1 初识GPT-4和ChatGTP
GPT-4 和其他 GPT 模型是基于⼤量数据训练⽽成的⼤语⾔模型 (large language model,LLM),它们能够以⾮常⾼的准确性识别和⽣成⼈类可读的⽂本。开发⼈员现在可以利⽤⾃然语⾔处理(natural language processing,NLP)技术创建应⽤程序。
1.1 LLM概述
1.1.1 探索语⾔模型和 NLP 的基础
人工智能。机器学习,深度学习,Transformer 之间的关系如下图所示。
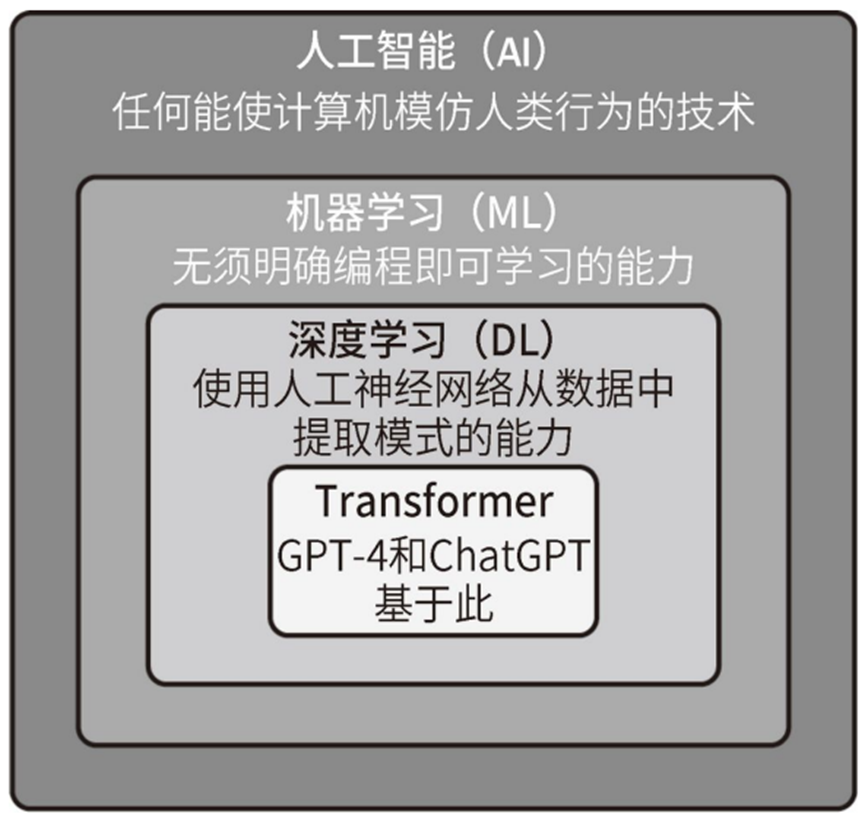
添加图片注释,不超过 140 字(可选)
GPT-4 和 ChatGPT 基于⼀种特定的神经⽹络架构,即Transformer。 Transformer 就像阅读机⼀样,它关注句⼦或段落的不同部分,以理解其上 下⽂并产⽣连贯的回答。此外,它还可以理解句⼦中的单词顺序和上下⽂ 意思。这使 Transformer 在语⾔翻译、问题回答和⽂本⽣成等任务中⾮常有效。
1.1.2 LLM原理
LLM 是试图完成⽂本⽣成任务的⼀类 ML 模型。LLM 使计算机 能够处理、解释和⽣成⼈类语⾔,从⽽提⾼⼈机交互效率。为了做到这⼀ 点,LLM 会分析⼤量⽂本数据或基于这些数据进⾏训练,从⽽学习句⼦中 各词之间的模式和关系。这个学习过程可以使⽤各种数据源,包括维基百 科、Reddit、成千上万本书,甚⾄互联⽹本⾝。在给定输⼊⽂本的情况下, 这个学习过程使得 LLM 能够预测最有可能出现的后续单词,从⽽⽣成对输⼊⽂本有意义的回应,因此它们可以直接执⾏⼤多数 NLP 任务, 如⽂本分类、⾃动翻译、问题回答、文本生成等。
1.1.3 LLM发展
LLM开始于简单的语⾔模型,如 n-gram,词频来根据前⾯的词预测句⼦中的下⼀个词,其预测结果是在训练⽂本中紧随前⾯的词出现的频率最⾼的词。为了提⾼ n-gram 模型的性能,⼈们引⼊了更先进的学习算法,包括循环神经⽹络(recurrent neural network,RNN)和⻓短期记忆(long short-term memory,LSTM)⽹络。能学习更⻓的序列,并且能够更好地分析上下⽂,但它们在处理⼤量数据时的效率欠佳;然后发展到tranfermer架构,最后到GPT;

添加图片注释,不超过 140 字(可选)
1.1.4 Transformer 架构及其在 LLM 中的作⽤
