Your BI dashboards are slow, and tuning them is costing too much time and money.
It's a familiar pattern. A dashboard query takes 30 seconds, so someone builds an aggregate table to speed it up. That table needs a refresh pipeline. The pipeline needs monitoring. Then a second BI tool needs the same data in a slightly different shape, so someone builds another aggregate table using a separate pipeline. Before long, you're managing a sprawl of aggregates, extracts, and tool-specific semantic layers — each with its own staleness window, its own governance gaps, and its own line item on the compute bill.
BI workloads are different from other analytical workloads. They're highly concurrent, latency-sensitive, and repetitive in their query patterns. That combination demands a deliberate approach to modeling, storing, optimizing, and serving data. The good news: Databricks provides a full stack for BI serving — from physical data layout to a governed semantic layer — and each layer compounds the performance gains of the layer below it.
This post walks through that stack bottom-up, with practical guidance on where to focus for the biggest improvements in query performance and cost.
Before diving into each layer, here's the full picture:
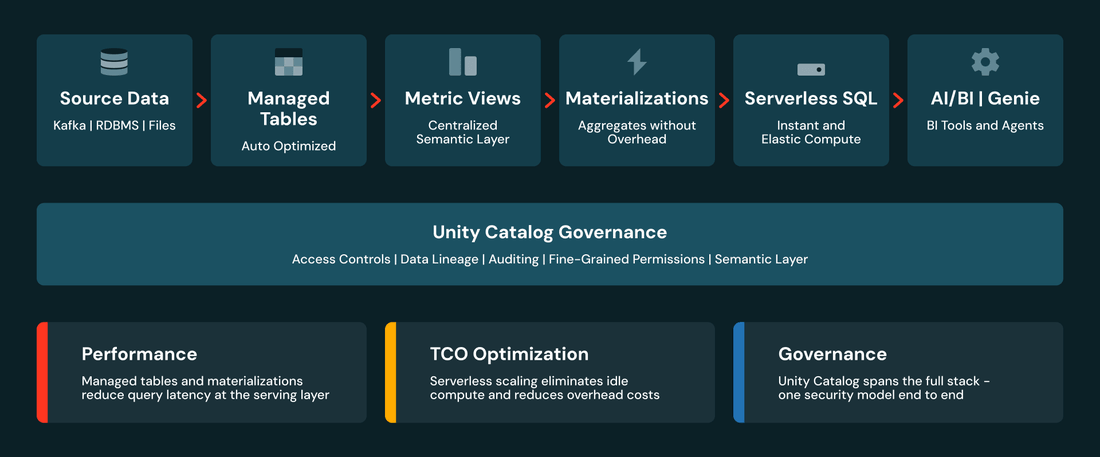
Unity Catalog provides governance throughout — lineage and access control from raw data through semantics to consumption. Each layer addresses a different aspect of performance and cost. Let's walk through them.
The physical layer is where most BI performance is won or lost. Get this right and every query benefits — before you've touched the semantic layer.
Star schemas remain the gold standard for BI query performance. Wide, denormalized dimension tables joined to fact tables via surrogate keys give the query optimizer clean, predictable join paths.
Databricks fully supports the relational modeling constructs you need: primary and foreign key constraints (with RELY for optimizer hints), identity columns for surrogate keys, and CHECK and NOT NULL constraints. If you're following a medallion architecture, keep your normalized or Data Vault models in Silver and build denormalized star schemas in Gold for BI consumption.
For detailed implementation patterns — SCD Type-1 and Type-2 handling, fact table ETL with MERGE, late-arriving dimensions — see the Implementing a Dimensional Data Warehouse in Databricks SQL blog series.
Unity Catalog managed tables are the foundation for everything else in this stack. Unity Catalog manages all read, write, storage, and optimization responsibilities for managed tables. This unlocks automatic features you don't get with external tables: Predictive Optimization (covered below) is enabled by default. Automatic liquid clustering selects clustering keys that adapt as query patterns change. Metadata caching is always on, reducing cloud storage requests and speeding up query planning.
Use managed tables throughout the platform — not just for BI-serving, but across Bronze, Silver, and Gold layers. They're the default table type in Unity Catalog, and the performance and governance benefits compound with every other optimization in this stack.
Liquid clustering replaces static partitioning and manual Z-ORDER — and unlike those approaches, you can redefine clustering keys without rewriting existing data. Add CLUSTER BY (col1, col2) at table creation or use ALTER TABLE on existing tables. If you're not sure which columns to choose, CLUSTER BY AUTO lets Predictive Optimization select keys based on observed query patterns.
