想象这样一个场景:你在跑一个多 Agent 仿真,20 个 Agent 在互动,每轮结束后所有人把彼此的输出 All-Gather 一遍,然后各自基于这一轮的"公共信息"再生成下一轮的回应。
听起来很自然,对吧?
但作为一个结结实实在 LLM 推理框架里踩过坑的人,第一反应是:KV Cache 要爆。
20 个 Agent,每人都有同样的公共输出 block,但因为各自的私有历史(private history)长度不一样,这些公共 block 在不同 prompt 里出现在不同位置——这就直接把 vLLM 的 prefix caching 废掉了,因为 prefix caching 要求共享内容必须在 prompt 开头,位置完全一致。
最近看到了一篇来自 UCLA 的工作 TokenDance(arXiv 2604.03143),专门解决这个问题,思路挺清晰的,今天想和大家聊聊它解决了什么真问题、以及是怎么解的。
先交代一下背景。
多 Agent 系统里有一类非常常见的通信模式叫 All-Gather:每轮推理结束后,所有 Agent 的输出都被广播给全体,下一轮每个 Agent 的 prompt 里都包含:
如下图所示,公共输出 block O 在每个 Agent 的 prompt 里都出现,但位置不同,因为每个人的私有历史 H 长度不一样:
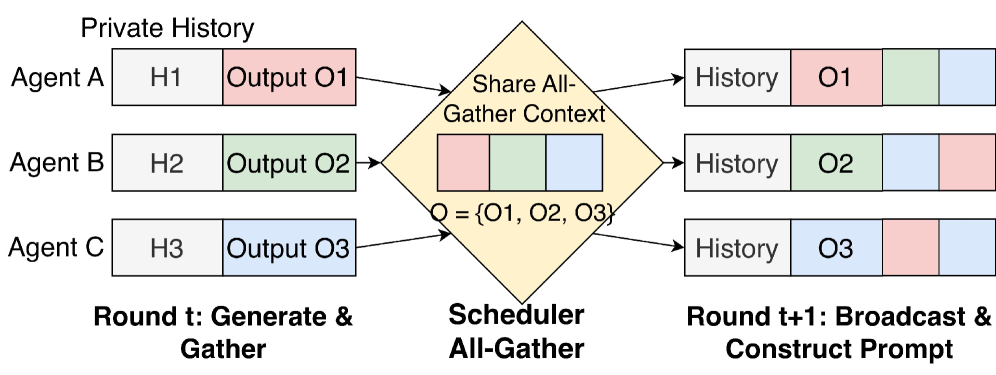
这就带来了一个核心问题:所有 Agent 的 KV Cache 里都包含了大量结构相似的内容,但现有系统完全没有跨 Agent 复用。
vLLM 的 prefix caching 只能处理前缀完全一致的情况——只要 H 不同,O 的 KV Cache 就没法共享,每个 Agent 都得重新算一遍。20 个 Agent?算 20 遍,存 20 份,内存直接 OOM。
