我把 775 篇收藏的文章塞进一个 4MB 的向量库,然后问它:"我都收藏过哪些关于 loop engineering 的资料?"三秒钟,它把散在六七篇文章里的观点拼成一段答案,每条都带出处。

这不是什么 SaaS 产品,是我自己写的一个 skill,叫 chao-rag-wiki。今天聊聊它,顺便聊聊它背后那个问题:知识库越攒越大,你到底怎么"读"它?
得先从 Karpathy 的一个想法说起。
起点是 Andrej Karpathy 抛出的一句话:
"The LLM writes and maintains the wiki; the human reads and asks questions."
(LLM 负责写和维护 wiki,人类负责读和提问。)
有人把这句话做成了一个 skill —— karpathy-llm-wiki。玩法是这样:
你有两个目录。raw/ 放原始素材,只读、永不修改——收藏的推文、文章、论文都丢这里。wiki/ 放编译后的知识文章,AI 全权打理。
每往 raw/ 加一篇新素材,AI 就把它"编译"进 wiki:判断这篇属于哪个已有主题,跟某篇是同一个核心论点就合并进去、更新段落,全新概念就新建一篇,顺便检查跟已有内容有没有冲突、有就标出来。最后维护一个 wiki/index.md 全局索引,每篇一行——链接、摘要、更新日期。
你查询的时候("我知道哪些关于 X 的东西?"),AI 先读 index.md 定位到相关文章,打开那几篇,再综合作答。
这个设计很优雅,本质是用 AI 把碎片素材沉淀成结构化的知识资产,而且会随时间复利增长。读起来像一本你自己的、不断长大的百科全书。
但它有个隐含前提:素材得先被"编译"进 wiki,才搜得到。下面这个 skill,想绕开的就是这件事。
