分析日期:2026-06-01
项目地址:https://github.com/harry0703/MoneyPrinterTurbo
最新版本:v1.2.9(2026-05-30)
开源协议:MIT License
MoneyPrinterTurbo 是一个基于 AI 大模型的全自动短视频生成工具。只需提供一个视频主题或关键词,即可全自动完成以下工作流程:
项目采用完整的 MVC 架构,代码结构清晰,同时提供 Web 界面(Streamlit)和 API 接口(FastAPI)两种使用方式。
| 类型 | 地址 |
|---|---|
| GitHub 仓库 | https://github.com/harry0703/MoneyPrinterTurbo |
| 在线使用(中文) | https://reccloud.cn(录咖平台,基于该项目) |
| 在线使用(英文) | https://reccloud.com |
| API 文档(本地) | http://127.0.0.1:8080/docs(Swagger) |
| WebUI(本地) | http://127.0.0.1:8501(Streamlit) |
注:项目没有独立官网,录咖平台是基于该项目的免费在线版。
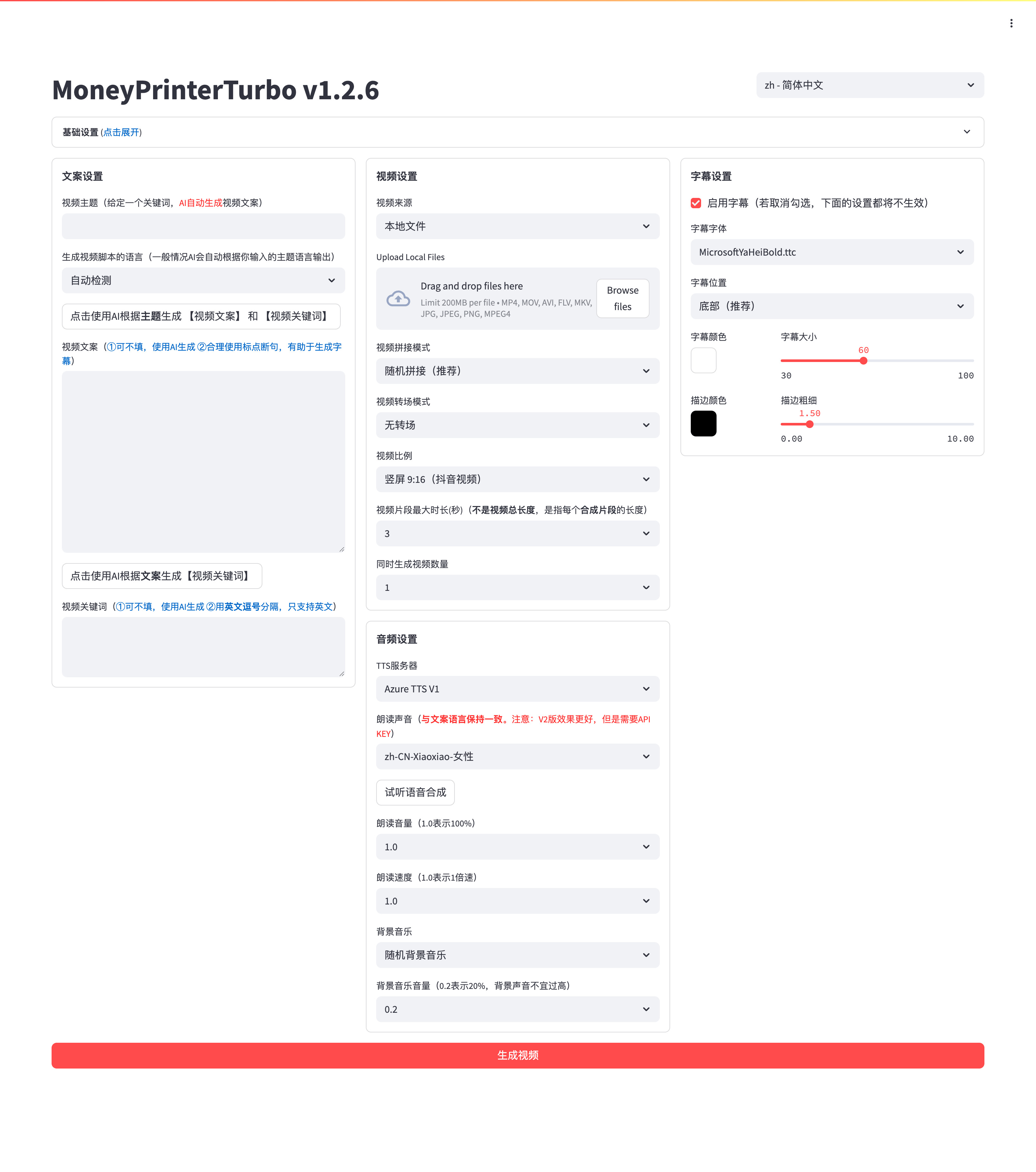
WebUI 界面:
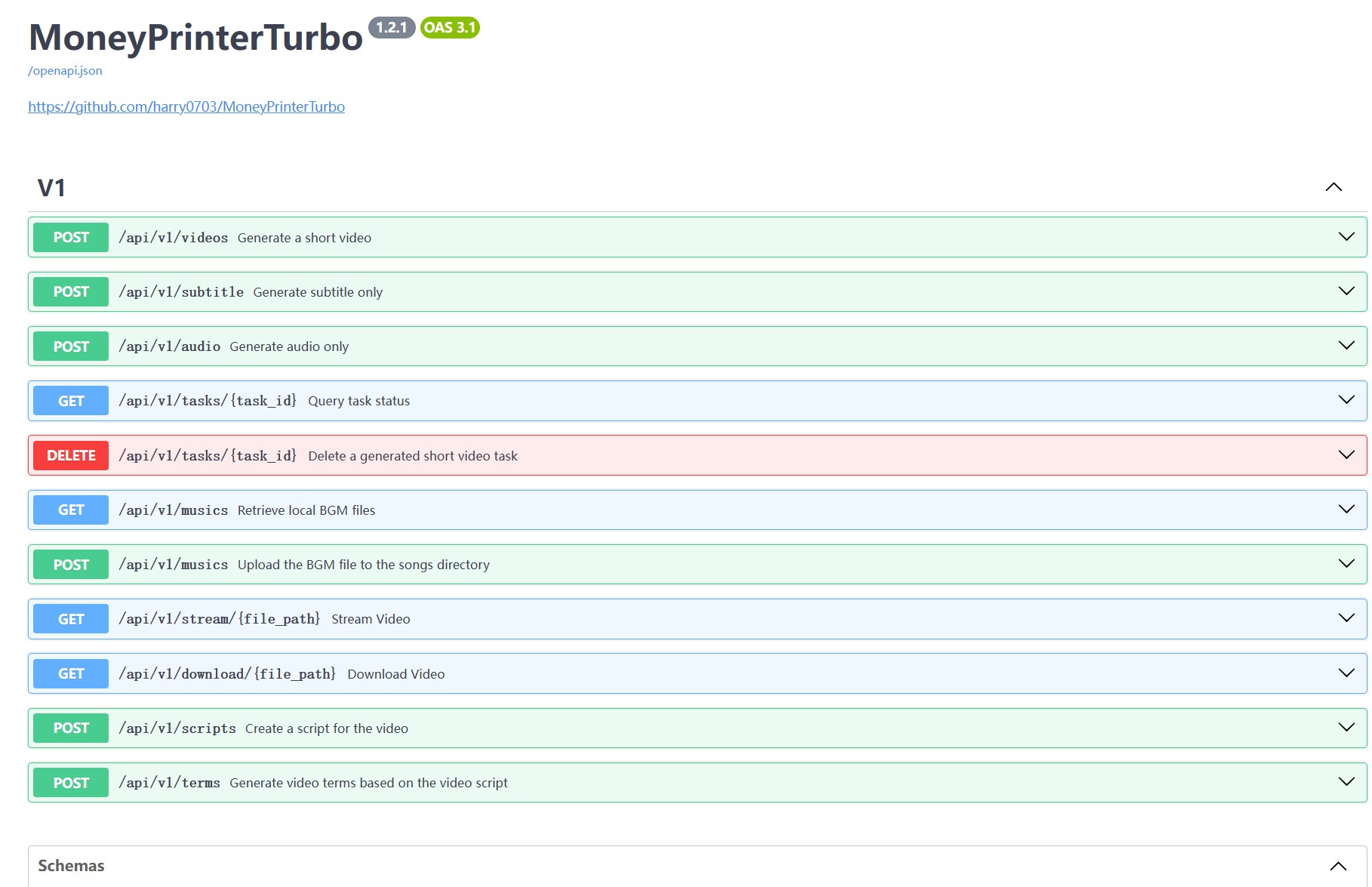
API 文档界面:
演示视频:
| 主题 | 格式 | 链接 |
|---|---|---|
| 《如何增加生活的乐趣》 | 竖屏 9:16 | GitHub 仓库 docs/ 目录 |
| 《金钱的作用》 | 竖屏 9:16 | 同上 |
| 《生命的意义是什么》 | 竖屏/横屏 | 同上 |
| 《为什么要运动》 | 横屏 16:9 | 同上 |
外部演示:
从文案生成到视频合成,真正实现"一键出片"。用户只需输入主题关键词,系统自动完成脚本编写、素材搜索下载、语音合成、字幕生成、视频拼接与合成全流程。
支持 OpenAI、Azure、Google Gemini、DeepSeek、通义千问、Moonshot(Kimi)、Ollama(本地部署)、MiniMax、文心一言、Cloudflare Workers AI、ModelScope、LiteLLM(100+ 模型网关)、Pollinations(免费)、Grok/xAI、OneAPI、g4f 等多达 16 种 LLM 提供商,通过配置文件一键切换。
支持 5 种 TTS 引擎:
一次任务可生成多个视频(video_count 参数),每个视频使用不同的素材排列组合,用户可选择最满意的版本。
| 部署方式 | 说明 |
|---|---|
| Windows 一键启动包 | 下载解压后运行 start.bat |
| Docker | docker-compose up |
| 手动部署 | uv sync + 安装 ImageMagick |
| Google Colab | 浏览器中直接运行,免本地部署 |
支持 Upload-Post 自动发布到 TikTok / Instagram(需配置 API Key)。
TOML 格式配置文件,支持:
stop_at 参数支持在任意步骤停止(script/terms/audio/subtitle/materials/video),便于调试和分步调用 API。
| 项目 | 最低配置 | 推荐配置 | 理想配置 |
|---|---|---|---|
| 操作系统 | Windows 10 / macOS 11.0 / Ubuntu 20.04 | 同左 | 同左 |
| Python | 3.11 | 3.11 | 3.11(不支持 3.13+) |
| CPU | 4 核 | 6-8 核 | 8 核及以上 |
| 内存 | 4 GB | 8 GB | 16 GB 及以上 |
| GPU | 非必须 | 4 GB 显存 | 8 GB 显存(Whisper 加速) |
| 磁盘 | 2 GB(程序+依赖) | 5 GB | 10 GB+(素材缓存) |
GPU 非必需。如果主要依赖云端 LLM/TTS 和在线素材,CPU 和内存比 GPU 更重要。GPU 主要加速本地 Whisper 语音识别。
| 工具 | 用途 | 安装方式 |
|---|---|---|
| ImageMagick | 字幕图片渲染(必须) | 官网下载 或 winget install ImageMagick.ImageMagick |
| FFmpeg | 视频处理(通常自动下载) | 项目启动时自动检测,也可手动安装 |
| uv | Python 包管理器(推荐) | pip install uv 或 winget install astral-sh.uv |
| 包名 | 用途 |
|---|---|
moviepy (2.1.2) |
视频编辑和合成 |
streamlit (1.45.0) |
Web UI 框架 |
edge_tts (7.2.7) |
微软 Edge 语音合成 |
fastapi (0.115.6) |
API 框架 |
uvicorn (0.32.1) |
ASGI 服务器 |
openai (1.56.1) |
OpenAI API 客户端 |
faster-whisper (1.1.0) |
语音识别/字幕生成 |
loguru (0.7.3) |
日志管理 |
pydub (0.25.1) |
音频处理 |
litellm (1.60.0) |
多 LLM 提供商统一接口 |
redis (5.2.0) |
Redis 状态管理(可选) |
| API Key | 用途 | 获取方式 |
|---|---|---|
| LLM API Key | 文案生成(至少选一个) | OpenAI / DeepSeek / 通义千问 等 |
| 素材 API Key | 视频素材搜索下载 | Pexels 或 Pixabay |
如果使用 Ollama 本地 LLM,则不需要 LLM API Key。如果使用本地素材,则不需要素材 API Key。
# 1. 克隆项目
git clone https://github.com/harry0703/MoneyPrinterTurbo.git
cd MoneyPrinterTurbo
# 2. 安装依赖
uv sync --frozen
# 3. 复制并编辑配置文件
cp config.example.toml config.toml
# 编辑 config.toml,填入 API Key 和 ImageMagick 路径
# 4. 启动 Web UI
# Windows:
webui.bat
