dify는 오픈 소스 LLM 애플리케이션 개발의 오픈 소스 플랫폼으로, 에이전트 구축부터 AI 워크플로우编排、RAG, 에이전트 등을 제공하며, 검색 전략, 모델 관리 등의 기능을 지원하여 AI 애플리케이션을 쉽게 구축하고 운영할 수 있습니다.
가장 중요한 것은 LangChain보다 사용하기 쉽고, 멋진 콘텐츠가 있습니다.
배포 및 설치 튜토리얼을 보고 싶다면, 본 글의 목차를 직접 클릭하세요.
Dify는 생성형 AI 네이티브 애플리케이션을 구축하기 위해 필요한 핵심 기술 스택을 포함하고 있으며, 개발자는 애플리케이션의 핵심 가치에 집중할 수 있습니다.

| 카테고리 | 내용 |
|---|---|
| LLM 추론 엔진 | Dify Runtime (v0.4부터 LangChain 제외) |
| 지원하는 상업 모델 | 10+ (OpenAI 및 Anthropic 포함)<br>주요 신규 모델은 48시간 내에 |
| 지원하는 MaaS 제조업체 | 7곳에 연결될 수 있습니다: Hugging Face, Replicate, AWS Bedrock, NVIDIA, GroqCloud, together.ai, OpenRouter |
| 지원하는 로컬 모델 추론 실행 시간 | 6가지: Xoribits(추천), OpenLLM, LocalAI, ChatGLM, Ollama, NVIDIA TIS |
| OpenAI 인터페이스 표준 모델 통합 | 무한한 지원 |
| 다모달 기능 | ASR 모델、풍부한 텍스트 모델(최고 지원 GPT-4o 사양) |
| 내장 애플리케이션 유형 | 텍스트 생성、챗봇、대리인、워크플로우、대화 흐름 |
| Prompt-as-a-Service编排 | 대중적으로 칭찬받는 시각적编排 인터페이스, 중앙에서 Prompt를 수정하고 결과를 미리보기 |
| 编排 모드 | 간단한编排、대리인编排、프로세스编排 |
| Prompt 변수 유형 | 문자열、단일 선택 열거 |
| 외부 API 지원 | 파일(2024 Q3 출시) |
| 대리인 워크플로우 특징 | 산업 선두를 이루는 시각적 워크플로우编排 인터페이스, 실시간 노드 편집 및 디버깅, 모듈식 DSL, 네이티브 코드 실행 시간 |
| 지원 노드 | LLM, 지식 검색, 문제 분류기, IF/ELSE, 코드, 템플릿, HTTP 요청, 도구 |
| RAG 기능 | 산업 최초의 시각적 지식베이스 관리 인터페이스, 조각 미리보기 및 회상 테스트 지원 |
| 인덱싱 방법 | 키워드, 텍스트 벡터, LLM 보조 질문-조각 모델 |
| 검색 방법 | 키워드, 텍스트 유사도 매칭, 혼합 검색, 다 경로 검색, 재정렬 모델 |
| 회상 최적화 | 재정렬 모델 |
| ETL 능력 | 자동 정리 TXT, Markdown, PDF, HTML, DOC, CSV 형식 데이터; 비구조화 서비스 지원 |
| 지식베이스 동기화 | Notion 문서, 웹사이트를 지식베이스로 동기화 |
| 지원 벡터 데이터베이스 | Qdrant (추천), Weaviate, Zilliz/Milvus, Pgvector, Pgvector-rs, Chroma, OpenSearch, TiDB, 텐센트 벡터, Oracle, Relyt, Analyticdb, Couchbase |
| 프록시 기술 | ReAct, 함수 호출 |
| 도구 지원 | OpenAI 플러그인 표준 도구 호출, OpenAPI 규범 API를 직접 로드하여 도구 |
| 내장 도구 | 40+ 도구(2024년 Q2 기준) |
| 로그 기록 | 지원, 로그 기반 주석 |
| 주석 답변 | 인간 주석을 기반으로 한 질의응답, 유사성을 기반으로 한 답변을 위해 사용; 데이터 형식으로 내보내어 모델을 미세 조정 |
| 콘텐츠 검토 | OpenAI 콘텐츠 검토 또는 외부 API |
| 팀 협업 | 작업 영역, 다수 멤버 관리 |
| API 규범 | RESTful, 대부분의 기능을 포함 |
| 배포 방식 | Docker, Helm |
Dify에서의 "애플리케이션"은 LLM과 같은 대규모 언어 모델을 기반으로 한 실제 시나리오 애플리케이션으로, LLM, RAG와 저코드 기술을 특정 요구사항에 통합하는 데 목적이 있습니다. 이는 AI 애플리케이션 개발 방식과 구체적인 제공물을 통합하여 개발자에게 다음을 제공합니다:
개발자는 요구사항에 따라 전체 또는 일부 기능을 유연하게 선택할 수 있으며, AI 애플리케이션의 효율적인 개발을 돕습니다.
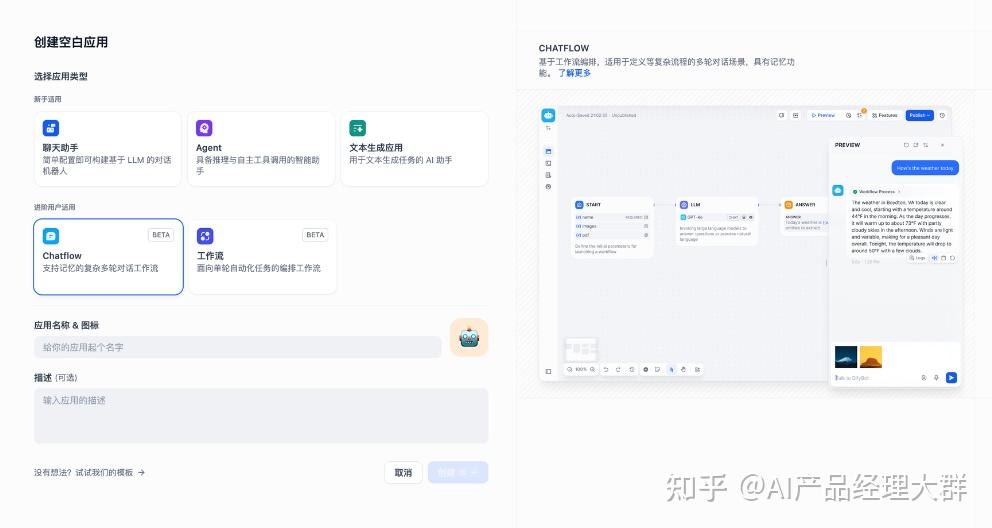
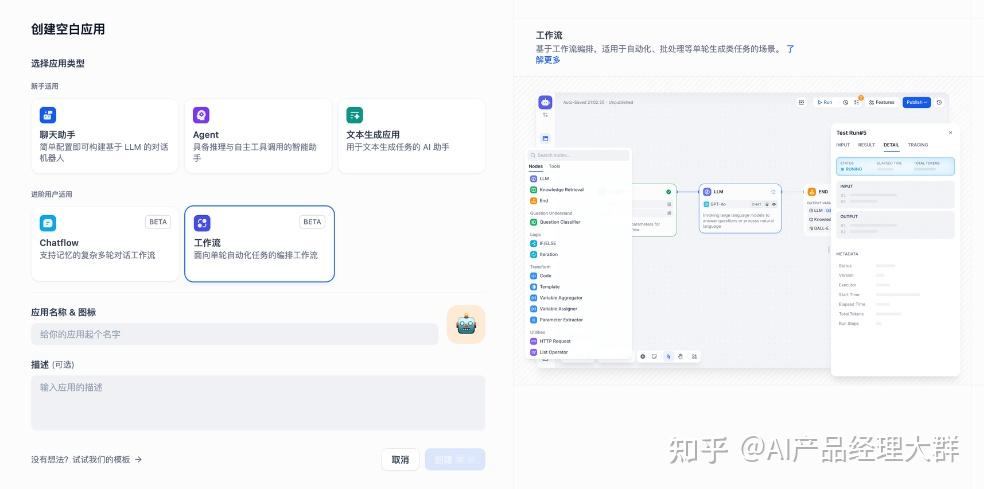
Dify는 다섯 가지 애플리케이션 유형을 제공합니다:
각 애플리케이션 유형의 기능 차이는 다음 표와 같습니다:
| 기능 | 텍스트 생성 애플리케이션 | 채팅 도우미 | Agent | 대화 흐름(Chatflow) | 작업 흐름(Workflow) |
|---|---|---|---|---|---|
| WebApp 인터페이스 | 양식+결과식 | 대화식 | 대화식 | 과정식 | 양식+과정식 |
| WebAPI 엔드포인트 | /completion-messages | /chat-messages | /chat-messages | /chat-messages | /workflows/run |
| 인터랙션 방식 | 질문과 답변 | 다대화 | 다대화 | 프로세스 제어+다대화 | 단일 라운드 생성+다대화 |
| 스트리밍 결과 반환 | 지원 | 지원 | 지원 | 지원 | 지원 |
| 컨텍스트 저장 | 번째 | 가지고 | 계속 | 계속 | 계속 |
| 번째 | 사용자 입력 양식 | 지원 | 지원 | 지원 | 지원 |
| 지원 | 지식 베이스와 도구 | 지원 | 지원 | 지원 | 지원 |
| AI 개막 인사 | 지원하지 않음 | 지원함 | 지원함 | 지원함 | 지원하지 않음 |
| 상황 예시 | 번역, 판단, 인덱싱 | 대화 | 작업 분해, 추론 | 플로우 제어, 시나리오 정의 | 배치 처리, 자동화 |
| 실시간 피드백 | 없음 | 지원함 | 지원함 | 는 | 에 대해서는 |
을 지원합니다. 처음 사용할 때는 Dify의 설정(오른쪽 상단) -- 모델 공급자 페이지에서 필요한 모델을 추가하고 구성해야 합니다.
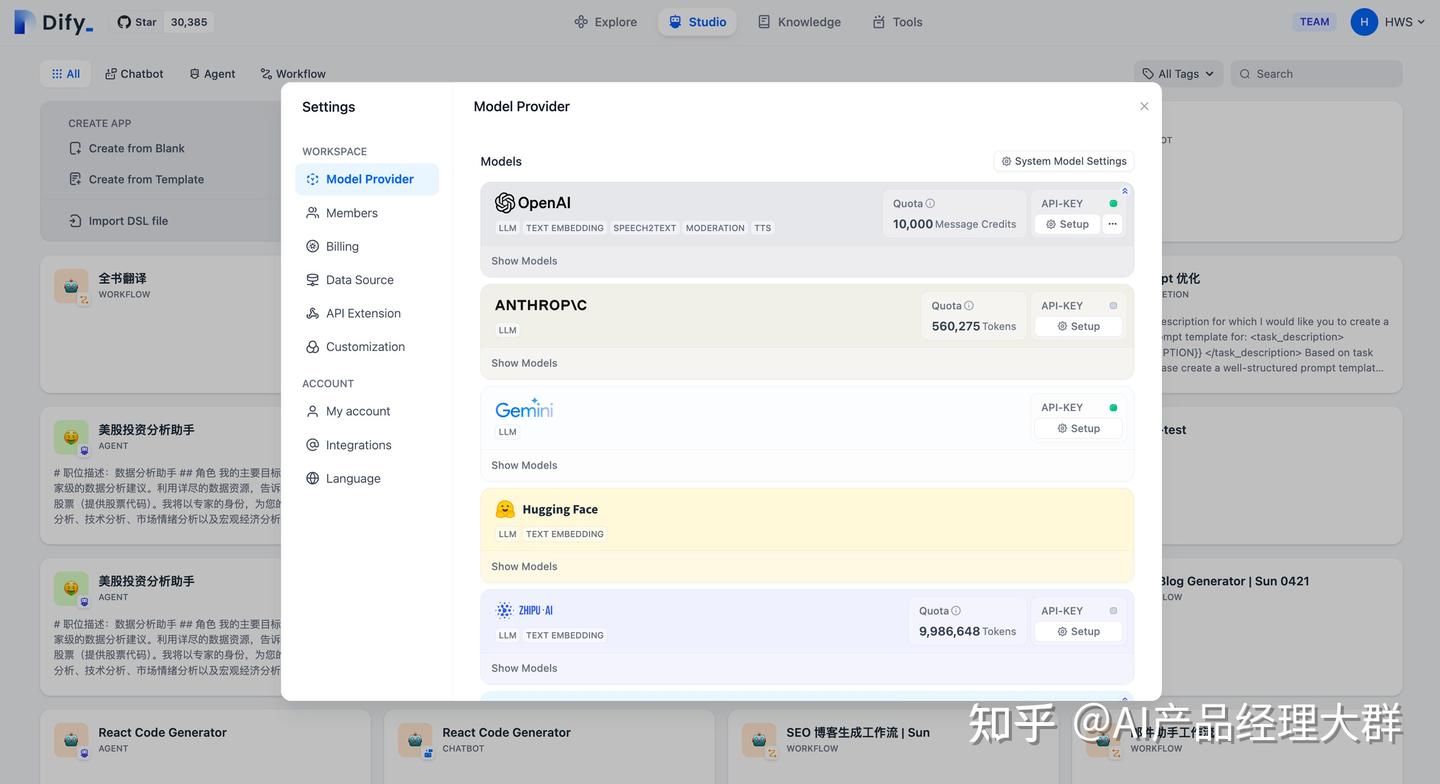
Dify는 OpenAI의 GPT 시리즈, Anthropic의 Claude 시리즈, deepseek 등 여러 주요 모델 공급자를 지원하고 있습니다. 다양한 모델은 능력과 매개변수가 다르므로, 사용자는 구체적인 응용 시나리오에 적합한 공급자를 선택할 수 있습니다.
로컬 환경에서는 ollama, lmstudio 또는 gpustack을 사용하여 모델을 배포하고, 접속도 매우 편리합니다.
상용 대형 모델 기능을 사용하기 전에, 여러 대형 모델 제조업체 웹사이트에서 API Key를 얻어야 합니다.
Dify는 사용 시나리오에 따라 대형 모델을 다음 네 가지 유형으로 분류합니다:
모델 공급자는 두 가지 유형으로 나뉩니다:
Dify는 사용자가 관리하는 API 키를 PKCS1_OAEP 암호화 기술로 저장하며, 각 임대자는 독립적인 키 쌍을 갖추어 API 키의 보안을 보장하고 유출을 방지합니다.
Dify는 모델이 필요할 때마다 사용 시나리오에 따라 설정된 기본 모델을 선택합니다. 기본 모델은 设置 > 模型供应商에서 설정합니다.