我借了 karpathy-llm-wiki 的"raw/ 只读"哲学,但把后半段换成了 RAG(检索增强生成)。
一句话说清区别:karpathy-llm-wiki 是先把书写好再去翻书;chao-rag-wiki 是书原样不动,但给每一页都建了语义索引,随问随搜。

技术栈是这么几块拼的:
1. 向量检索用 turbovec。 Google Research 的 TurboQuant 算法的 Rust 实现,能把向量压 16 倍还几乎不掉精度——上一篇我专门拆过。我的 775 篇切成 9089 个 chunk(去重后),整个索引才 4.8MB,常驻内存毫无压力。
2. 嵌入默认使用千帆的 bge-large-zh(1024 维),但接口跟 provider 无关。 想换 OpenAI、Voyage 或本地模型都行,只改环境变量,不动代码。key 全走环境变量,绝不硬编码。
3. 混合检索(Hybrid RAG),这是关键。 同时跑两路:稠密向量检索管语义,知道"自我迭代"和"循环"是一回事;BM25 关键词检索管字面,能精确命中 rotate_writer.go 这种代码标识符、人名、专有词。两路结果用 RRF(Reciprocal Rank Fusion,倒数排名融合)合并。语义检索擅长"意思对但用词不同",关键词检索擅长"就要这个词",融合之后两头都不漏。
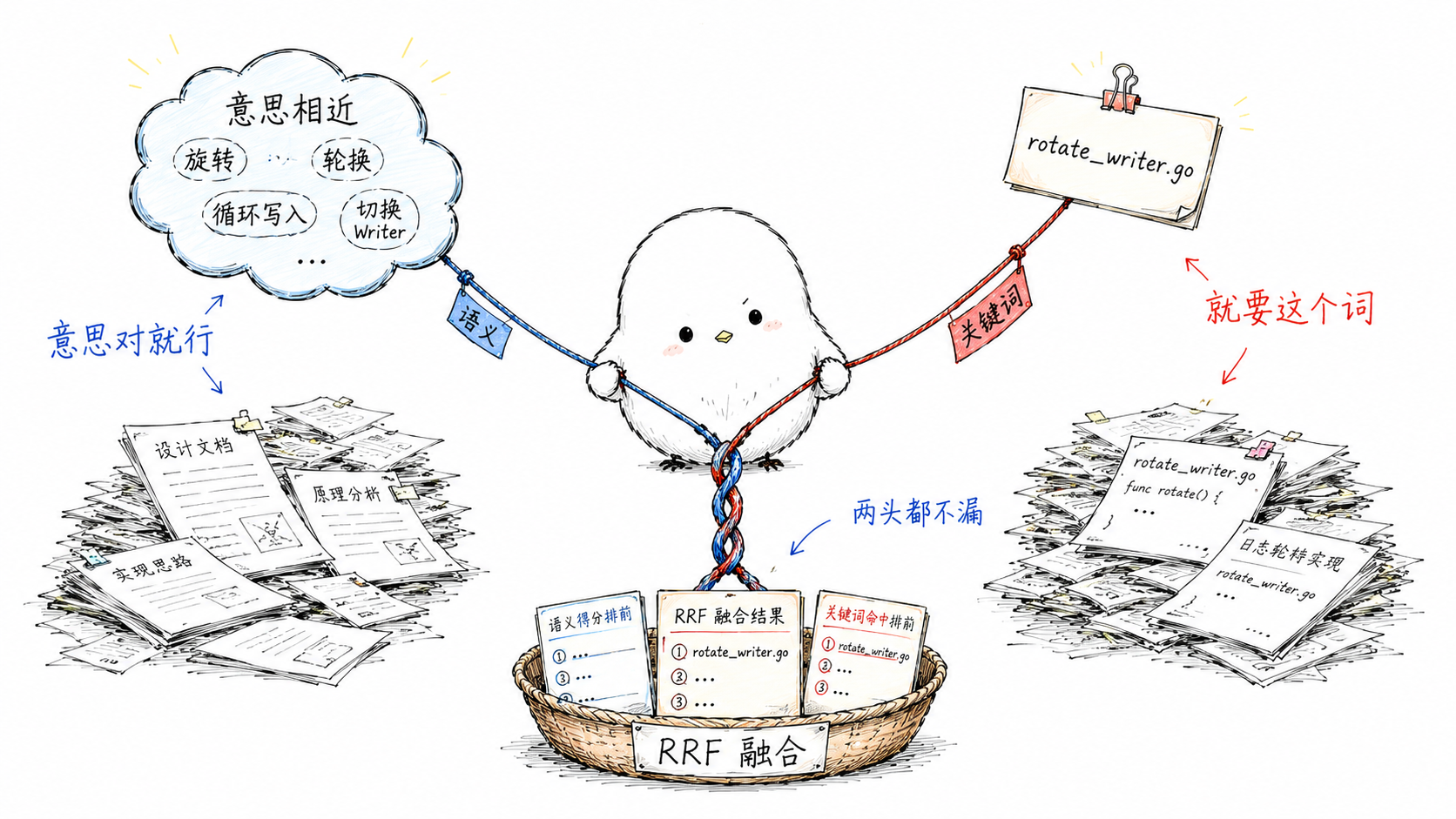
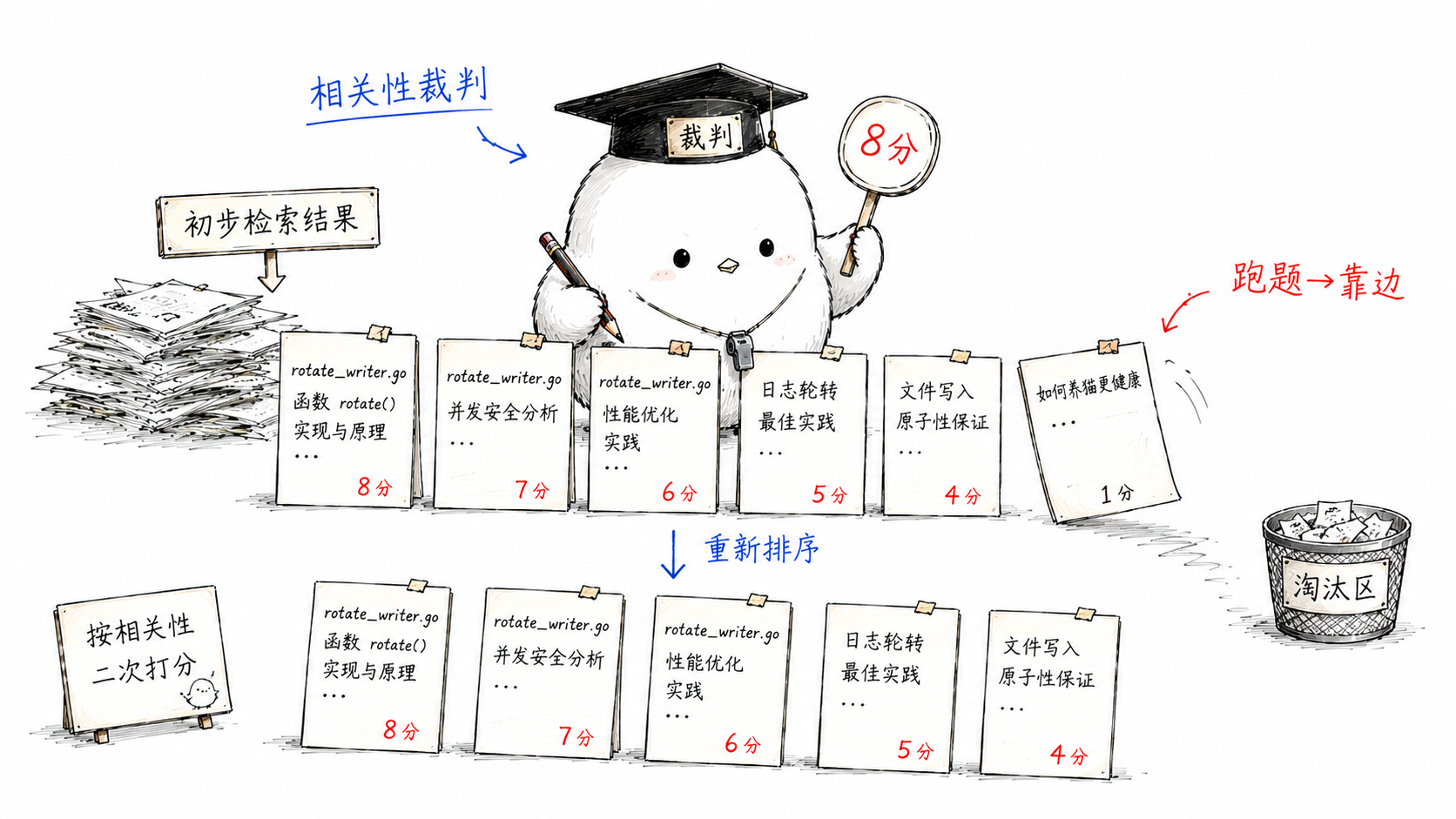
4. 可选的 LLM 重排(rerank)。 检索快但粗,再拉一个 LLM 当"相关性裁判"给候选打分重排,精度优先时加 --rerank 就行。
