大模型(Large Model)通常指的是具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。
规模庞大:大模型包含数十亿个参数,模型大小可以达到数百GB甚至更大。
深度神经网络:大模型通常基于深度神经网络,如卷积神经网络(CNN)、循环神经网络(RNN)或Transformer模型。
强大的表达能力和学习能力:大模型能够处理和生成复杂的数据,如自然语言、图像和音频。
广泛的应用领域:大模型在多个领域得到广泛应用,包括自然语言处理(NLP)、计算机视觉(CV)、语音识别等。
需要大量数据:大模型的训练需要大量的数据和计算资源。
BERT:一种用于自然语言处理的大规模预训练语言模型。
GPT-3:一种能够生成文本、代码、翻译等多种内容的大规模语言模型。
T5:一种基于Transformer的文本到文本的转换模型。
学习大模型之前需要具备下面的基础知识,学习起来才不会吃力
线性代数:这是理解许多算法(特别是深度学习算法)的关键。主要概念包括向量、矩阵、行列式、特征值和特征向量、向量空间以及线性变换。
微积分:许多机器学习算法涉及到连续函数的优化,这需要理解导数、积分、极限和级数。多变量微积分以及梯度的概念也很重要。
概率论与统计学:这些知识对于理解模型如何从数据中学习并进行预测至关重要。主要概念包括概率理论、随机变量、概率分布、期望、方差、协方差、相关性、假设检验、置信区间、最大似然估计和贝叶斯推断。
大模型需要掌握Python,它 是一种强大且灵活的编程语言,因其可读性、一致性和强大的数据科学库生态系统而特别适合机器学习。
Python 基础:掌握 Python 编程需要理解基本语法、数据类型、错误处理和面向对象编程。
数据科学库:包括熟悉 NumPy 用于数值计算,Pandas 用于数据操作和分析,以及 Matplotlib 和 Seaborn 用于数据可视化。
数据预处理:这包括特征缩放和标准化、处理缺失数据、异常值检测、分类数据编码,以及将数据划分为训练集、验证集和测试集。
机器学习库:熟练使用 Scikit-learn 是至关重要的,这个库提供了广泛的有监督和无监督学习算法。理解如何实现线性回归、逻辑回归、决策树、随机森林、K 最近邻(K-NN)和 K-means 聚类等算法也很重要。主成分分析(PCA)和 t-SNE 等降维技术对可视化高维数据也非常有帮助。
神经网络是许多机器学习模型的基础,特别是在深度学习领域。要有效利用神经网络,需要全面理解其设计和机制。
基础知识:包括理解神经网络的结构,如层、权重、偏置以及激活函数(如 sigmoid、tanh、ReLU 等)。
训练和优化:熟悉反向传播算法以及不同类型的损失函数,如均方误差(MSE)和交叉熵。理解各种优化算法,如梯度下降、随机梯度下降、RMSprop 和 Adam。
过拟合:了解过拟合的概念(即模型在训练数据上表现良好但在未见过的数据上表现较差),各种正则化技术(如 dropout、L1/L2 正则化、提前停止、数据增强)以防止过拟合。
实现多层感知机(MLP):构建一个多层感知机,也称为全连接网络。
自然语言处理(NLP)是人工智能的一个迷人领域,它弥合了人类语言与机器理解之间的差距。从简单的文本处理到理解语言细微差别,NLP 在翻译、情感分析、聊天机器人等许多应用中扮演了关键角色。
文本预处理:学习各种文本预处理步骤,如分词(将文本拆分为单词或句子)、词干提取(将单词还原为其根形)、词形还原(类似于词干提取,但考虑上下文)、停用词去除等。
特征提取技术:熟悉将文本数据转换为机器学习算法可以理解的格式的方法。关键方法包括词袋模型(BoW)、词频-逆文档频率(TF-IDF)和 n-grams。