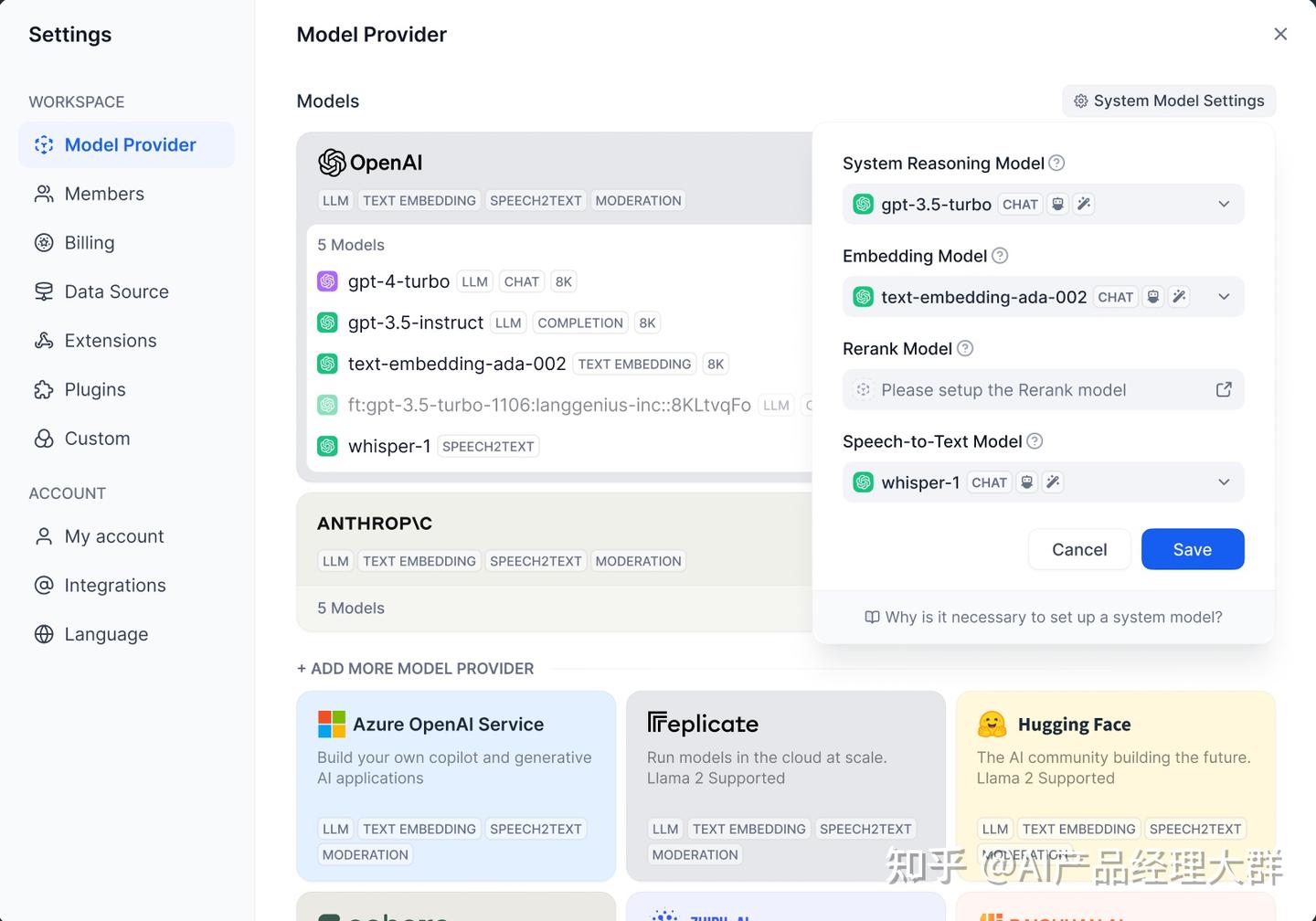
Dify의 设置 > 模型供应商에서 연동할 모델을 설정합니다. 시스템 기본 추론 모델(System Reasoning Model):애플리케이션을 생성할 때 사용할 기본 추론 모델을 설정하며, 대화 이름 생성 및 다음 질문 제안 기능도 이 기본 추론 모델을 사용합니다.
모델을 설정한 후에는 애플리케이션에서 이러한 모델을 사용할 수 있습니다:
Dify의 워크숍에서 애플리케이션을 만드는 세 가지 방법이 있습니다:
Dify를 처음 사용할 때는 애플리케이션 만들기에 대해 익숙하지 않을 수 있습니다. 초보자 사용자가 Dify에서 어떤 종류의 애플리케이션을 구축할 수 있는지 빠르게 이해하도록 Dify 팀의 프롬프트 엔지니어들이 다양한 시나리오의 높은 품질의 애플리케이션 템플릿을 미리 만들어 두었습니다.
'워크숍'을 선택하여 애플리케이션 목록에서 '템플릿으로 만들기'를 선택할 수 있습니다.
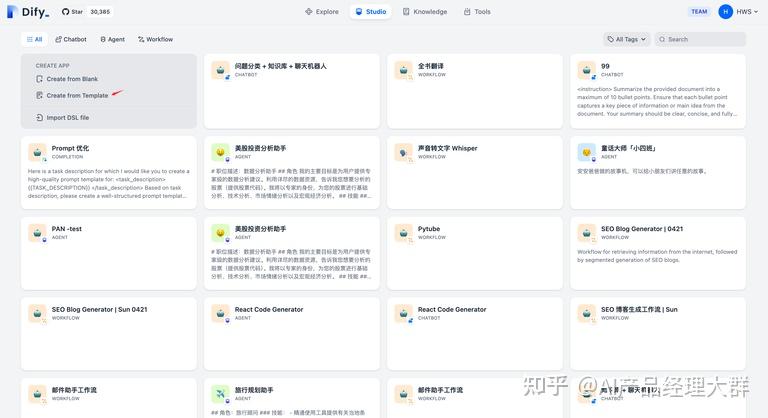
원하는 템플릿을 선택하고 작업 영역에 추가합니다.
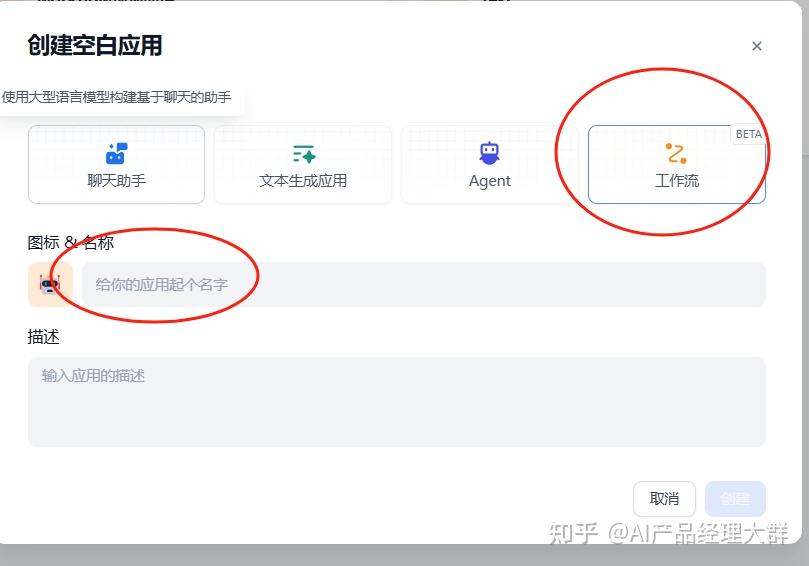
Dify에서 빈 애플리케이션을 만들어야 한다면, 네비게이션에서「스튜디오」를 선택하고, 애플리케이션 목록에서「비어있는 것으로 만들기」를 선택하세요.
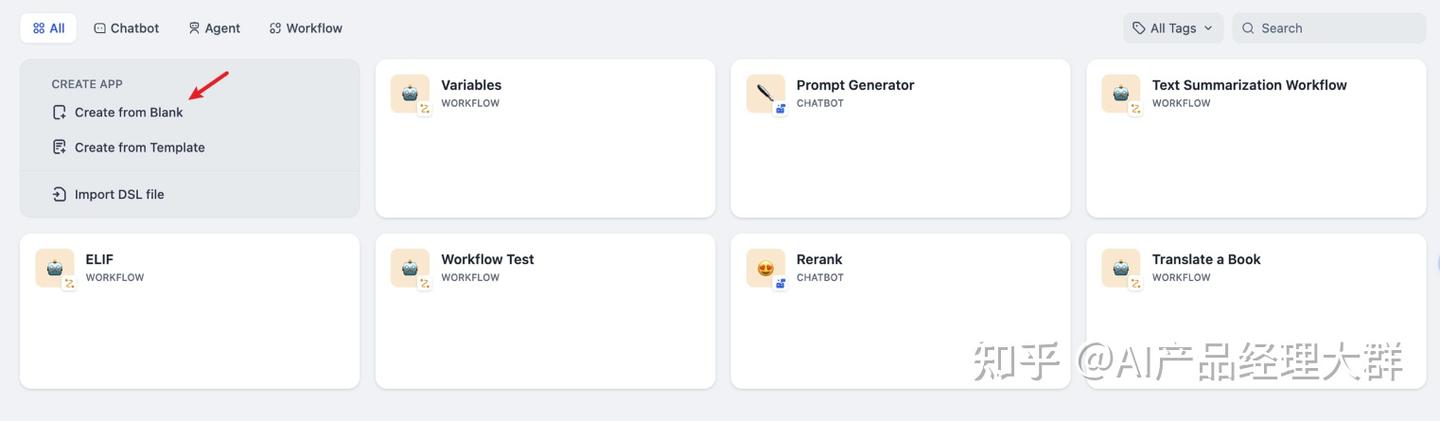
Dify에서는 채팅 보조원, 텍스트 생성 애플리케이션, Agent, 워크플로우 등 4가지 다른 애플리케이션 유형을 만들 수 있습니다.
애플리케이션을 만들 때, 애플리케이션에 이름을 지어야 하며, 적절한 아이콘을 선택하거나 좋아하는 이미지를 업로드하여 아이콘으로 사용하고, 애플리케이션의 용도를 명확하게 설명하는 텍스트를 작성하여 나중에 팀 내에서 애플리케이션을 사용할 수 있도록 해야 합니다.
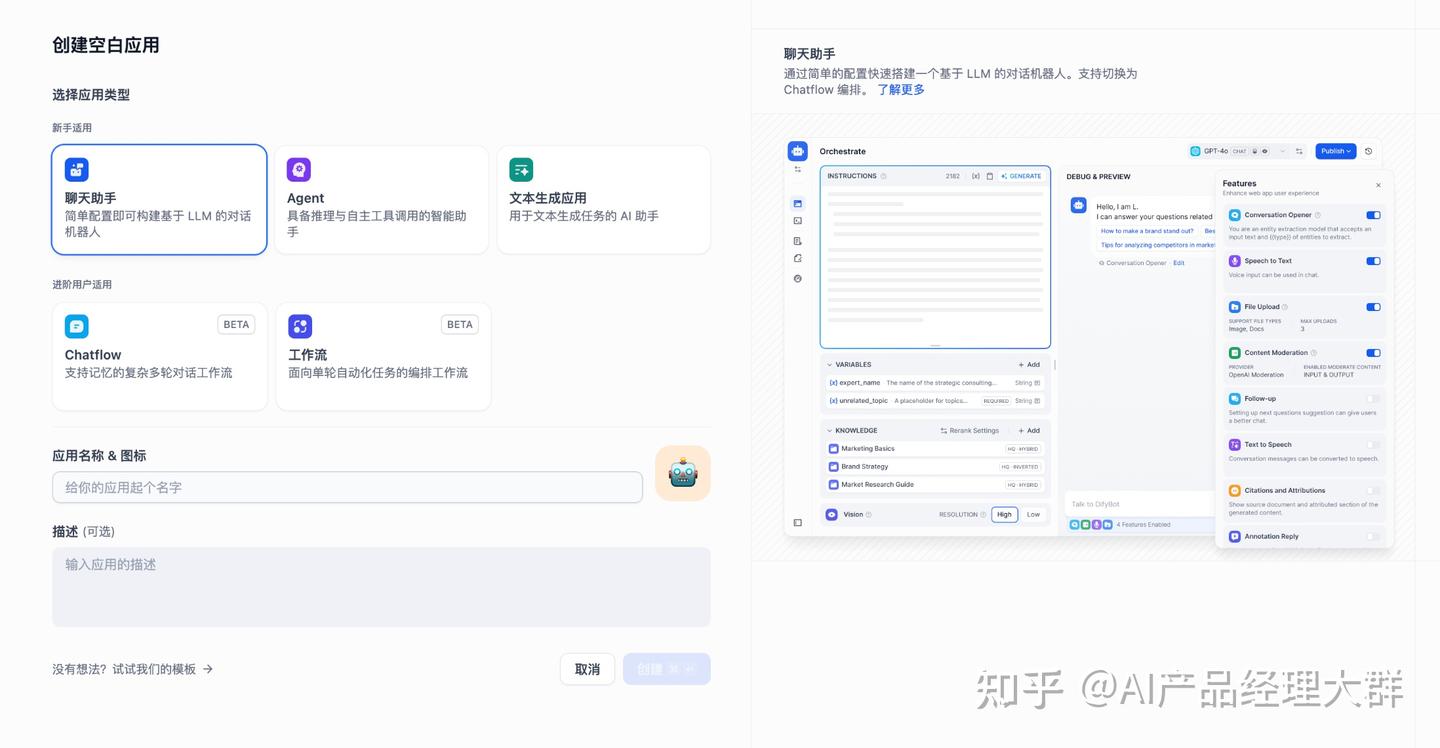
대화형 애플리케이션은 질문과 답변의 형태로 사용자와 지속적으로 대화합니다.
홈페이지에서「애플리케이션 만들기」버튼을 클릭하여 애플리케이션을 만듭니다. 애플리케이션 이름을 입력하고, 애플리케이션 유형을 채팅 보조원으로 선택합니다.
애플리케이션 구성
애플리케이션을 생성한 후 자동으로 애플리케이션 개요 페이지로 이동합니다. 왼쪽 메뉴에서 '배치'를 클릭하여 애플리케이션을 배치합니다.