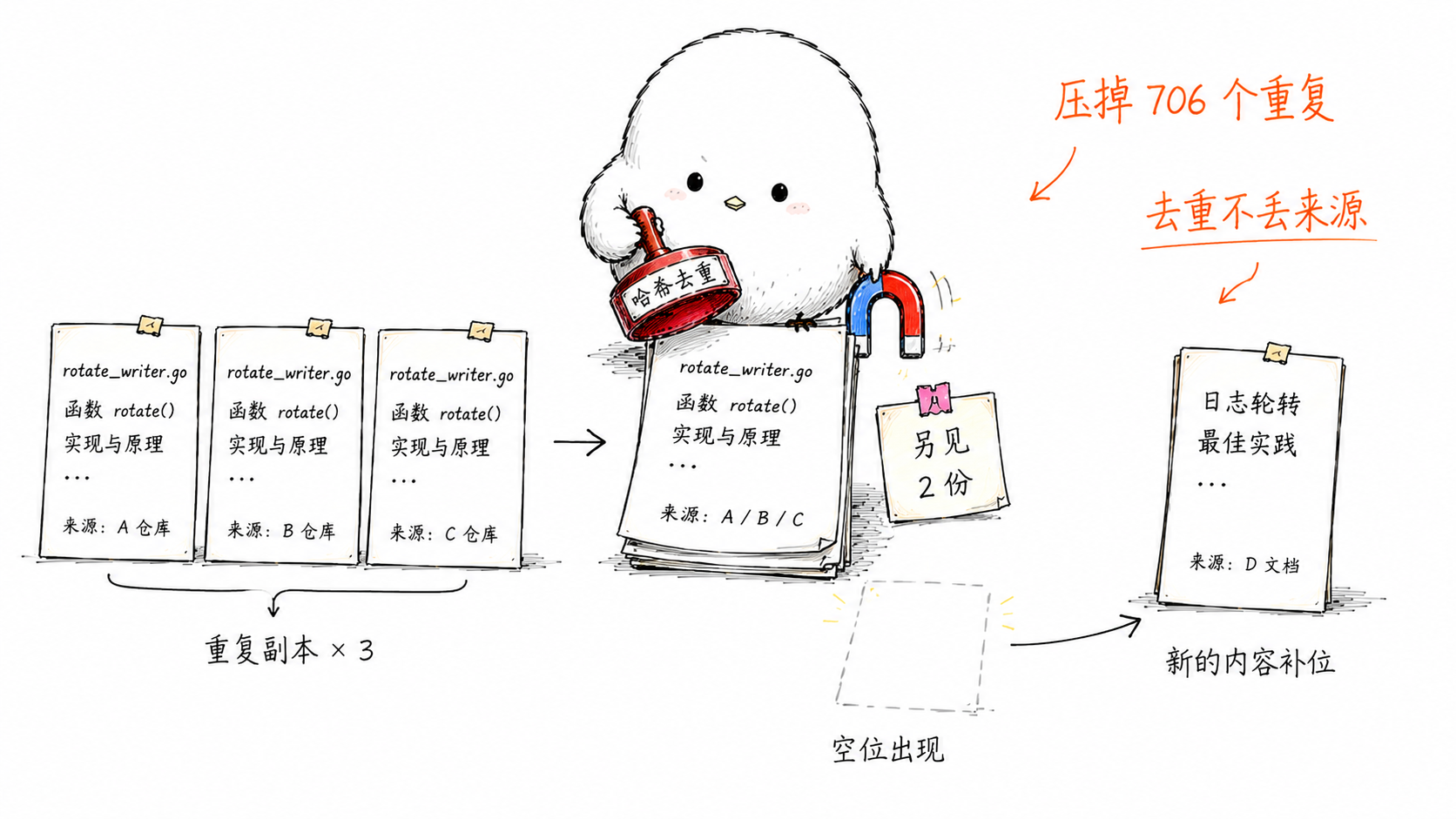
5. 建索引时按 chunk 文本哈希去重。 raw/ 里同一段内容存了多份副本的话,只留一份进库,免得副本在结果里挤名额——我这 775 篇就压掉了 706 个重复 chunk。
先说好的:
零编译延迟。新素材丢进 raw/,跑一句增量索引就搜得到,不用 AI 逐篇消化。而且增量索引按内容哈希只处理新增和改动的文件,没变化就几秒退出。
召回更全。它检索的是原始全文的每个片段。哪怕某个话题你压根没想过给它单独建篇文章,只要素材里提过,就搜得到。
混合检索加重排加去重,对中英混排、专有名词、长尾问题都更稳。同一段内容在 raw/ 里有多份副本,建索引时按 chunk 文本哈希自动合并,结果不会被副本占名额——但保留"另见 N 份副本"的来源信息,去重不丢信息。
再说差的,这些恰好是 karpathy-llm-wiki 的强项:
它没有知识沉淀,给你的是原文片段拼盘,不是一篇消化过、把内部矛盾理顺了的文章。karpathy-llm-wiki 那边的 wiki 文章是真正的二次创作,读起来成体系。
它只能精确去重。逐字相同的副本能干净合并,但"同一篇、有细微编辑差异"的近似重复就认不出来了——那得上 MinHash 或 SimHash,复杂得多。
它依赖在线 embedding,查询要联网(或者本地部署的大模型)、有 API 成本(BM25 那一路不用)。
说白了,karpathy-llm-wiki 重"沉淀",chao-rag-wiki 重"召回"。前者像精心整理的笔记本,后者像一个全文搜索引擎。
光说不练假把式。同样两个问题,两个 skill 各跑一遍。