For BI workloads, cluster on your most common filter and join columns — date keys, region, product category. You can select up to four columns, and if two columns are highly correlated, include only one. When dashboards filter on cluster columns, liquid clustering improves query performance through data skipping.
Predictive Optimization automatically runs OPTIMIZE, VACUUM, and statistics collection on tables that would benefit from these operations — so you don't need to schedule these jobs yourself. It collects both Delta data-skipping statistics and query optimizer statistics during Photon writes, and back-fills stats for existing tables. In observed workloads, this delivered an average 22% performance improvement. For BI workloads with repetitive filter patterns, the impact is especially significant — better statistics mean better data skipping and more efficient query plans.
Enable Predictive Optimization at the catalog level and let it run. Using Predictive Optimization is one of the highest-return, lowest-effort optimizations you can make.
The result: BI queries scan less data, join more efficiently, and cost less to run — and you haven't touched the semantic layer yet.
Here's where things get interesting. Most organizations have the same business metrics defined in multiple places — a revenue calculation in one BI tool, a slightly different one in another, a third variant in a SQL notebook someone wrote last quarter. Each definition drifts independently. Nobody's sure which one is right.
Metric Views in Unity Catalog solve this by providing a headless BI layer — a single, governed semantic layer where you define your data model and KPIs once, independent of any specific BI tool. You define them centrally in SQL or the point-and-click UI in Unity Catalog Explorer. AI/BI Dashboards, Genie, SQL notebooks, and third-party BI tools all resolve metrics from the same definitions. Define a metric once, and every consumer — human or AI — gets the same answer.
Metric Views go beyond centralized metric definitions — the semantic metadata is what sets them apart. Fields like display_name, comment, and synonyms give AI systems the context they need to interpret business questions correctly. When a user asks Genie "what was our revenue last week?", those annotations are how Genie maps natural language to the right measure and dimensions. No custom prompts, no separate glossary. The same applies to AI agents built on Databricks — any agent with access to Unity Catalog can discover and query governed metrics through the semantic layer instead of hard-coded SQL. The richer your metadata, the more accurately AI serves the right answer.
Here's an example using a system table, since every Databricks customer has access — but the same pattern applies to business KPIs like revenue, order volume, or customer retention. This Metric View calculates DBSQL warehouse metrics:
Consumers query the Metric View using MEASURE() to reference the governed metric definitions:
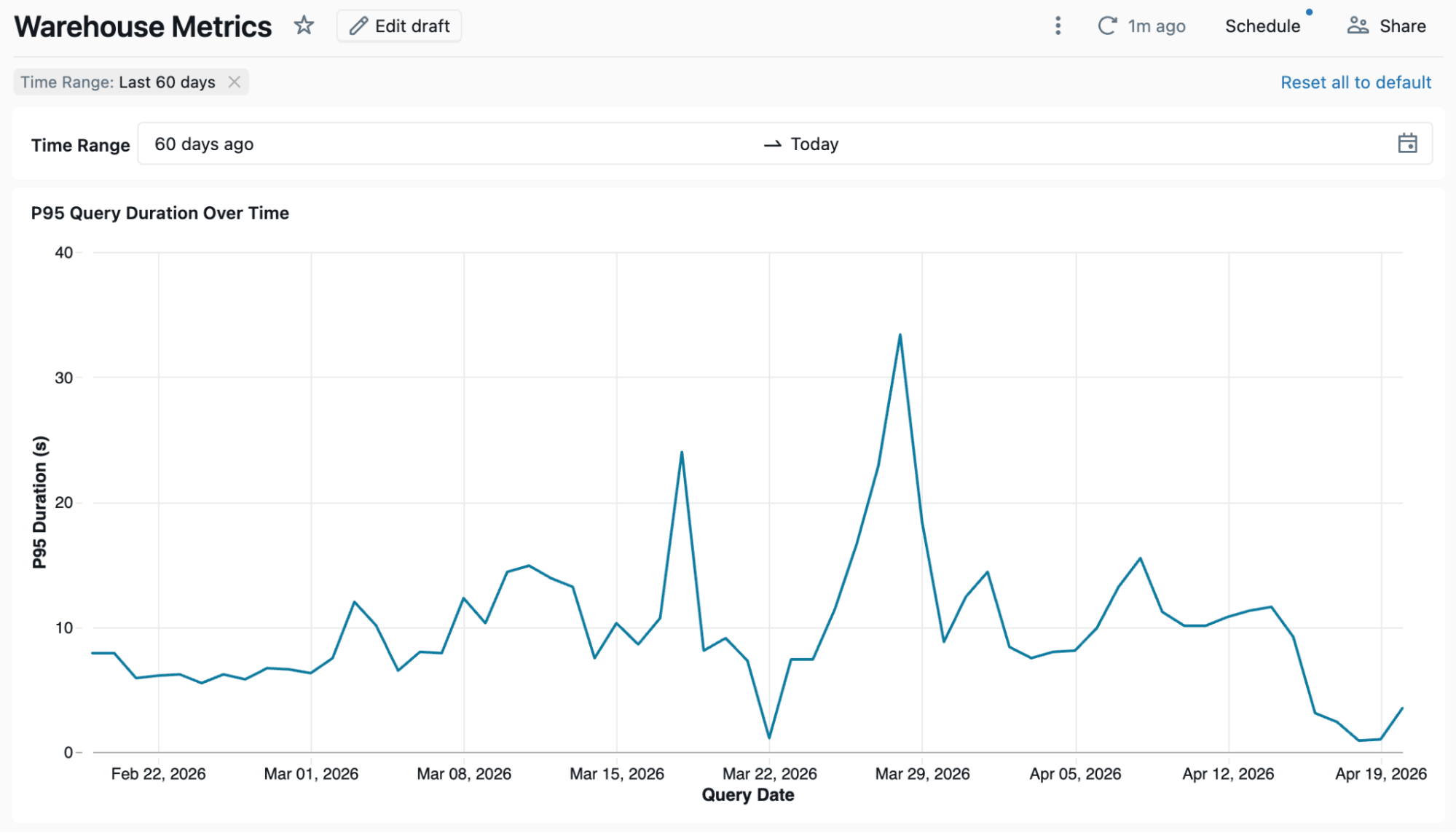
The metrics are defined once in the Metric View. Every dashboard, Genie space, or notebook that queries metv_dbsql_metrics gets the same result. Below is a dashboard using the metric view as a source.
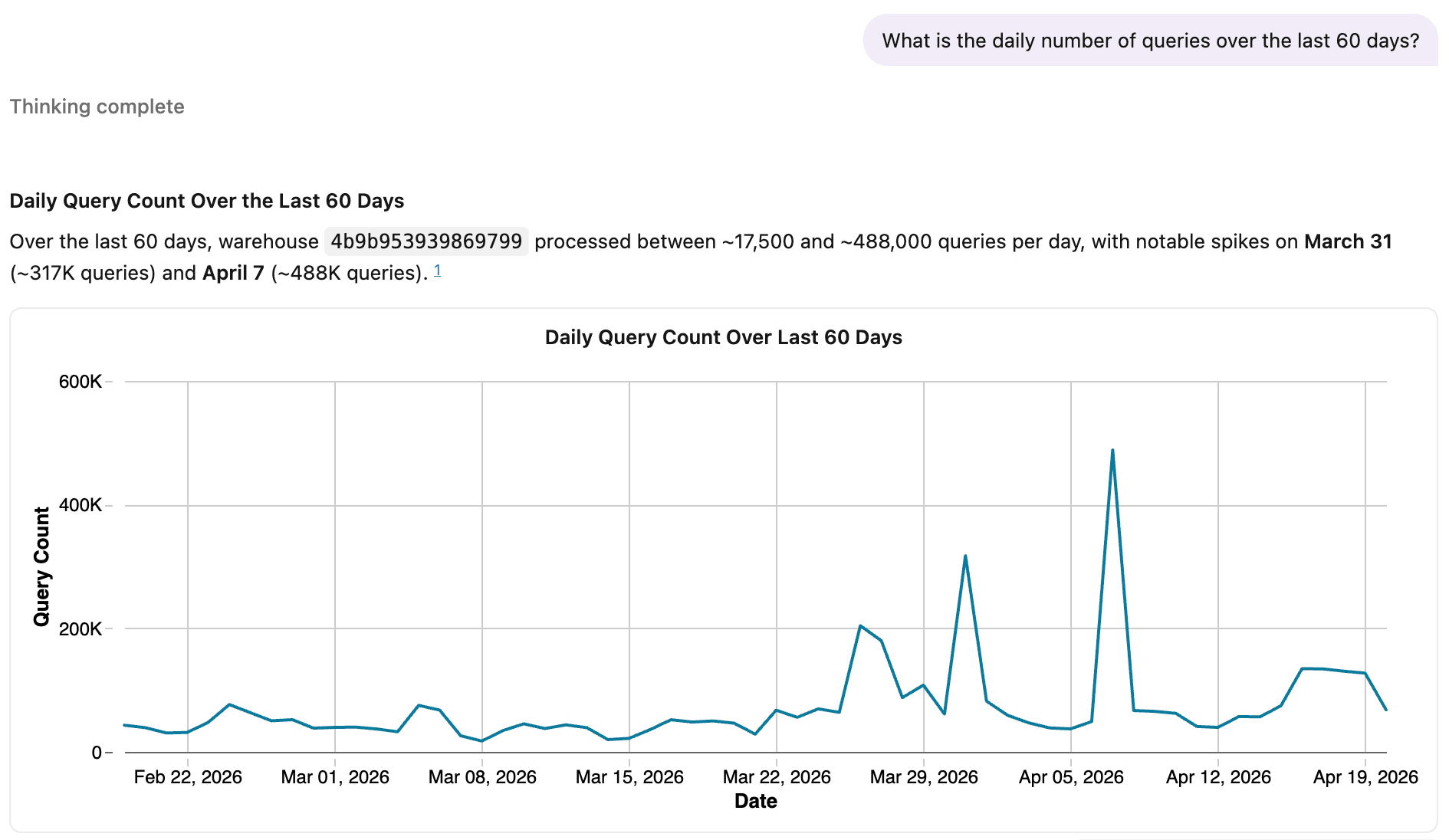
Here's Genie using the same metric view.