Transformer 架构解决之 前的 NLP 模型(如 RNN)的问题:很难处理⻓⽂本序列并记住其上下⽂。具备⾼效处理和编码上下⽂的能⼒。核⼼⽀柱是注意⼒机制:对文本中的词做相关性分类,在任务的每个步骤中关注最相关的词。交叉注意⼒和⾃注意⼒是基于注意⼒机制的两个架构模块;
(1)交叉注意⼒,输出文本时,关注输入文本中的关键词,忽略不重要的信息,预测输出文本中下一个单词,输出和关键词相关性高的文本;例如翻译Alice enjoyed the sunny weather in Brussels的时候,关注sunny weather;
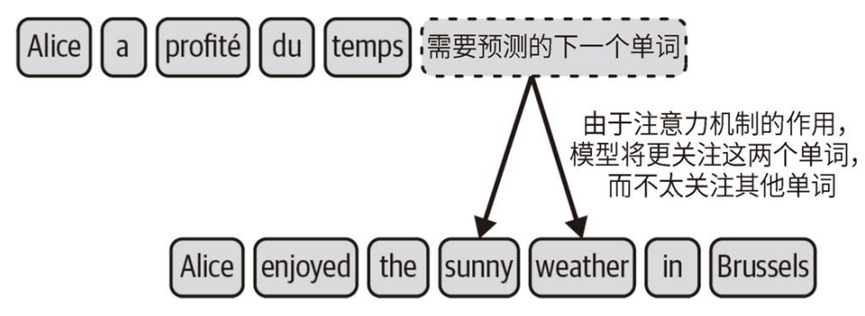
添加图片注释,不超过 140 字(可选)
(2)⾃注意⼒机制,使模型能够评估句⼦中的每个词相⽐于其他词的重要性。这使得模型能够更好地理解各词之间的关系。并根据输⼊⽂本中的多个词构建新词。例如Alice received praise from her colleagues,要理解 her 这个单词,⾃注意⼒机制给句⼦中的Alice和colleagues分配更多的权重,也可以组成新词Alice's colleagues;
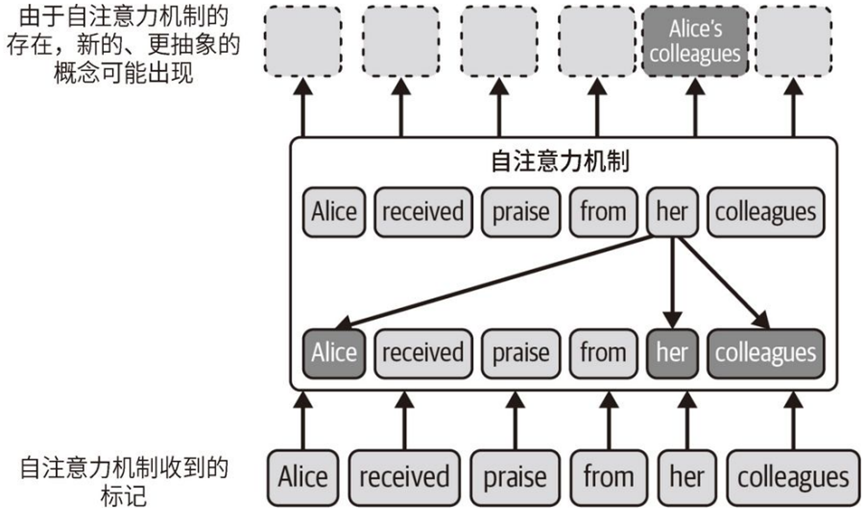
添加图片注释,不超过 140 字(可选)
Transformer 架构具有易于并⾏化的优势。这意味着 Transformer 架构可以同时处理输⼊⽂本的多个部分,⽽⽆须顺序处理。这 样做可以提⾼计算速度和训练速度,Transformer架构和图形处理单元(graphics processing unit,GPU)的架构完美契合,非常适合用于训练;
1.1.5 Transformer主要组件编码器和解码器
标准的 Transformer 架构有两个主要组件:编码器和解码器,两者都⼗分依赖注意⼒机制。
(1)编码器的任务是处理输⼊⽂本,识别有价值的特征,并⽣成有意义的⽂本表⽰,称为嵌⼊(embedding)。
(2)解码器使⽤这个嵌⼊来⽣成⼀个输出,⽐如翻译结果或摘要⽂本。这个输出有效地解释了编码信息;
(Generative Pre-trained Transformer,GPT)是 ⼀类基于 Transformer 架构的模型,专门利⽤解码器部分,不存在编码器,因此⽆须通过交叉注意⼒机制来整合编码器产⽣的嵌⼊。仅依赖解码器内部的⾃注意⼒机制来⽣成上下⽂感知的表⽰和预测结果。
1.1.6 GPT 模型的标记化和预测步骤