# Linux/Mac:
sh webui.sh
# 或启动 API 服务
uv run python main.py
MoneyPrinterTurbo/
├── main.py # API 服务入口(uvicorn 启动)
├── app/ # 核心应用代码(MVC 架构)
│ ├── asgi.py # FastAPI 应用实例
│ ├── router.py # 路由注册
│ ├── config/ # 配置模块
│ │ └── config.py # TOML 配置加载
│ ├── controllers/ # 控制器层
│ │ ├── base.py # 基础控制器
│ │ ├── ping.py # 健康检查
│ │ ├── manager/ # 状态管理器
│ │ │ ├── memory_manager.py # 内存状态管理
│ │ │ └── redis_manager.py # Redis 状态管理
│ │ └── v1/ # API v1
│ │ ├── llm.py # LLM 接口
│ │ └── video.py # 视频生成接口
│ ├── models/ # 数据模型层
│ │ ├── const.py # 常量定义
│ │ ├── exception.py # 异常定义
│ │ └── schema.py # 数据结构/请求体
│ ├── services/ # 服务层(核心业务逻辑)
│ │ ├── task.py # 任务调度(核心编排器)
│ │ ├── llm.py # LLM 服务(16+ 提供商)
│ │ ├── voice.py # 语音合成(5 种 TTS 引擎)
│ │ ├── subtitle.py # 字幕服务(Whisper + 校正)
│ │ ├── material.py # 素材搜索下载
│ │ ├── video.py # 视频合成(拼接/转场/叠加)
│ │ ├── state.py # 任务状态管理
│ │ ├── upload_post.py # 跨平台发布
│ │ └── utils/
│ │ └── video_effects.py # 视频特效
│ └── utils/ # 工具类
│ ├── file_security.py # 文件安全校验
│ └── utils.py # 通用工具
├── webui/ # Streamlit Web UI
├── resource/ # 资源文件
│ ├── fonts/ # 字幕字体
│ └── songs/ # 背景音乐
├── docs/ # 文档和演示
├── config.example.toml # 配置文件模板
├── Dockerfile # Docker 镜像
├── docker-compose.yml # Docker Compose
└── pyproject.toml # Python 项目配置
task.py — 任务调度(核心编排器)整个视频生成流程的入口和总指挥。实现了一个 7 步流水线,按顺序协调所有子服务完成视频生成。
关键设计:
stop_at 参数支持在任意步骤中断,便于调试和分步 API 调用FAILED,不产生脏数据llm.py — LLM 服务统一的 LLM 调用接口,支持 16+ 种大语言模型提供商。大多数提供商通过 OpenAI 兼容接口统一调用,特殊提供商(qwen、gemini、cloudflare、ernie)有独立逻辑。
