REPL(读取-求值-打印循环)是一种交互式编程环境,它接收单个用户输入,执行这些输入,并立即返回结果。它充当对话式界面,用于快速原型设计、调试和实验,允许开发人员在不运行完整程序的情况下测试代码片段。常见的例子包括 Python shell、Node.js 和 IDE 控制台。
OpenAI Agents SDK中对REPL的实现:
该 SDK 提供 run_demo_loop,可在终端中直接对智能体行为进行快速、交互式测试。
import asyncio
from agents import Agent, run_demo_loop
async def main() -> None:
agent = Agent(name="Assistant", instructions="You are a helpful assistant.")
await run_demo_loop(agent)
if __name__ == "__main__":
asyncio.run(main())
run_demo_loop 会在循环中提示输入用户输入,并在轮次之间保留对话历史。默认情况下,它会在模型生成输出的同时进行流式传输。运行上面的示例后,run_demo_loop 会启动一个交互式聊天会话。它会持续请求你的输入,在轮次之间记住完整的对话历史(因此你的智能体知道已经讨论过什么),并在生成回复的同时将智能体的响应实时流式传输给你。
要结束此聊天会话,只需输入 quit 或 exit(然后按回车),或使用键盘快捷键 Ctrl-D。
引申:REPL-Plan
大型语言模型(LLM)在复杂、长时程(long-horizon)规划任务中表现不稳定,即使采用现有的“代码增强”(code-augmented)方法,仍然存在几个难以克服的根本性缺陷。具体来说,文章明确指出了当前代码增强规划方法的三大痛点:
人类程序员真正写复杂程序时,从来不是“一口气写完整个脚本”,而是开一个REPL(交互式编程壳/Notebook),一句一句敲、立刻看到结果、错了马上改、需要递归调试函数时就再开一个REPL来试。
