The next phase of the open lakehouse will be defined by the catalog. Open table formats made it possible for many engines to work on the same data, but the catalog determines whether that data can be governed, optimized, and shared consistently across systems. As more workloads, including AI and agentic applications, depend on governed access to data across many systems, enterprises need an Iceberg catalog that can provide interoperability, great performance, and enterprise-ready governance.
That is why today, we are announcing the most comprehensive set of Iceberg capabilities available on any lakehouse catalog. In this blog, we will discuss new enhancements for Iceberg support in Unity Catalog and break down 5 things that make Unity Catalog the most interoperable Iceberg catalog on the market today.
We’ve pushed a broad set of Iceberg capabilities across Databricks and Unity Catalog into General Availability and Preview to ensure every engine, every catalog, and every team can work seamlessly together.
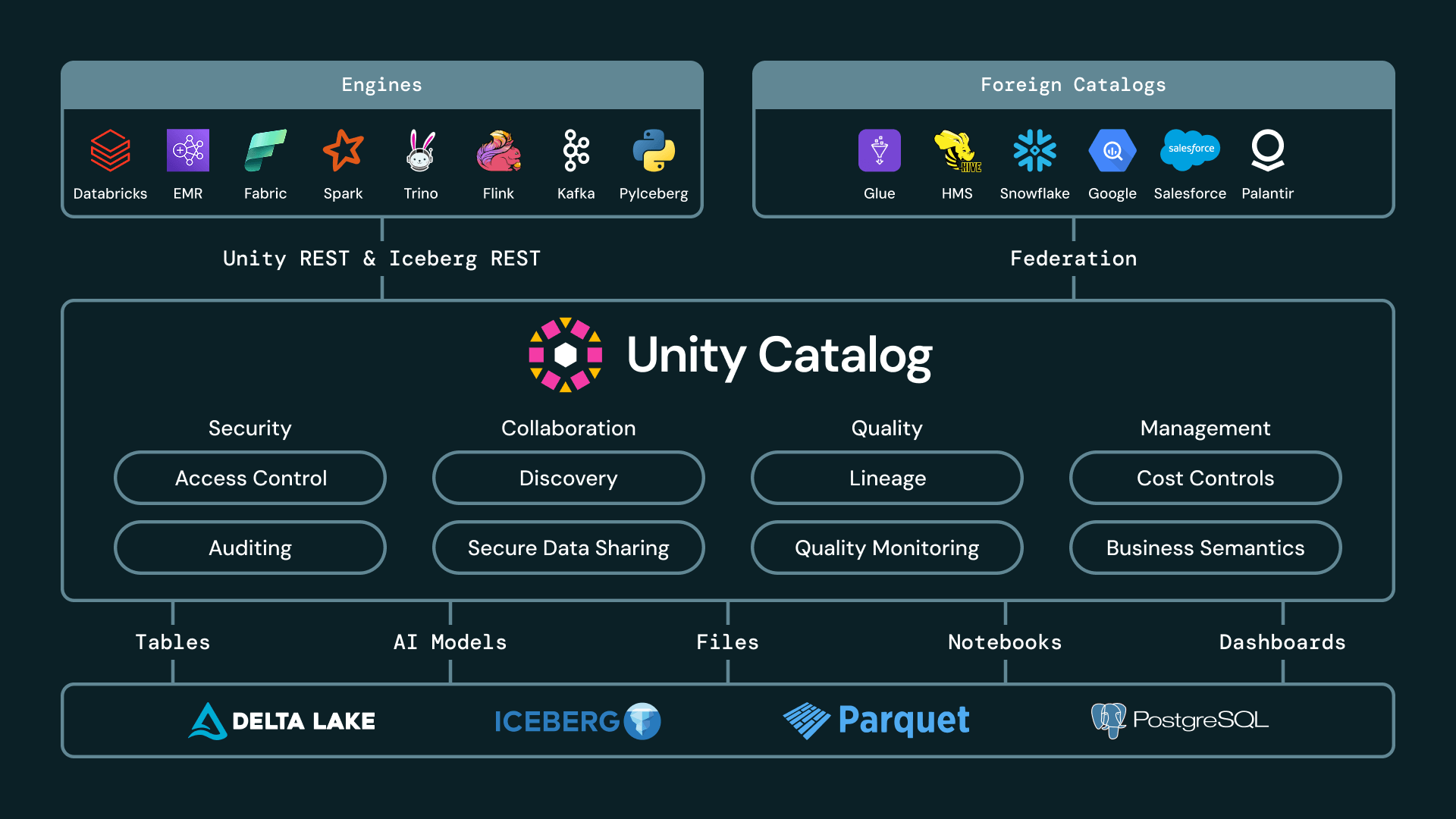
To deliver a fully open lakehouse, an Iceberg catalog must go beyond basic metadata tracking. It needs to give you absolute flexibility across diverse engines, vendors, and governance models. We believe evaluating an open Iceberg catalog comes down to how well it addresses five fundamental operational requirements: providing open APIs, federating across external estates, enforcing cross-engine governance, enabling secure and open sharing, and continuous performance and format innovation.
