
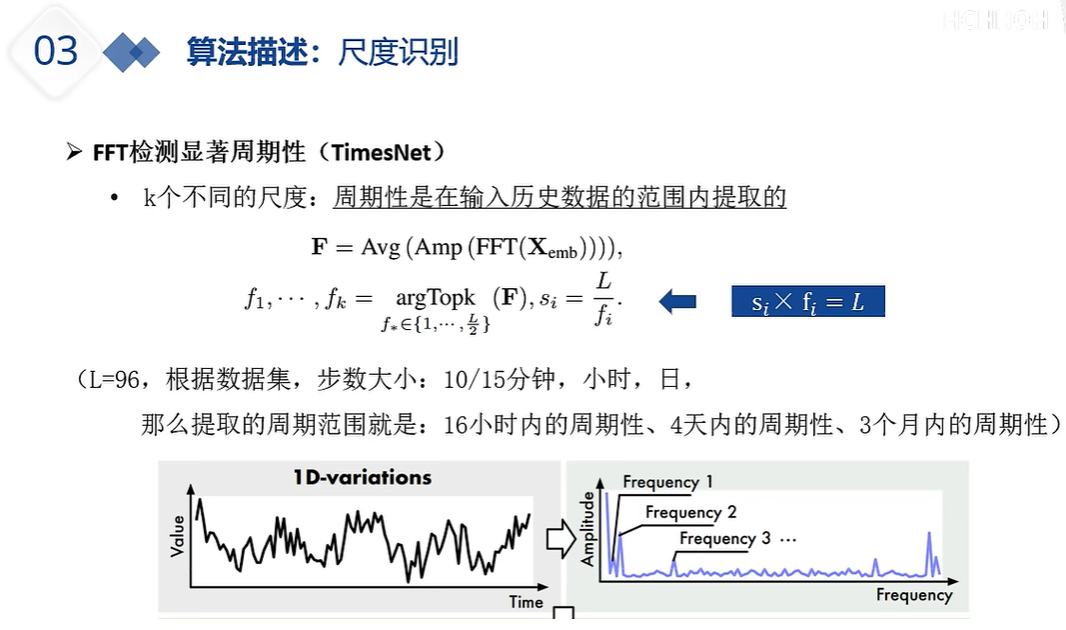

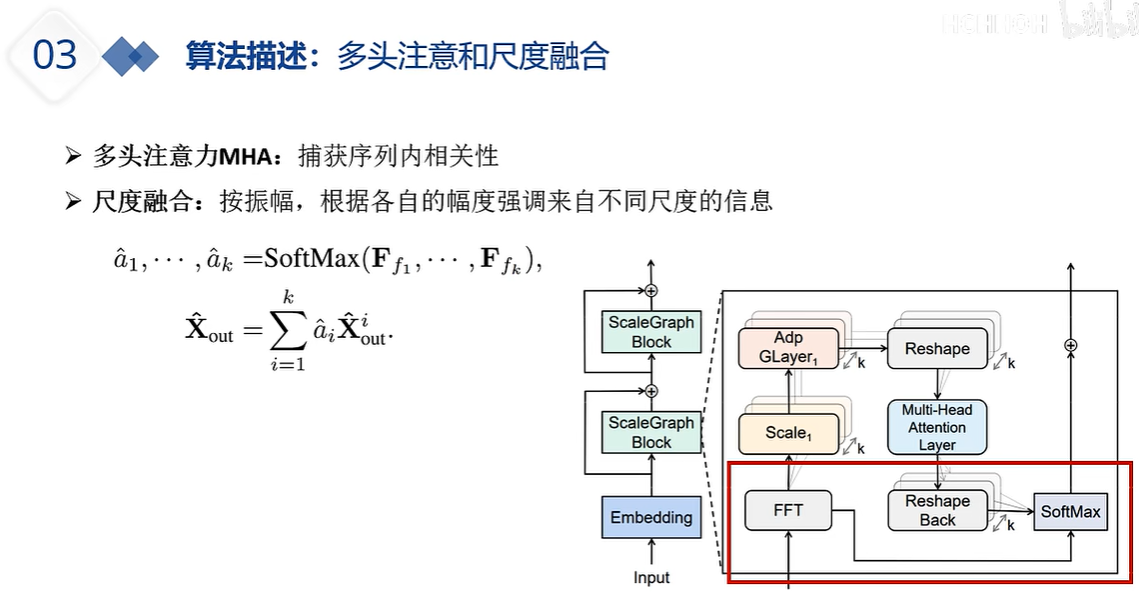
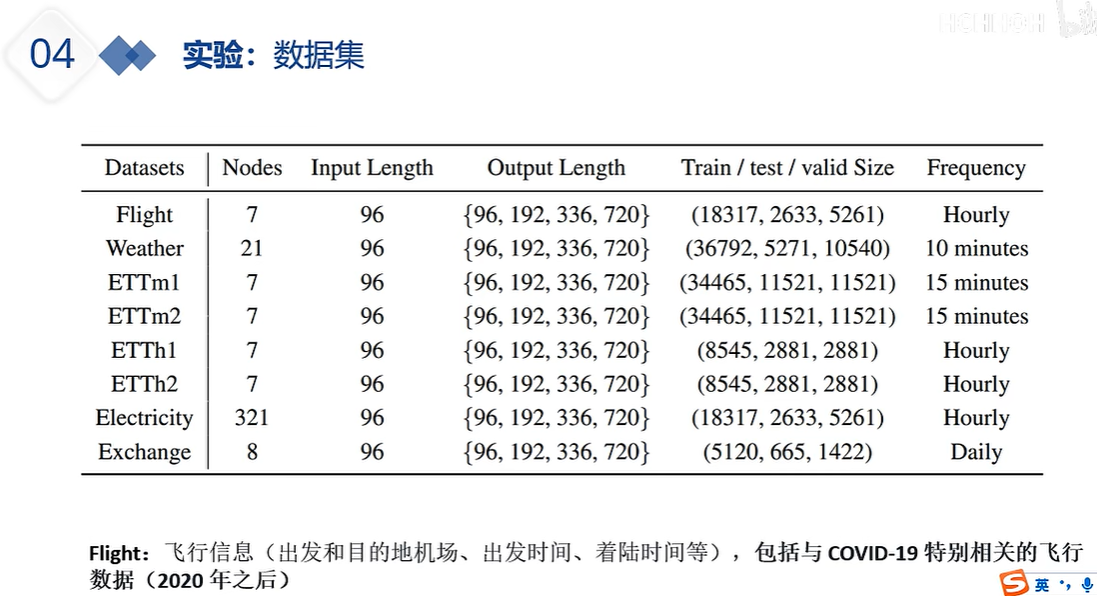
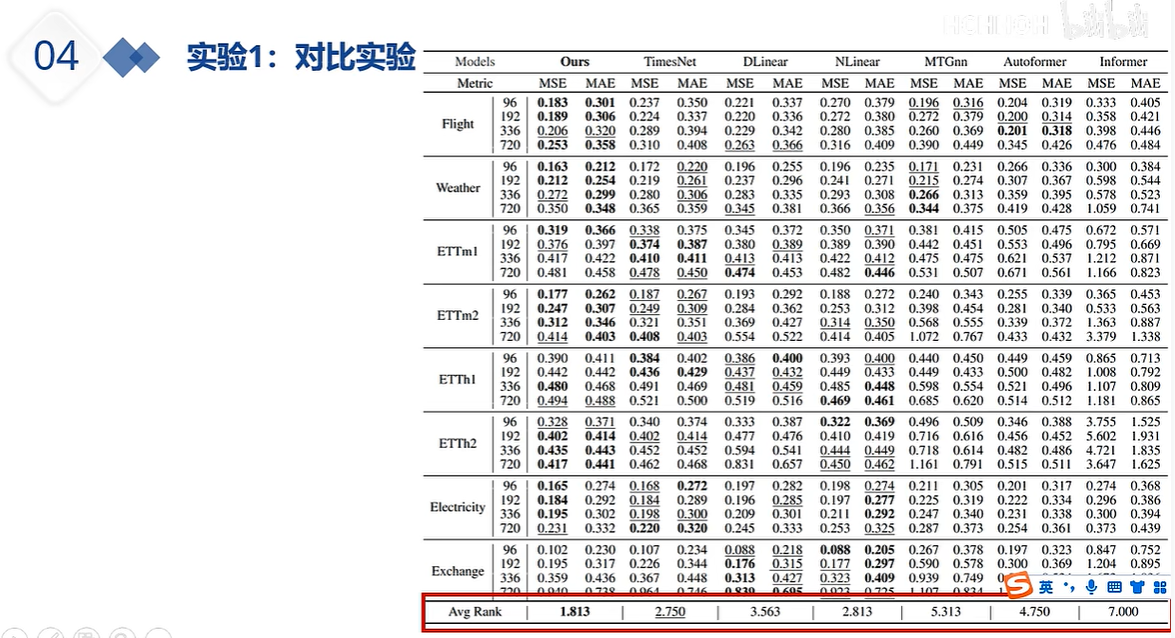