(1)文本补全:GPT 模型接收⼀段提⽰词作为输⼊,然后⽣成⼀段⽂本作为输出。举例来说,提⽰词可以是 The weather is nice today, so I decided to(今天天⽓很好,所以我决定),模型的输出则可能是 go for a walk(去散步)。
(2)标记(token):GPT 模型收到⼀段提⽰词之后,分词器⾸先将输⼊拆分成标记(token)。这些标记可以是单词、单词的⼀部分、空格或标点符号。⽐如,在前⾯的例⼦中拆分成[The, wea, ther, is, nice, today,,, so, I, de, ci, ded,to]。
LLM 根据提⽰词的上下⽂预测最有可能出现的下⼀个标记,上下⽂作为⼀个整体来考虑。基于这个上下⽂,模型为每个潜在的后续标记分配⼀个概率分数,然后选择概率最⾼的标记作为序列中的下⼀个标记。GTP模型的预测推理步骤如下图所示:
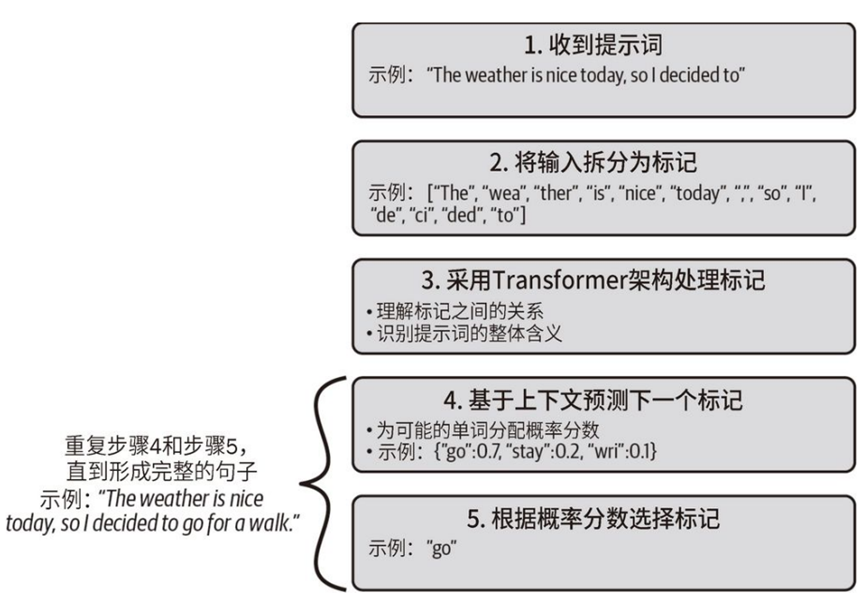
添加图片注释,不超过 140 字(可选)
1.2 GPT模型发展
在 GPT-1 出现之前,构建⾼性能 NLP 神经⽹络的常⽤⽅法是利⽤监督学
习。这种学习技术使⽤⼤量的⼿动标记数据,难度⼤成本⾼。
1.2.1 GPT-1
GPT-1引⼊了⽆监督的预训练步骤。这个预训练步骤不需要标记数据。通过训练模型来预测下⼀个标记。预训练步骤是在⼤量数据上进⾏的,使⽤了 BookCorpus 数据集。缺点是⼩模型,它⽆法在不经过微调的情况下执⾏复杂任务。需要⽤少量⼿动标记的数据(二次监督学习)进⾏微调后;具有1.17 亿个参数;
1.2.2 GPT-2
2019 年初提出了 GPT-2。其参数量和训练数据集的规模⼤约是 GPT-1 的 10 倍。参数量为 15 亿,训练⽂本为 40 GB。这使⽤更⼤的数据集训练更⼤的语⾔模型可以提⾼语⾔模型的任务处理能⼒,并使其在许多任务中能够更好地处理⾃然语⾔。
1.2.3 GPT-3
OpenAI 发布了 GPT-3。GPT-2 和 GPT-3 之间的主要区别在于模型的⼤⼩和⽤于训练的数据量。它有 1750 亿个参数,这使其能够捕捉更复杂的模式。数据集上包括 Common Crawl(它就像互联⽹档案馆,其中包含来⾃数⼗亿个⽹⻚的⽂本)和维基百科。这个训练数据集包括来⾃⽹站、书籍和⽂章的内容。在⽂本⽣成⽅⾯还展⽰出更强的连贯性和创造⼒,性能更强。此外,GPT-3 取消了微调步骤。
