2023 welcomed AI with unprecedented enthusiasm, revealing new trends, solutions, and use cases. In fact, 55% of organizations have increased their investment in AI and now have a solution in pilot or in production since the start of the year. Reports by Retool, Menlo Ventures, and Streamlit all offer insights on the state of AI in 2023. Each report represents a different sample size, but there are some key themes across the reports that we’re most excited about.
The first common thread across the reports is that developers love Pinecone. Vector databases have been the fastest-growing databases in popularity over the past 12 months. In such a dynamic and complex space, we’re thrilled to be recognized as the most popular and most used vector database across all reports.

Pinecone is the most used vector database

Pinecone is the only vector database in Menlo Ventures Gen AI stack
Pinecone continues to receive recognition outside of these reports. Pinecone is the only vector database on the inaugural Fortune 2023 50 AI Innovator list. We are ranked as the top purpose-built vector database solution in DB-Engines, and rated as the best vector database on G2.
We designed Pinecone with three tenets to guarantee it meets and exceeds expectations for all types of real-world AI workloads:
The unanimous recognition is a powerful validation of our product principles. We are more motivated than ever to continue improving our product and delivering the best experience possible for all our customers.
Across the reports, generative Q&A is among the most popular applications. Streamlit’s report revealed that chatbots are the leading app category, and Retool’s survey echoes this sentiment, with chatbots and knowledgebase Q&A as the highest use cases internally and externally. Respondents told Retool their top concerns for those applications include model output accuracy and hallucinations.
When developing chatbots for specific purposes, there’s a need for customization with domain-specific data for more reliable results. For example, an internal legal Q&A assistant at a law firm needs to access all the public legal literature, and internal legal documents to generate more relevant and accurate answers.
Vector-based RAG, an AI framework augmenting LLMs with up-to-date external knowledge to improve response accuracy, is becoming the standard approach. 31% of AI adopters surveyed by Menlo Ventures use RAG to supply more accurate answers. Menlo Ventures also predicted that “powerful context-aware, data-rich workflows will be the key to unlocking enterprise generative AI adoption.” Those workflows, powered by RAG with vector databases, will provide companies a competitive advantage over the programmatic logic employed by many incumbents.
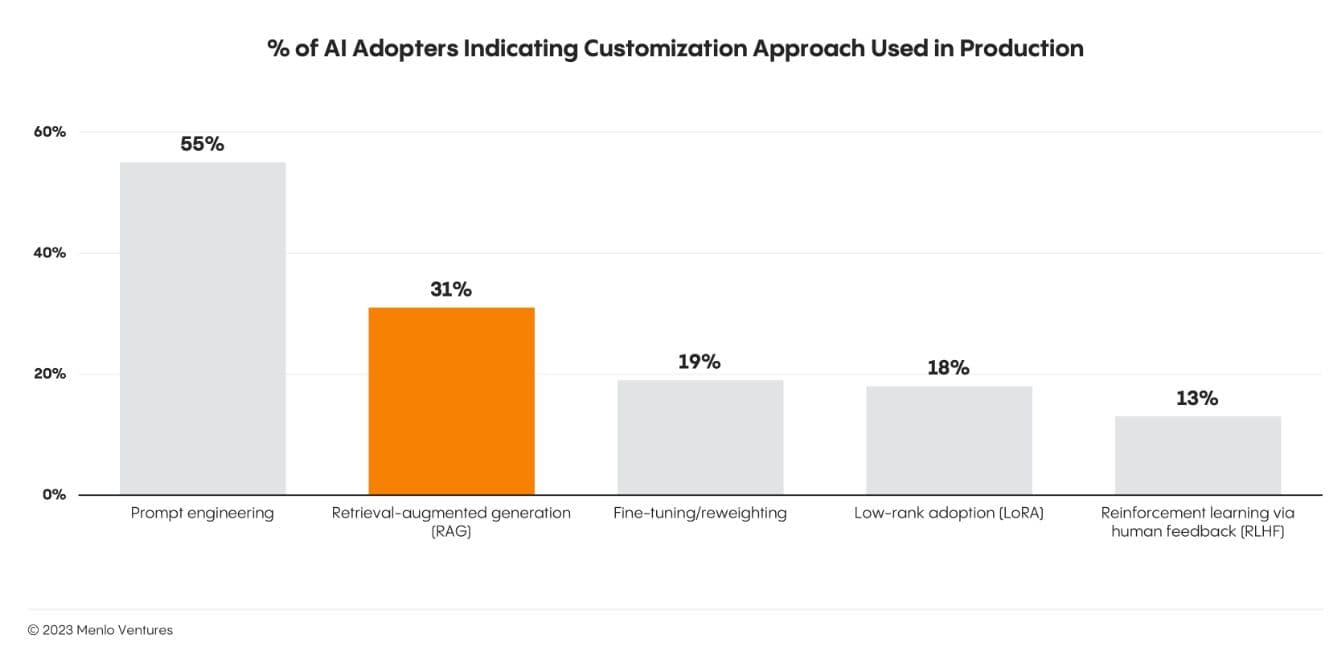
RAG is the 2nd most popular customization approach
To help developers quickly and easily build GenAI applications with RAG, Pinecone launched Canopy. Canopy takes on the heavy lifting such as chunking and embedding your text data to chat history management, query optimization, context retrieval (including prompt engineering), and augmented generation, so you can focus on building and experimenting with RAG.
