


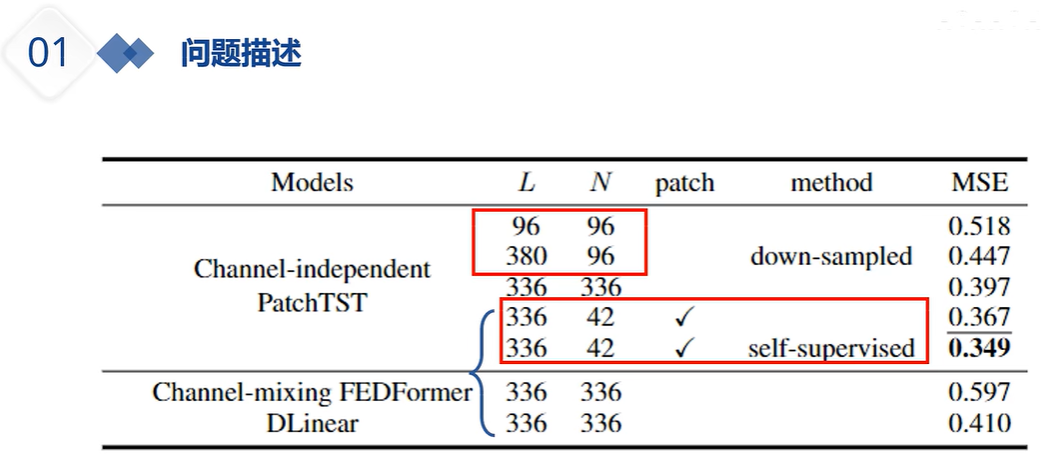
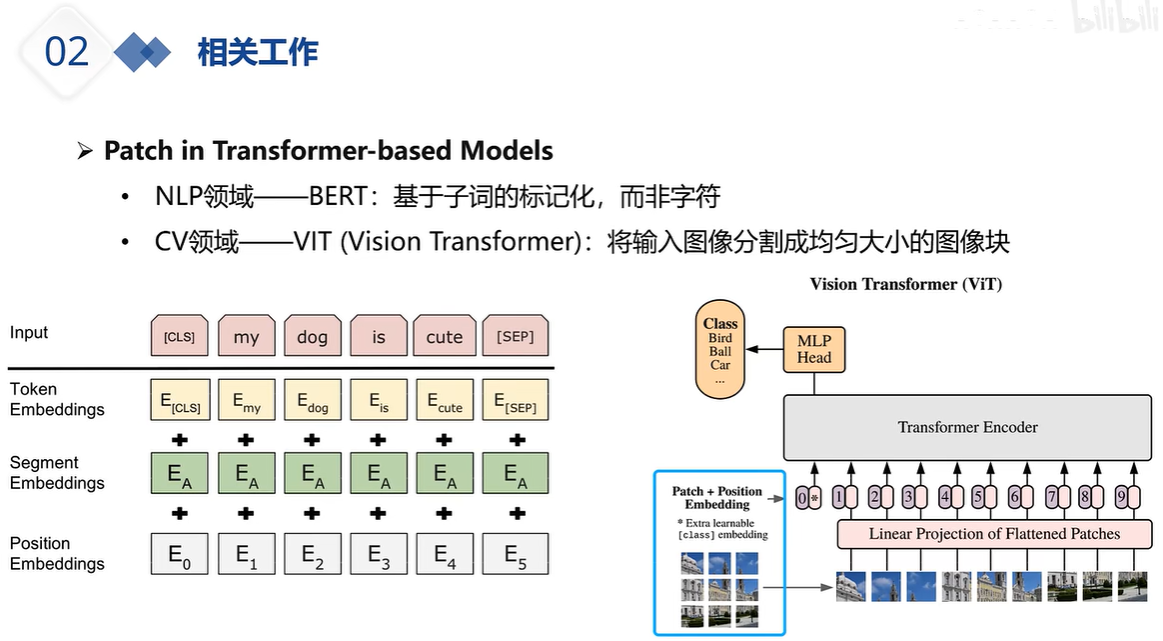
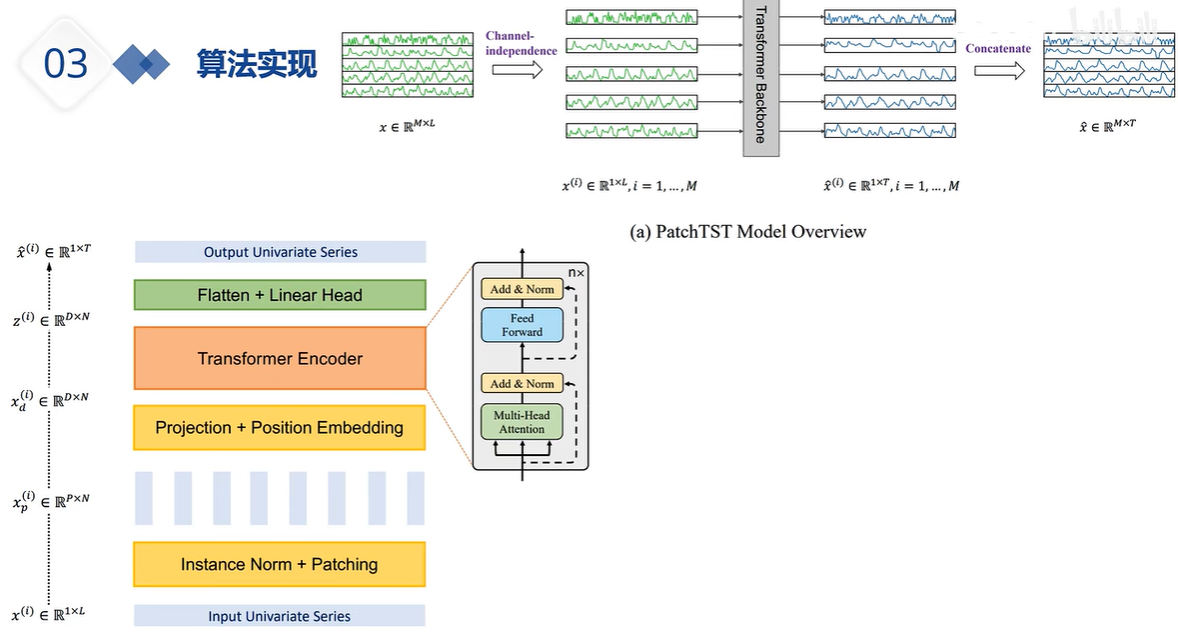

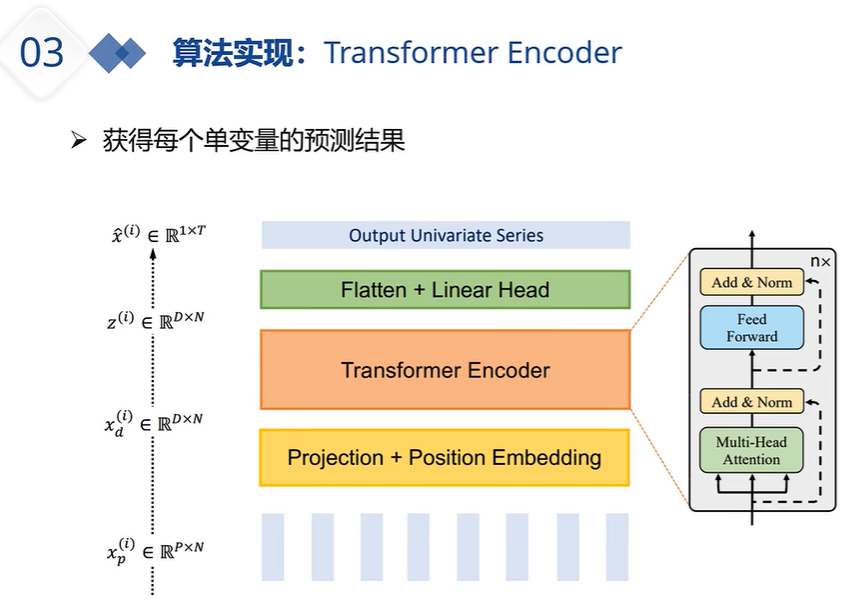
通道独立更大意义上是扩展数据集,提升模型泛化性能吧,也有几篇论文在讨论这个问题了。毕竟现在时序预测的一个瓶颈就是数据量上不去。
他指的这个通道说的就是特征,比如我有十四个特征不知道你有没有看过itansformer这篇文章,假如我的输入(32,96,14)这代表的是32个样本每个样本大小为96个历史长度,14个特征这样,通道独立说的就是进行一个转置(32,14,96)那么第一行代表的就是96个时间步的第一个特征,那么他做自注意力机制其实就是特征与特征,通道与通道之间做自注意力机制
而且他 每个通道共享 transformer权重啊 这能算通道独立吗?对特征之间相关性不大的数据,特征独立反而可以避免模型因为特征之间复杂的相互关系学习不到而降低性能。大佬,我想问一下,用多变量预测单变量,既然是独立通道,那么每个特征又是怎么影响输出的呢?