自从 Karpathy的llm-wiki理念提出来之后,我收集资料的时候特意使用Obsidian web clipper进行收集,最近几个月也收集了700多篇资料,也在Hermes中建立了llm-wiki,这次我使用chao-rag-wiki 建立了RAG索引,让我们比较一下这两个skill搜索资料的效果。
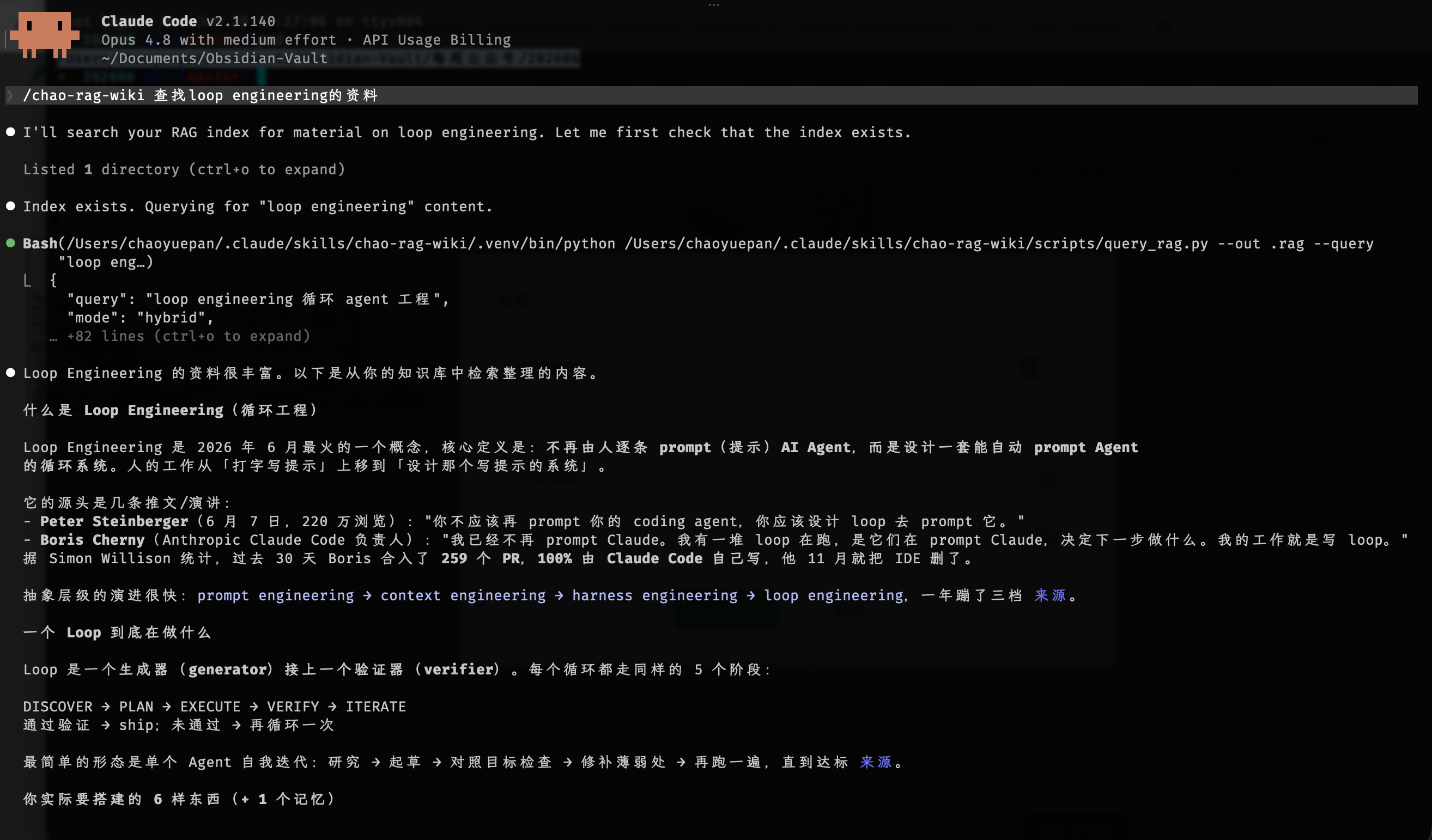
chao-rag-wiki(hybrid + rerank)召回了散在多篇原文里的片段:
1 | [1] rerank=8.0 PART 2: WHAT LOOP ENGINEERING ACTUALLY IS |
它直接定位到讲 loop engineering 五阶段(DISCOVER→PLAN→EXECUTE→VERIFY→ITERATE)的原文段落,连"大多数开发者其实还不需要 loop"这种唱反调的视角也捞了出来——因为那篇文章确实在我素材里。
karpathy-llm-wiki 呢?它在 wiki/index.md 里一搜就命中一篇编译好的文章:
1 | | Loop Engineering: 从提示 Agent 到设计循环 | 2026 年 6 月爆发的 AI 编程 |
打开是一份消化整合过的结构化笔记:核心定义、Boris Cherny 的三阶段演化、五个必需品表格、引用了 8 个来源,读起来一气呵成。
这一局 karpathy-llm-wiki 赢在成品质量。loop engineering 是热门话题,我早让它编译过一篇。chao-rag-wiki 给的是原料,它给的是成菜。
这局反过来了。
chao-rag-wiki(hybrid + rerank):
