你有没有想过,当你让 ChatGPT "记住你喜欢简洁的回答",或者让代码助手"别忘了这个项目用的是 TypeScript"时,这些信息究竟去了哪里?
这个问题比表面看起来复杂得多。LLM 本身是"无状态"的——每次对话都是从零开始,模型并没有一个专门的"记忆区"来存放你的偏好。那些看似被"记住"的信息,可能被塞进了 prompt,可能缓存在某个向量数据库里,也可能通过微调烧进了模型参数。每种方式都有自己的代价和局限。
来自港科大、新加坡 A*STAR 等机构的研究团队最近发表了一篇综述,试图回答一个更根本的问题:这些看似迥异的"记忆"机制,背后有没有统一的设计逻辑? 他们的答案是肯定的,并且提出了一个简洁的框架来理解整个领域。
论文链接:LLM Agent Memory: A Survey from a Unified Representation–Management Perspective
先澄清一个常见的误解。
GPT-4 Turbo 支持 128K token,Claude 3 号称能处理 200K,Gemini 1.5 Pro 更是喊出了百万 token 的口号。看起来记忆问题已经被"暴力解决"了——上下文窗口足够大,把所有历史对话都塞进去不就行了?
事情没那么简单。研究者们发现了一个有趣的现象叫"lost in the middle":当你把关键信息埋在长文本的中间位置时,模型往往会"视而不见"。注意力机制理论上能看到所有 token,但实际上它对头尾更敏感,中间的信息容易被稀释。更实际的问题是成本——注意力计算的复杂度是 \(O(n^2)\),上下文翻倍意味着计算量翻四倍,这在生产环境中是不可接受的。
所以,记忆的本质不是"看到更多",而是"记住关键" 。这篇综述的出发点正在于此:与其关注上下文能装多少 token,不如关注信息如何被选择性地保留、组织和检索。
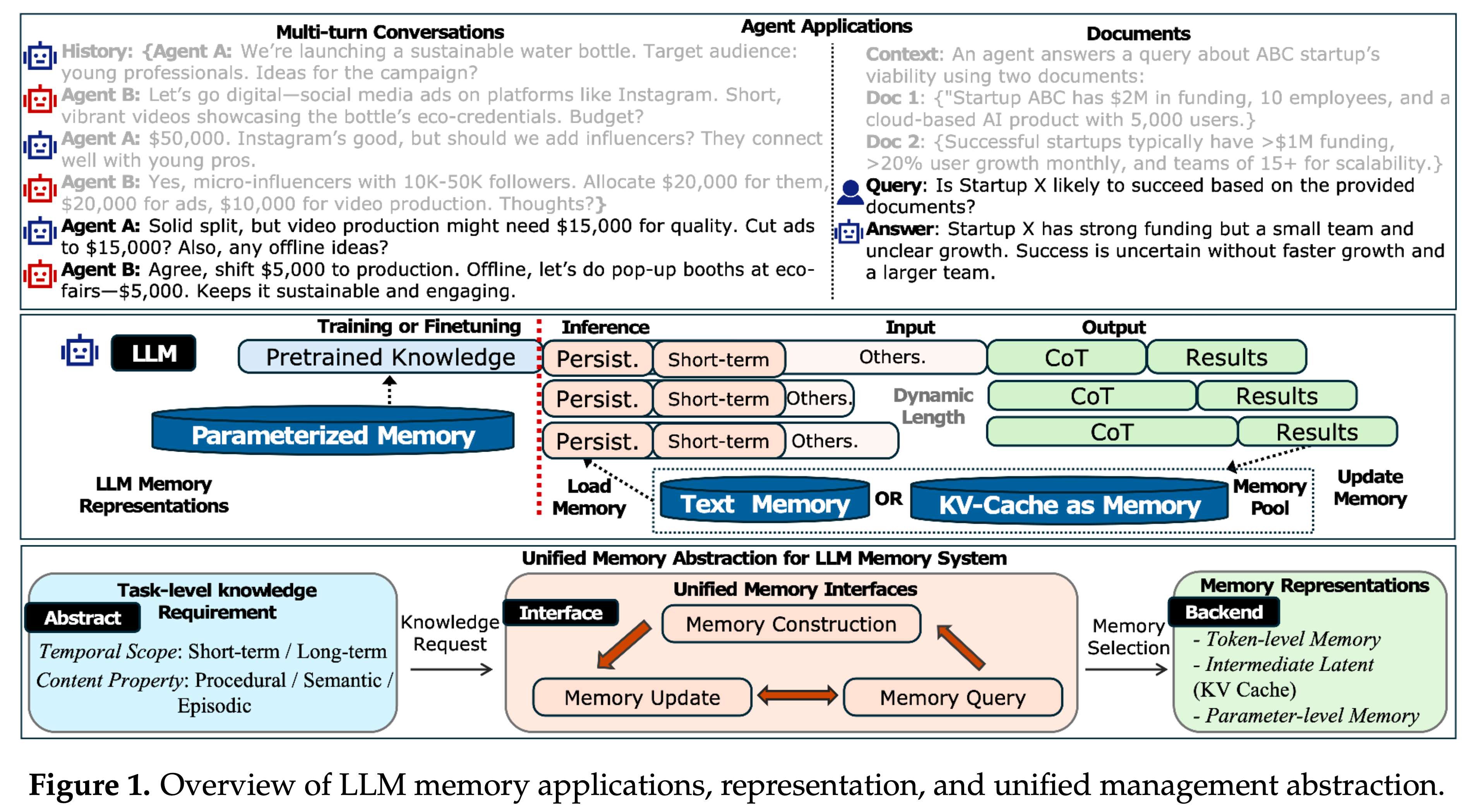
综述的核心贡献是提出了一个理解 LLM 记忆的统一框架。思路其实很直观:任何记忆系统都要回答两个问题——信息存在哪里?如何操作它?
