relu 函数在deep net 里更容易梯度下降,收敛到最优解的能力比sigmoid更强,
下面通过 一元函数逼近来简要说明relu 函数是如何进行逼近的
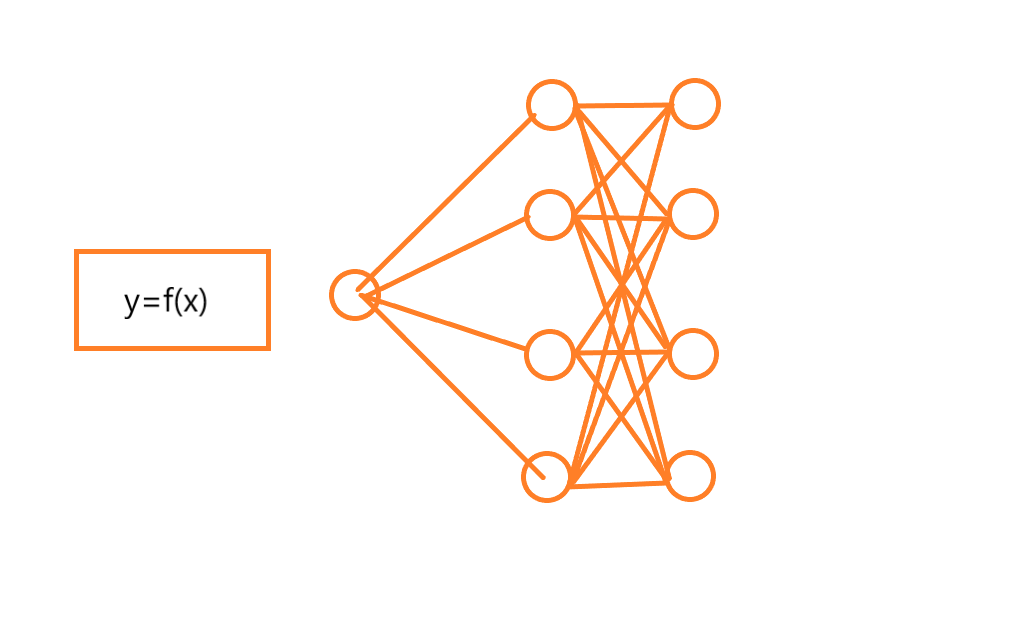
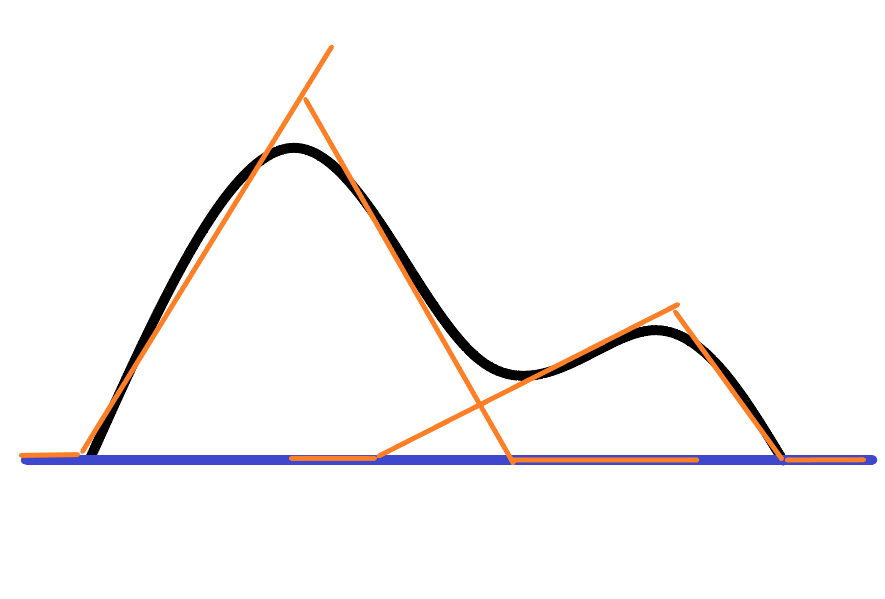
如上两图所示,deep net 中有一个输入节点,输入的样本就是 x 结果是 y=f(x)一类的非线性函数
现在因为每个x->f(x) 类似于第二图所示,那么经过若干轮训练后 会不会得到 象第二图那样的结果呢?就是说 第一个隐含层(整体来看是第二层) 上4个节点,最终是4个 relu函数,被调节成了,第二图的样子,这样可以满足每一个新输入的x值都会在符合误差要求的落在这4个relu函数中的一个上面,简单的说就是这4个relu函数有一个是正确的,那么根据deep net的 反向传播 梯度下降的若干次调节,是不是可以理解为,第二个隐含层也就是最右边那4个节点或 这一层就只有一个节点也可以,它可以通过反向传播找到第一层里总是去选择正确的那一个relu节点并且把其它节点有值(非0值)的激活节点给趋0化处理或称为作废处理,也就是 relu函数的非0分支被截取了
第一个隐含层的relu 函数 拐点都在 原点上,所以第二隐含层才有实际的逼近意义,
relu(w1x+b1),relu(w2x+b2),relu(w3x+b3),relu(w4x+b4), 这是第一个隐含层的4个节点,都还处于原点位,不具有拟合能力,到第二隐含层的节点有
relu(w11*relu(w1x+b1)+w12*relu(w2x+b2)+w13*relu(x3x+b3)+w14*relu(x4x+b4)+b11)
relu(w22*relu(w1x+b1)+w22*relu(w2x+b2)+w23*relu(x3x+b3)+w24*relu(x4x+b4)+b22)
relu(w33*relu(w1x+b1)+w32*relu(w2x+b2)+w33*relu(x3x+b3)+w34*relu(x4x+b4)+b33)
relu(w44*relu(w1x+b1)+w42*relu(w2x+b2)+w43*relu(x3x+b3)+w44*relu(x4x+b4)+b44)
粗体部分为 relu可拟合能力,可以知道 适当的 现在我们需要调节所有的参数2个隐层8个节点 应该就可以达成分段正确以给定误差逼近目标函数的能力了,如图2所示,拟合能力在于第二层的粗体,但是同时第二层外面不能有激活函数relu不然又会归于原点位,所以上面写得有问题 其实外面不能有relu函数
按我上面的图,来说,第一隐含层的 wix+bi 这些节点所产生的各种情况经过 relu 后输出结果应该是 各个wix+bi 线在 1,2维 (平面情况下)空间的截取吧,所以第一层应该就可以通过各种wi,bi凑合成一种对目标的拟合了,后面的节点主要是进行选择,为什么用relu可以而用y=x 和relu差不了多少的就不行,因为relu是非线性的,在net中表现情况估计就是线性的,最终不能彻底消除多义性节点,但非线的,大致上可以,更具体怎么回事还没想明白
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。