transformer权重啊 这能算通道独立吗?对特征之间相关性不大的数据,特征独立反而可以避免模型因为特征之间复杂的相互关系学习不到而降低性能。大佬,我想问一下,用多变量预测单变量,既然是独立通道,那么每个特征又是怎么影响输出的呢?
对数据patch处理后,数据点变成了数据段。这种情况下,数据输入到transformer前需要怎么处理呢,数据维度变了
时序former的输入一般是(B,L,F),数据维度本身也是考虑了步长的
我的理解是,虽然数据点变成了数据段,升了一维,但由于通道独立,每个变量单独地进trans,因此又降了一维,一升一降就抵消了
我看了代码,patch之后,维度成了四维。然后其中一个维度和batch合并了,维度又还是三维了
x: 【bs x nvars x patch_num x d_model】->u: 【bs * nvars x patch_num x d_model】,意思就是将变量个数nvars与batchsize乘到了一起,即nvars变成了与batchsize同一级的参数,这样一来自注意力就不能跨变量了,就如同朴素的Transformer中自注意力无法跨batch一样。
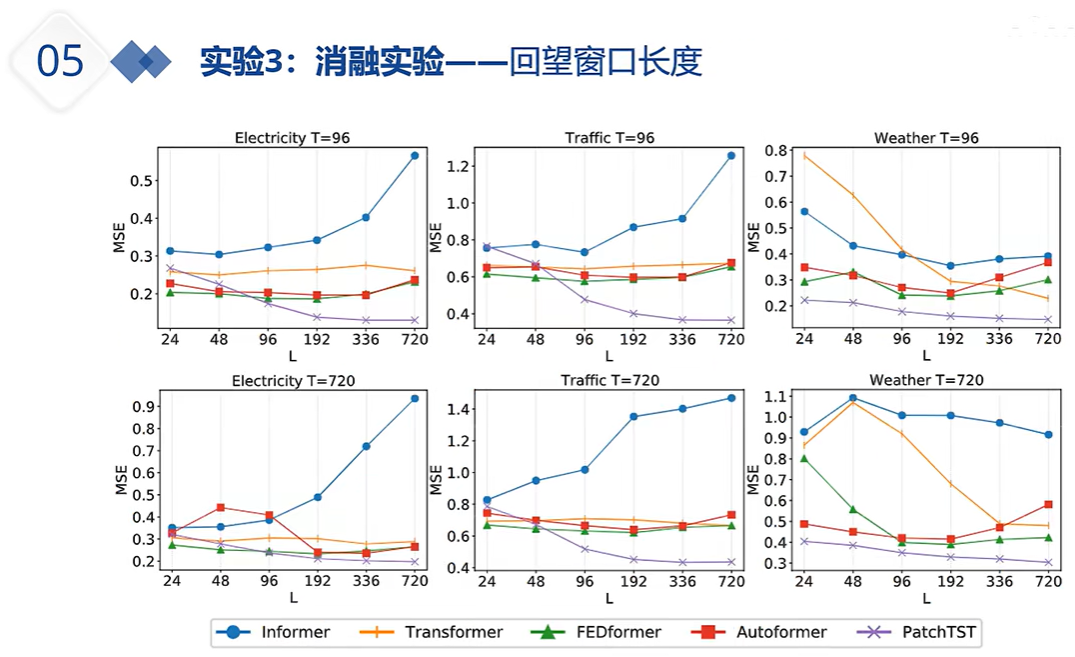
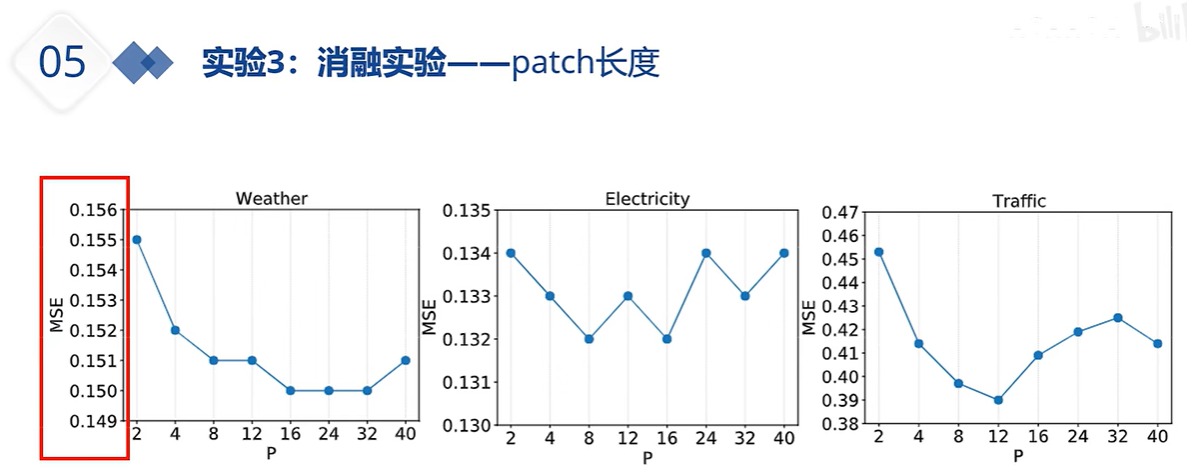