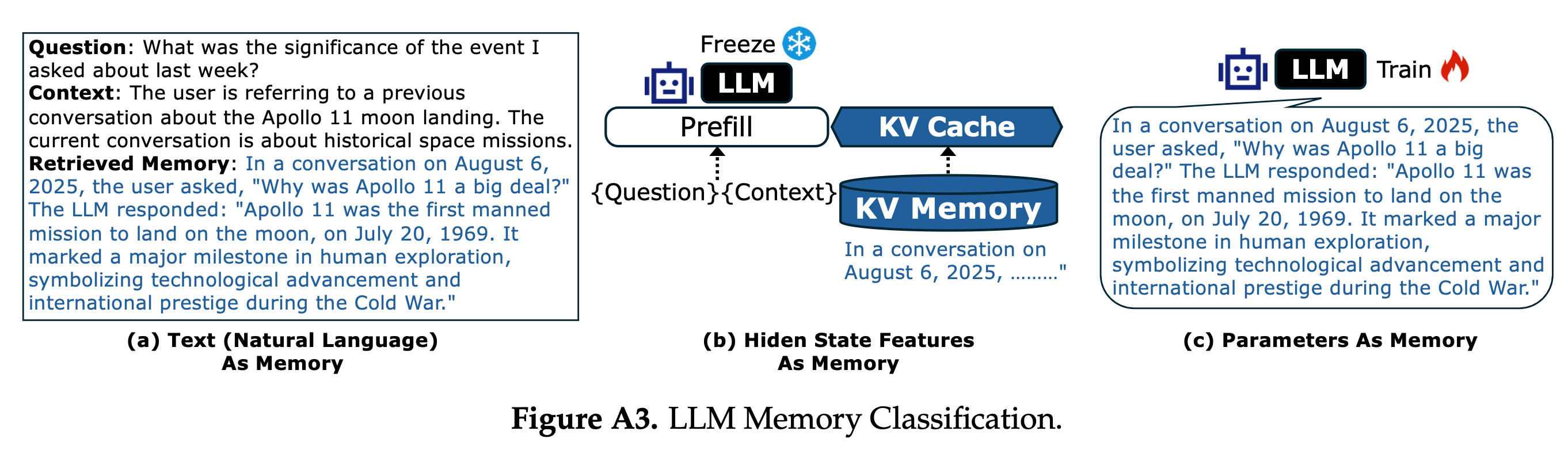
第一个问题关于"表示"。LLM 的记忆可以存在三个地方:直接写在 prompt 里的自然语言、推理过程中缓存的中间向量(典型如 KV Cache)、以及烧录在模型权重里的参数化知识。三者的特性截然不同:
| 表示形式 | 存储位置 | 核心优势 | 主要局限 |
|---|---|---|---|
| 自然语言 Token | Prompt 上下文 | 显式、可编辑、无需训练 | 占用上下文窗口,查询效率受限 |
| 中间表示 (Latent) | KV Cache / 向量库 | 高效、运行时可修改 | 容量有限,仅会话内有效 |
| 模型参数 | 权重 | 持久化、无检索开销 | 修改困难,易遗忘旧知识 |
第二个问题关于"管理"。无论选择哪种表示,记忆系统都需要处理三个操作:构建(存什么、怎么组织)、更新(如何维护和淘汰)、查询(如何找到相关信息)。有意思的是,这三个操作在不同表示下的难点完全不同。
论文用一个决策矩阵揭示了这种差异:
| 记忆表示 | 适合的知识类型 | 核心瓶颈 | 设计重点 |
|---|---|---|---|
| Token | 短期情景 + 语义知识 | 查询 | 如何在有限上下文中选出高信号子集 |
| Latent | 短期情景记忆 | 更新 | 固定容量下的缓存调度与压缩 |
| Parameter | 长期程序 + 语义知识 | 写入 | 避免灾难性遗忘和知识冲突 |
这个框架的价值在于,它让我们能用同一套语言比较表面上毫不相关的技术——RAG 系统和 KV Cache 压缩算法,看起来是两个领域,但本质上都在解决"有限容量下的记忆管理"问题,只是一个管理文本片段,一个管理向量。

最直观的做法是把记忆直接写成自然语言,塞进 prompt。这就是 RAG(检索增强生成)的基本思路:维护一个外部知识库,需要时检索相关片段注入上下文。
RAG 的精妙之处在于它把"记忆"问题转化成了"检索"问题。检索是信息领域研究了几十年的老问题,有成熟的工具和方法论——向量数据库、倒排索引、BM25、语义嵌入——这些都可以直接拿来用。
但 RAG 的挑战也很明显:检索的是片段,而非完整的知识。想象你在问一个跨越多个文档的复杂问题,答案需要综合三个段落的信息,而每个段落单独看都不像是"相关"的——这时候简单的相似度检索就会失效。
研究者们为此发展出各种技巧。HyDE(Hypothetical Document Embeddings)让模型先"假想"一个答案,再用这个假想答案去检索真实文档——有点像"先猜后验"。Step-Back Prompting 则是反过来,把具体问题抽象成更通用的形式,检索更宽泛的背景知识后再回答原问题。这些方法的共同点是:不直接检索,而是先改造查询。
另一条路是把记忆组织成更结构化的形式。HippoRAG 借鉴了人脑海马体的工作方式,用知识图谱连接记忆片段,支持沿着关系边进行多跳推理。GraphReader 则是让 Agent 在图结构上"游走",边走边决定下一步往哪个方向探索。这类方法的代价是构建和维护结构的额外开销,但在需要复杂推理的场景下回报也很可观。
