参考:
全网最牛的注意力机制创新思维分析,看了立马提走一篇二区_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV15x4y1h7RX/?vd_source=3ad05e655a5ea14063a9fd1c0dcdee3e
2.2小节
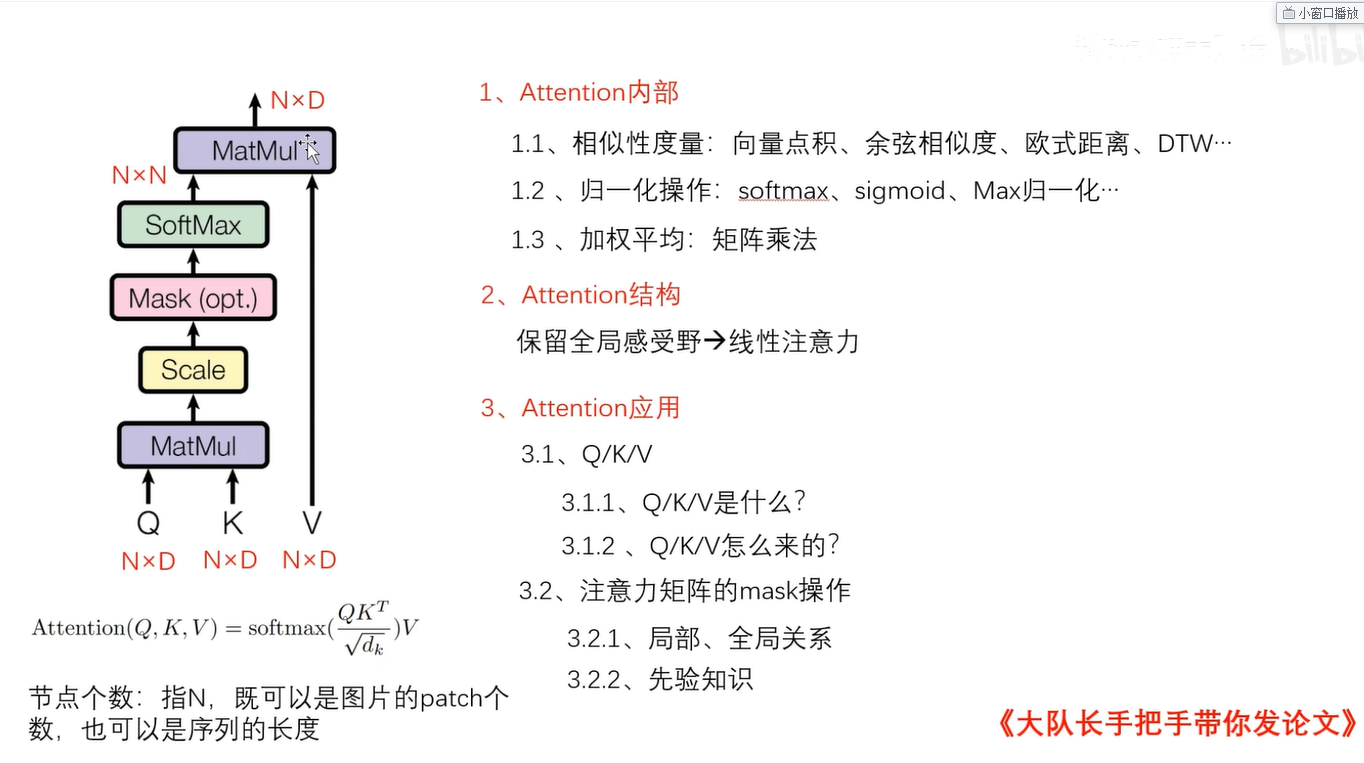
如上图所示,可以修改的方向主要有3个方向:
1. attention内部的改进:
attention首先接受q k v三个输入,通过矩阵乘法度量向量之间的相似性;除了点积能度量相似性之外,还有余弦相似度,欧式距离,皮尔逊相关系数来度量。根据你的数据类型还可以选择DTW等相关算法来替换掉,原始的点积操作运算。再或者你还可以自己构造一个度量函数。e.g. : α=sigmoid(MLP(a,b)),也即你可以通过一个全连接层MLP,把要建立相关性的a和b作为输入,然后后面再接一个sigmoid激活函数,这样的话,其结果α也可以被看作一个权重。当然,点积的效率是最高的,如果大家不缺那点计算资源,那么就可以按照此说法修改,修改后故事就可以多写一点了。三四区的审稿人会给你一个面子的。
同时,原始的点积得到注意力矩阵之后,应该通过softmax归一化权重表示,以把把它们拉到同一个量纲上面,避免过大或过小的权重值;同样归一化操作除了softmax,也可以通过sigmoid和max归一化等;sigmoid就是一个天然的权重生成器;当然上图1.2部分的归一化,并没有太多的创新价值,除非你能在你的任务上,通过实验或理论证明为什么你是用的不同的归一化方法 比softmax要好。这样才更好一些。
同样,softmax归一化权重之后,还要通过注意力权重矩阵对value矩阵进行加权,得到最终的输出;我们都知道,归一化的注意力矩阵是n*n的,与value矩阵进行一个矩阵乘法;第一行与第一列相乘更新第一个节点的第一个特征,第一行与第二列相乘来更新第一个节点的第二个特征,每一个特征的更行,都是对所有节点进行一个加权平均,而真实计算时速度很慢;可能一些微小的计算负担就能够影响模型在实际系统上的部署,为了降低部署负担,能否为每一个节点去学习一个权重表示;而预算中有N个节点,我们可以各位N个节点的每一个节点去学习一个权重。这样的话,注意力矩阵就不是N*N了,而是N*1,;这样不仅计算加权平均时计算负担小,而且很有可能计算注意力矩阵的一步时,也就不需要N*N的复杂度了,
2.attention结构的改进:
这方面主要对attention结构方面修改,我们都知道attention核心是加权平均,也即先有权重,然后再加权求和;它们的优点是拥有一个全局感受野;而对这一类的改进来说,权重的计算已经不是最重要的了,它们可能需要权重,也可能不需要权重;但是他们保丽龙attention依然具有全局感受野的一个优点;更新之后具有全局上下文表示,这是他们的特点;这一类主要以线性注意力为主,新手很难在此处改进创新,但是可以考虑把线性注意力迁移到自己任务上;个人感觉:换一个领域,换一个数据集,在保证性能的基础上,降低计算复杂度还是一个很好的切入点的。
3. attention应用的改进:
此处的改进上限很高,下限很低。下限低主要是指将attention直接应用到你的任务上,现在来看这种是比较low的,因为用的人太多了。那么attention引用有什么创新呢?需要注意的是attention接受的是qkv三个输入,那就说明其输入可以是多样化的,也即把其应用于任何一个不同的任务,其都具有不同的意义。所以思路有2:
3.1.1 我们要问一下,qkv是什么,qkv怎么来的?那么我们考虑到几乎所有的任务,都存在一个局部和全局特征(也即细粒度和粗粒度问题),那么我们可以定义K矩阵为局部特征或者全局特征表示,此时 q和K再相乘,就可以使得q矩阵拥有更大的感受野。再进一步,我们想要实现多尺度的任务表示,那么我们就可以考虑堆叠多个这样的注意力层,在任何一个不同的注意力层,我们都可以是的K矩阵具有不同的局部特征表示,而局部特征表示可以通过一个简单的卷积层来实现,这样的话,我们就能够使得模型具有一个多尺度的感受野,还能够降低计算复杂度,这个卷积操作不使用padding操作的话,长度会缩短,就会提高计算效率。同样,Q矩阵也可以具有局部特征表示。那么我们就可以保持k矩阵不变,通过卷积来提取q矩阵的一个局部特征表示,如此同样操作,堆叠具有多个不同感受野的注意力层,也能有提取多尺度的特征表示。最后将每个层的输出,通过一个上采样,恢复原有的shape大小,最后进行一个拼接、相加、加权求和都可以。
3.1.2 第二个改进思路 qkv是怎么来的?;K矩阵既可以是原始的输入,也可以是通过卷积层提取的局部特征表示;如果节点个数过多的话,不仅计算负担比较大;还有可能因为关注所有节点,而出现信息冗余的现象;那么我们就可以通过选择部分节点,(具体选择方法可以通过生成随机数或规律的去选择 e.g 规律的选择单数的 或 选复数的节点)具体如何选择根据你的喜欢来定;
3.2 第二个改进点则是注意力矩阵的mask操作,在你完成之后,你可以选择性的保留注意力矩阵中的某些值,选择性的过滤掉一些不重要的节点对之间的关系,也算一个不错的挺重要的创新。同样有两个点:
3.2.1 当我们的出发点是 是局部的、全局关系的时候,我们可以通过mask操作,为每一个节点保留局部或者是全局的其他相关性节点。局部 全局可以分开考虑。
3.2.2 通过你所做任务的一些先验知识来告诉你或者你从中挖掘到一些知识,来告诉你该保留或丢掉哪些节点对关系。也能够实现。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。