At Databricks, we’ve built a unique inference platform that serves every frontier model, from open source models like Kimi and Qwen to proprietary models like OpenAI, Gemini, and Claude. We power inference for some of the largest agentic applications in the world, including Superhuman, Yipit Data, Fox Sports, and others. Today, we serve more than 125T tokens per month.
What makes LLM serving hard at scale is reliability. With agents becoming the interface to how we work and live, inference demand is growing exponentially. We see extremely spiky demand curves that peak during working hours.
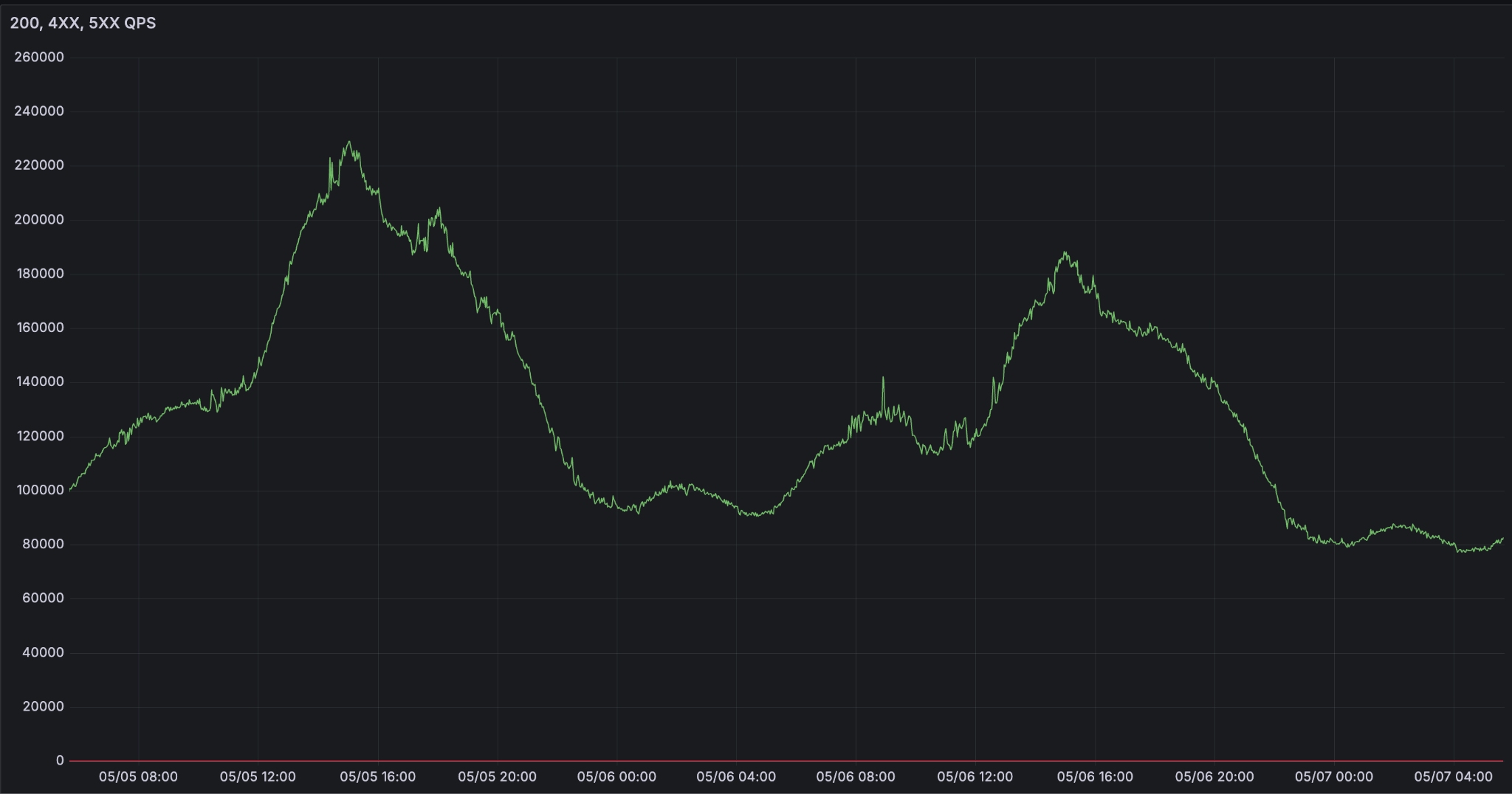
What does it mean to be a reliable inference platform? The contract appears simple. Availability is whether the request can be processed. But, in practice, different use cases have significantly different latency requirements, and this factors into availability. The most advanced agents cannot afford for p95 time to first token (TTFT) and output tokens per second (OPTS) to degrade.
