | … | Feature 1 of 9th hour | Feature 2 of 1st hour | … | Feature 18 of 9th hour | |
|---|---|---|---|---|---|---|---|
| 10th hour of day 1 | |||||||
| 11st hour of day 1 | |||||||
| … | |||||||
| 24th hour of day 1 | |||||||
| 1st hour of day 2 | |||||||
| … |
Number of columns should be , and rows should be .
You may wonder why variable is capital and variable is lower-case, just Google matrix notation.
1 |
|
1 |
|
1 |
|
1 |
|
1 | X_train_set = X[: math.floor(len(x) * 0.8), :] |
1 |
|
1 | eval_loss(X_validation, y_validation, w) |
1 | w = train(X = X_pruned, y = y, w = w) |
Compare the Steps of machine learning section with each code snippets below and rethink the whole flow, you may have an overview about machine learning now 👍 .
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。