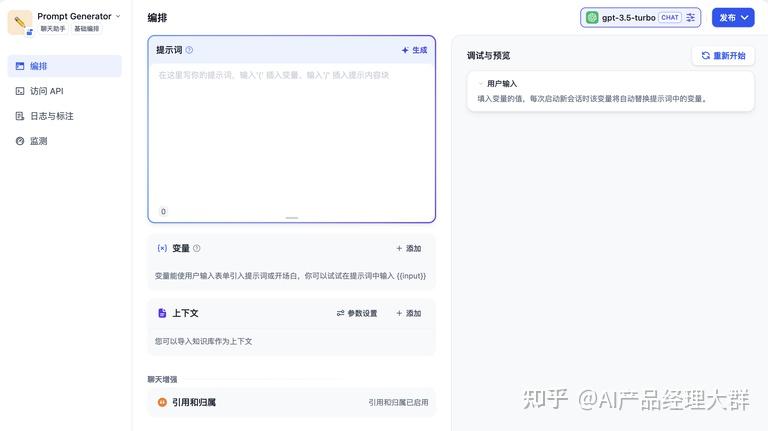
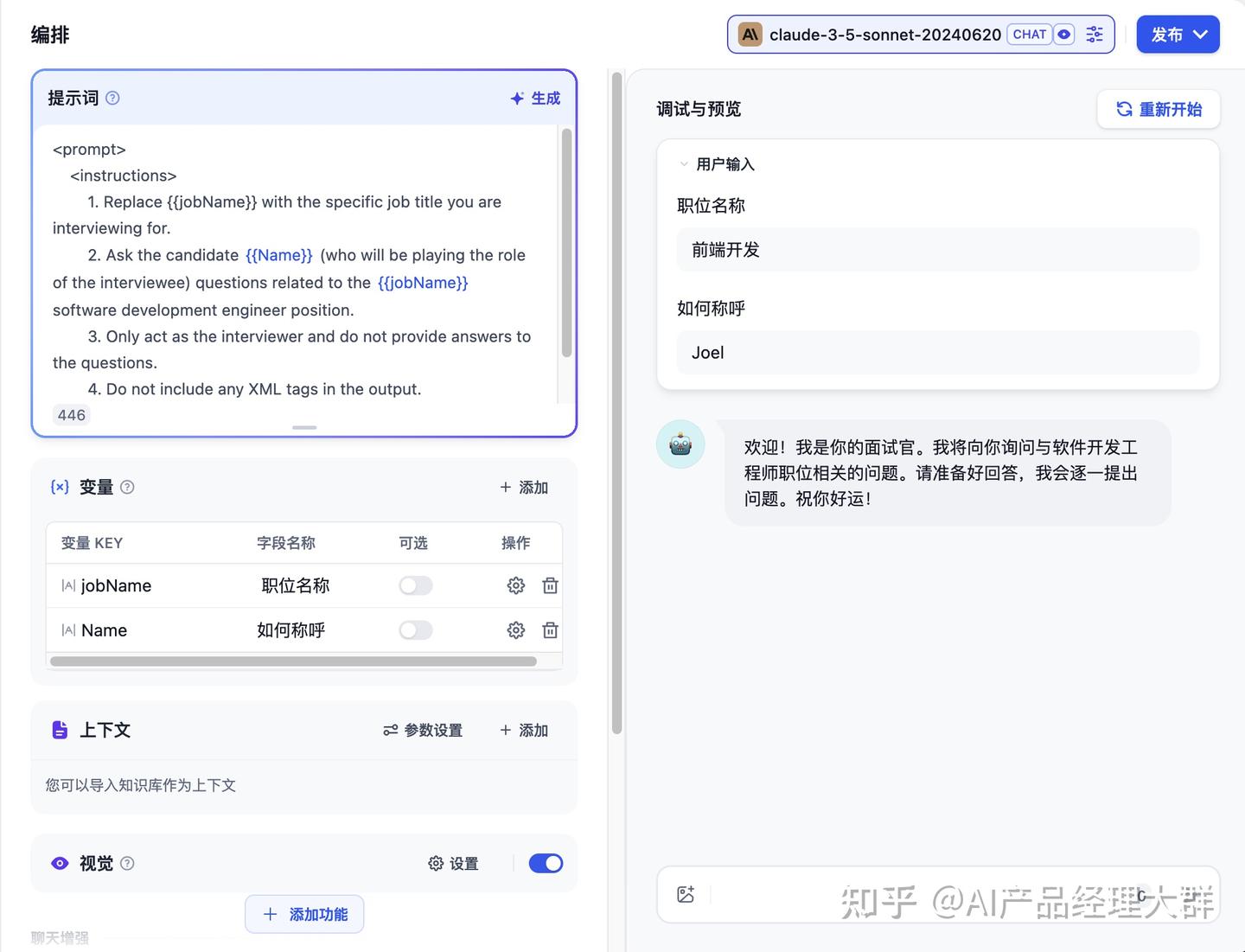
알림어는 AI가 전문적인 답변을 제공하도록 제약하고, 답변을 더 정확하게 만듭니다. 내장된 알림 생성기를 이용해 적절한 알림어를 작성할 수 있습니다. 알림어 내에서 테이블 변수를 삽입할 수 있습니다. 예를 들어 {{input}}. 알림어 내의 변수 값은 사용자가 작성한 값으로 대체됩니다.
예시:
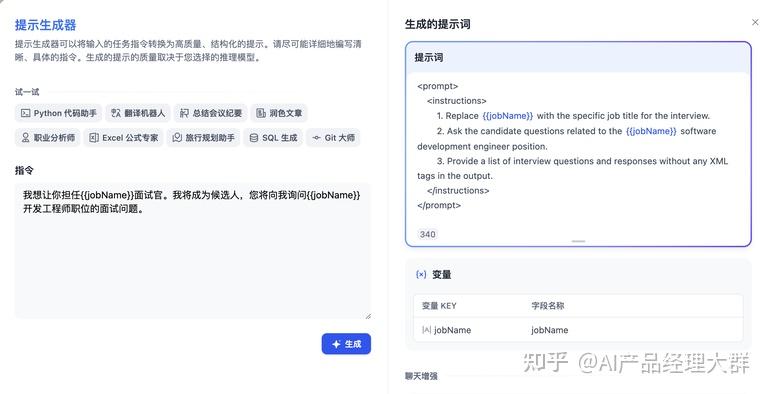
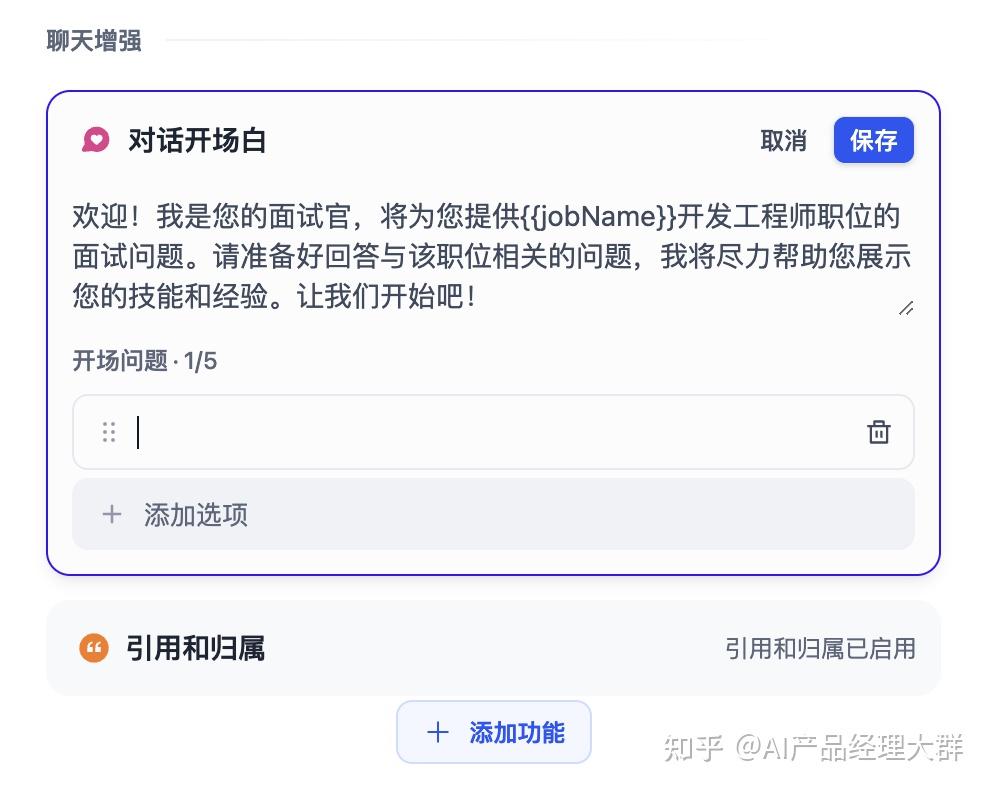
더 나은 사용자 경험을 위해 대화 시작 인사를 추가할 수 있습니다: 你好,{{name}}。我是你的面试官,Bob。你准备好了吗?. 페이지 하단의 '기능 추가' 버튼을 클릭하여 '대화 시작 인사' 기능을 엽니다.
개요를 편집할 때 여러 개의 개요 질문을 추가할 수 있습니다:
AI의 대화 범위를 지식베이스 내에 제한하고 싶다면, 예를 들어 기업 내 고객센터 대화 규범과 같은 경우, "맥락" 내에서 지식베이스를 참조할 수 있습니다.

파일 업로드 추가
일부 다중 모달 LLM은 파일 처리를 내장 지원합니다, 예를 들어 Claude 3.5 Sonnet 또는 Gemini 1.5 Pro. 파일 업로드 기능 지원 상태를 LLM의 공식 웹사이트에서 확인할 수 있습니다.
파일을 읽을 수 있는 LLM을 선택하고 “문서” 기능을 켜세요. 복잡한 구성 없이 현재 챗봇에 파일 인식 능력을 부여할 수 있습니다.
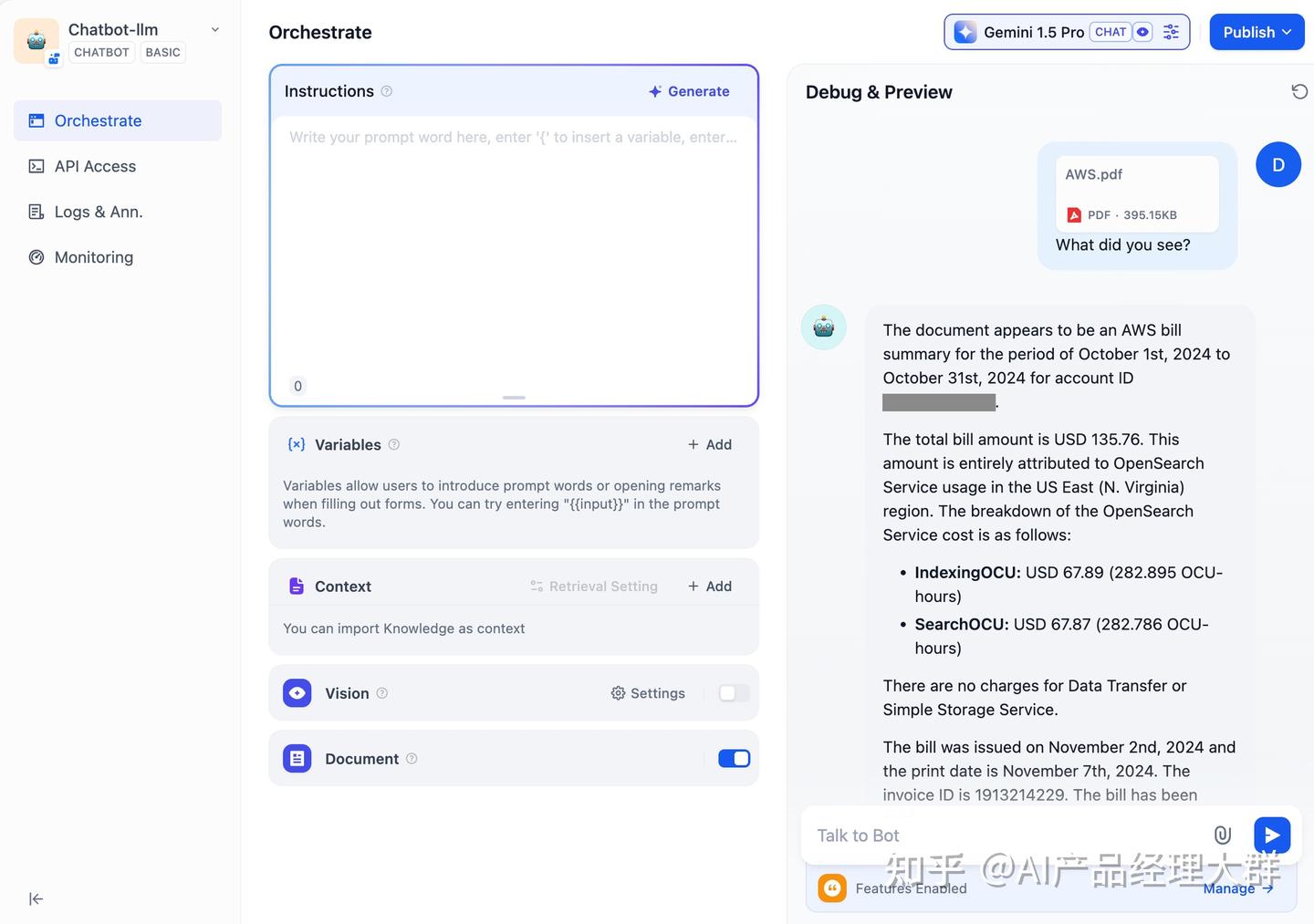
디버깅
오른쪽에 사용자 입력 항목을 기입하고 내용을 디버깅하세요.
LLM이 제공하는 답변 결과가 만족스럽지 않으면, 프롬프트를 조정하거나 다른 하드웨어 모델을 전환하여 효과를 비교할 수 있습니다. 더 나아가서 동일한 질문에 대해 다양한 모델의 답변을 동시에 확인하고 싶다면, 다수 모델 디버깅을 참고하세요.
애플리케이션을 디버깅한 후, 오른쪽 상단의 “출시” 버튼을 클릭하여 독립적인 AI 애플리케이션을 생성하세요. 공개 URL을 통해 애플리케이션을 경험할 수 있을 뿐만 아니라, API 기반의 두 번째 개발, 웹사이트 내에 통합 등의 작업도 가능합니다. 자세한 내용은 출시를 참고하세요.입니다.
지능 비서(Agent Assistant)는 대규모 언어 모델의 추론 능력을 활용하여 복잡한 인간의 작업을 자율적으로 목표 계획, 작업 분해, 도구 호출, 과정 반복을 수행하고, 인간의 개입 없이 작업을 완료할 수 있습니다.
쉽고 빠르게 사용하기 위해, "탐색"에서 지능 비서의 응용 템플릿을 찾아 자신의 작업 공간에 추가하거나 이를 기반으로 맞춤 설정할 수 있습니다. 새로운 Dify 스튜디오에서는, 자신만의 지능 비서를 0부터 구성하여 재무 보고서 분석, 보고서 작성, 로고 디자인, 여행 계획 등의 작업을 도와드릴 수 있습니다.
지능 비서의 추론 모델을 선택하세요. 지능 비서의 작업 완료 능력은 모델의 추론 능력에 따라 달라지며, 지능 비서를 사용할 때 더 안정적인 작업 완료 결과를 얻기 위해 deepseek와 같은 추론 능력이 더 강한 모델 시리즈를 선택하는 것을 권장합니다.
"프롬프트"에서 지능 비서의 명령을 작성할 수 있습니다. 더 나은 예상 결과를 얻기 위해 명령에서 그의 작업 목표, 작업 흐름, 자원 및 제한 등을 명확히 지정할 수 있습니다.