文章提出的REPL-Plan就是把这种“人类写原型/调试代码的真实工作流”直接搬给LLM用:
文章针对下面的方法做了详细的讨论,总结相关的优缺点
| 方法类别 | 代表性工作 | 优点 | 缺点 |
|---|---|---|---|
| 纯文本逐步推理 + Action (Think step by step / ReAct 类) |
ReAct ,Reflexion, ADaPT,Zero-shot CoT 等 |
实现简单、少样本/零样本有效 显著提升短时程常识推理 能交替产生推理轨迹和行动 |
长时程任务极易幻觉(hallucination) 短期决策错误频发 无法处理需要精确循环/变量/控制流的复杂逻辑 在ALFWorld无memory下仅53.7%,真实网页任务仅17.6% |
| 纯文本子任务分解/分治 (Text-based Decomposition) |
THREAD ← 最强基线 Tree of Thoughts |
支持top-down递归分解 高度动态,能根据环境反馈调整计划 在ALFWorld达到95.5%,简单WebShop也76.3% |
完全缺乏代码表达力(no code-expressivity) 遇到需要循环、变量、长观察解析的复杂逻辑时彻底崩溃 WebShop k=10仅21%,真实网页复杂任务0.0% |
| 纯代码生成 (Code-as-Planning) |
包含:(1)伪代码自结构,不执行;(2)写可执行代码直接运行 | 充分利用代码控制流(if/loop/function) 对需要精确逻辑的任务理论上表达力最强 |
三大致命缺陷: 1. “模糊”(fuzzy)子任务无法可靠编码(如主观判断、解析非结构观察) 2. 必须bottom-up规划(先写完所有函数和case),LLM几乎不可能一次写对 3. 代码bug极难动态修复,一次生成整段代码,出错就全盘崩溃 |
| 需要External Memory / Reflection的混合方法 | Reflexion, AdaPlanner, RAP, AutoGuide, LATS, TDAG 等 | 通过记忆/多轮反思在部分任务上有提升 在ALFWorld有memory时可达76-85% |