对于多轮对话的 Agent,记忆管理变得更复杂。不仅要存储信息,还要随着交互演化。A-MEM 模仿 Zettelkasten 笔记法,让记忆以互联的"笔记"形式增长,新记忆自动链接到相关的旧记忆。Reflexion 则走得更远:Agent 不仅记录发生了什么,还会反思"为什么失败",把经验教训提炼成可复用的策略。这已经不是简单的存储,而是接近人类的"经验学习"了。
如果你用过大模型推理框架,对 KV Cache 一定不陌生。它的原理很简单:Transformer 在自回归生成时,每个新 token 都需要和之前所有 token 做注意力计算。如果每次都从头算,复杂度是 \(O(n^2)\);但如果把之前 token 的 Key 和 Value 向量缓存起来,新 token 只需要算自己的部分,复杂度就降到了 \(O(n)\)。
这本来是个纯粹的工程优化,但如果从记忆的角度看,KV Cache 其实是模型对上下文的隐式编码。它不是原始文本,而是文本经过注意力机制"消化"后的中间表示,某种程度上比原始 token 更"接近"模型的内部理解。
问题在于,KV Cache 的大小随序列长度线性增长,而 GPU 显存是有限的。当上下文达到几万 token,缓存就会成为瓶颈。于是就有了各种"压缩"策略。

最直接的思路是淘汰不重要的 token。StreamingLLM 发现了一个有趣的现象:注意力分数往往集中在序列开头的几个 token 上(即使它们在语义上并不重要),这被称为"attention sink"。基于这个发现,它只保留开头几个 token 和最近的滑动窗口,其余全部丢弃,就能支持无限长的流式生成。H2O 则更精细,它追踪每个 token 的累积注意力分数,只保留"heavy hitter"——那些真正被频繁关注的 token。
另一条路是压缩而非丢弃。MiniCache 发现相邻层的 KV 向量高度相似,可以跨层共享;ChunkKV 则是把语义相近的 token 合并成一个"超级 token",保留语义信息的同时减少条目数量。还有量化的路线:KIVI 用非对称 2-bit 量化,几乎不损失精度的情况下把缓存压缩到原来的八分之一。
这些方法和操作系统里的内存管理高度相似——淘汰策略像 LRU/LFU,压缩像内存去重,分层缓存像虚拟内存。这不是偶然,而是因为底层问题是同构的:有限容量下的高效数据管理。
最"持久"的记忆是直接写进模型权重。预训练过程本质上就是在做这件事:把海量文本中的知识压缩成几十亿个浮点数。
参数化记忆的好处是一劳永逸——不需要检索,不需要缓存,知识就在那里,推理时自动激活。研究表明,Transformer 的 FFN 层可以被理解为一个巨大的 key-value 存储,特定的神经元甚至对应特定的事实知识。
但代价也很明显:参数一旦写入,就很难修改。这不仅是工程问题,更是科学问题。"灾难性遗忘"是持续学习领域的老大难:微调模型学习新知识时,旧知识会被覆盖。EWC 等方法通过正则化约束"重要参数"的变化来缓解这个问题,但远没有根本解决。
模型编辑(Model Editing)是另一种思路:不是全局微调,而是精准修改特定事实。想象你要把模型对"埃菲尔铁塔在哪个城市"的回答从巴黎改成伦敦(纯假设),模型编辑试图找到负责这个事实的神经元并定点修改。ROME、MEMIT 等方法在这条路上取得了进展,但问题是:事实在模型里并不是孤立存储的,修改一个事实可能连带影响相关知识的一致性。