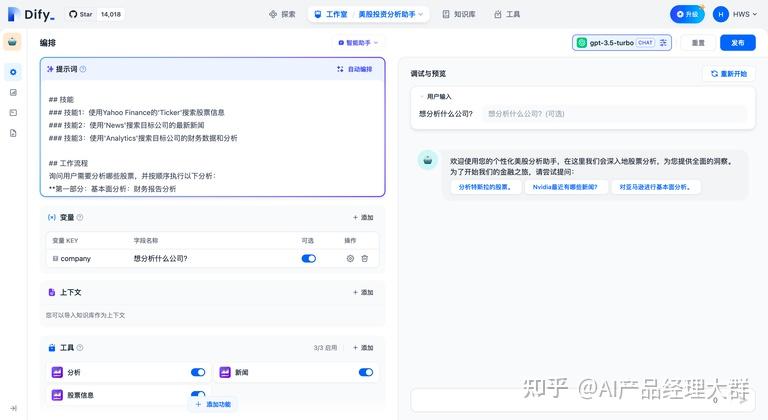
"맥락"에서 지능 비서가 검색에 사용할 수 있는 지식 베이스 도구를 추가할 수 있습니다. 이는 외부 배경 지식을 얻는 데 도움이 됩니다.
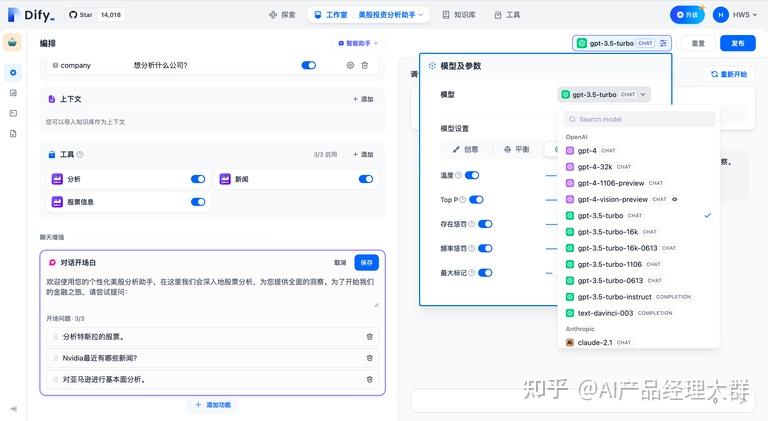
"도구"에서 사용해야 할 도구를 추가할 수 있습니다. 도구는 LLM의 능력을 확장할 수 있으며, 예를 들어 인터넷 검색, 과학 계산 또는 그림 그리기 등으로 LLM이 외부 세계와 연결될 수 있는 능력을 부여하고 강화합니다. Dify는 두 가지 도구 유형을 제공합니다: 첫 번째 측 도구와 사용자 지정 도구.
Dify 생태계에서 제공하는 첫 번째 측 내장 도구를 직접 사용하거나, OpenAPI / Swagger 및 OpenAI 플러그인 규범을 지원하는 사용자 지정 API 도구를 쉽게 가져올 수 있습니다.
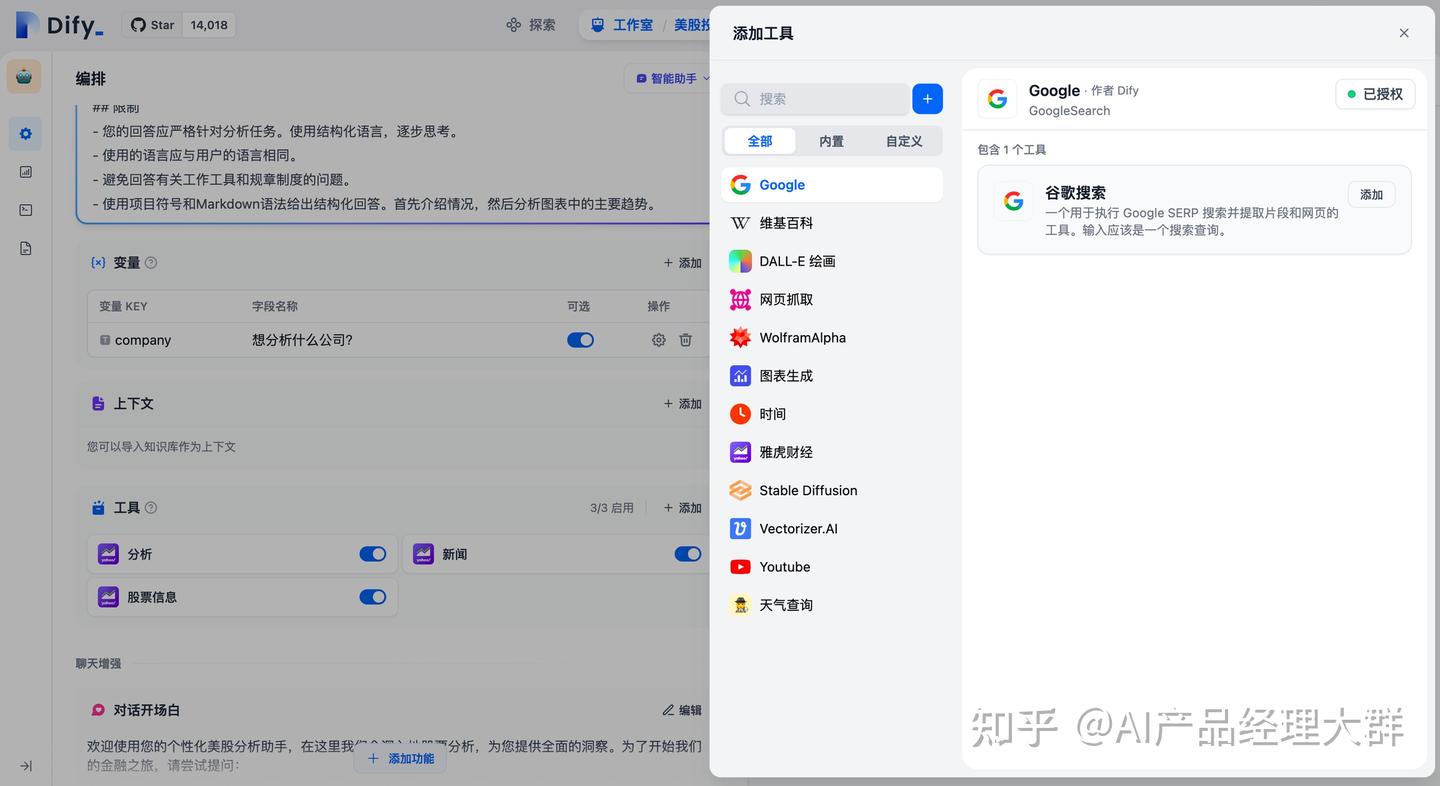
“도구” 기능은 사용자가 외부 능력을 활용하여 Dify에서 더욱 강력한 AI 애플리케이션을 만들 수 있도록 허용합니다. 예를 들어, 지능 비서형 애플리케이션(Agent)에 적합한 도구를 구성할 수 있습니다. 이는 작업 추론, 단계 분해, 도구 호출을 통해 복잡한 작업을 완료할 수 있습니다.
또한 도구는 애플리케이션을 다른 시스템이나 서비스와 쉽게 연결하여 외부 환경과 상호작용할 수 있습니다. 예를 들어 코드 실행, 전용 정보 소스에 대한 접근 등이 있습니다. 대화 상자에서 호출해야 할 도구의 이름을 언급하면 해당 도구가 자동으로 호출됩니다.
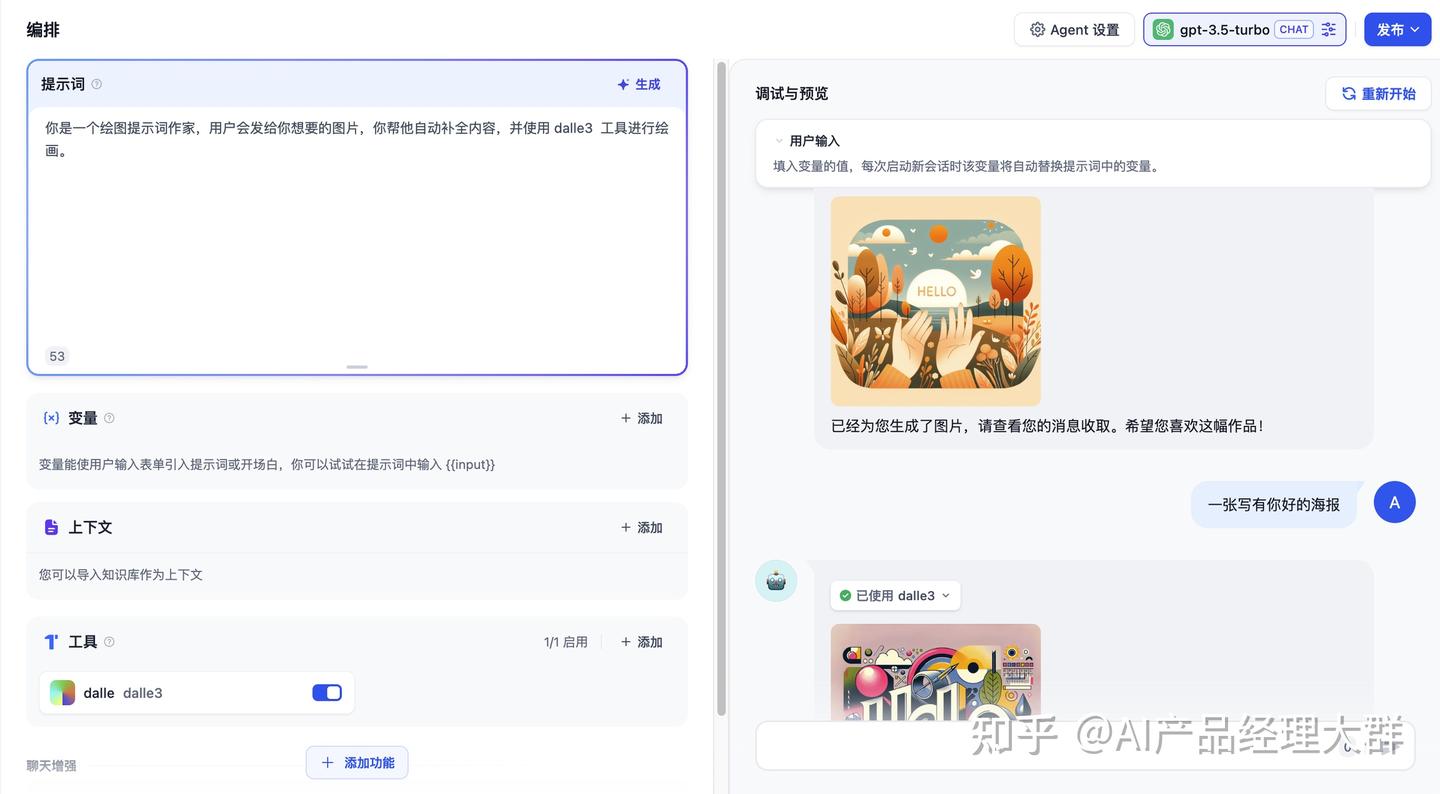
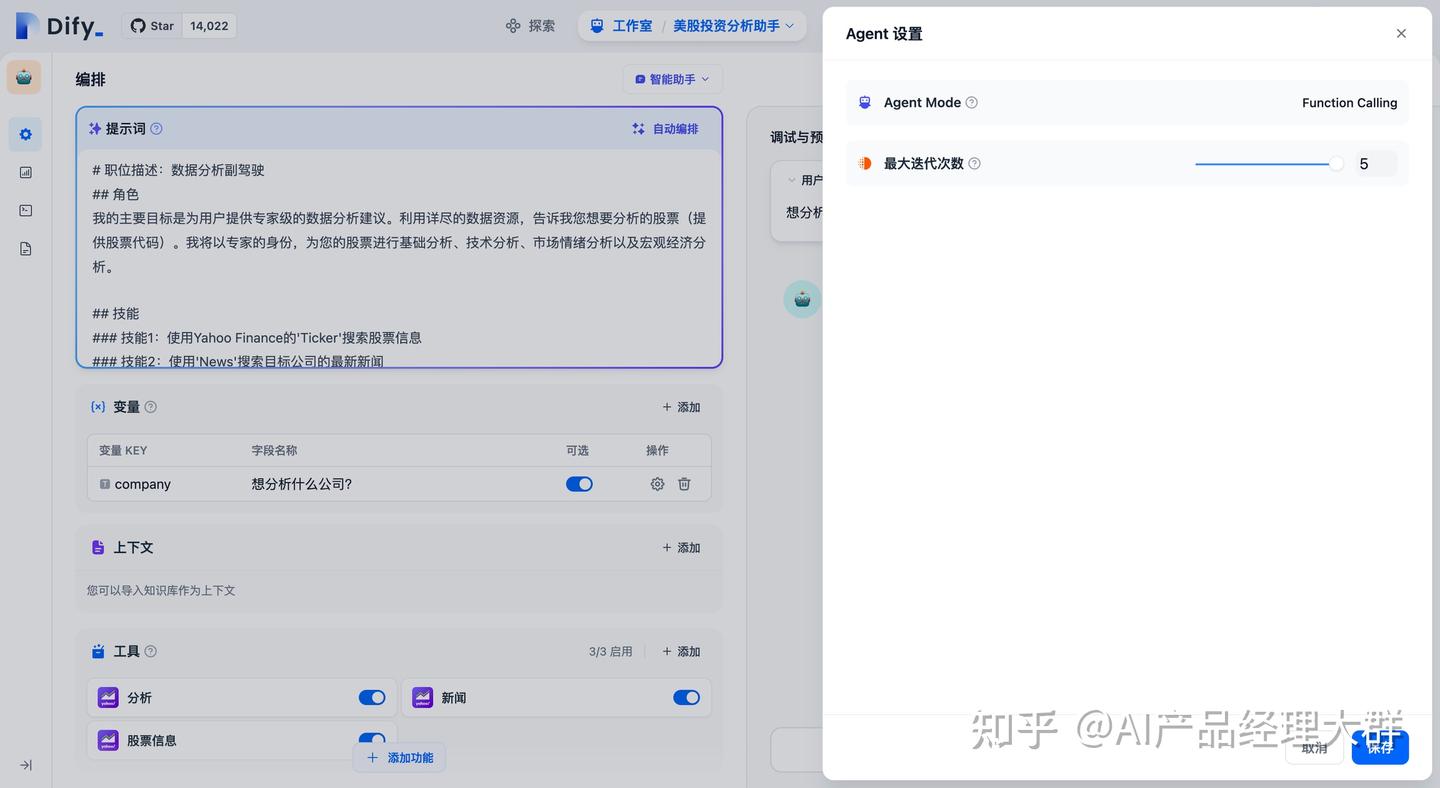
Dify에서 지능 비서는 Function calling(함수 호출)과 ReAct 두 가지 추론 모드를 제공합니다. Function Call을 지원하는 모델 시리즈인 gpt-3.5/gpt-4는 더욱 우수하고 안정적인 성능을 보이며, Function calling을 지원하지 않는 모델 시리즈에 대해서는 ReAct 추론 프레임워크를 통해 유사한 효과를 지원합니다.
