添加访问Milvus密码:https://wtl4it.blog.csdn.net/article/details/147311073?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EYuanLiJiHua%7EPaidSort-1-147311073-blog-148588110.235%5Ev43%5Epc_blog_bottom_relevance_base5&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EYuanLiJiHua%7EPaidSort-1-147311073-blog-148588110.235%5Ev43%5Epc_blog_bottom_relevance_base5&utm_relevant_index=1
向量数据库是用来缓解LLM上文长度受限、模型知识更新成本高的重要工具。将附带语义信息的非结构化数据进行向量化后存储到向量数据库中,即可在业务中可通过相似度算法从库中检索出相关数据,Milvus便是其中之一。Milvus分为Milvus Lite、Milvus Standalone 和 Milvus Distributed三个版本,由于笔者的使用场景中,数据量没那么大,但也不确定会很小,于是便掐头去尾选择Milvus Standalone版本,另外,与Milvus交互时使用的语言为Python,设备的操作系统为WSL2 Ubuntu。由于是初见Milvus,因此记录的内容中势必有许多错误,还请读者多多包涵、不吝斧正。
使用Milvus之前,需要先在设备上部署Milvus数据库,并安装相应的SDK,官方文档中提供了在Docker中安装Milvus的安装脚本。
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
bash standalone_embed.sh start
执行standalone_embed.sh脚本时会自动下载相应的docker镜像,如果读者因网络问题下载失败,可尝试将docker镜像源调整为"https://docker.1ms.run"或"https://docker.xuanyuan.me",或许可以成功下载。如果安装过程中报错,需要重试的话可以使用delete指令删除历史镜像后再重新执行start。
bash standalone_embed.sh delete
SDK的安装方式也比较简单,就不过多赘述了。
pip install pymilvus
上述步骤执行完毕后即可开始使用Milvus,但可能有一个潜在的坑,官网文档中有“使用GPU运行Milvus”字样的章节,但其中并未介绍何时需要使用GPU运行Milvus、GPU在哪些步骤起到加速作用、加速效果如何等方面的内容,等后续遇到相关问题时再回来补这个坑。另外,在官方提供的standalone_embed.sh中包含了启动milvus镜像时的默认参数,读者可按需更改,在本次实验中均在默认参数的条件下进行。
Milvus通过Collection来管理数据,Collection本身是一个二维表,有固定的列和变化的行,每列代表一个字段,每行代表一个Entity。插入数据时,需要先在Milvus中创建Collection,同时设定Collection中都包含哪些字段,每种字段都是什么数据类型,这些字段的要求被称之为“Schema”。一个Collection Schema中可以包含一个主键、最多四个向量字段和几个标量字段,官方文档中给出的图例如下所示。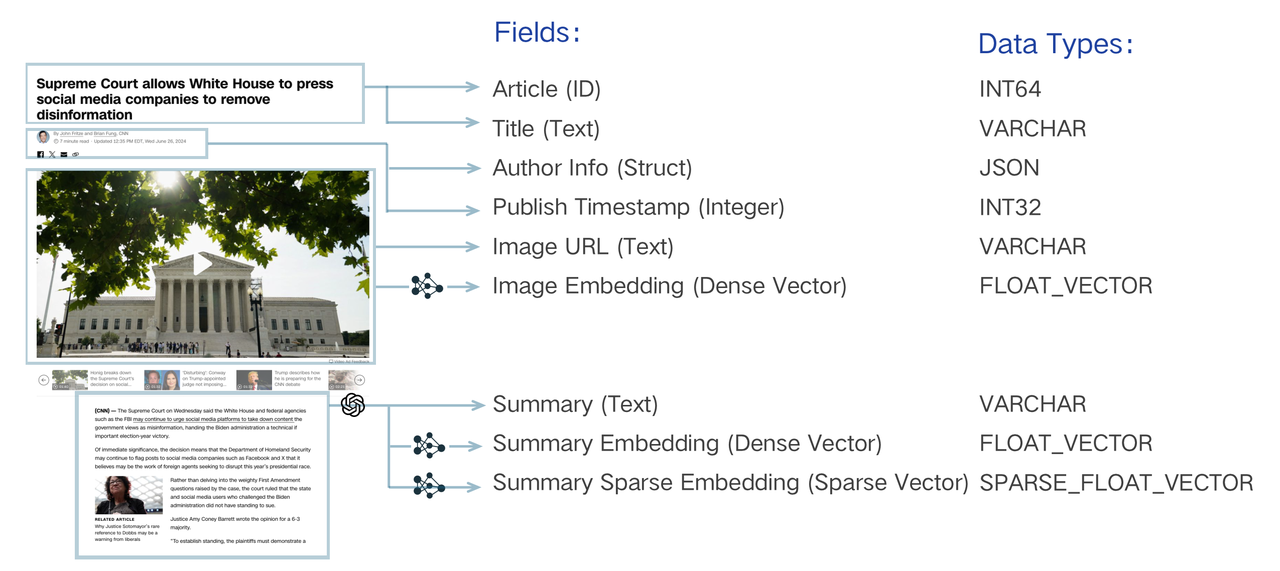
通过阅读python SDK中的DataType类,发现实际上Schema中支持的数据类型要比图例中给出的数据类型丰富一些。
| 分类 / Category | 数据类型(SDK 常量) |
|---|---|
| 布尔型 Boolean | BOOL |
| 整型 Integer | INT8、INT16、INT32、INT64 |
| 浮点型 Floating | FLOAT、DOUBLE |
| 字符串 String | STRING、VARCHAR |
| 半结构化 Semi-structured | JSON |
| 几何型 Geometry | GEOMETRY |
| 向量型 Vector | BINARY_VECTOR、FLOAT_VECTOR、FLOAT16_VECTOR、BFLOAT16_VECTOR、SPARSE_FLOAT_VECTOR、INT8_VECTOR |
于是,创建一个Collection的case就呼之欲出了。
from pymilvus import MilvusClient, DataType
from configs.config import VECTORDB_DIM, COLLECTION_NAME