In a multi-tenant system for LLM serving, achieving both reliability and latency is challenging.
Reliability
Frontier performance requires the latest GPUs with high bandwidth interconnect for KV cache transfer. These compute setups are fundamentally less reliable than classical CPU systems, and they are expensive. Given that all-to-all communication is required,, a single node’s downtime requires reconfiguration for multiple other nodes in disaggregated prefill/decode setups. The highest bandwidth networking requires single-spine connectivity in a single physical rack (e.g. NVL72 systems). This means failures in specific systems within a single datacenter rack can create a wide-blast-radius outage. Standard tricks in distributed systems like multi-AZ or leveraging backup instance types mean keeping expensive backup GPUs idling, a cost-prohibitive option. Overprovisioning is another classic trick, but given compute supply is so constrained, it’s extremely expensive and impractical. Thus, systems must remain operational under heavy strain.
Shipping velocity also needs to remain high under these constraints - our inference demand has grown multiple orders of magnitude year-over-year, and fueling that growth while shipping innovative features was challenging. Features like images, videos, and safety classification each require different preprocessing systems which all must scale independently.
Finally, achieving best-in-class performance and supporting new model architectures requires optimizations that span the gamut from custom kernels to proprietary inference engines. As architectures subtly change, new low-level software often gets introduced that can fail in opaque ways at scale, surfacing in difficult debugging scenarios ranging from server hangs to GPU crashes.
Latency
Keeping latency under control with diverse load patterns is challenging. This is because the cost to serve a request is highly variable and hard to estimate a priori. Even healthy servers under heavier load process all requests more slowly, exposing a tradeoff between throughput (and thus cost efficiency) and the fastest latency that products need to handle. This can also manifest as a reliability problem, since servers can unexpectedly enter unhealthy states very quickly based on the mix of requests assigned to them.
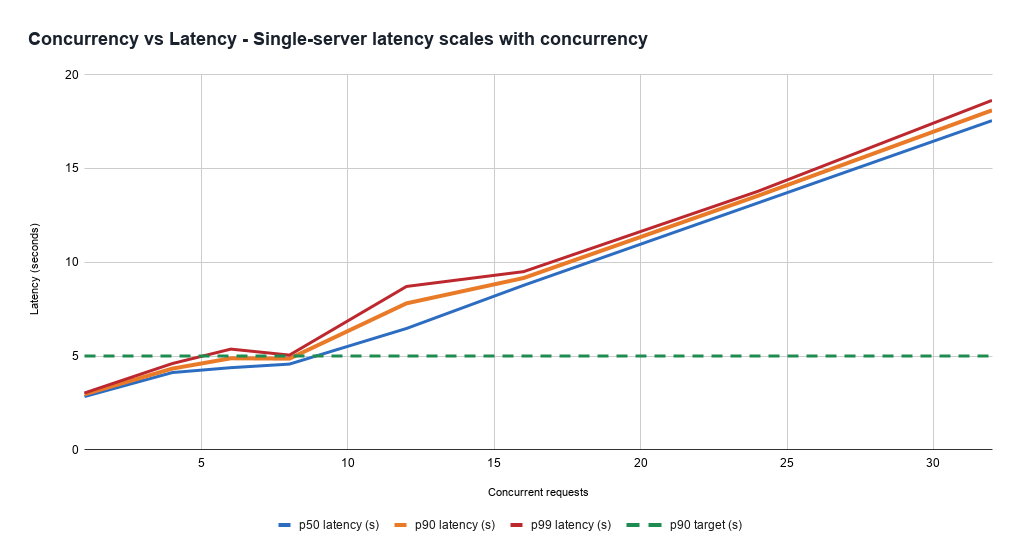
Additionally, latency is dominated by output token generation, but up-front estimation of cost is hard, since it’s difficult to predict how long the model will talk for. Thus, low latency serving requires complex capacity management, load balancing, and request prioritization systems.