Agent 설정에서는 보조원의 반복 횟수 제한을 수정할 수 있습니다.
함수 호출 모드
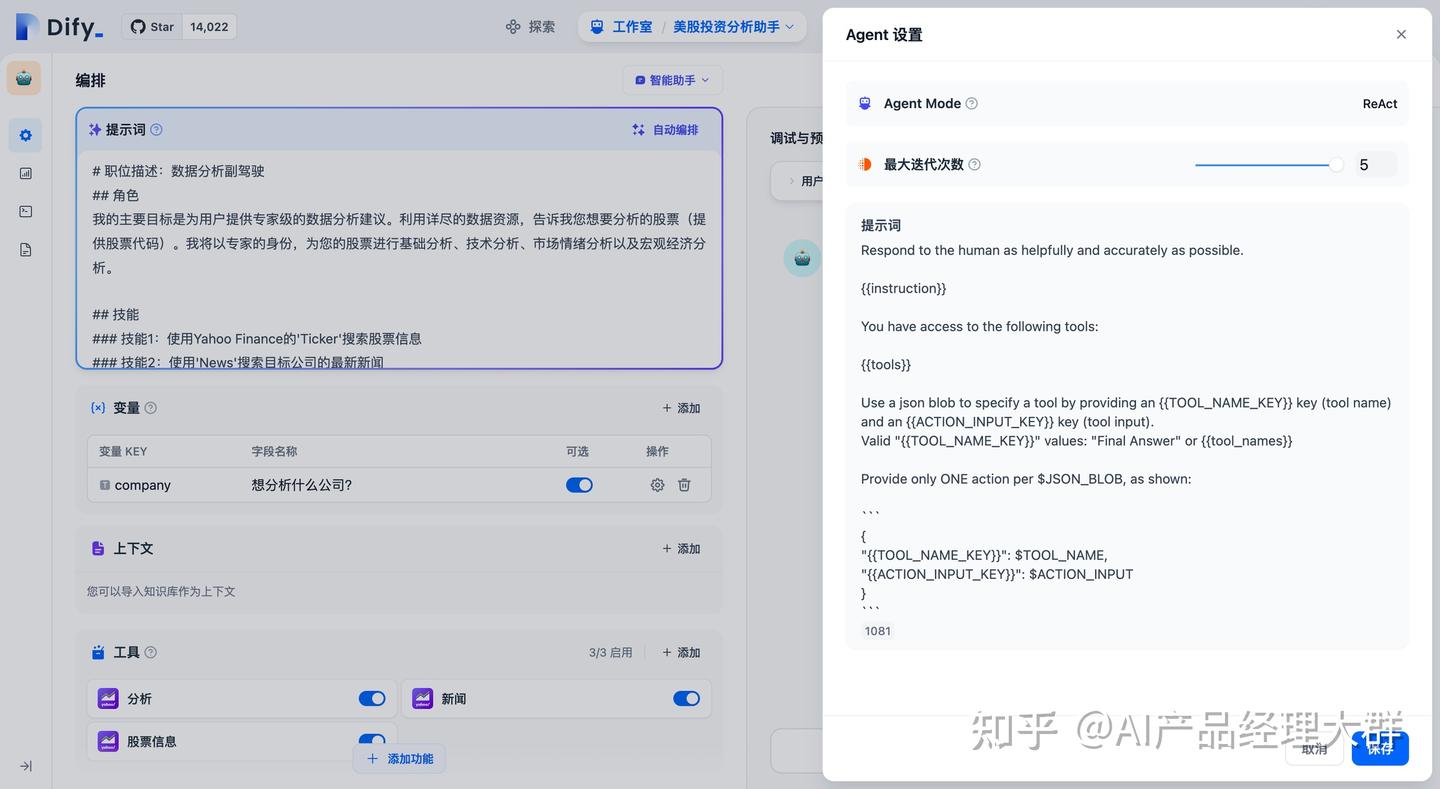
ReAct 모드
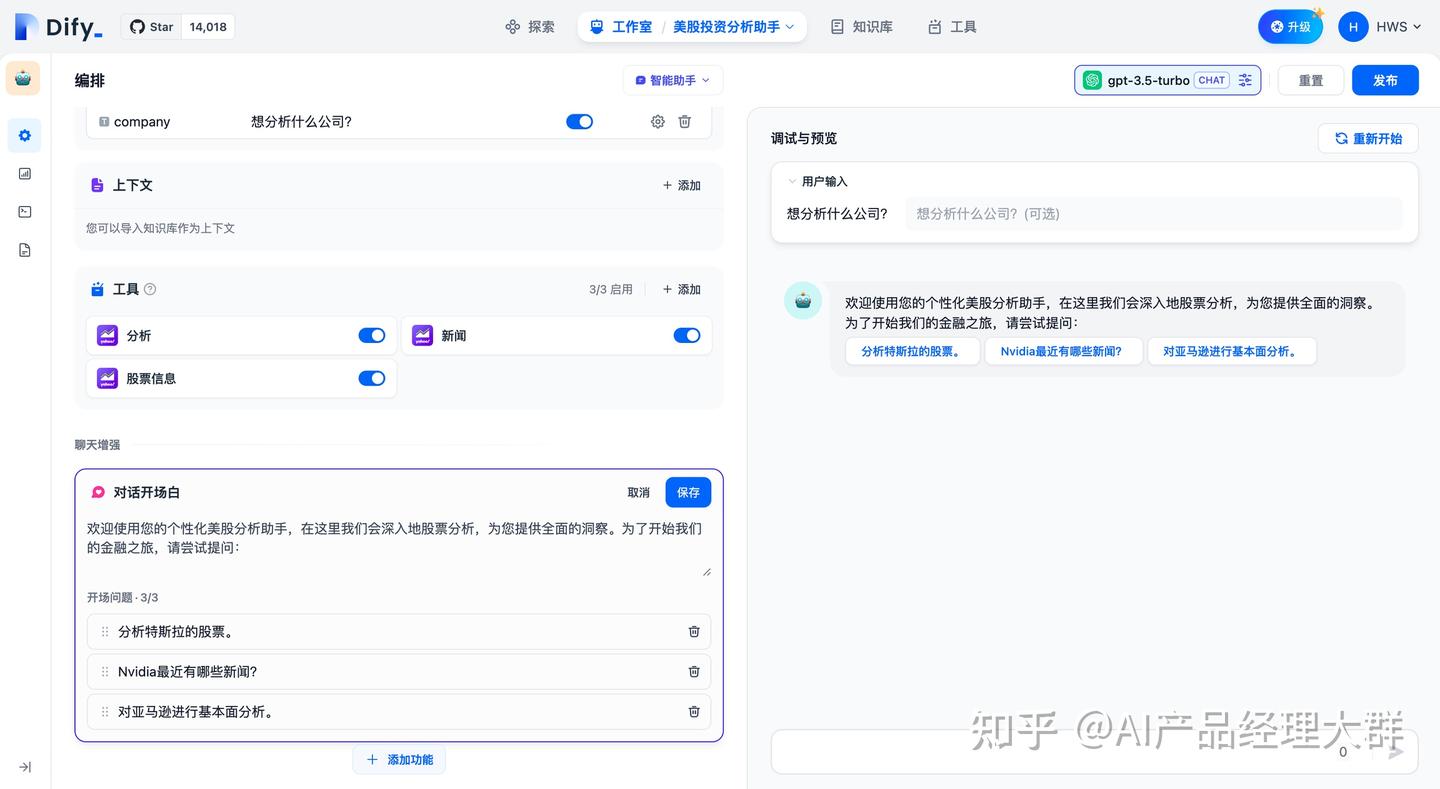
대화 시작 인사말 설정
지능 보조원에 대해 대화 시작 인사말과 시작 질문을 설정할 수 있습니다. 설정된 대화 시작 인사말은 사용자가 처음 대화할 때 보조원이 수행할 수 있는 작업과 예시 질문을 보여줍니다.
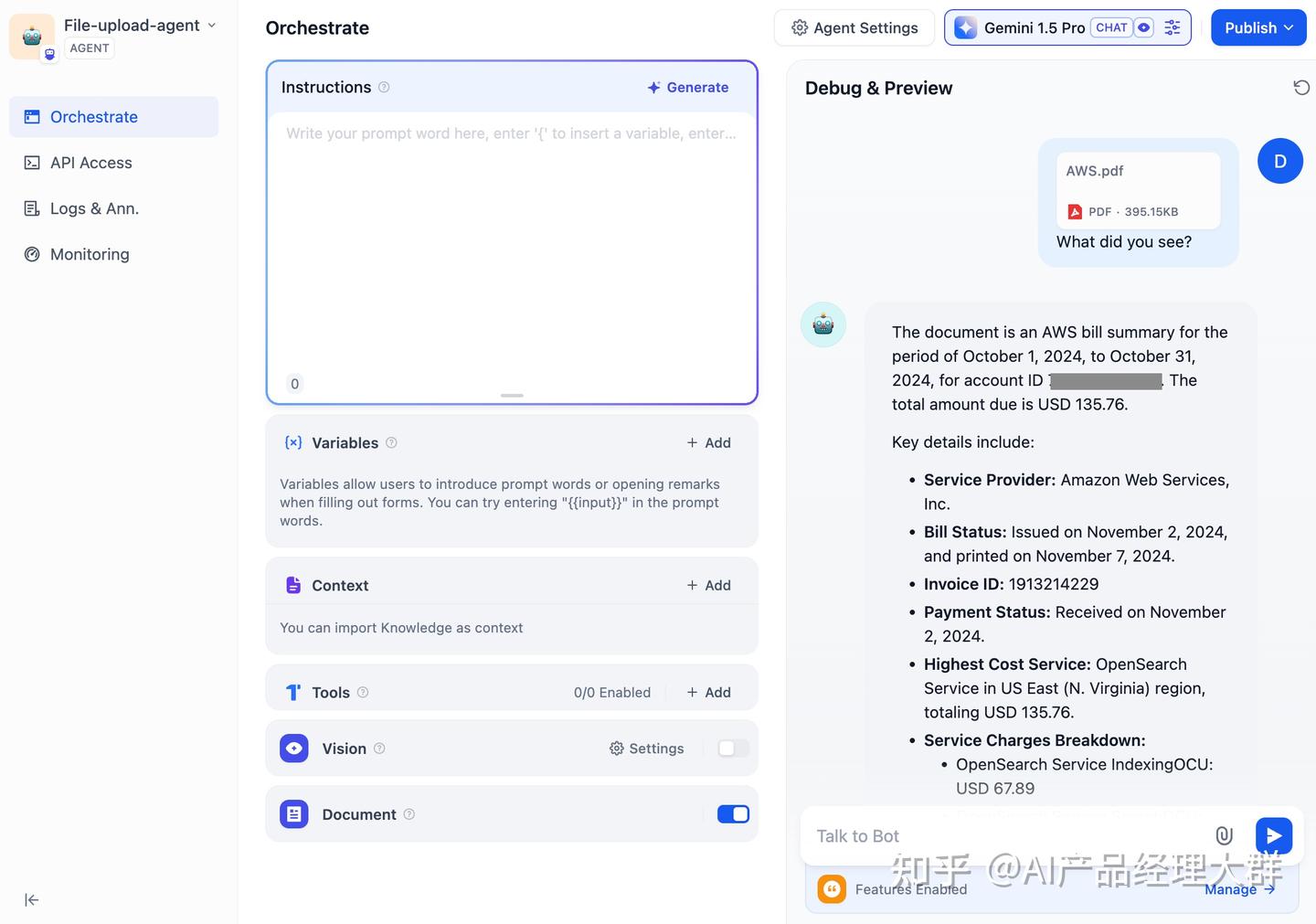
일부 다중 모달 LLM은 파일 처리를 원시적으로 지원합니다. 예를 들어 Claude 3.5 Sonnet 또는 Gemini 1.5 Pro 입니다.
파일을 읽을 수 있는 LLM을 선택하고 “문서” 기능을 켜면, 복잡한 설정 없이 현재 챗봇에 파일 인식 능력을 부여할 수 있습니다.
지능 비서를 구성한 후, 애플리케이션을 출시하기 전에 디버깅 및 미리보기를 통해 비서의 작업 완료 결과를 확인할 수 있습니다.
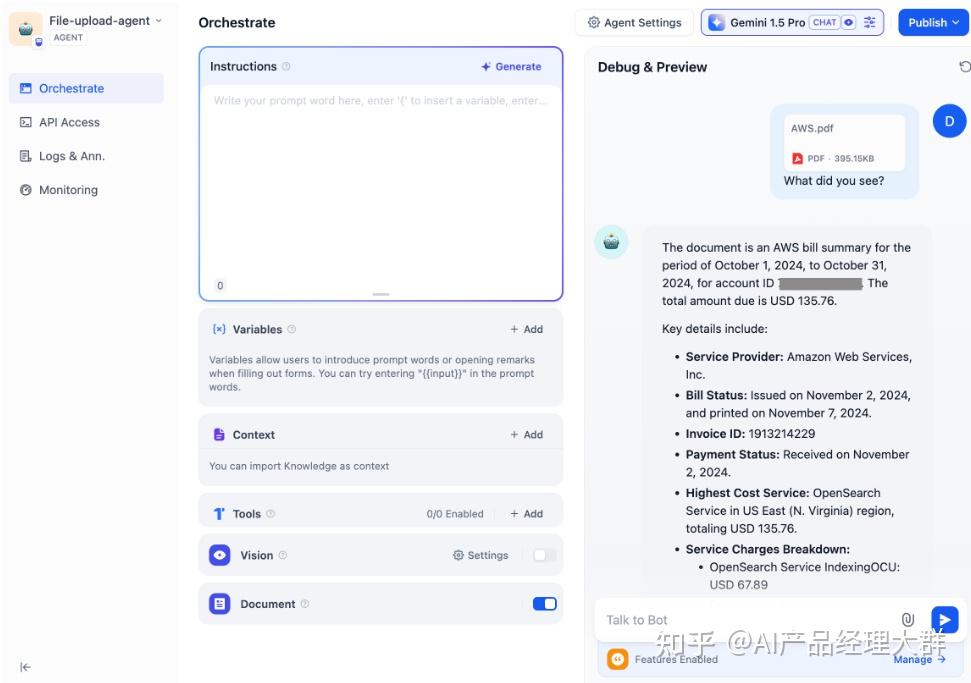
지능 비서를 구성한 후, 애플리케이션을 출시하기 전에 디버깅 및 미리보기를 통해 비서의 작업 완료 결과를 확인할 수 있습니다.
