Pinecone is thrilled to be partnered with Confluent today as they announce the general availability of the industry’s only cloud-native, serverless Apache Flink® service. Available directly within Confluent’s data streaming platform alongside a cloud-native service for Apache Kafka®, the new Flink offering is now ready for use on AWS, Azure, and Google Cloud. Integrated with Pinecone serverless, Confluent provides a simple solution for accessing and processing data streams from across the entire business to build a real-time, contextual, and trustworthy knowledge base to fuel AI applications.
Real-time GenAI applications require real-time data processing
Successfully deploying GenAI use cases will require retrieval augmented generation, or “RAG”, pipelines that provide relevant, real-time data streams sourced from every corner of the business. However, preparing pipelines of this sort is no easy task—especially when accounting for an ever-increasing amount of diverse data sources spanning across both legacy and modern data environments.
Ensuring applications have access to real-time pipelines with processed, prepared data will often require allocation of valuable engineering resources to manage open source tooling in-house rather than focusing on business-impacting innovation. Alternatively, securely processing data streams in multiple downstream systems (or across multiple distributed systems) is complex and inhibits data (re)usability, requiring redundant and expensive processing.
Without a reliable, cost-effective means of processing and preparing real-time data streams required by downstream tools, the benefits of GenAI will stay out of reach for most.
Easily build high-quality, reusable data streams with the industry’s only cloud-native, serverless Flink service
Apache Flink® is a unified stream and batch processing framework that has been a top-five Apache project for many years. Flink has a strong, diverse contributor community backed by companies like Alibaba and Apple. It powers stream processing platforms at many companies, including digital natives like Uber, Netflix, and Linkedin, as well as successful enterprises like ING, Goldman Sachs, and Comcast.
Fully integrated with Apache Kafka® on Confluent Cloud, Confluent’s new Flink service allows businesses to:
By leveraging Kafka and Flink as a unified platform, teams can connect to data sources across any environment, clean and enrich data streams on the fly, and deliver them in real-time to Pinecone. This ensures that their GenAI apps have the most up-to-date view of their business.
Confluent’s fully managed Flink service is now generally available across all three major cloud service providers, providing customers with a true multicloud solution and the flexibility to seamlessly deploy stream processing workloads everywhere their data and applications reside. Backed by a 99.99% uptime SLA, Confluent ensures reliable stream processing with support and services from the leading Kafka and Flink experts.
Together, Pinecone and Confluent enable simple development of GenAI applications
Pinecone became the most popular choice for developers building GenAI applications. The Pinecone and Confluent integration empowers users to quickly tap into a continuously enriched real-time knowledge base, so they can quickly scale and build AI applications using trusted data streams:
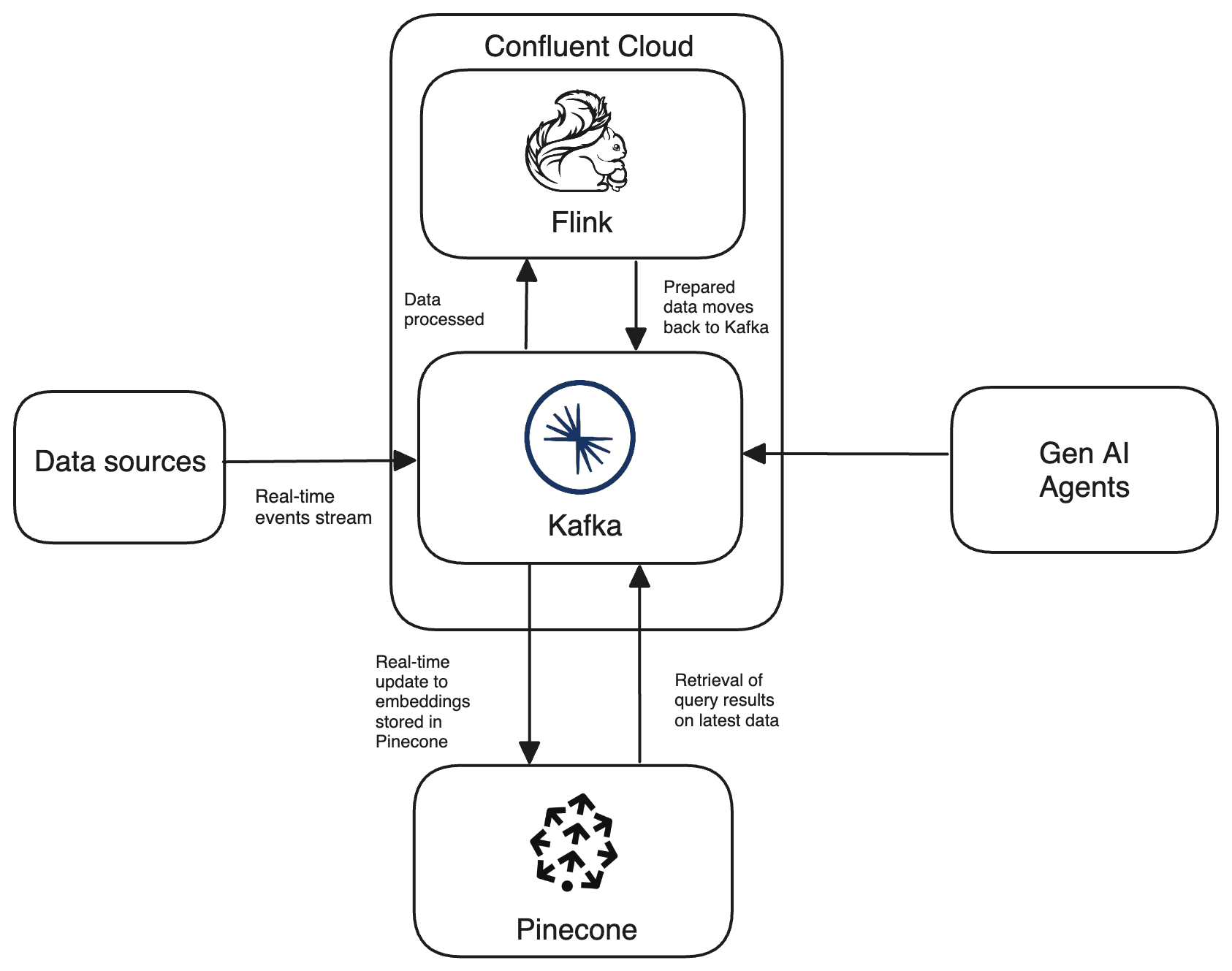
Pinecone and Confluent enable simple development of GenAI applications
When asked how the two technologies help our end customer, Pinecone's Vice President of Business Development said, “Pinecone’s recent Serverless offering changed the game for developers who want to create remarkably better GenAI applications at scale. Confluent’s new Apache Flink Service takes it a step further by unifying and curating trustworthy data streams. Our joint solution presents a reliable and cost-effective way for developers to build and deploy knowledgeable AI.”
Getting Started
If you are new to Pinecone, see why over 5,000 customers are running Pinecone in pilots or production applications and try us for free today.
Learn more about Confluent’s integration with Pinecone serverless and be sure to check out the Quick Start Guide to configure your integration. Not yet a Confluent customer? Start your free trial of Confluent Cloud today. New signups receive $400 to spend during their first 30 days—no credit card required.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。