Jenova delivers hundreds of specialized AI agents (e.g., Manga Creator, Roleplay Game Master, Film Screenwriter, Fundamental Stock Analyst, Relationship Advisor), each engineered for a specific use case with encoded domain workflows, persistent memory, and context that compounds over time.
Where general-purpose AI tools require users to configure a model into an expert every session, Jenova's agents arrive ready to work. The Manga Creator orchestrates a multi-step workflow across character reference libraries, visual consistency, and narrative continuity spanning hundreds of pages. The Roleplay Game Master maintains persistent world state, tracks player decisions, and adapts the story accordingly. The Stock Analyst runs multi-source research pipelines, not single-prompt responses. These are automated expert systems, not prompt wrappers. What makes them valuable over time is retrieval: the ability to surface the right knowledge from a user's history and apply it to the current interaction.
That retrieval capability is powered by Pinecone.
Challenge
For Jenova, the core technical challenge was clear from the start: specialized agents are only as good as the knowledge they can access. An agent that forgets everything between sessions can't build on what it's already learned, and neither can the user. Without persistent memory, users would have to re-teach agents every session, a friction point that directly erodes retention and lifetime value. To deliver on the promise of genuine expert systems, Jenova needed knowledge as foundational infrastructure, not a feature bolted on after launch.
The requirements were demanding. The platform needed agent memory retrieval across sessions, RAG over user-provided materials (uploaded documents, web content, etc.), cross-agent context reuse through a shared memory layer, and long-term personalization via stored user-level context. The data involved conversation histories, uploaded files in multiple formats, web pages, agent-generated documents, and structured memory records, all needing to be indexed, retrieved, and surfaced at the right moment during real-time interactions.
Building and operating that retrieval infrastructure in-house would have consumed the engineering resources Jenova needed for product development. And treating memory as a secondary concern was not an option. For an agent platform, memory quality is what separates a product users rely on from one they abandon.
During early infrastructure planning, the team evaluated Milvus as an alternative. The decision came down to operational simplicity, reliability, cost, and ease of integration. Pinecone was the clear winner on all counts. Jenova needed retrieval infrastructure that was production-grade from the start, not a system that would require ongoing tuning or dedicated infrastructure engineering to keep running.
Solution

Pinecone has been part of Jenova's architecture since day one. Retrieval-backed agent memory was a design requirement, not something bolted on after the fact. The evaluation criteria were retrieval quality, production reliability, query latency, operational simplicity, scalability, and total cost of ownership. Pinecone was the clearest fit across every dimension, with its serverless infrastructure eliminating operational burden entirely.
In Jenova's architecture, Pinecone sits inside the agent memory and retrieval layer of the orchestration pipeline. When a user sends a message, the system generates a semantically-optimized retrieval query — not a raw copy of the message, but a clean extraction of what the agent actually needs to find. That query hits Pinecone, the most relevant context is returned, and it gets injected into the agent's orchestration payload before response generation begins.
This means agents aren't working from the immediate conversation window alone. They become knowledgeable by drawing from a curated view of everything relevant across a user's history: prior sessions, uploaded materials, and cross-agent memory, surfaced at exactly the moment they need it.
The retrieval architecture has evolved through several milestones:
Responsibilities are cleanly split across the stack. Jenova's application layer handles agent orchestration and workflow automation. Model providers (OpenAI, Anthropic, Google, and open-source models) handle embedding generation and language model inference. Pinecone handles vector indexing and retrieval. AWS serves as the primary cloud infrastructure. The split keeps each layer doing what it does best without coupling concerns that should be independent.
For an agent platform, the quality of the knowledge layer determines whether users stay or leave. Pinecone is what lets us store everything a user has ever worked on and retrieve exactly the right piece of it in milliseconds. That's the foundation our entire product is built on. — Boris Wang, Founder, Jenova
result
Pinecone-backed retrieval has become the foundation of Jenova's product differentiation, retention economics, and growth.
Retrieval precision that compounds over time. Standalone query extraction before retrieval ensures queries hitting Pinecone are semantically clean. Combined with Pinecone's retrieval accuracy, this improved judged retrieval relevance by roughly 20–25 percentage points in internal evaluations. In the majority of multi-session interactions, agents now successfully reference relevant prior context without user prompting, an effect strongest for power users with 20+ sessions of history.