Unity Catalog is the only catalog that delivers on all five requirements.

Customers should be able to use the engine that best fits the workload, whether Spark, Trino, Flink, Snowflake, DuckDB, pandas, or another Iceberg-compatible client, without copying data or giving every engine broad storage permissions.
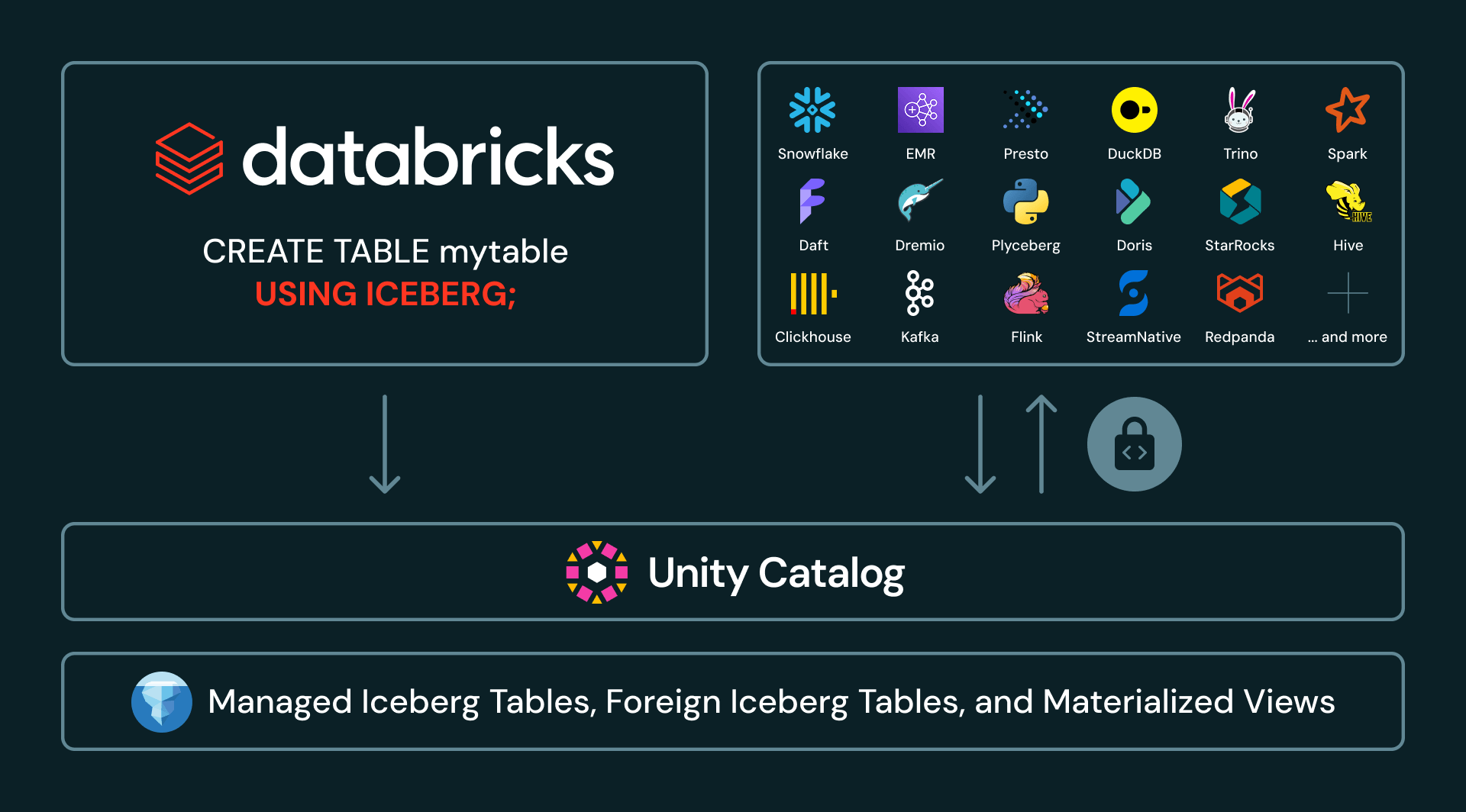
With Managed Iceberg now generally available on Databricks, customers can create, read, and write to Iceberg tables in Unity Catalog from any engine using UC’s Iceberg REST Catalog APIs.