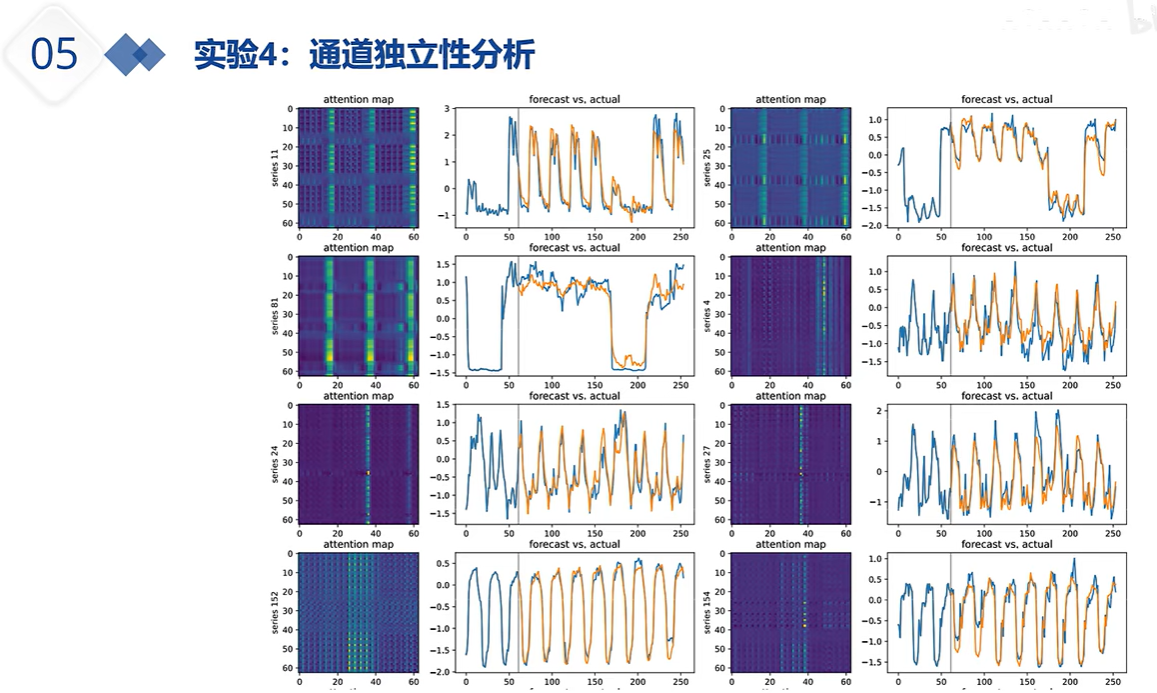
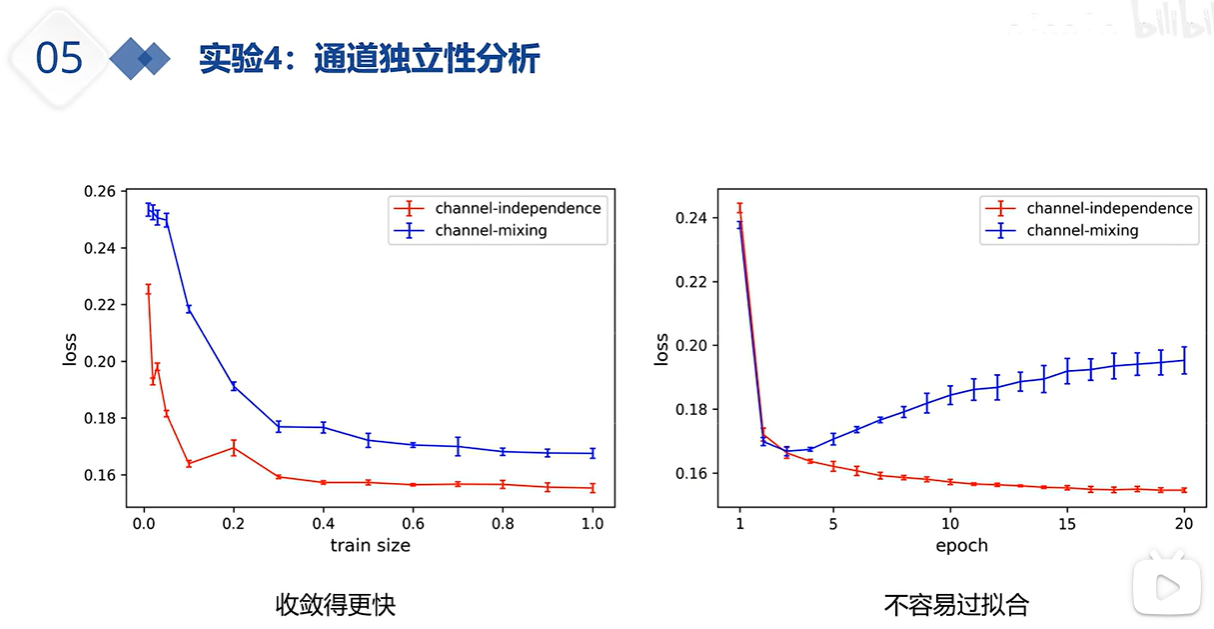
上图红线是通道独立 蓝线是通道混合;单通道 各个通道间的注意力相近,他们互现学习能让预测效果变得更好,但所有变量一起学习 可能学到的冗余错误信息比较多,导致最终预测效果变差。多通道信息混合从某种程度上说,影响/损害了注意力的效果;另一方面,独立的通道 或 通道独立能让模型个收敛的更快。切不容易过拟合。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。