针对这个问题,有一类方案叫 PIC(Position-Independent Caching)——不依赖 token 在 prompt 里的绝对位置,而是通过旋转位置编码(RoPE)的特殊处理,让同一段内容的 KV Cache 可以在不同位置上复用。
但 PIC 的问题在于:它是 per-request 的。
每个 Agent 的请求独立进来,PIC 会对每个请求各自做一次 RoPE 旋转和重要位置选择(important-position selection)。N 个 Agent 同轮进来,就做 N 次,根本没有利用"这 N 个请求共享同一批 token"这个事实。
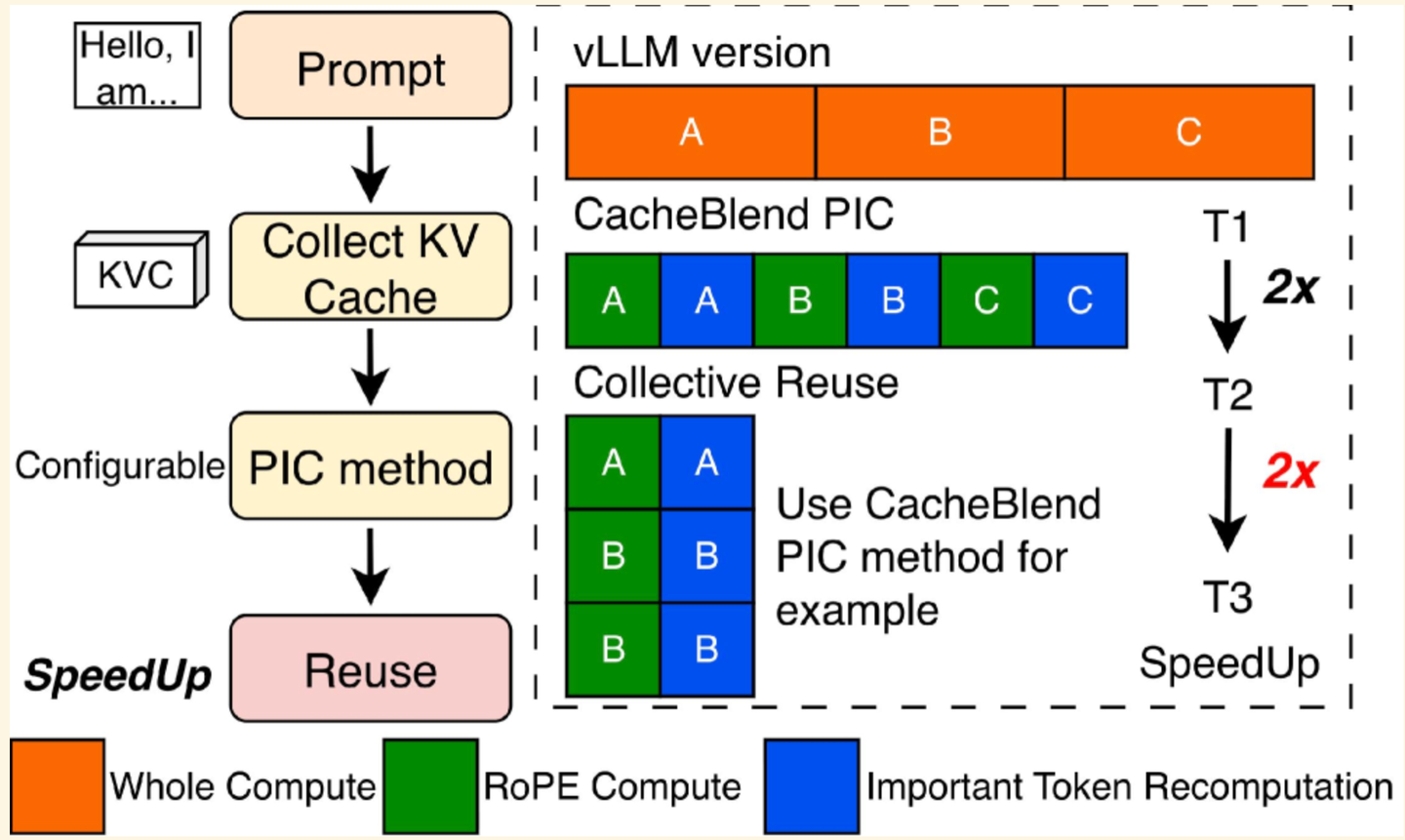
如下图对比了 per-request PIC(上)和 TokenDance 的 collective reuse(下):
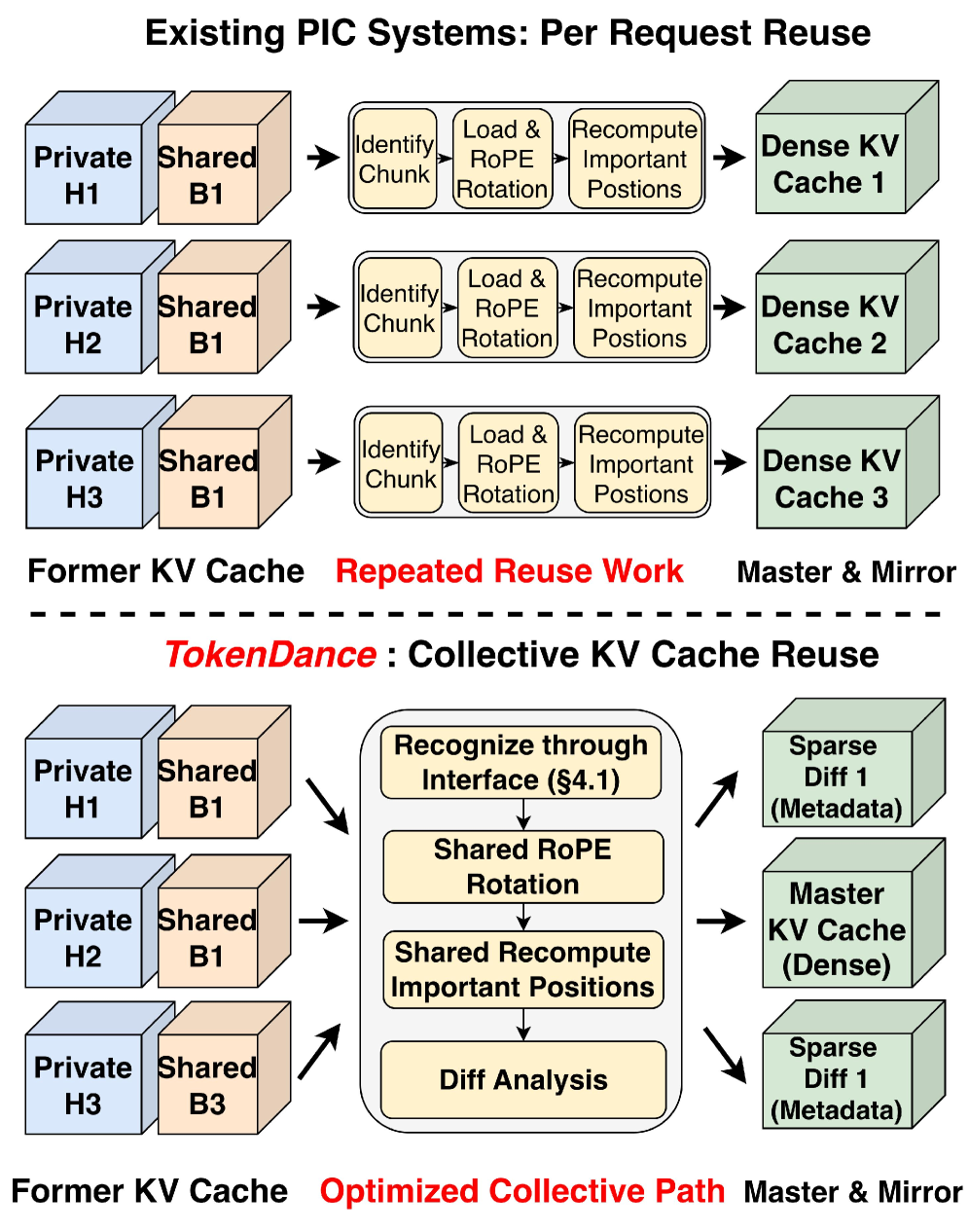