Before we dive into the specifics of how to address those problems, let’s walk through a high level overview of our serving infrastructure.
In the data plane,
In the control plane,
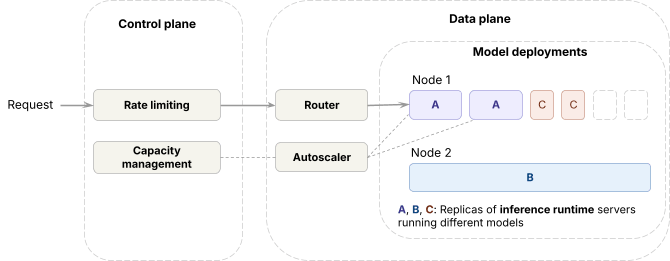
We need to be able to roughly reason about capacity - how much we have, how much we’ve sold, and how much customers are using. To do this, we introduced an abstraction called "model units." If we project that a replica can process a fixed number of model units per minute (e.g., 100), we can make the following assumptions:
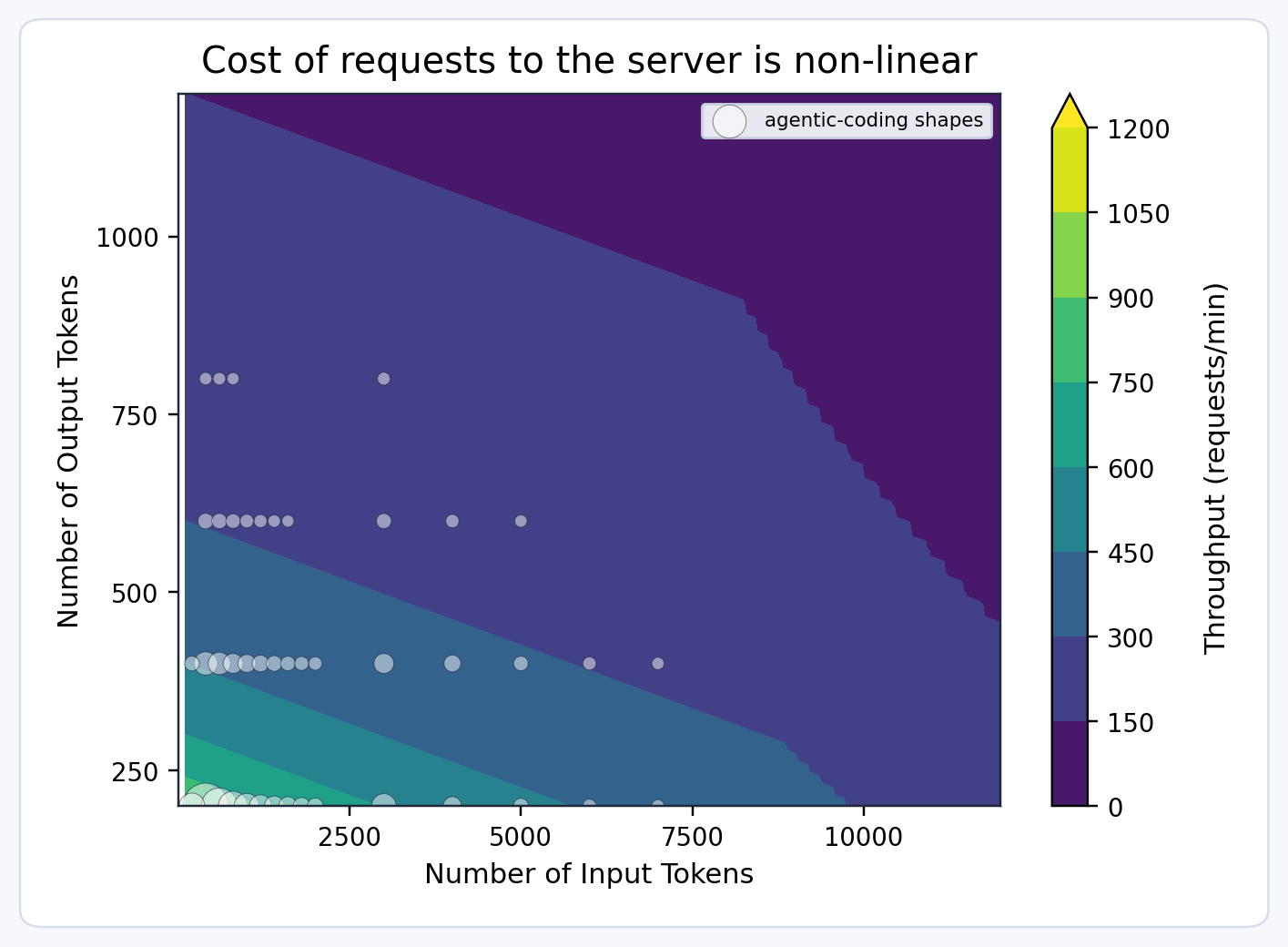
Therefore, we model request cost using a multi-dimensional function such as:
The coefficients α, β, γ are determined by automated benchmarking for each model on each hardware type. Model units can be further adjusted for optimizations like prefix caching, and they must account for features like multi-modality.
Such estimations are structurally imperfect, but they serve as a way for us to break a multi-tenant system into something more manageable that resembles cloud VMs. VMs have the desirable property of offering predictable performance that can be allocated to specific customers. For production agentic workloads, it’s important to offer guarantees around low latency and capacity, and without such allocation systems, the best we can do is offer “best-effort” capacity that could be clawed back if too many customers use the system.
Since requests have a highly variable impact on servers, it’s important to make nearly optimal routing decisions. In general, load balancing tends to lean on statistical approaches like P2C (power of two choices), which estimate load based on queue size and leverage sampling to reduce the memory and latency overheads of understanding all the possible targets. However, LLM latencies tend to be high, server counts are lower than scaled out CPU systems, and the cost of misrouting is severe. Therefore, LLM serving necessitates a different approach.
Today, we use Dicer, Databricks' auto-sharder, to dynamically route workloads across servers. Without load-aware routing, long-context requests cause individual servers to become hotspots while others sit underutilized. We integrated model units with Dicer so that routing decisions are based on server load in model units rather than traditional request-based heuristics. Dicer also provides stateful sessions, making request routing sticky. A workload's requests go to only a subset of servers, which improves cache hit rates (crucial for latency-sensitive workloads like coding agents) and limits blast radius.
We can also tune the load metrics and even use more optimal routing systems in the future based on higher fidelity cost metrics, as we learn more.
