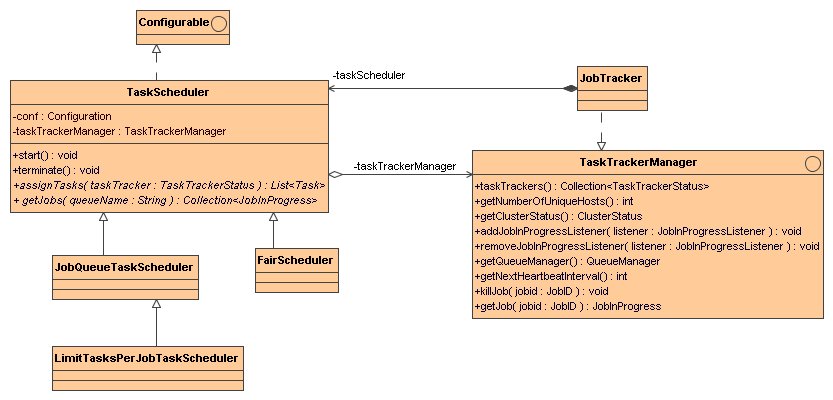
TaskScheduler是作业调度器的抽象基类. 具体的实现有:
JobTracker维护一个TaskScheduler的实例,并托管其生命周期.
TaskScheduler实例伴随JobTracker一起构造
![]() Code
Code
启动JobTracker的主方法中, 构造JobTracker对象并给taskScheduler设置TaskTrackerManager实例字段:
![]() Code
Code
在offerService中回调其start()方法:
public void offerService() throws InterruptedException, IOException {
taskScheduler.start();

}
taskScheduler在JobTracker.heartbeat方法中进行任务指派:
![]() Code
Code
taskScheduler销毁:
void close() throws IOException {
if (taskScheduler != null) {
taskScheduler.terminate();
}
}
taskScheduler中还有一个方法getJobsFromQueue(String queueName), 当前用于JobClient查询指定任务队列的Job信息.
TaskScheduler的实现的关键是分派任务的策略. 这体现在assignTasks方法中. TaskScheduler所需要的关于集群信息由
传入的TaskTrackerManager提供, TaskScheduler运行所需要的关于job的信息由JobQueueJobInProgressListener的Collection<JobInProgress> getJobQueue()方法提供.
JobQueueTaskScheduler是默认使用的TaskScheduler. 是一个单纯的FIFO.
其任务分配的规则相当简单:
对于Map任务:
1. 需要预留部分 task slot 以供失效任务,或应对边际效应的speculative任务之用.
2. 如果为当前TT找到 local task, 在不超过TT并发指标, 且满足集群task slot预留的基础上, 可继续为此 tt 分配 task.
如果分配给当前TT的是remote task, 则当次分派完毕(也就是只会为当前TT分配一个任务)。
对于reduce任务:
规则同上,不同之处在于不管有没有找到 local task, 每次heartbeat仅为给定 TT 分配一个task.
这里再补充一点信息, 在实际运营当中,当有某台机器的磁盘出现read only file-system时, 整个Job都会被挂死.
原因是因为机器任务失败后,其TaskTracker仍会不断和JobTracker进行心跳来领任务,而对于 ROFS这种情况,其后续Task的执行也必然错误.
这样,这个TT不断的错误,直到超过Job中容忍的错误上限时整个Job失败.
当前job的失败警戒值为mapred.max.map.failures还有mapred.max.reduce.failures.当job中map或reduce总共有这么多次失败后,job就会宣告失败.
对于tasktracker来讲,有个属性mapred.max.tasktracker.failures用来指定对于给定的job单个tt上最多能失败多少次, 如果超过阀值此tt会被拉入给定jobtracker的黑名单.
对于ROFS错误,要么是文件系统错误,要么是硬盘损坏。
对于文件系统错误,首先可以通过fsck进行文件系统修复,如果修复未果,只能重启,如果重启未果,则需要进行操作系统修复。
如果是磁盘损坏,若支持热插拔最好,否则只能关机换盘.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。