依赖外部记忆,计算成本高 去掉memory后性能大幅下降 本质上还是受限于纯文本或半代码方式,无法同时拥有“动态纠错+完整代码表达力” |
文章指出现有方法只能在“动态性”与“代码表达力”之间二选一,而REPL-Plan是第一个真正把两者都拿满的方案——既能像程序员写Notebook一样动态试错、递归spawn子REPL处理模糊任务,又保留完整的代码控制流,因此在所有长时程+复杂任务中全面碾压。
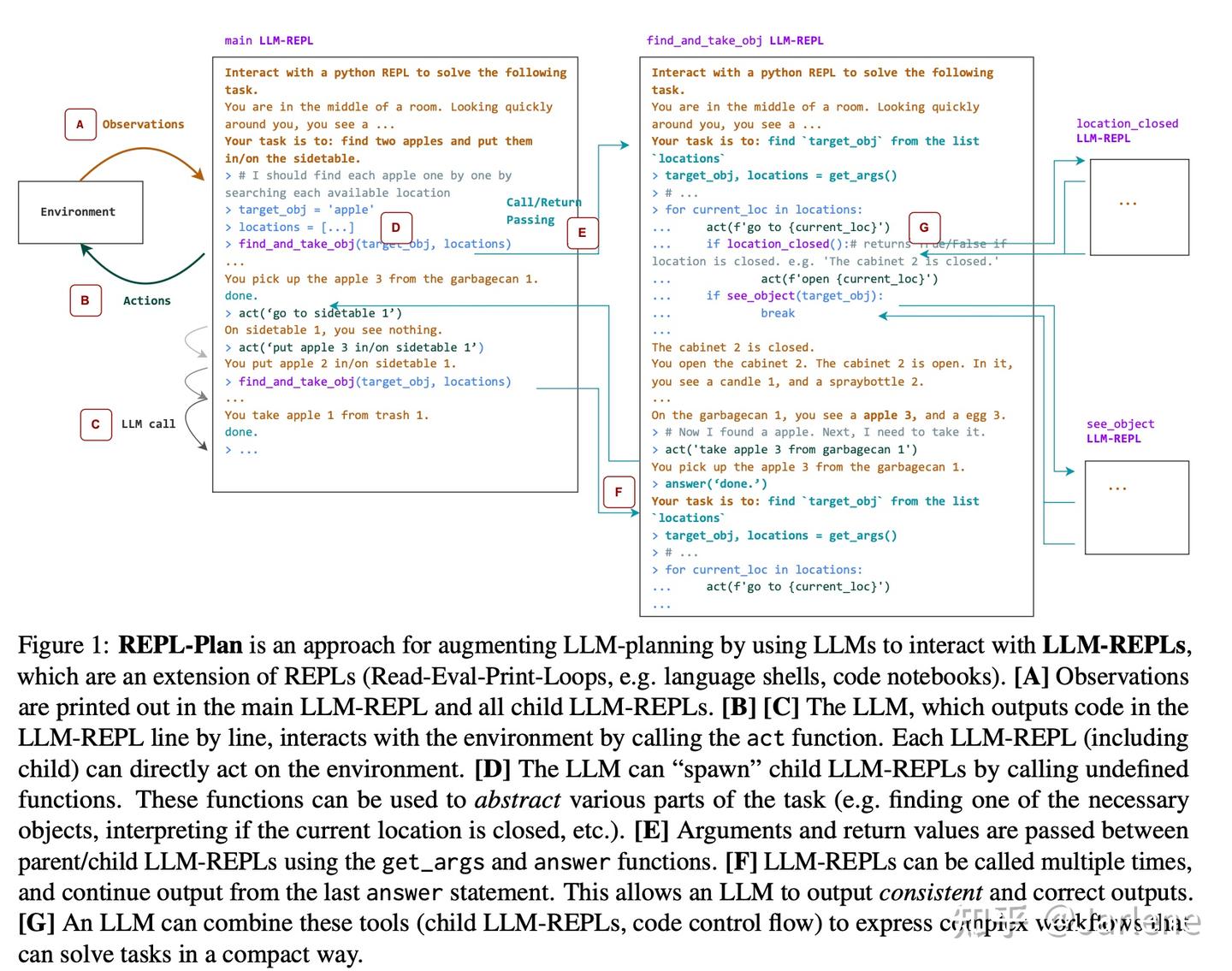
REPL-Plan原理
REPL-Plan的核心思想是模仿人类开发者使用交互式编程环境(如Python的REPL或Jupyter Notebook)的方式来解决复杂问题。其原理建立在以下几个关键点上:
check_requirements())时,系统不会报错,而是会动态生成一个子LLM-REPL来专门处理这个子任务。如上图所示,这种机制实现了自上而下的任务分解。主REPL负责高层规划流程,而将模糊、复杂或可复用的子任务(如“解析物品”、“判断匹配度”)委托给子REPL。子任务完成后,通过 answer() 函数将结果返回给父REPL,这与函数调用的栈机制非常相似。
REPL-Plan的实现可以看作一个状态机,其核心实现逻辑和关键组件:
每个LLM-REPL可以被视为一个类(LLMREPLFunction)的实例,它包含:
task: 该REPL要解决的任务描述。history: 该REPL中所有已执行的代码及其输出的历史记录。locals: 一个字典,包含当前REPL的局部变量状态和预定义的原语函数。系统的核心是一个循环,其简化版的数学描述可以表示为一系列的状态转换:设 𝑆𝑡=(𝐻𝑡,𝐿𝑡) 表示在时间步 𝑡 的系统状态,其中:𝐻𝑡 是到时间 𝑡 为止的代码和执行历史。𝐿𝑡 是当前的局部变量环境。系统的演进过程如下:
answer(a)。此时,返回值 𝑎 被传递给父REPL,并用于定义函数 𝑓。这些是注入到每个LLM-REPL环境中的特殊函数,是实现与环境交互和递归分解的基础:
act(a): 在环境中执行动作 𝑎,并获取新的观察。这是规划与环境的接口。get_obs(): 返回当前的环境观察(通常是一个长字符串)。args: 触发子LLM-REPL的生成。在底层,这通过触发一个NameError并按照上述情况B处理来实现。get_args(): 在子REPL中调用,用于接收父REPL传递过来的参数。answer(a): 在子REPL中调用,将结果 𝑎 返回给父REPL,并终止子REPL的执行。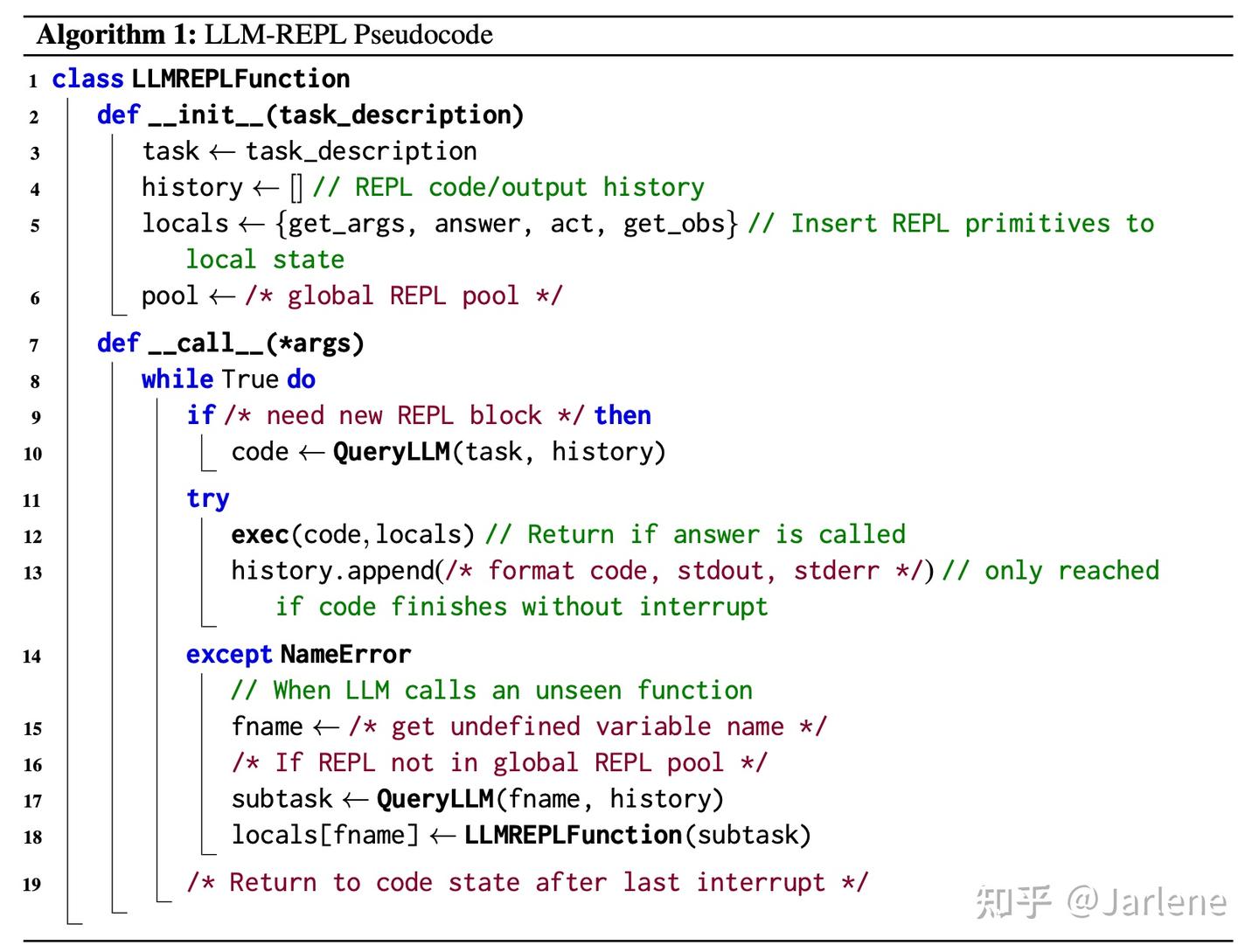
伪代码
REPL-Plan的原理并非依赖于某个神秘的数学突破,而是源于一个强大且实用的工程框架。它将大语言模型的代码生成能力与交互式编程范式的强大功能(如即时反馈、状态管理和递归抽象)巧妙地结合在一起。其“数学精髓”体现在递归算法、状态机模型以及与LLM的条件概率交互中,从而实现了对复杂、长视野规划任务的动态、稳健且可表达的解码。
这篇论文通过在三个具有挑战性的语言交互环境中进行系统实验,全面评估了REPL-Plan的性能。实验旨在测试智能体在长视野、需推理、需处理模糊信息的任务中的能力。选用的环境和基线对比如下:
| 实验环境 | 任务描述 | 核心挑战 | 对比的基线方法 |
|---|---|---|---|
| ALFWorld | 文本模拟家庭环境中的任务(如:在厨房找到苹果并加热) | 具身推理、长序列动作规划 | ReAct, Reflexion, AdaPlanner, RAP, AutoGuide, THREAD |
| WebShop (k=3) | 在模拟电商网站根据自然语言描述搜索并购买商品 | 理解网页语义、比较商品属性 | 同上,包括 THREAD |
| WebShop (k=10) | 同上,但每页显示10个商品,策略更复杂(如:搜索两次,从Top-20中选最佳) | 处理更多选项、需要循环和复杂逻辑 | THREAD, REPL-Plan |
| 真实世界网页任务 |
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。