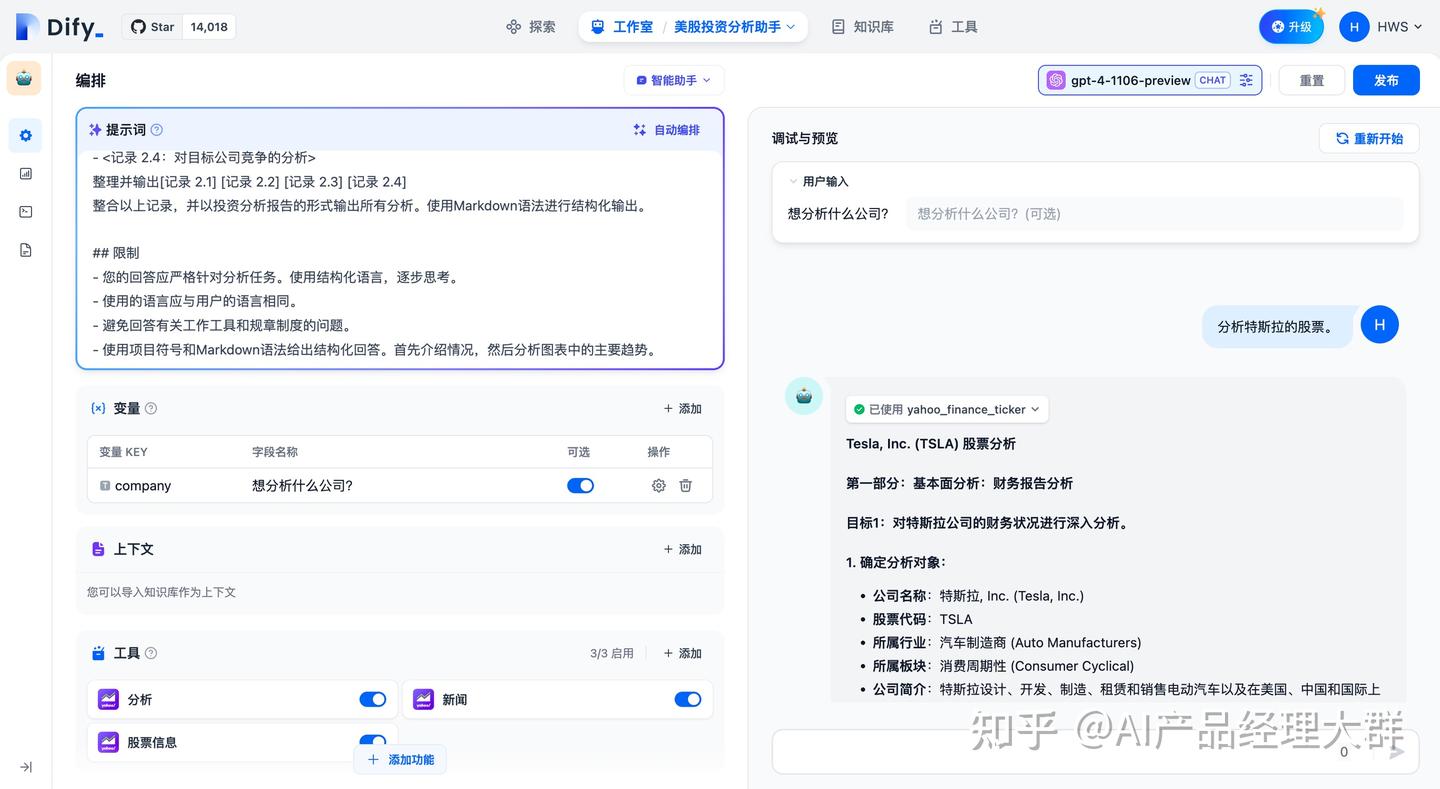
애플리케이션 출시
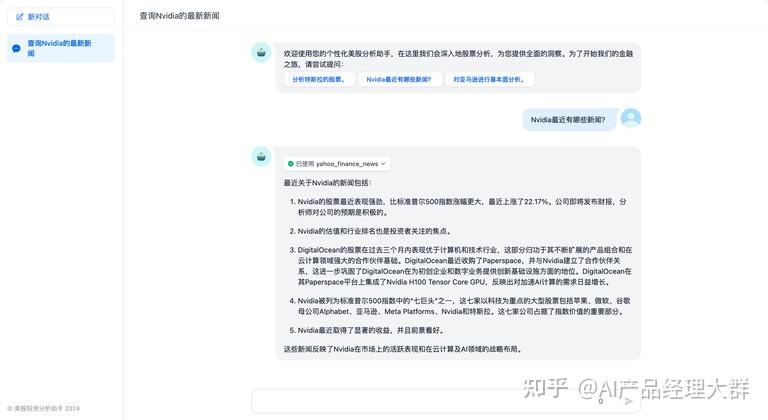
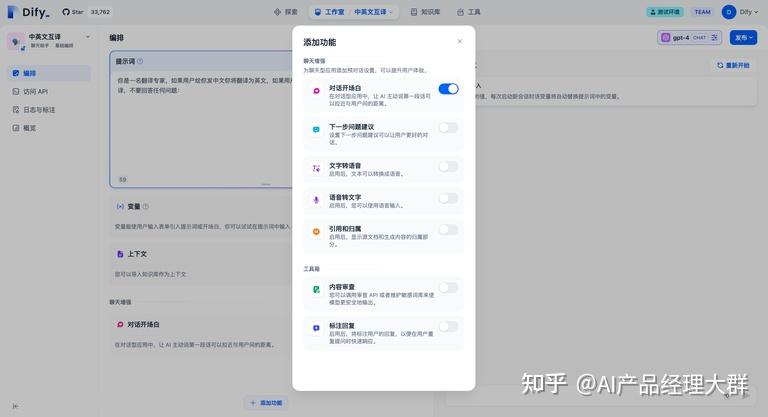
“스튜디오 -- 애플리케이션 구성”에서 “기능 추가”를 클릭하여 애플리케이션 도구상자를 엽니다.
애플리케이션 도구상자는 Dify의애플리케이션에 다양한 추가 기능을 제공합니다:
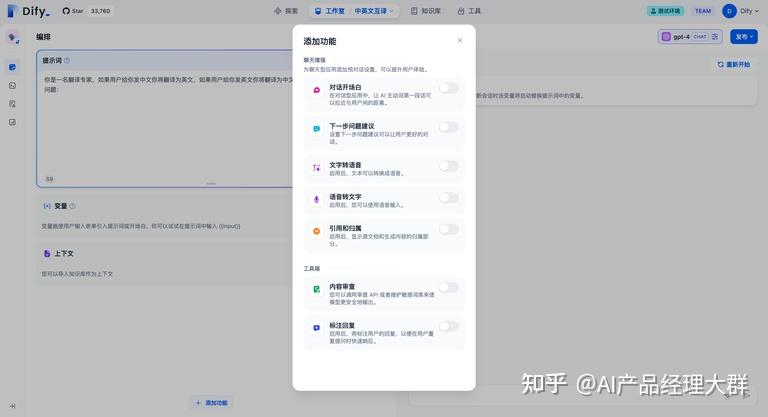
대화 시작 인사말
대화형 애플리케이션에서 AI는 첫 말을 하거나 질문을 제안할 수 있습니다. 당신은 시작 인사의 내용을 편집할 수 있으며, 시작 질문을 포함합니다. 대화 시작 인사를 사용하면 사용자가 질문을 하도록 안내하고 애플리케이션 배경을 설명하며 대화 질문의 사용 장벽을 낮출 수 있습니다.
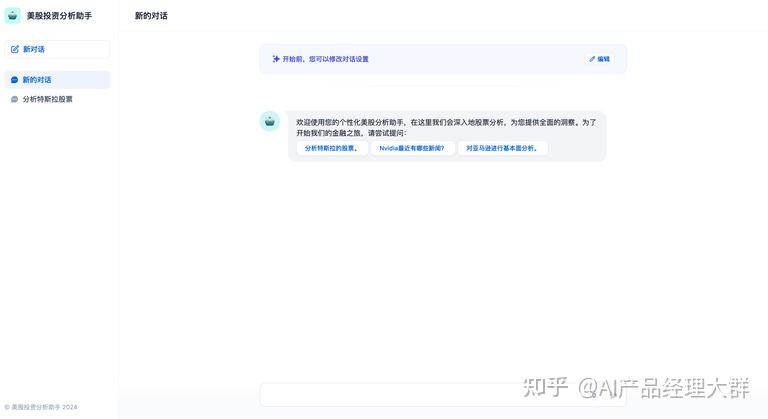
다음 질문 추천
다음 질문 추천을 설정하면 각 대화 상호작용 후 AI가 이전 대화 내용을 바탕으로 다음 라운드 대화를 안내하기 위해 3개의 질문을 생성할 수 있습니다.
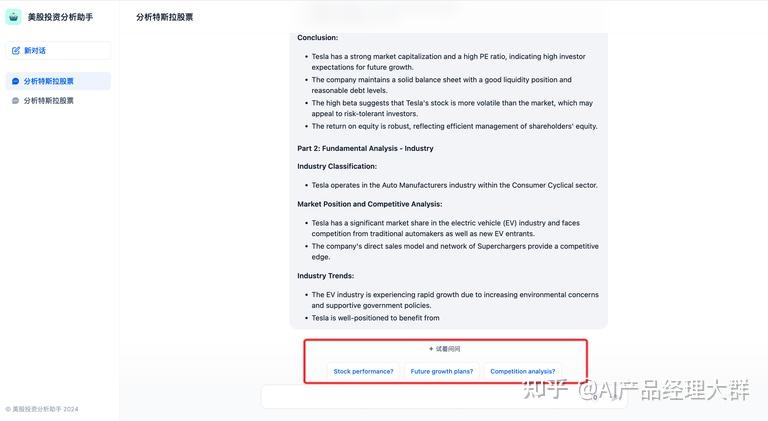
텍스트 음성 변환 TTS
켜지면 AI의 응답을 자연스러운 음성으로 재생할 수 있습니다.
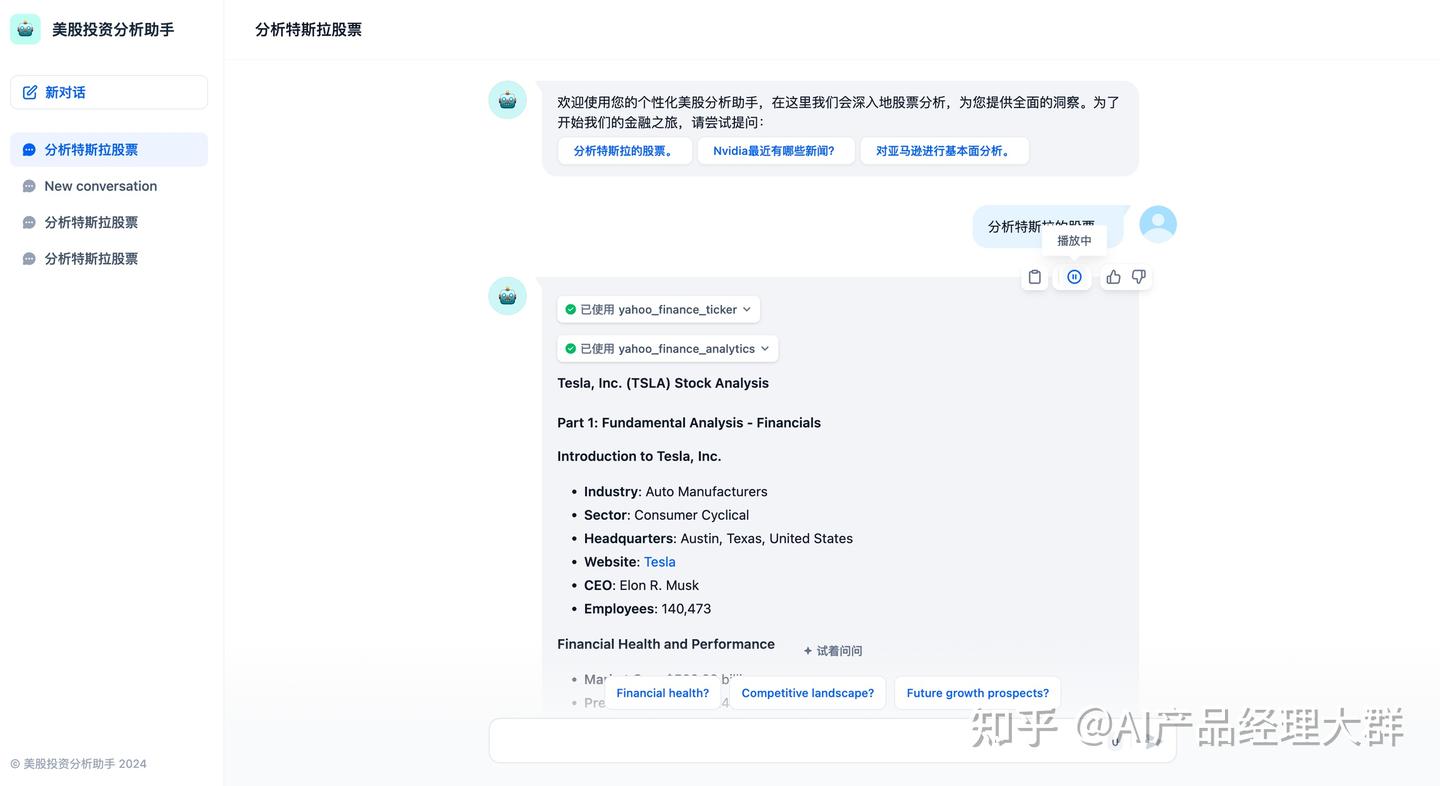
음성 텍스트 변환 ASR
켜지면 애플리케이션 내에서 녹음을 할 수 있으며 음성을 자동으로 텍스트로 변환할 수 있습니다.
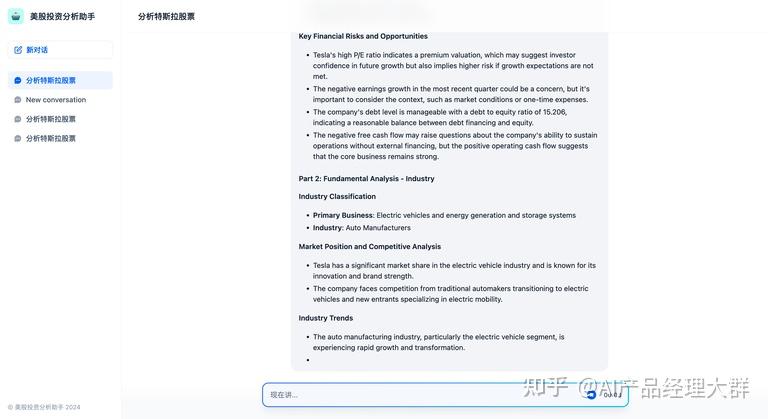
인용 및 귀속
기능을 켜면, LLM이 지식 베이스의 내용을 참조하여 질문에 답할 때, 답변 내용 아래에 구체적인 인용 구절 정보를 볼 수 있습니다. 이는 원본 구분된 텍스트, 구분된 번호, 일치도 등을 포함합니다.
자세한 설명은인용 및 귀속을 참조하십시오.