这就是整个行业在多 Agent serving 上面临的核心矛盾:公共内容明明存在,但跨 Agent 的复用机制不存在。
TokenDance 的整体架构如下:
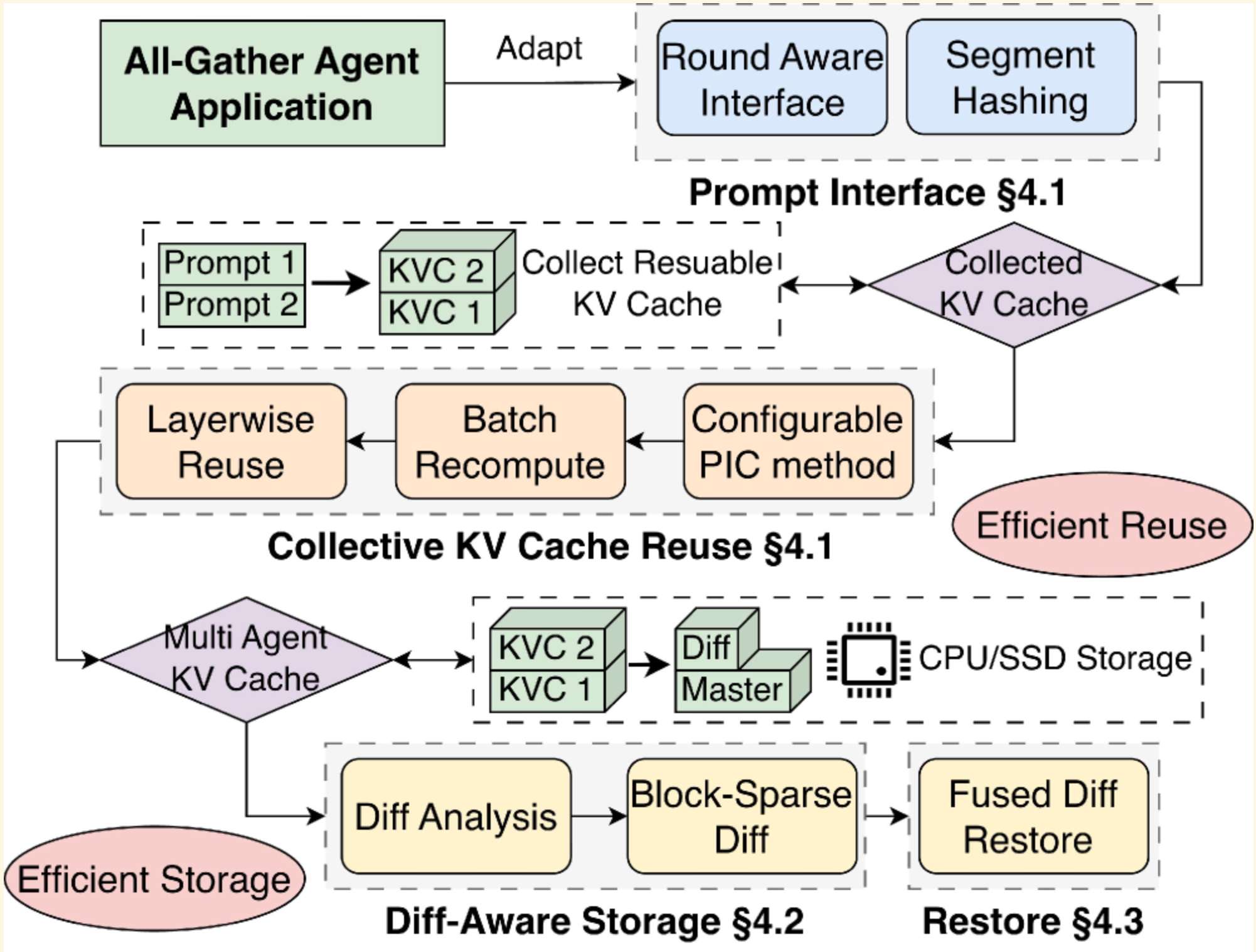
三个核心模块,逐一拆解。
要复用,首先得让系统知道哪些 block 是共享的。
问题是:传统 LLM serving 的 prompt 接口是 flat string,进来一串 token,系统不知道哪段是公共输出、哪段是私有历史。block boundary 的信息在 application 层就丢掉了。
TokenDance 引入了一个 round-aware prompt interface,用特殊分隔符 <TTSEP> 显式标记不同 block 的边界。如下图:
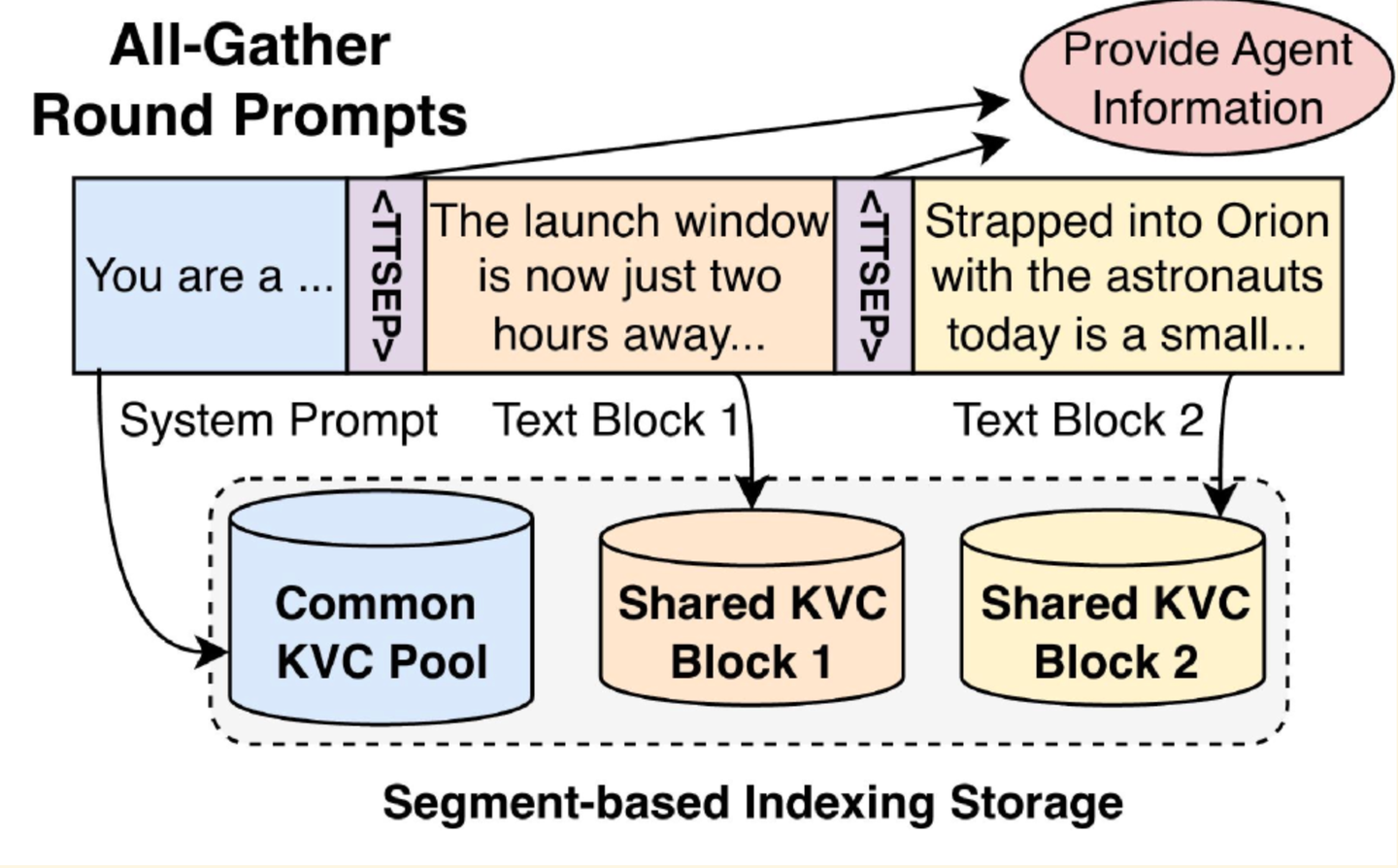