WISE 提出了一个有趣的架构:维护两套记忆——稳定的"预训练知识"和可编辑的"后天知识",查询时用路由机制决定访问哪一套。这有点像人脑的长期记忆和工作记忆的分离,但在工程上如何高效实现还是开放问题。
模型合并(Model Merging)则是从另一个角度利用参数记忆:把多个微调模型的权重"融合"成一个,期望继承各自的能力。最简单的做法是参数平均,但这往往导致性能下降——不同任务的知识可能编码在同一组参数上,直接平均会相互干扰。TIES、DARE 等方法通过稀疏化和冲突解决来缓解这个问题,但对任务兼容性仍然敏感。
把三种记忆表示放在一起看,会发现一个有趣的规律:选择不同的表示,本质上是在选择不同的瓶颈。
Token 记忆的瓶颈在查询。上下文窗口就那么大,你不可能把所有历史都塞进去,必须选择"放什么"。这个选择做好了,模型能看到正确的信息;做不好,关键证据就被遗漏了。
KV Cache 的瓶颈在更新。显存就那么多,你必须决定"留什么、扔什么"。淘汰策略太激进会丢失重要上下文,太保守会撑爆缓存。
参数记忆的瓶颈在写入。权重就那么一份,你必须确保"新知识进去的同时旧知识不能出来"。做好了是增量学习,做不好就是灾难性遗忘。
这意味着,没有一种记忆表示能通吃所有场景。实用的系统需要分层组合:用参数存储长期稳定的知识和技能,用 KV Cache 维持会话内的连续性,用 Token 引入即时的外部证据。统一的管理接口(构建-更新-查询)则是粘合这些层次的"控制平面"。
综述最后讨论了几个开放方向,我觉得其中两个特别值得关注。
第一是训练和推理的边界正在模糊。传统上,训练是离线的、批量的;推理是在线的、即时的。但在长期运行的 Agent 场景下,这个区分不再清晰——Agent 需要在运行中学习新知识、适应新用户,同时不能遗忘已有能力。这要求一种新的系统架构,能在推理时高效地做轻量级参数更新,而这正是目前的框架(无论是 PyTorch 还是各种推理引擎)不擅长的。
第二是跨领域的方法迁移。操作系统研究内存管理几十年了,数据库研究查询优化也几十年了,里面有大量成熟的技术——分页、淘汰策略、索引结构、执行计划——可以借鉴到 LLM 记忆系统。事实上已经有人在做这件事:vLLM 的 PagedAttention 就是把操作系统的分页思想用到了 KV Cache 管理上。但这只是冰山一角,还有大量的经典方法等待被重新发现。
这篇综述做的事情,不是简单地列举"有哪些方法",而是试图回答"为什么会有这些方法、它们在解决什么共同的问题"。统一的"表示-管理"框架虽然简洁,但确实能把一堆看似不相关的工作串联起来,让人看到全局的图景。
如果你在做 LLM 应用,这个框架或许能帮你更清晰地思考记忆系统的设计选择:你的场景需要什么类型的记忆?瓶颈在哪个环节?有没有可以借鉴的现有方案?
如果你在做 LLM 系统研究,这篇综述的参考文献列表本身就很有价值——几乎涵盖了 2023-2025 年记忆相关工作的全貌。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。