(1)任务理解不一致,是最终⽤户提供的任务与模型在训练过程中所 ⻅到的任务不⼀致。
(2)说错话说坏话说假话,⽐如涉及种族歧视、性别歧视等。训练数据来源于网络;
1.2.4 InstructGPT
InstructGPT 模型的训练过程主要有两个阶段:
(1)监督微调 (supervised fine-tuning,SFT),人类标记员从提⽰词数据集中随机抽样,给出相应的理想回答,用数千个提示词和回答组成的训练集去微调GPT-3;
(2)训练奖励模型 (reinforcement learning from human feedback,RLHF)。训练奖励模型⾃动给SFT模型的回答给出评分排序,得出能判断模型输出符合程度的评估模型;
(3)使⽤奖励模型进⾏强化学习。强化学习是⼀个迭代的过程,SFT初始模型输出结果,奖励模型评分,根据得到的奖励分数,相应地更新⽣成式模型,然后循环往复。
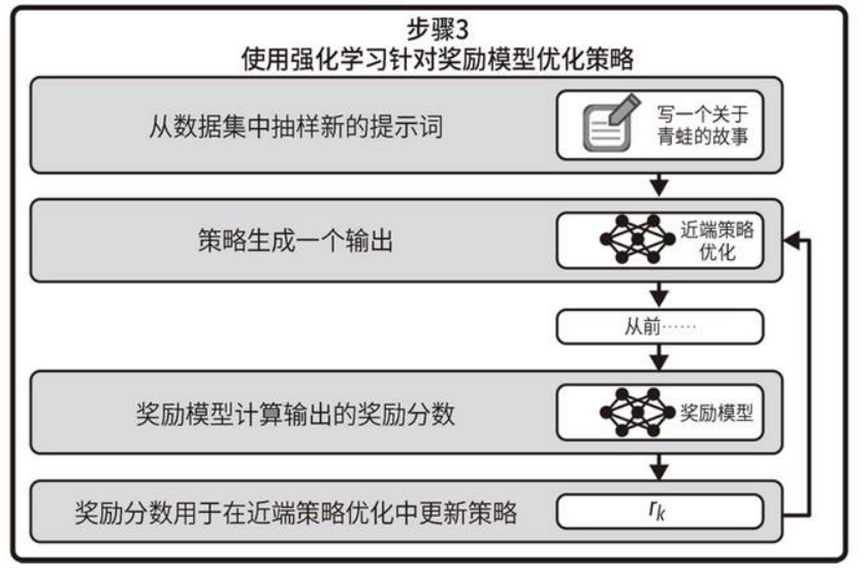
添加图片注释,不超过 140 字(可选)
1.2.5 GTP-3.5
提出了 Codex 模型,这是⼀个在数⼗亿⾏代码上进⾏了微调的 GPT-3 模型。正是它给 GitHub Copilot 这款⾃动化编程⼯具赋予了强⼤的能⼒,为使⽤ Visual Studio Code、JetBrains 甚⾄ Neovim 等许多⽂本编辑器的 开发⼈员提供了帮助。
1.2.6 GPT-4
GPT-4 是第⼀个能够同时接收⽂本 和图像的多模态模型。
1.3 LLM应用
1.4 AI幻觉
AI ⾃信地给出⼀个回答,但是这个回答是错误的,或者涉及虚构的信息。例如计算数学题目,如果没有工具调用,GTP并不会计算,它只是根据训练的样本预测输出的结果;不能精确计算;OpenAI 已经为 GPT-4 引⼊了插件功能,包括计算器,它可以帮助 GPT 正确回答数学问题。所以在创意型应⽤程序中使⽤纯 GPT 解决⽅案,⽽不是在医疗咨询⼯具等真相⾄关重要的问答类应⽤程序中使⽤。
1.5 使⽤插件和微调优化 GPT 模型
插件:它没有直接访问互联⽹的权限,这意味着 GPT 模型⽆法获取新信息,其知识仅限于训练数据。GTP可以调用插件的对外API接口,获取更多的能力;
微调:用额外的训练数据训练现有模型, 调节其内部参数,以适应特定的任务。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。