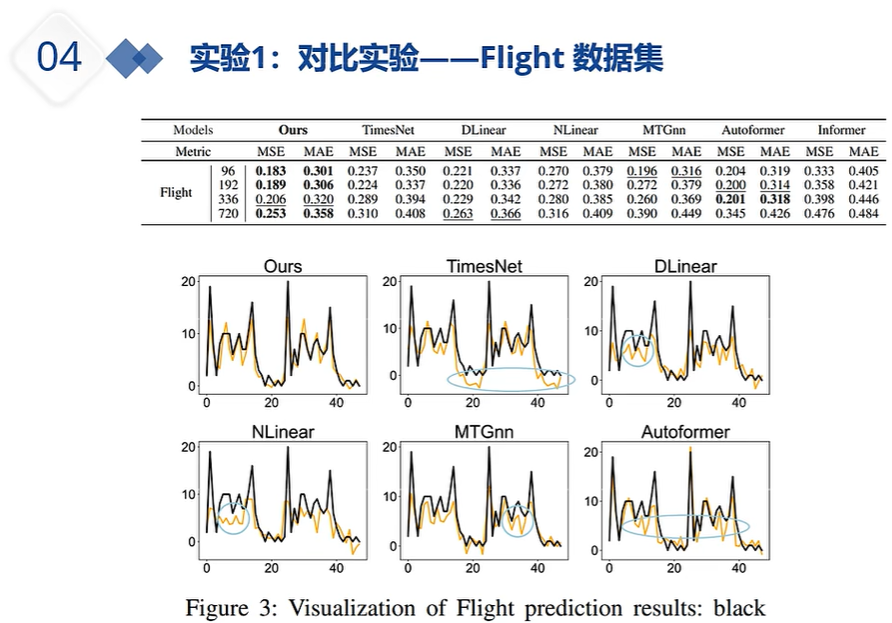

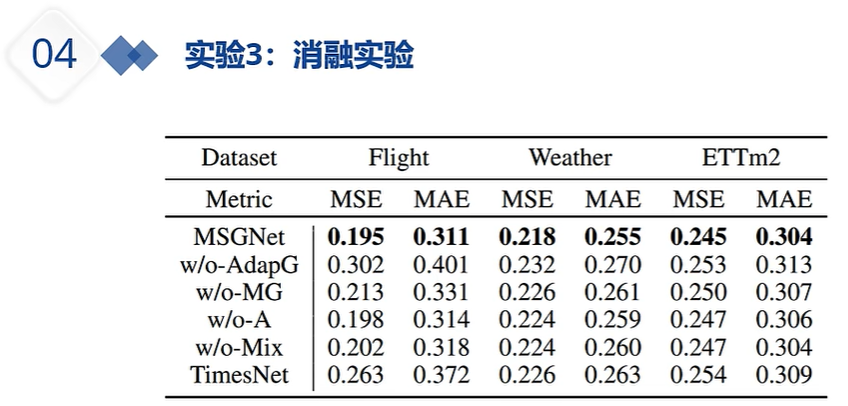
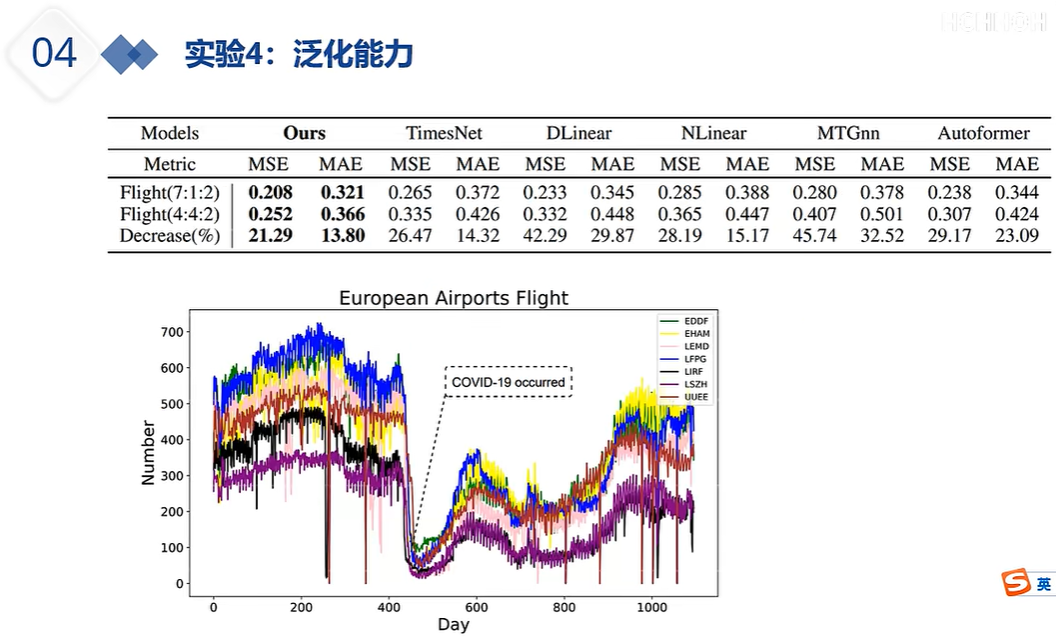