这个改动看起来很简单,但很关键——它让 runtime 能够在 block 粒度上识别共享内容,为后续的 collective reuse 和 diff-aware storage 奠定基础。
识别到共享 block 之后,TokenDance 不再对每个 Agent 独立做 PIC,而是把一轮里所有 Agent 的请求分组,对公共 block 只做一次 RoPE 旋转和 important-position selection,然后把结果分发给所有 Agent。
如下图对比了三种方式:
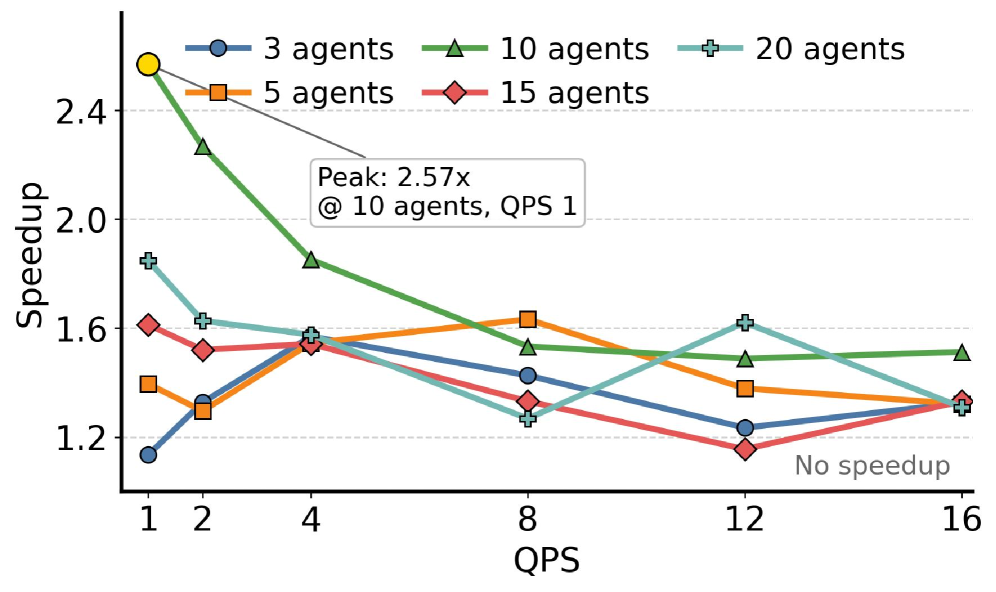
实验结果显示,collective reuse 相比 serial PIC 最高有 2.57x 的 prefill 加速(10 agents,QPS=1):
collective reuse 之后,各 Agent 的 KV Cache 里,公共 block 对应的部分其实高度相似,只有 10-20% 的位置存在差异(因为 RoPE 之后不同 Agent 的相对位置略有不同,加上各自私有历史导致的 attention 差异)。