UC’s Iceberg REST Catalog APIs now also extend beyond managed Iceberg tables. UC also vends credentials for federated Iceberg tables, providing secure access via open APIs even to tables managed in external catalogs. And, currently in Gated Public Preview, customers can create materialized views in Databricks and expose them as Iceberg tables to downstream consumers. With broader availability in the coming weeks, customers will be able to create Iceberg-compatible materialized views directly with CREATE MATERIALIZED VIEW my_mv USING ICEBERG.
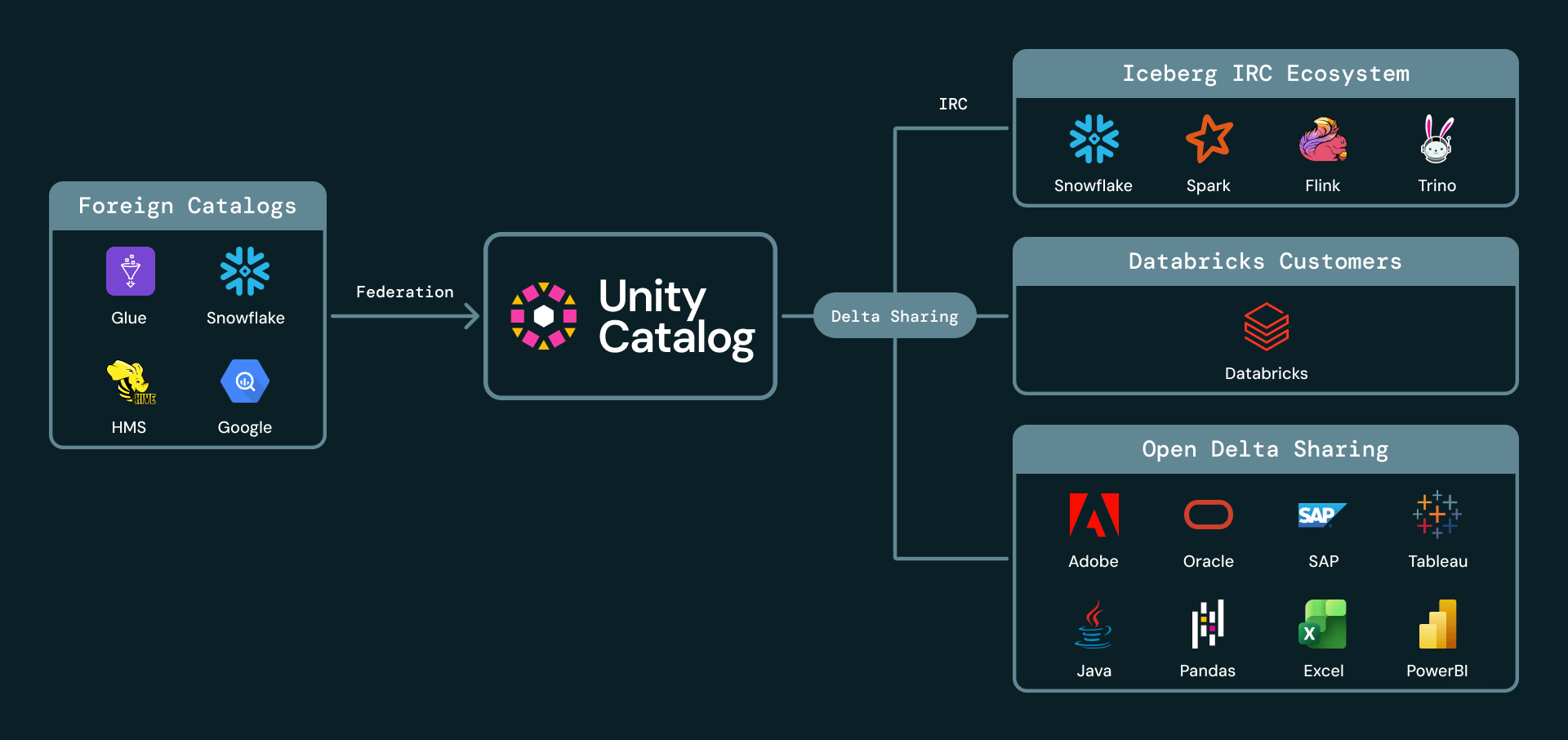
Many large enterprises have multiple catalogs in their lakehouse. For example, they may have data distributed across Unity Catalog, AWS Glue, Snowflake Horizon, and Hive Metastore. With Foreign Iceberg now generally available, Unity Catalog can govern Iceberg tables managed in other catalogs. Customers can discover, secure, query, and share external Iceberg tables through Databricks while leaving the data and source catalog in place.
Unity Catalog now supports a broad and growing set of Iceberg catalog integrations, including AWS Glue, Google Cloud Lakehouse Runtime Catalog, Snowflake Horizon, Palantir, Salesforce, and Workday. These integrations allow enterprises to treat Unity Catalog as the single pane of glass for their Iceberg estate, even when the data is produced or managed elsewhere.