1 | [1] rerank/score Mattpocock Skills 系统:AI Agent 的能力单元 › SKILL.md 的文件结构 |
干净命中 mattpocock 技能库里 grill-me、grill-with-docs 的介绍——"写代码前先让 AI 反过来拷问你"。注意第 3 条后面那个 (+1 dup copies):去重把那篇的副本合并成一条、留了来源标记,没让重复内容占掉好几个名额。
karpathy-llm-wiki 呢?我去 wiki/index.md 里搜 "grill"、"mattpocock"、"拷问"……
一条都没有。
不是说我素材里没有 grill 相关内容——有,好几篇正文都提了 /grill-me。问题是这个话题从没被单独编译成一篇 wiki 文章,index.md 里就没它的入口。按 karpathy-wiki "先读 index 再定位文章"的路子,它要么直接漏掉这个查询,要么只能模糊地甩你一篇泛泛的"agent skills 框架"。
这一局 chao-rag-wiki 完胜。它检索全文,根本不在乎你立没立过条目。
两个查询跑下来,结论挺清楚:它俩不是替代关系,是互补关系。
| karpathy-llm-wiki | chao-rag-wiki | |
|---|---|---|
| 核心机制 | AI 编译素材成文章 | RAG 全文语义检索 |
| 查询方式 | 读 index → 定位文章 | 向量+BM25 混合检索+重排 |
| 强项 | 热门话题、成体系的沉淀 | 全量召回、长尾话题、专有名词 |
| 弱项 | 没编译过的话题会漏 | 给原料而非成品、只能精确去重 |
| 延迟 | 编译慢、查询快 | 索引快、查询需联网 |