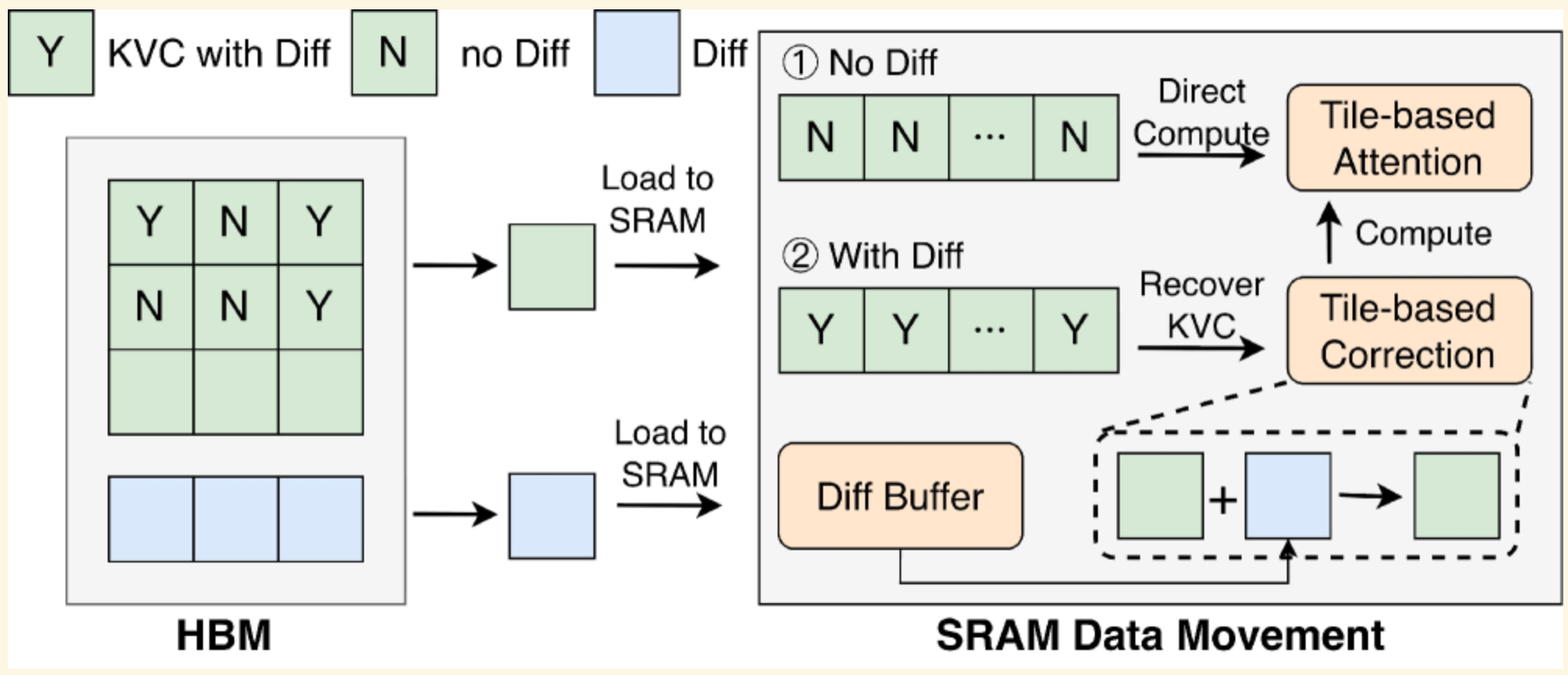
TokenDance 用一个 Master-Mirror 布局 来压缩这个冗余:
如下图:
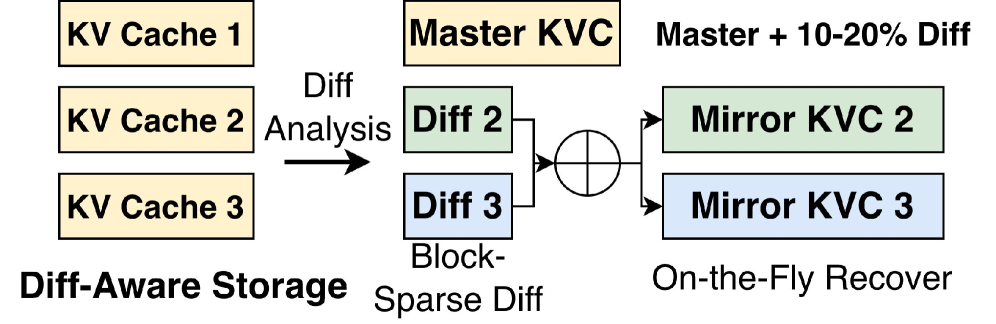
通俗说:从存 N 份完整 KV Cache,变成存 1 份 + (N-1) 份稀疏 diff。
压缩比很可观:
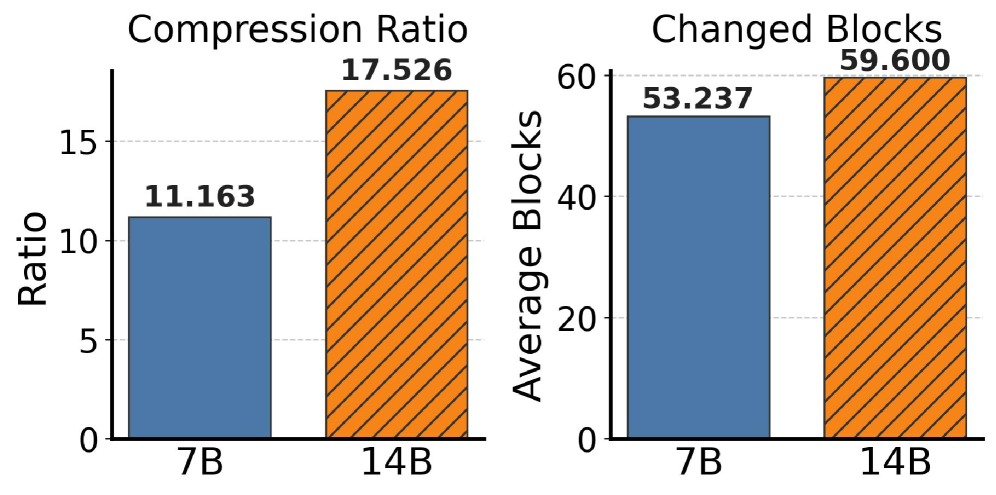
7B 模型可以达到 11-17x 的 KV Cache 体积压缩;14B 模型因为每个 token 的 cache tensor 更大而 diff block 数量相近,所以压缩比更高。
一个自然的问题是:压缩成 diff 之后,推理时得把 Mirror 还原成完整 KV Cache,这个还原本身会不会带来 latency?