此时就可以访问Milvus的webui,在Collections选项卡中看到刚刚创建的Collection。这里留两个伏笔,在官方文档中,创建Collection有两个可选步骤:设置索引参数和设置集合属性,由于是初见记录而且文档中也难以直接看懂这两部分的作用和应当使用的时机,所以暂时先略过,下面开始尝试向Collection中插入数据。
开荒阶段,删删改改是常见的事情。
from pymilvus import MilvusClient
from configs.config import COLLECTION_NAME
milvus_client = MilvusClient()
if milvus_client.has_collection(collection_name=COLLECTION_NAME):
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
在创建Collection时设定Schema中,包含id、category、title、pub_time、vector这几种值,其中vector是title的向量化结果,其余均为标量,实现插入功能使用一行代码就能实现,官方文档中也只有这一行代码,但在实际使用过程中,需要为插入的Entity创建索引,这里的索引和前面创建Collection时可选步骤的索引看起来像是同一个东西,可是据说一个Collection中可以创建不超过4个向量字段,如果真的需要4个向量字段,那还需要保证这4个向量使用相同的索引?Whatever,先继续进行。
from openai import OpenAI
from pymilvus import MilvusClient
from engines.corpus.corpusEngine import get_video_list, string_to_timestamp
from configs.config import OpenaiConfig
openai_client = OpenAI(api_key=OpenaiConfig["api_key"], base_url=OpenaiConfig["api_base"])
MODEL_NAME = "text-embedding-3-small"
DIMENSION = 1536
raw_data = get_video_list()
ids = [i["id"] for i in raw_data]
categorys = [str(i["diseaseTypeId"]) for i in raw_data]
titles = [i["title"] for i in raw_data]
pub_times = [string_to_timestamp(i["publishTime"]) for i in raw_data]
vectors = [
vec.embedding
for vec in openai_client.embeddings.create(input=titles, model=MODEL_NAME, dimensions=DIMENSION).data
]
通过向量相似度的方式来检索出与输入query相关的Entity,实现起来也是一行代码。
from pymilvus import MilvusClient
from openai import OpenAI
from configs.config import OpenaiConfig, COLLECTION_NAME
openai_client = OpenAI(api_key=OpenaiConfig["api_key"], base_url=OpenaiConfig["api_base"])
MODEL_NAME = "text-embedding-3-small"
DIMENSION = 1536
client = MilvusClient()
client.load_collection(COLLECTION_NAME)
query = "小麦过敏"
query_vector = openai_client.embeddings.create(input=query, model=MODEL_NAME, dimensions=DIMENSION).data
query_vector = [i.embedding for i in query_vector]
res = client.search(
collection_name=COLLECTION_NAME,
anns_field="vector",
data=query_vector,
limit=3,
虽然粗枝大叶,但也算是有一个阶段性的进展了,其他的基本操作和基础知识我们后续再补充:
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。