想读一篇消化好的总结,问 karpathy-llm-wiki;想确认"我到底收藏过啥"、找长尾、找冷门词,用 chao-rag-wiki。 |
我现在就是这么用的:chao-rag-wiki 当全文搜索引擎兜底召回,karpathy-llm-wiki 当精编笔记本沉淀热点。一个保证不漏,一个保证好读。
前面讲的都是 skill 本身。可知识库要真转起来,得先解决一个更前面的问题:素材怎么进来?总不能每篇手动复制粘贴。
我这套链路全自动,分三段。
raw/Obsidian Web Clipper 是官方的浏览器插件,Chrome、Edge、Firefox 都有。看到一篇好文章、一条推文,点一下插件图标,它就把正文提取成干净的 Markdown,存进你的 Obsidian vault。
它能配模板和保存路径,这是关键。我把模板的目标文件夹设成 vault 里的 raw/articles/,文件名用 {{date}} -{{author}}-{{title}},再让它自动带上来源 URL、抓取日期这些 frontmatter。于是浏览中随手一点,文章就躺进了 raw/——正好是两个 skill 都约定"只读、不改"的那个源目录。我那 775 篇,基本就是这么攒的。
素材进来了,但还没"可搜"。这步交给定时任务——raw/ 每天在长,那就让索引每天自己追上:
1 |
|
前面说了,--update 按内容哈希只处理新增和改动的文件,没变化就几秒退出、零 API 调用,所以天天跑也不浪费。Web Clipper 当天剪的新文章,第二天一早就进了向量库。
karpathy-llm-wiki 那一路同理,挂个任务把当天 raw/ 的新文件编译进 wiki 沉淀下来就行。两条管道并行:chao-rag 让每篇立刻可搜,karpathy-wiki 把值得沉淀的编成文章。