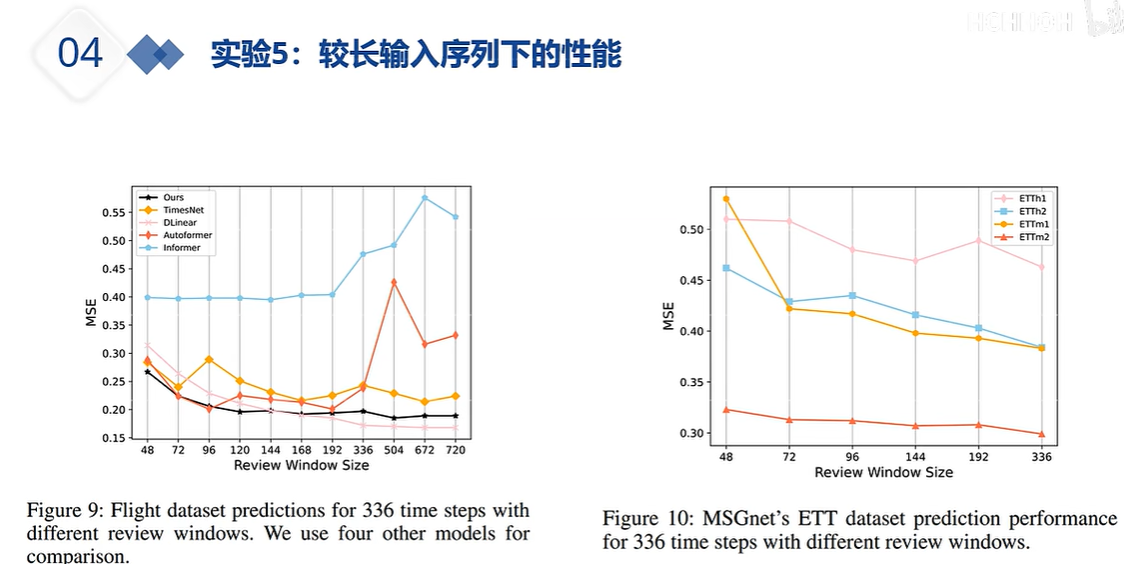
DLinear的出现就是为了质疑注意力机制系列的能力,注意力机制系列在预测时,如果输入的嗯史数据过长,那么其预测未来的性能会变差。
上图可以看出,随着历史数据窗口的增加,基于注意力机制的那些former系列模型,会随着输入历史数据的长度,效果逐渐变差,而黑色线段代表的作者的模型及Dlinear模型,都是逐渐变得效果更好。
上图中右图 则说在不同的数据集上,作者的模型随着历史数据的长度增加,预测效果变得更好。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。