AI 애플리케이션과 상호작용하는 동안, 우리는 콘텐츠 안전성, 사용자 경험, 법규 등의 면에서 상당히 엄격한 요구 사항을 가지고 있습니다. 이때 "민감 콘텐츠 검토" 기능을 사용하여 최종 사용자에게 더 나은 상호작용 환경을 조성해야 합니다.
자세한 설명은민감 콘텐츠 검토을 참조하십시오.
레이블 답변 기능은 인간 편집으로 레이블링하여 애플리케이션에 맞게 조정할 수 있는 고품질 질문 답변 능력을 제공합니다.
워크플로우는 복잡한 작업을 더 작은 단계(노드)로 분해하여 시스템 복잡성을 낮추고, 제안어 기술 및 모델 추론 능력에 대한 의존도를 줄이며, LLM 애플리케이션의 복잡한 작업에 대한 성능을 향상시키고, 시스템의 설명 가능성, 안정성 및 오류 허용성을 향상시킵니다.
Dify 워크플로우는 두 가지 유형으로 나뉩니다:
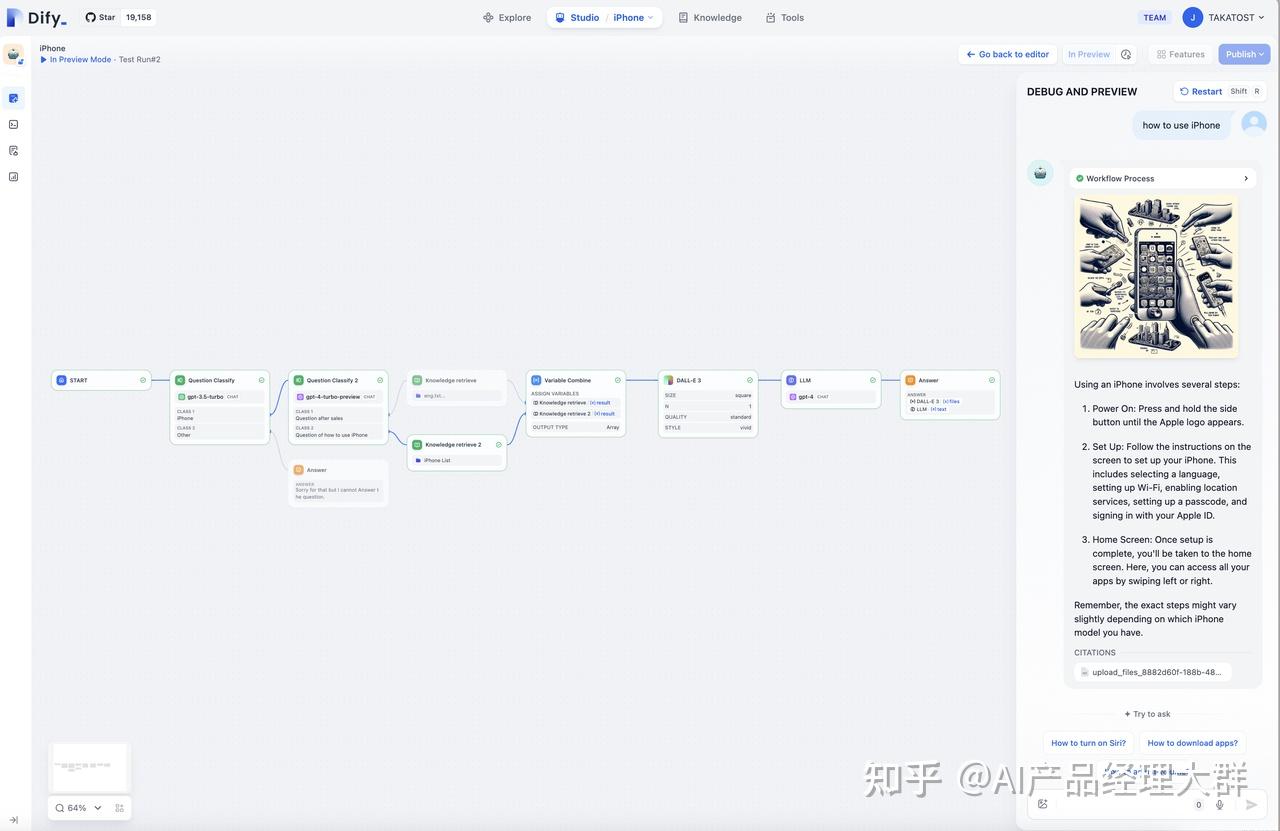
자연어 입력에서 사용자 의도 식별의 복잡성을 해결하기 위해 Chatflow는 질문 이해 유형의 노드를 제공합니다. Workflow에 비해 Chatbot 기능 지원이 추가되었습니다. 예를 들어 대화 이력(Memory), 라벨링 답변, Answer 노드 등이 있습니다.
자동화 및 배치 시나리오에서 복잡한 비즈니스 논리를 해결하기 위해 워크플로우는 풍부한 논리 노드를 제공합니다. 예를 들어 코드 노드, IF/ELSE 노드, 템플릿 변환, 반복 노드 등이 있으며, 이 외에도 타이머 및 이벤트 트리거 기능을 제공하여 자동화 프로세스 구축을 편리하게 합니다.
LLM을 고객 서비스 시스템에 통합하여 일반 질문에 자동으로 답변하고 지원 팀의 업무 부담을 덜 수 있습니다. LLM은 고객 쿼리의 맥락과 의도를 이해하고 실시간으로 도움이 되고 정확한 답변을 생성할 수 있습니다.
블로그 게시물을 만들거나 제품 설명이나 마케팅 자료를 만들어야 할 때, LLM은 높은 품질의 콘텐츠를 생성하여 도와줄 수 있습니다. 아웃라인이나 주제를 제공하면, LLM은 광범위한 지식 베이스를 활용하여 매력적이고 정보가 풍부하며 구조가 좋은 콘텐츠를 만듭니다.
는 Trello, Slack, Lark와 같은 다양한 작업 관리 시스템과 통합되어 프로젝트와 작업을 자동화할 수 있습니다. 자연어 처리를 사용하면 LLM은 사용자 입력을 이해하고 해석할 수 있으며, 작업을 만들고 상태를 업데이트하고 우선순위를 할당할 수 있어 수동 개입이 필요 없습니다.
는 대규모 지식 베이스를 분석하고 보고서나 요약을 생성하는 데 사용될 수 있습니다. LLM에게 관련 정보를 제공하면, 그는 경향, 패턴 및 통찰력을 식별하여 원시 데이터를 실행 가능한 지능으로 전환할 수 있습니다. 데이터 기반 의사 결정을 원하는 기업에게 이는 특히 가치가 있습니다.
LLM은 이메일 초안 작성, 소셜 미디어 업데이트 및 기타 형태의 의사소통에 사용될 수 있습니다. 간략한 아웃라인 또는 핵심 포인트를 제공하면 LLM은 구조가 잘 되어 있고 일관성 있으며 맥락에 맞는 정보를 생성할 수 있습니다. 이를 통해 많은 시간을 절약하고 반응이 명확하고 전문적임을 보장할 수 있습니다.
노드
노드는 워크플로우의 핵심 구성 요소로, 다양한 기능의 노드를 연결하여 워크플로우의 여러 작업을 수행합니다.
워크플로우의 핵심 노드를 참조하십시오.노드 설명.
변수
변수는 워크플로우 내 전후 노드의 입력과 출력을 연결하여 프로세스 내 복잡한 처리 논리를 구현하며, 시스템 변수, 환경 변수 및 세션 변수를 포함합니다.
적용 시나리오:
대화형 상황에 맞춰져 있으며, 고객 서비스, 의미 검색, 그리고 응답 구성 시 다단계 논리가 필요한 대화형 애플리케이션에 적합합니다. 이 유형의 애플리케이션의 특징은 생성된 결과에 대해 다중 라운드 대화 상호작용을 지원하고 결과를 조정할 수 있다는 점입니다.
일반적인 상호작용 경로: 지시 → 내용 생성 → 내용에 대해 여러 번 논의 → 결과 재생성 → 종료
워크플로우(Workflow)
적용 시나리오:
자동화 및 배치 처리 상황에 맞춰져 있으며, 고품질 번역, 데이터 분석, 콘텐츠 생성, 이메일 자동화 등의 애플리케이션에 적합합니다. 이 유형의 애플리케이션은 생성된 결과에 대해 다중 라운드 대화 상호작용을 지원하지 않습니다.
일반적인 상호작용 경로: 지시 → 내용 생성 → 종료
sys.query、sys.files、sys.conversation_id이 포함됩니다。sys.user_idWorkflow의 시작 노드에 내장된 변수는 다음과 같습니다:sys.files,sys.user_id。여기서 빈 애플리케이션을 만들고, 워크플로우를 선택합니다:
임의로 이름을 지어서 생성 버튼을 누르면 생성이 완료됩니다.
이제 우리는 프로세스 노드를 만듭니다. 이전 단계에서 만들었으면, 자동으로 프로세스 노드의 캔버스가 보여주고, 시작 버튼도 하나 더 있습니다.
여기서는 위의 절차에 따라 진행하겠습니다.
1) 제목 힌트 메시지 설정, 내용 힌트 메시지 설정
시작 버튼을 클릭하고 두 개의 입력 값을 설정하세요. 하나는 제목 힌트 메시지이고, 다른 하나는 내용 힌트 메시지입니다:
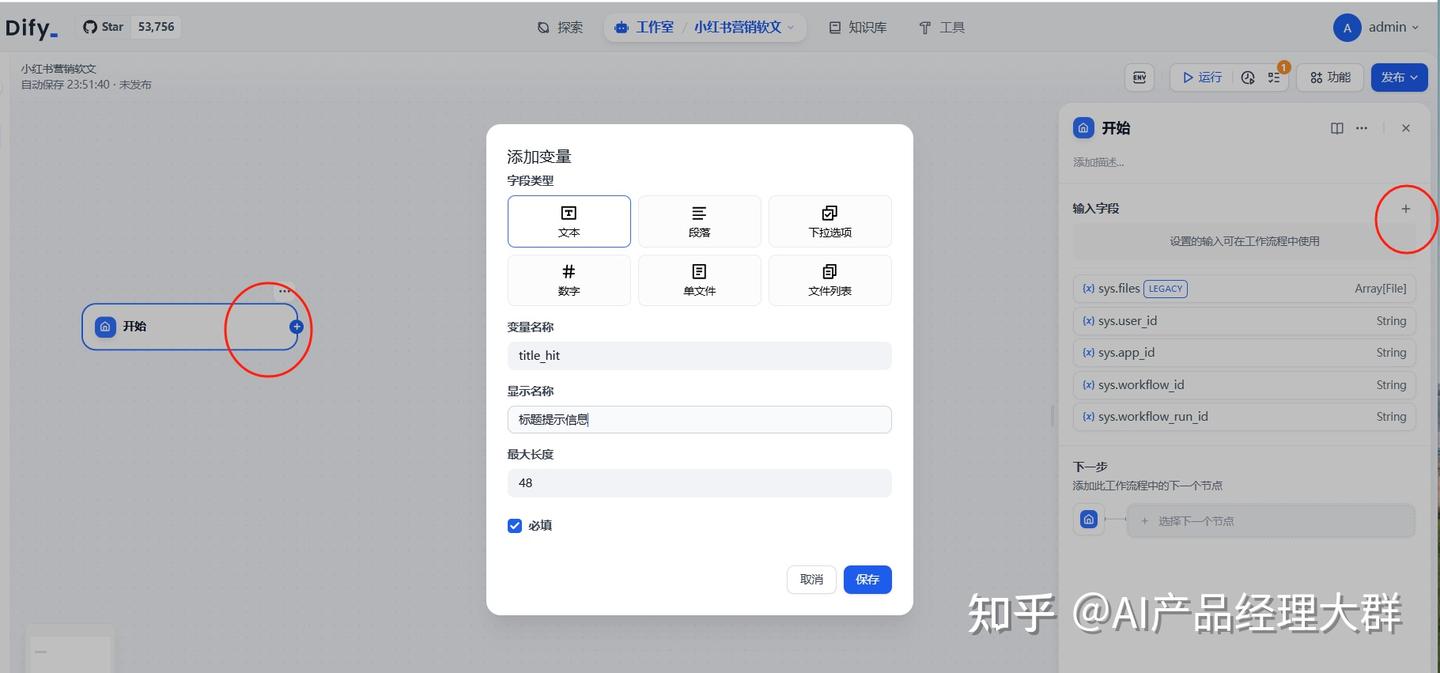
생성이 완료되면 패널에서 두 개의 필드가 추가된 것을 볼 수 있습니다.