实际上是在我的Mac mini m2上的Hermes中配置了定时任务,每天凌晨调用这个skill进行索引处理。
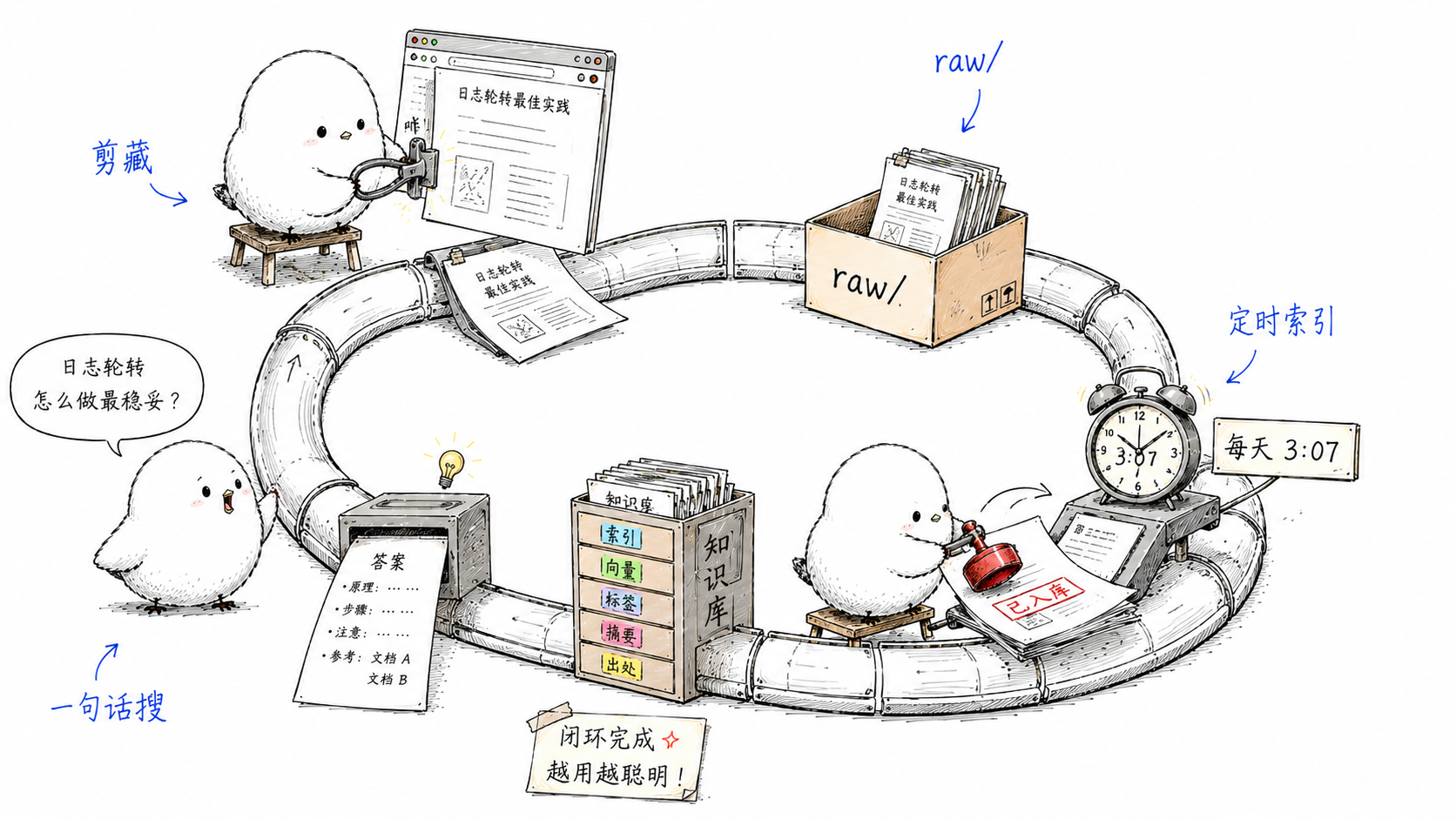
闭环这就成了。想找东西,直接在 Claude Code 里调:
/chao-rag-wiki 找出关于 X 的资料——全文混合检索,长尾、冷门词都捞得到;/karpathy-llm-wiki 我都知道哪些关于 X 的东西——读编译好的精编文章。整条链路连起来就是:浏览时点一下 Web Clipper,文章落进 raw/,定时任务自动索引,想搜时一句话调 skill。你只管"看到好东西点一下"和"有问题问一句",中间的剪藏、入库、索引全自动。Karpathy 那句"人类负责读和提问",落地大概就是这个样子。
chao-rag-wiki 已经开源,一行命令装上:
1 | npx skills add smallnest/chao-rag-wiki |
配好一个 embedding 的 key(默认千帆,也支持 OpenAI、Voyage 或任意 OpenAI 兼容网关),素材丢进 raw/,跑一句 build 就能开问。再按第五节配好 Web Clipper 模板和定时任务,整个知识库就自己转起来了。
最后留个彩蛋:写这篇时,"两个 skill 各跑两个查询、对比结果"那一步,就是 chao-rag-wiki 自己检索出来的。它检索自己被讨论的素材,多少有点自产自销。RAG 的尽头,没准就是让知识库学会自我介绍。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。