词嵌入:词嵌入是一种词语表示方法,它允许具有相似含义的词具有相似的表示。关键方法包括 Word2Vec、GloVe 和 FastText。
递归神经网络(RNNs):理解 RNNs 的工作原理,这是一种设计用于处理序列数据的神经网络。探索 LSTM 和 GRU,这两种 RNN 变体能够学习长期依赖关系。
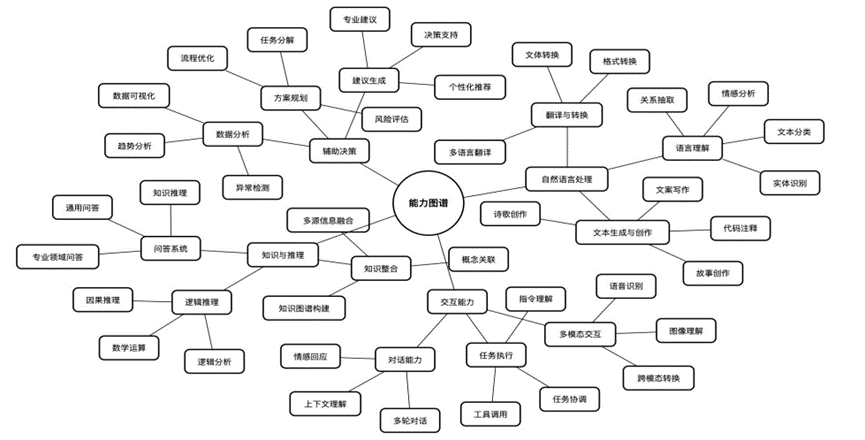
大模型功能有文本创作,摘要改写,代码编写,逻辑推理,分类,语义识别等。直接面向用户或者支持开发者,提供智能对话、文本生成、语义理解、计算推理、代码生成补全等应用场景, 支持联网搜索与深度思考模式,同时支持文件上传,能够扫描读取各类文件及图片中的文字内容。
添加图片注释,不超过 140 字(可选)
推理大模型: 推理大模型是指能够在传统的大语言模型基础上,强化推理、逻辑分析和决策能力的模型。它 们通常具备额外的技术,比如强化学习、神经符号推理、元学习等,来增强其推理和问题解决能力。
非推理大模型: 适用于大多数任务,非推理大模型一般侧重于语言生成、上下文理解和自然语言处理,而不强 调深度推理能力。此类模型通常通过对大量文本数据的训练,掌握语言规律并能够生成合适的内容,但缺乏像 推理模型那样复杂的推理和决策能力;

添加图片注释,不超过 140 字(可选)
推理模型更适合一些逻辑性强,创造性强,复杂度高,深度很深的任务,逐步推理问题的每个步骤来得到答案;常用模型这是范围更广,适合目标明确,相对简单,依据已有算法和大量的数据训练来快速预测可能的答案;
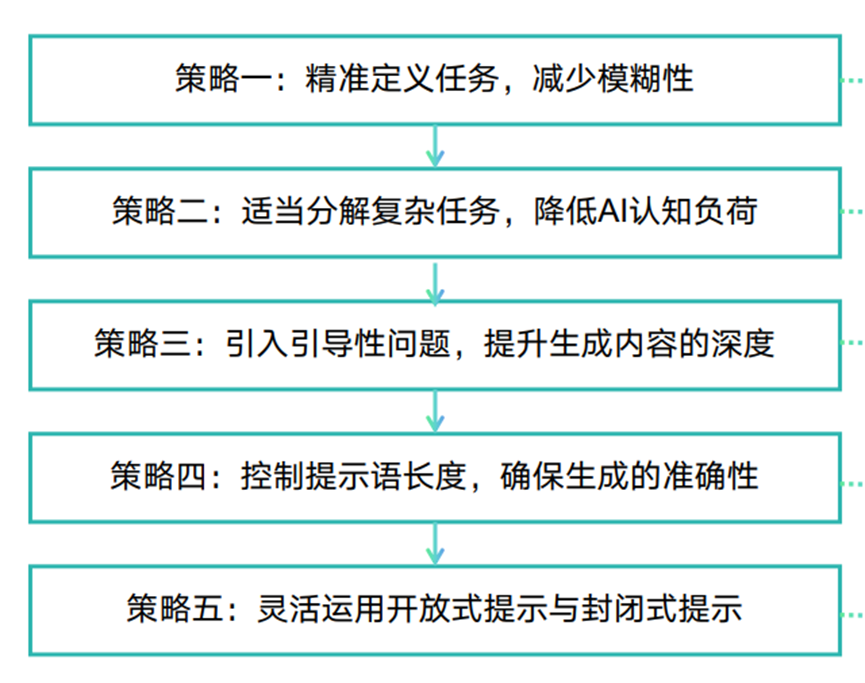
提示语的基本元素可以根据其功能和作用分为三个大类:信息类元素、结构类元素和控制类元素:
(1)信息类元素:决定了AI在生成过程中需要处理的具体内 容,包括主题、背景、数据等,为AI提供了必要的知 识和上下文;
(2)结构类元素:用于定义生成内容的组织形式和呈现方式, 决定了AI输出的结构、格式和风格。
添加图片注释,不超过 140 字(可选)
(3)控制类元素:用于管理和引导AI的生成过程,确保输出 符合预期并能够进行必要的调整,是实现高级提示语 工程的重要工具;
• Token 数量限制:目前,LLM通常具有 4K、8K、16K、32K和 128K等最大 Token 数量限制。当处理大量文本数据时,直接调用LLM 的API 可能会导致 Token 数量超出限制的错误。 这种限制影响了 LLM 处理长文本或大规模数据集的能力,需要相应的策略来优化或规避。
• 实时更新问题:这是LLM 面临的一个重大挑战。由于LLM 本身无法通过网络实时获取新信息,这可能导致在数据信息过时后 LLM 的准确性和实用性受到影响。因此,解决实时更新问题对提升 LLM 的性能来说至关重要。
• 短期记忆问题:LLM 存在短期记忆问题,即当处理的数据量超过其 Token 数量限制时,LLM可能会遗忘之前学到的知识,进而导致性能下降。
•安全、隐私和社会问题:LLM 存在安全、隐私和社会方面的潜在风险。LLM 在处理数据时可能会泄露敏感信息,或者被用于实现不当目的,从而引发关于隐私保护、系统安全、社会公平和道德责任等的诸多问题。为确保 LLM 的合规性和社会可接受性,需要加强对这些方面的关注和监管。
•法律和道德问题:随着 LLM 在各领域的广泛应用,如何制定合适的法规和道德准则,以确保其使用既合理又安全,同时维护社会公平,已成为一个亟待解决的重要议题。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。