TokenDance 的解法是 Fused Diff Restore——在 block 粒度上,直接在 SM(shared memory)里做 diff 修正,然后马上跑 attention,不需要先 materialize 一份完整的 KV Cache 再送给 attention kernel。
如下图:
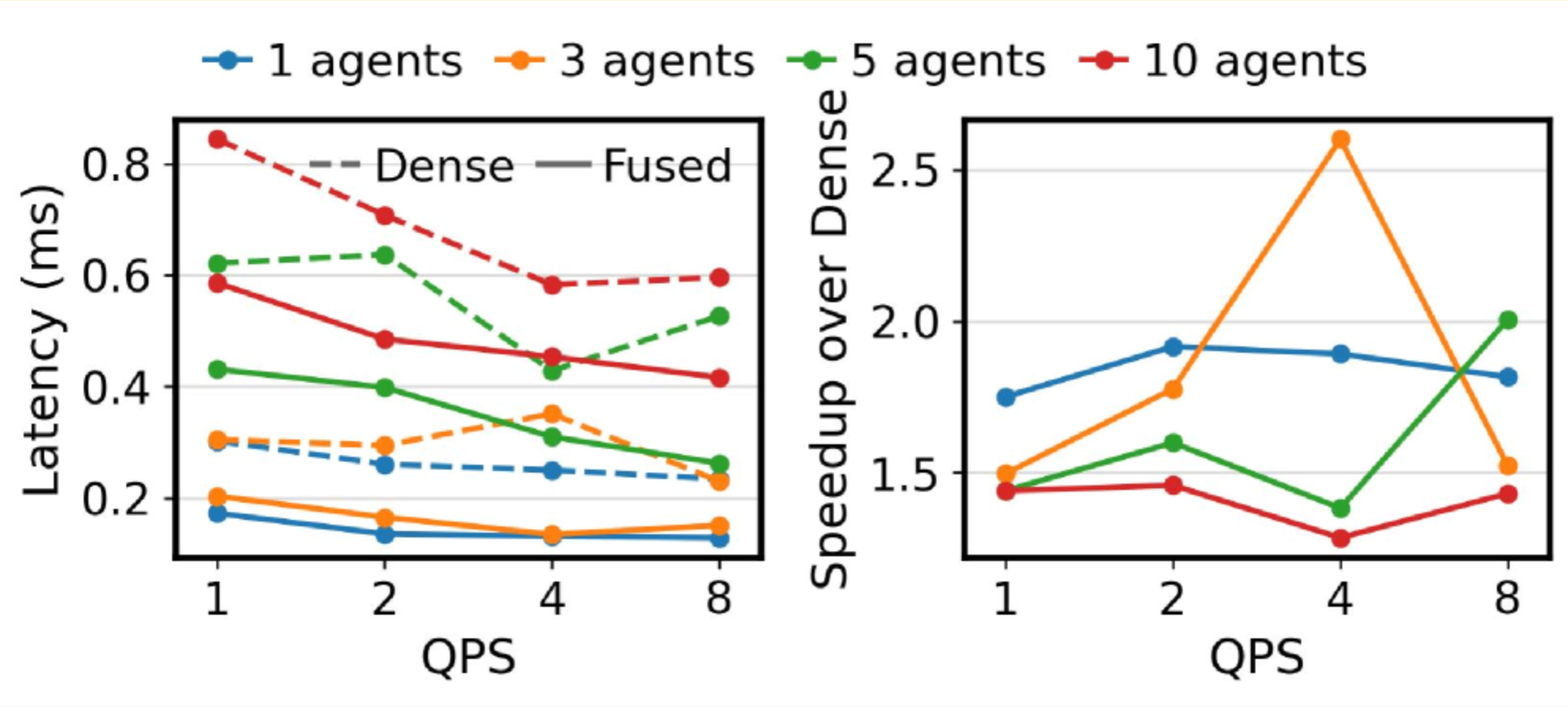
实验显示,fused retrieval 比 dense restore(先完整还原再推理)快 1.3-2.6x:
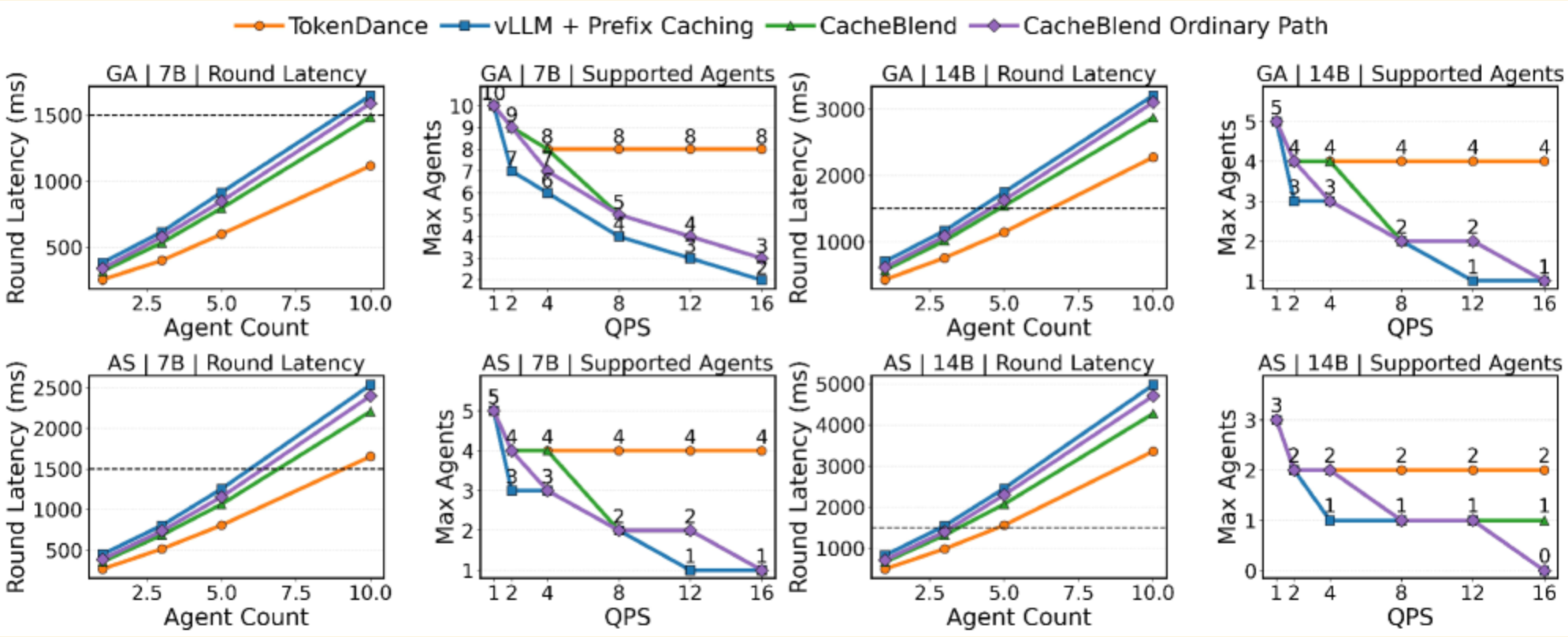
在 GenerativeAgents 和 AgentSociety 两个 benchmark 上,用 Qwen2.5-7B 和 Qwen2.5-14B 测试,TokenDance 相比 vLLM(with prefix caching)的结果:
如下图:
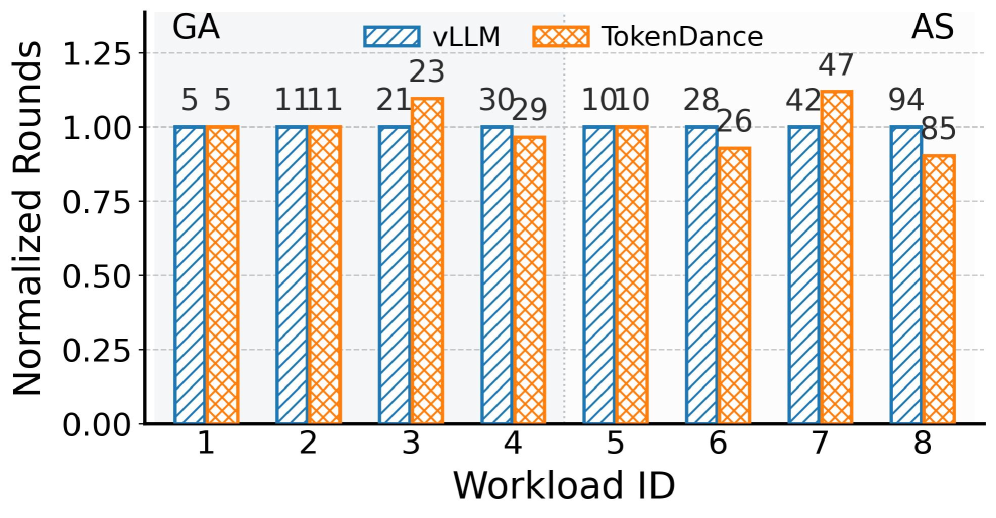
精度方面,TokenDance 与 vLLM(temperature=0)的输出在大多数场景下零divergence,少量差异来自底层 PIC 方法本身,不是 TokenDance 引入的:
这篇工作抓住的 insight 很准:多 Agent 系统的 All-Gather 通信会产生结构性的 KV Cache 冗余,而这个冗余以前从来没有被系统层利用过。
几个我觉得做得比较细的点:
Round-aware prompt interface 这个设计很务实。不是直接改 LLM 框架内部,而是在 application 和 runtime 中间加一层协议,改动侵入性小,容易接入现有多 Agent 框架(Camel、GenerativeAgents 等)。
Collective reuse 和 per-request PIC 的对比 讲清楚了——不是说 PIC 没用,而是 PIC 在 multi-agent 场景下没有利用到 batch 结构,TokenDance 在这一层补了一刀。
Diff 压缩的 insight 来自对实际 KV Cache 分布的测量——先验证了"reuse 之后 KV Cache 只有 10-20% 不同",再设计压缩方案,而不是拍脑袋。工程上这种先 profiling 再设计的做法是对的。
唯一的小问题是论文对 PIC 的具体变体(哪种 RoPE off-set 策略)描述得比较模糊,复现起来可能需要看代码细节。
总体来说,这是一篇工程针对性很强的系统论文,解决的是多 Agent serving 落地时的实际痛点。如果你在搭多 Agent 仿真平台,或者在做 LLM serving 层的优化,这篇值得精读。
如有错误欢迎评论区指出,这块我也在持续学习中。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。