For teams with metric definitions scattered across multiple BI tools, Metric Views provide a path to consolidate the semantic layer into Databricks. Instead of maintaining separate metric logic in each tool, you define it once in Unity Catalog and connect your BI tools to that governed source.
The core implementation is open-sourced in Apache Spark™ (SPARK-54119), with Unity Catalog OSS support coming — so you're building on an open standard with no vendor lock-in. That openness matters more as AI takes on more of the BI workload. Agents querying your data need a consistent, machine-readable definition of what each metric means, and an open standard lets any tool or agent — not just vendor-specific ones — reason over the same governed metrics.
Traditionally, when BI dashboards were too slow, the answer was to build aggregate tables. You'd create materialized views or custom pre-aggregation tables on top of your star schema, set up refresh pipelines, and re-point your BI tools at the new tables. It worked, but it added a whole layer of objects and pipelines to maintain — and every time the aggregation logic changed, you had to update the BI tool queries to match.
Metric View materialization offers a simpler alternative. When you enable materialization on a Metric View, the platform automatically maintains pre-aggregated results behind the same metric definitions your BI tools already query — no separate aggregate tables to build, no BI tool queries to refactor. Here's what happens under the hood:
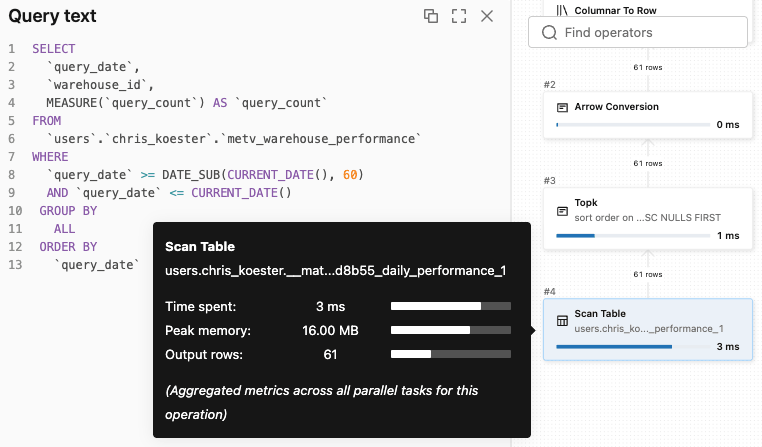
Dashboard queries that previously scanned full fact tables now hit pre-aggregated materializations — with lower latency and lower compute cost. The dashboard and Genie examples above both queried the same Metric View, and both had their queries transparently routed to a materialization. The query plan below from Genie shows this in action.
Faster queries and lower cost aren't competing goals — every optimization that reduces data scanned also reduces the compute you pay for. And each optimization in the stack compounds. Liquid clustering and better statistics improve data skipping and query plans. Materializations can be refreshed incrementally, reducing the compute SQL warehouses need to serve dashboards. Here are a few more ways to lower cost:
system.billing.usage and system.query.history can be used to track BI usage by dashboard, user, and warehouse. Build Metric Views and an AI/BI Dashboard on system tables to gain visibility into your BI usage.You don't need to implement the entire stack at once. Start where you'll see the most impact:
OPTIMIZE, VACUUM, and statistics collectionDatabricks provides optimizations at every layer of the BI serving stack. Managed tables, liquid clustering, and Predictive Optimization minimize data scanned and compute spent. Metric Views centralize your business logic in a governed semantic layer that serves dashboards, Genie, and AI agents consistently. Materialization delivers sub-second query performance without manual pre-aggregation pipelines. Together, these layers compound — driving down both query latency and total cost of ownership.
Start by defining your first Metric View on an existing Gold-layer table and enabling materialization. See the resources below to get started.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。