Historically, row- and column-level controls were enforced inside a single engine. In the open lakehouse, the same table can be accessed by many engines. This introduced a hard problem: governance needs to work everywhere data can be accessed.
With cross-engine attribute-based access controls (ABAC) now in Beta, Unity Catalog extends attribute-based access control to Iceberg clients using the Iceberg REST Catalog Scan APIs.
How it works: Administrators define policies once in UC, including column masks, row filters, and tag-based policies. When an external Iceberg engine requests access, UC evaluates the applicable policies during server-side scan planning. UC then returns a filtered scan plan so the engine only reads authorized data when processing the query.
This brings fine-grained governance to external Iceberg engines using open standards. Any engine, such as Apache Spark or DuckDB, which implements the Iceberg REST catalog scan planning client (added in the Iceberg 1.11 release) can access data with ABAC enforced. Customers can use the best engine for each workload while maintaining one governance model across the lakehouse.
Unity Catalog and managed Iceberg give us the best of both worlds: native performance for our AI and ML pipelines, and open interoperability for every downstream consumer. One write path, zero duplication, and a governance layer every engine respects, including the AI-driven products we're building for Rippling's Data Cloud.— Tae Lee, Staff Engineer, Data Platform at Rippling
Cross-domain sharing often forces data providers into bad tradeoffs: copy data into another platform, build complex external authentication mechanisms, or require every recipient to use the same vendor ecosystem. Databricks pioneered secure open data sharing with Delta Sharing, the most widely adopted open source protocol for Data and AI sharing - supporting both Databricks-to-Databricks and Databricks-to-Open sharing.
We are excited to announce that Iceberg is now a first class citizen in Databricks DeltaSharing both as a source format, as well as a destination. With sharing to Iceberg clients now generally available, Databricks customers can share live data externally with any recipient that supports the Iceberg REST Catalog API. Recipients can query shared data from Iceberg-compatible clients such as Snowflake, Trino, Flink, and Spark, without manual ingestion or copies. Providers continue to manage access, auditing, and governance through Unity Catalog.
We are also announcing Public Preview of foreign Iceberg sharing. Customers can share Iceberg tables that are managed or cataloged outside Databricks but registered and governed in Unity Catalog. This means UC can serve as the sharing layer for managed and foreign Iceberg tables, while keeping data in place and governance centralized.
Open interoperability only works if the tables remain performant at production scale. Unity Catalog is the only catalog that uses AI to optimize your tables for faster queries and lower operational overhead. Predictive Optimization determines which tables need maintenance, which optimizations to run, and how often to run them, and adapts your table’s data layout based on workload patterns. This reduces the operational work required to keep Iceberg tables fast and cost-efficient as usage changes, and these optimizations benefit all engines - for example data layout optimization techniques improve data skipping for queries running outside of Databricks such as in Apache Spark. We are constantly innovating on the customer experience – and are the only catalog that can intelligently select clustering keys for optimal performance or automatically upgrade open tables with the latest innovations based on prior access patterns.
Databricks is also advancing the Iceberg standard itself. With Iceberg v3 now generally available on Databricks, customers get support for deletion vectors, row tracking, and VARIANT across managed Iceberg tables, foreign Iceberg tables, and UniForm-enabled managed tables. These capabilities close important gaps between performance and interoperability: deletion vectors accelerate updates, merges, and deletes; row tracking supports more efficient incremental processing; and VARIANT provides a standard representation for semi-structured data. These features also work seamlessly across both Delta and Iceberg tables, enabling interoperability without rewriting data.
These investments point to the same goal: open tables that do not force customers to choose between ecosystem interoperability and the performance capabilities required for production workloads.
Unity Catalog gives us one place to govern data across teams and systems, while managed Iceberg delivers the performance we need at our scale.— Kayvon Raphael, Head of Data Engineering, Magnite
Taken together, these five capabilities make Unity Catalog the best catalog for Apache Iceberg. UC gives customers open access to Iceberg tables, a unified view across catalogs, fine-grained governance across engines, secure sharing across domains, and automatic optimization for production workloads.
With Iceberg v4, we are rethinking the core metadata structure from the ground up for better performance, scalability, and interoperability. Our goal is to continuously raise the bar for performance and feature innovation, and to do so in a way that brings Iceberg and Delta Lake closer together. This is why we are also proposing that the next version of Delta, Delta 5.0, adopts the adaptive metadata tree structure.
The result is simple: all managed tables are automatically optimized in Unity Catalog, governed through open APIs, and available to any engine. While other platforms make you choose between interoperability and advanced performance and capabilities. With Unity Catalog, you get both.
Join us at Data + AI Summit to learn more about Apache Iceberg, Unity Catalog, open sharing, federation, and the next phase of Delta and Iceberg format unification.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。