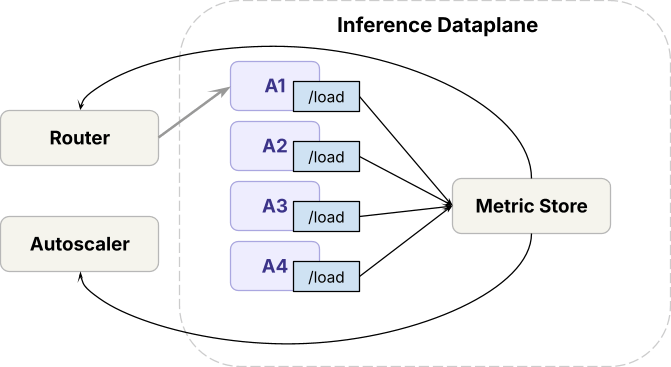
A similar problem exists in autoscaling. Pending request counts alone don't reflect true load. A spike in long-context requests looks identical to a spike in short ones, and CPU and memory metrics are similarly uncorrelated with actual GPU utilization.
Using model units, our autoscaler can decide whether to scale up or down based on the model unit utilization ratio. When the inference engine is running close to some percent of its maximum model units (determined by hardware type and workload shape), it's approaching peak throughput, which triggers scale-up. The reverse triggers scale-down. Rather than manually adjusting auto-scaling rules for each model, this approach allows for model-agnostic scaling infrastructure.
Building autoscaling on top of LLM inference patterns saved us from always scaling to max replicas. For models with bursty traffic, autoscaling kept replica counts close to actual demand, translating to over 80% GPU savings compared to static provisioning at peak.
Smart routing and scaling provided a great foundation, but they don't prevent failures at the engine level. No matter which inference engine we deploy (our in-house engine or popular open-source options), edge cases and resource contention emerge at production scale. We need mechanisms to detect and recover from failures automatically.
One failure mode we encounter is silent hangs. Requests involving edge cases (structured output, multimodal inputs) can trigger unhandled errors in the multi-process architecture of inference engines, causing servers to stop responding without surfacing errors.
We detect this with periodic black-box health checks: minimal end-to-end requests sent when no real requests have completed recently. If a health check fails, the Kubernetes liveness probe restarts the server. This works across all engines regardless of internal implementation.
However, under high load, health checks themselves can time out, causing the liveness probe to kill servers that are actually healthy. This risks cascading failures. To solve this, we assign health check requests the highest scheduling priority, ensuring they complete even under heavy load. With prioritized health checks, the full cycle of detecting a hang, killing the unhealthy server, and recovering takes less than 5 minutes. False liveness probe failures dropped from several per week to zero.
When large batches of multimodal requests arrived, we saw spikes in error rates and timeouts from a completely different source.
Investigations revealed that requests weren't even reaching the inference engine's core processes. Serving image requests is more resource-expensive than text-only requests, not just from the additional vision encoder running on GPUs, but also from CPU-intensive image processing. For certain models, the image processing was extremely slow, blocking the event loop entirely.
Moving blocking operations into separate threads and processes didn't solve the problem; requests still piled up under high image load. So we profiled the Python processes and made several discoveries:
By switching to Torchvision-based image processors and properly configuring OMP_NUM_THREADS, we sustained much higher QPS and fully leveraged the GPUs. After the fix shipped, requests completed per second jumped >3x with the same replicas and load. CPU throttling disappeared, and servers ran in a much healthier state.
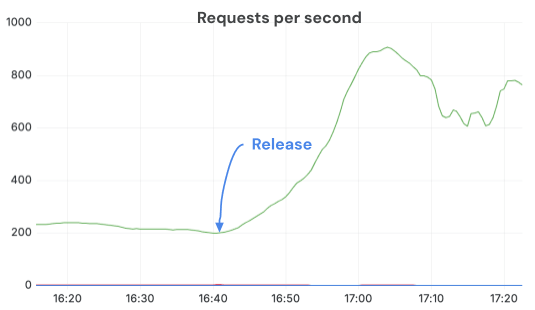
Serving LLMs reliably at scale requires work across every layer of the inference stack. We've covered autoscaling and load balancing infrastructure designed around LLM workloads, and runtime mechanisms that stay stable regardless of engine or workload. There's a lot more to the story: fast container start, safe rollouts across GPU fleets, GPU capacity management across clouds and regions. If these are the kinds of problems you want to work on, we’re hiring!
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。