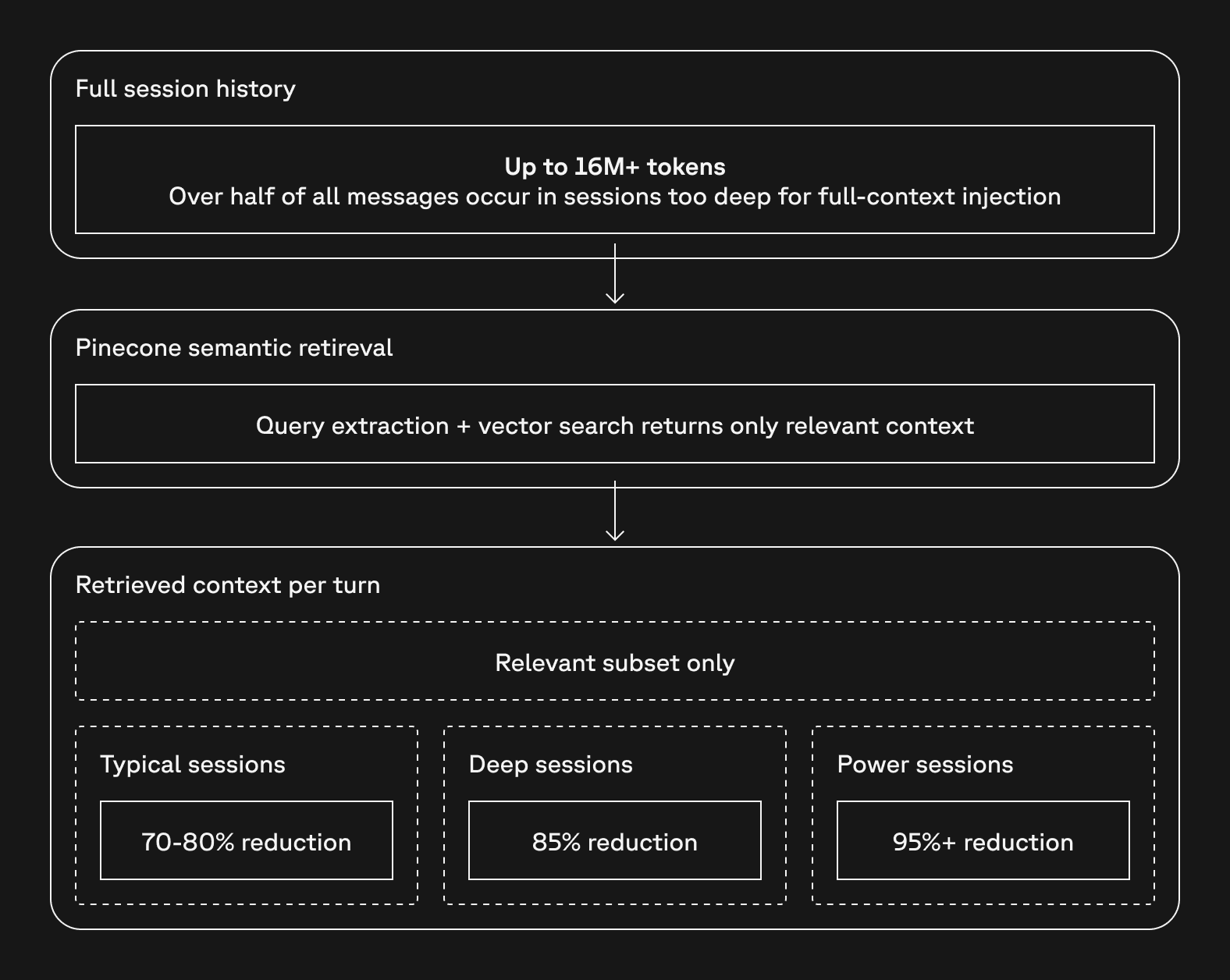
Dramatic token efficiency gains. Over half of all messages on the platform occur in sessions deep enough that full-context injection would be prohibitively expensive or impossible. The longest single session spans over 16 million tokens. Without vector-based retrieval, sessions at that scale simply could not function. Pinecone-backed semantic retrieval solves this by returning only the most relevant context per turn rather than the full history. For typical engaged sessions, this reduces token consumption by 70–80%. For deep sessions, the reduction reaches 85%. For the longest-running power sessions, it exceeds 95%. Those savings flow directly into gross margin.
Sub-10ms retrieval. Retrieval latency from Pinecone remains in the low single-digit milliseconds, effectively invisible inside a real-time agent interaction. That speed is critical for a platform where users interact with agents conversationally and expect immediate responses.
Scalable per-user isolation and unit economics. Pinecone's namespace architecture gives Jenova a muti-tenancy model with clean data isolation for each user within a single index. Every user's conversation history, uploaded documents, and cross-agent context lives in its own namespace, so queries only search that user's data. Because Pinecone charges per query based on namespace size, costs naturally align with user value: inactive users cost nothing, casual users cost little, and the most active power users cost more but are also the highest-paying customers. For a platform with 200,000+ signups generating user-specific knowledge across hundreds of agents, that multi-tenancy and pricing model is what keeps unit economics viable as the user base grows.
Organic growth driven by memory quality. Jenova has grown to over $1M ARR and 200,000 user signups across more than 70 countries, with nearly 100% of that being growth organic. Within the roleplay segment (~30% of all users and the platform's most popular agent), approximately 60% of new paying users come through word of mouth and community recommendation. Memory quality is the feature cited most often when users recommend Jenova. The number one reason users choose Jenova over dedicated roleplay AI products is the quality of its Pinecone-powered knowledge infrastructure.
High-value retention. Top power users concentrated in memory-intensive workflows like roleplay, creative writing, and long-running specialist research, spend $500–$2,000 per month. This includes businesses and organizations like the Central Bank of Nicaragua. The accumulated context from hundreds of sessions cannot be replicated on any competing platform. That accumulated knowledge is the definition of a switching cost.
Operational reliability. Zero Pinecone-related production incidents since launch. For a platform where memory reliability is part of the product promise, that track record matters.
Jenova's roadmap deepens its investment in Pinecone-powered retrieval. Near-term, the team is extending retrieval to cover image content via multimodal embeddings, giving agents like the Manga Creator the ability to retrieve from a user's visual history semantically rather than structurally. After that, async and background agent capabilities will allow agents to retrieve and process context proactively. A stock analyst that surfaces relevant portfolio context before the user asks, or a creative agent that prepares continuity context before a session begins.
When Jenova opens its platform to external developers through its upcoming Managed Agent API, third-party agents will be able to build on the same stack that powers Jenova's first-party agents, with fully managed memory, RAG, and agent workflow orchestration included. The same Pinecone-powered infrastructure that drives Jenova's retrieval layer will be available to every agent on the platform, making persistent, retrieval-backed knowledge a platform-level capability rather than something each developer has to build from scratch.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。