核心函数:
_generate_response(prompt) — 统一 LLM 调用入口generate_script() — 根据主题生成视频脚本generate_terms() — 根据脚本生成素材搜索关键词voice.py — 语音合成服务多引擎 TTS 服务,通过语音名称前缀路由到不同引擎(azure/gemini/siliconflow/mimo/默认 edge)。
核心函数:
tts() — TTS 主入口,返回 SubMaker 对象create_subtitle() — 从 TTS 时间戳生成 SRT 字幕get_all_azure_voices() — 获取 400+ 种 Edge TTS 语音subtitle.py — 字幕服务使用 faster-whisper 进行语音识别,并通过 Levenshtein 编辑距离与原始脚本对齐校正。
核心函数:
create() — Whisper 语音识别生成字幕(启用 VAD + word-level 时间戳)correct() — 字幕校正(相似度 > 0.8 时用脚本文本替换)material.py — 素材服务从 Pexels / Pixabay 搜索和下载无版权视频素材,支持多 API Key 轮换和 MD5 去重。
video.py — 视频合成服务最复杂的模块,负责素材拼接、转场效果、字幕叠加、音频混合、背景音乐添加。
核心函数:
combine_videos() — 素材拼接(支持 5 种转场效果)generate_video() — 最终合成(叠加字幕 + 混合音频)concat_video_clips_with_ffmpeg() — ffmpeg 高效无损拼接main.py (入口)
└─→ app/router.py (路由注册)
├─→ controllers/v1/video.py
│ └─→ task.start() ◄═══ 核心编排器
│ ├─→ llm.generate_script() → LLM 服务
│ ├─→ llm.generate_terms() → LLM 服务
│ ├─→ voice.tts() → 语音合成
│ ├─→ voice.create_subtitle() → 字幕生成(Edge)
│ ├─→ subtitle.create() → 字幕生成(Whisper)
│ ├─→ subtitle.correct() → 字幕校正
│ ├─→ material.download_videos() → 素材下载
│ ├─→ video.combine_videos() → 视频拼接
│ ├─→ video.generate_video() → 视频合成
│ └─→ upload_post.cross_post() → 跨平台发布
│
└─→ controllers/v1/llm.py
└─→ llm._generate_response() → LLM 服务
以下为 task.py 中 start() 函数的核心流程:
def start(task_id, params, stop_at="video"):
# 步骤1 [5%→10%]: 生成视频脚本
video_script = params.video_script or llm.generate_script(