While the modern AI stack is still in flux, it’s clear that building with a vector database like Pinecone will continue to transform industries. If you want an AI-powered search that’s fast, accurate, cost-effective, and scalable, a purpose-built database for vector data is necessary.
That’s why Pinecone built everything from scratch rather than piecing together a legacy architecture and a popular algorithm for a convenient bolt-on vector search. For example, our proprietary Pinecone Graph Algorithm (PGA) is built to be more memory efficient and achieve O(sec) data freshness, high availability, and low latency for production-level dynamic data.
Not all vector databases are the same. As gen AI use cases grow to billions of vectors, you need purpose-built vector databases that are highly cost-efficient at scale while still maintaining ease of use, high availability, performance, and accuracy.
A year ago, vector databases were still a new term to most people. All three recent reports highlighted the vector databases category, emphasizing their importance in the modern AI stack. The Streamlit report demonstrated that vector retrieval, the specialty of vector databases like Pinecone, is part of the fundamental LLM app architecture. Vector databases empower rapid and efficient searching within unstructured datasets, including text, images, video, or audio.
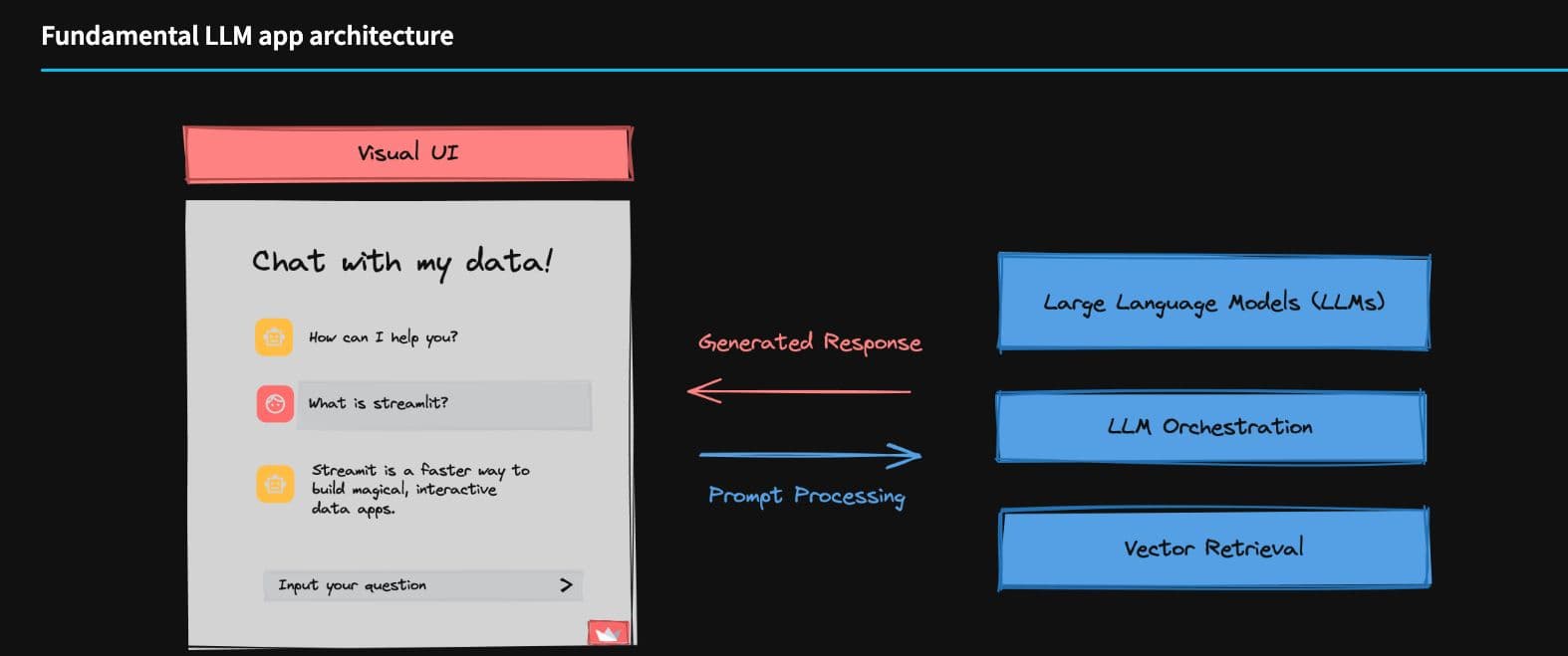
Vector retrieval is a key part in LLM app architecture
Despite all the excitement about AI, we’re still in the early days of adoption.
The Retool survey shows that although a majority (77.1%) responded that their companies had made some effort to adopt AI, around half (48.9%) said those efforts were fledgling – just getting started or ad-hoc use cases.
Menlo Ventures suggested that even though incumbents currently dominate the market, there are opportunities for startups to pioneer and drive innovation in the upcoming chapter of computing history. Advanced techniques, such as agents and chain-of-thought reasoning, are set to propel the next generation of generative AI-native players. These innovators are poised to reshape enterprise workflows and establish novel markets from scratch.
To stay ahead of the AI competition, try out the most popular vector database, or talk to our team, and learn how we can help you build revenue-driving GenAI applications.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。