video_subject=params.video_subject,
language=params.video_language,
paragraph_number=params.paragraph_number,
)
# 步骤2 [10%→20%]: 生成搜索关键词
video_terms = params.video_terms or llm.generate_terms(
video_subject=params.video_subject,
video_script=video_script,
amount=5,
)
# 步骤3 [20%→30%]: 生成语音音频
audio_file, audio_duration, sub_maker = voice.tts(
text=video_script, voice_name=..., voice_rate=...
)
# 步骤4 [30%→40%]: 生成字幕
# Edge 模式:利用 TTS 时间戳直接生成
# Whisper 模式:语音识别 + Levenshtein 校正
subtitle.create(audio_file=audio_file, ...)
subtitle.correct(subtitle_file=..., video_script=video_script)
# 步骤5 [40%→50%]: 获取视频素材
# 本地模式:预处理用户上传素材
# 在线模式:搜索 + 下载(累计时长 ≥ audio_duration)
downloaded_videos = material.download_videos(
task_id=task_id, search_terms=video_terms, ...
)
# 步骤6 [50%→100%]: 生成最终视频(循环 video_count 次)
for i in range(params.video_count):
# A: 拼接素材(切分→排列→转场→循环填充→ffmpeg合并)
video.combine_videos(combined_video_path=..., video_paths=...)
# B: 合成最终视频(叠加字幕 + 混合音频 + BGM)
video.generate_video(video_path=..., audio_path=..., subtitle_path=...)
# 步骤7(可选): 跨平台发布
upload_post.cross_post_video(...)
关键设计亮点:
stop_at 参数允许在任意步骤停止FAILED,不产生脏数据| 场景 | 说明 |
|---|---|
| 社交媒体内容批量生产 | 快速生成抖音、快手、视频号等平台的短视频,支持批量生成 |
| 营销推广视频 | 快速制作产品宣传、服务介绍视频,支持中英双语 |
| 教育培训内容 | 教师创建教学短视频、企业培训材料视频化 |
| 知识科普 | 将知识性内容快速转化为视频形式 |
| 个人创作 | 无需视频剪辑技能,输入创意即可出片 |
stop_at 参数实现流水线可中断,便于集成和调试此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。