2) AI를 사용하여 제목 생성
이전 단계의 패널에서 '다음' 위치에서,
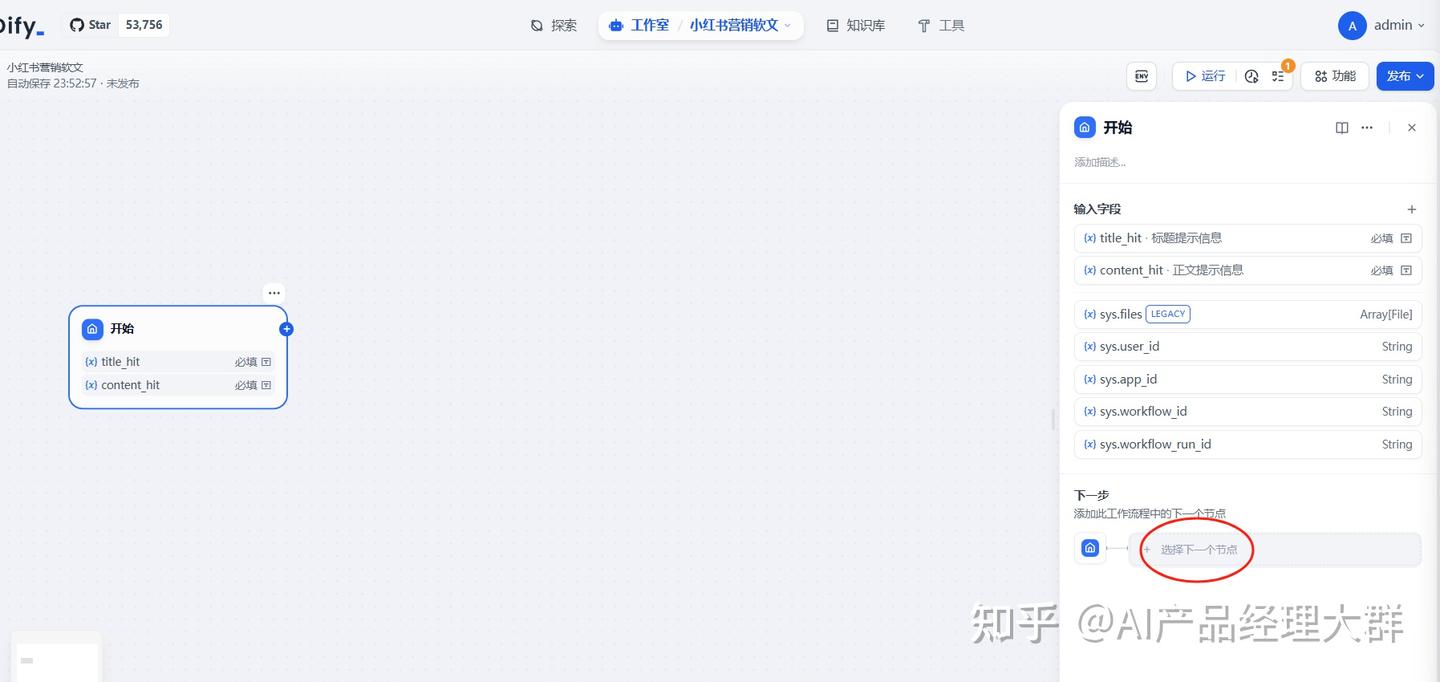
우리는 LLM 모델을 추가합니다:
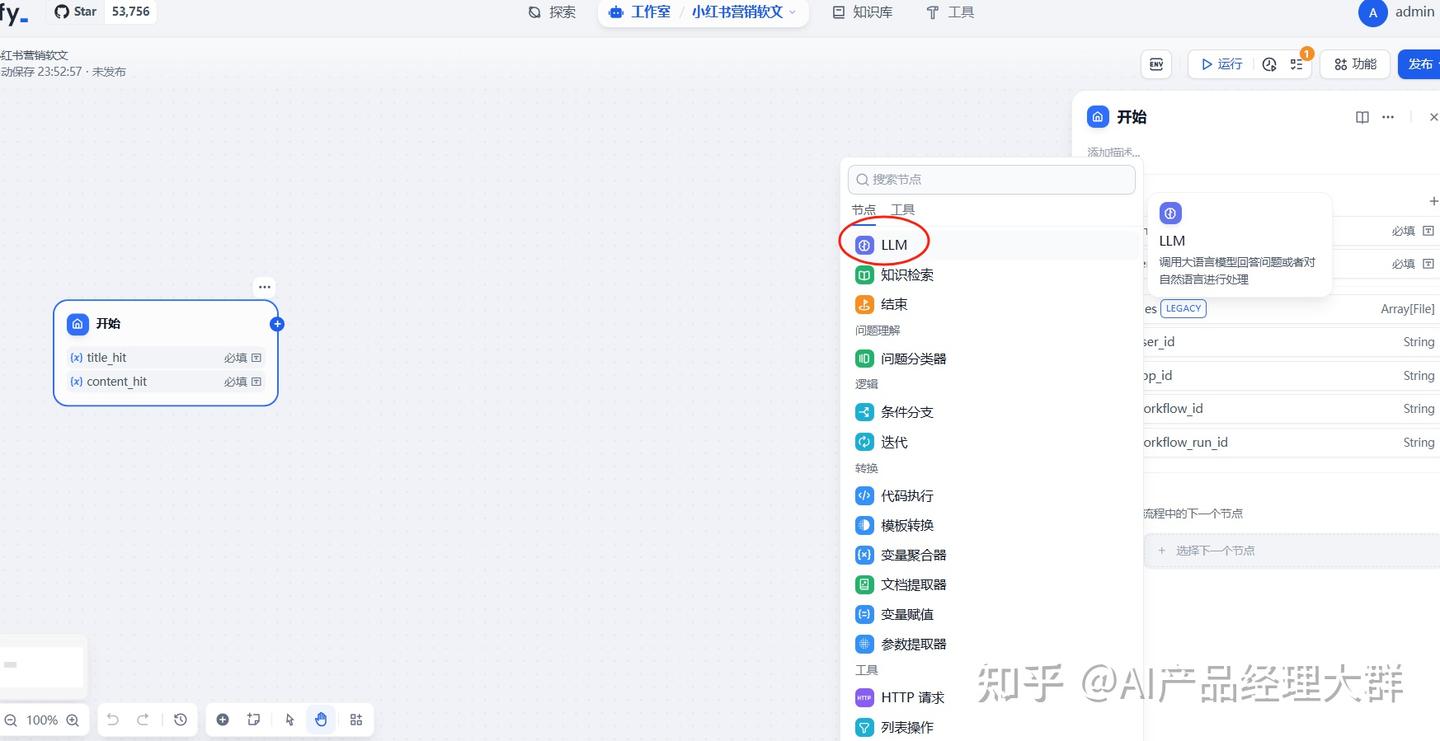
여기서는 여러 모델을 선택할 수 있으며, 필요에 따라 선택하면 됩니다. 여기서 우리의 요구사항은 모델을 사용하여 제목을 생성하는 것이므로, LLM을 선택하고 추가한 후, 노드에 LLM이 추가된 것을 볼 수 있습니다:
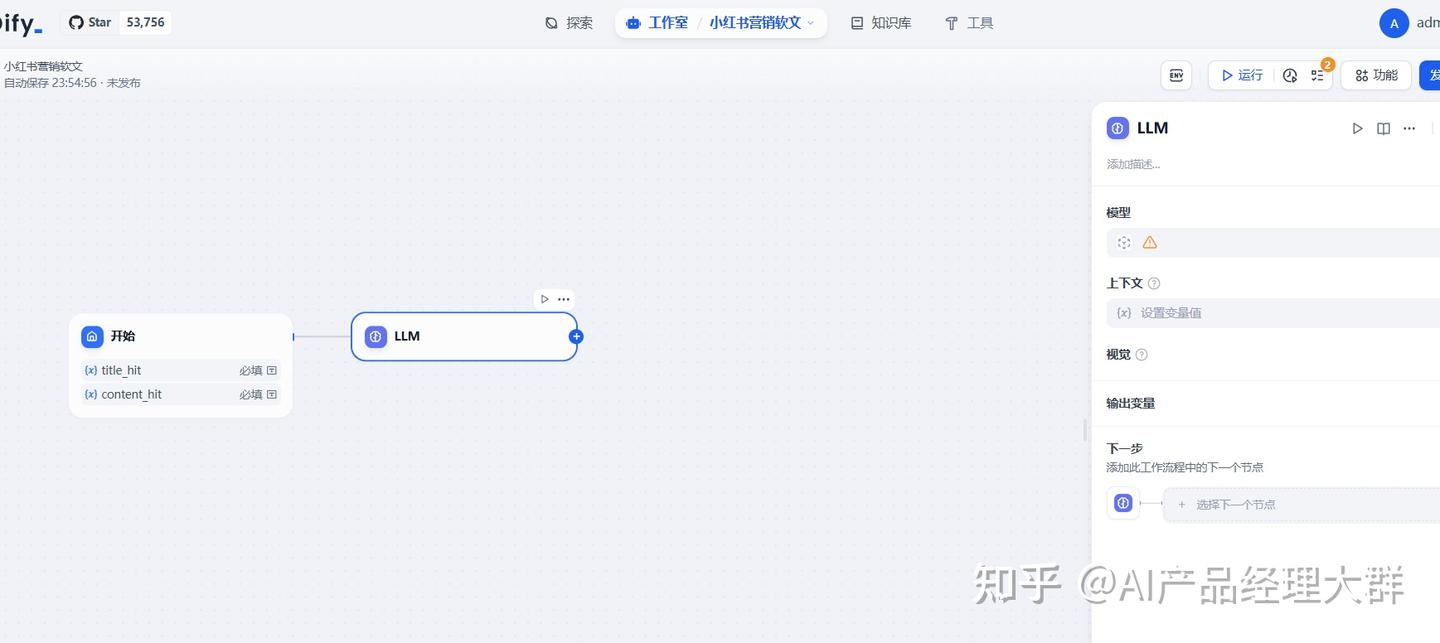
여기서 우리는 LLM 템플릿을 설정할 수 있습니다:
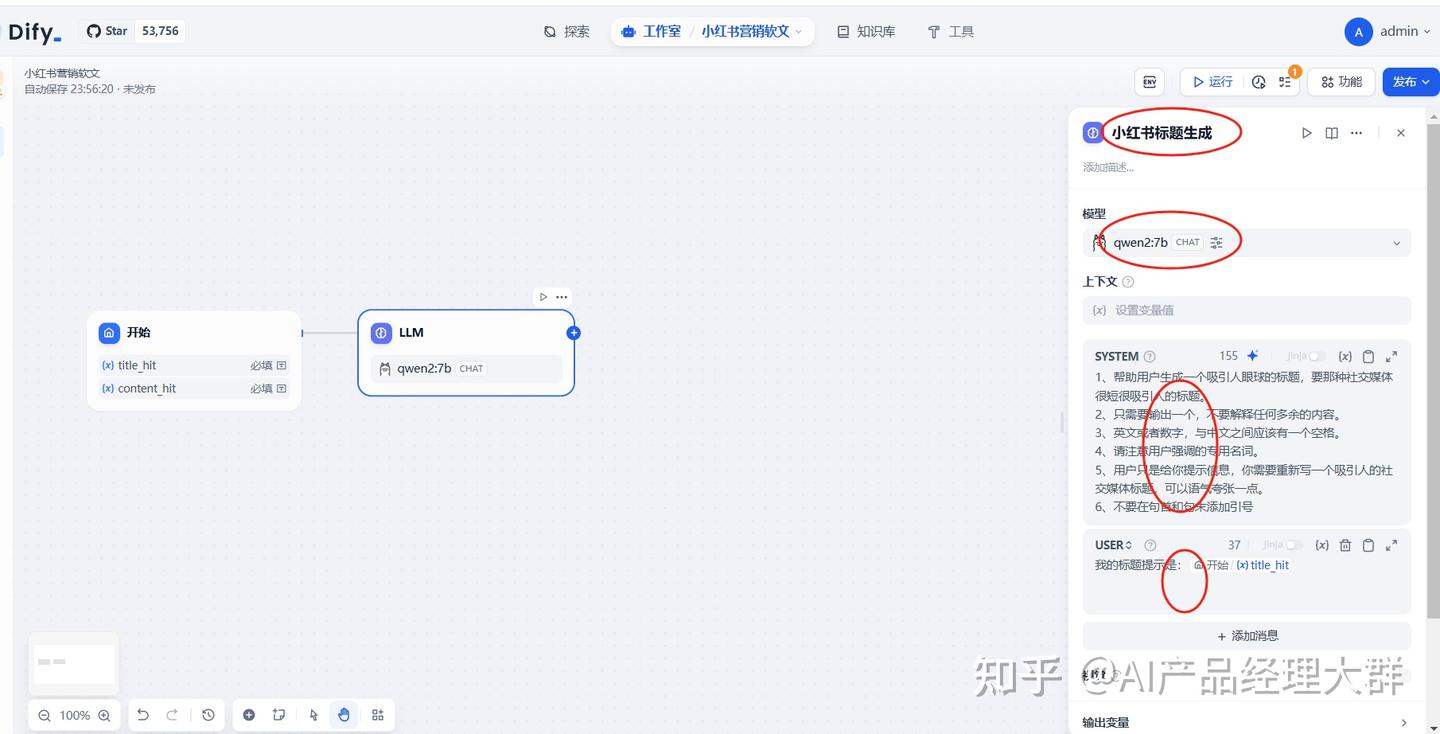
위의 4 부분의 정보만 설정하면 됩니다. 여기서 설명해 드리겠습니다:
BASIC
1、system部分其实就是我们给ai的提示语,也就是给他场景和要求。
2、user部分主要是作为用户传递的一些特定指向的注释信息。3) AI를 사용하여 본문 생성
다음으로 상고 2의 위치에서 다음 단계의 위치에 LLM을 추가하여 본문을 생성합니다:
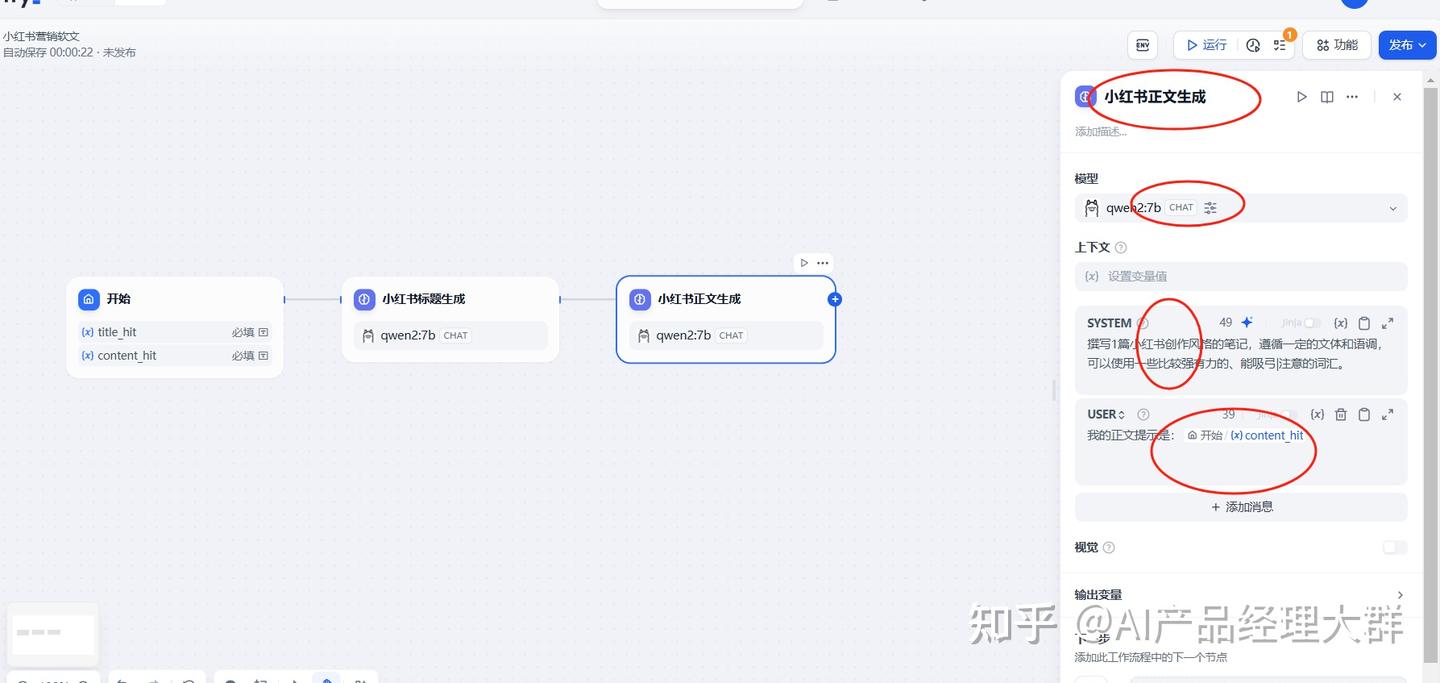
4) 제목과 본문을 결합합니다
여기서 상고 3의 패널에서 다음 단계를 선택하고 템플릿 변환을 추가하여 이전 제목과 내용을 추출합니다. 내용은 직접 편집해야 합니다:
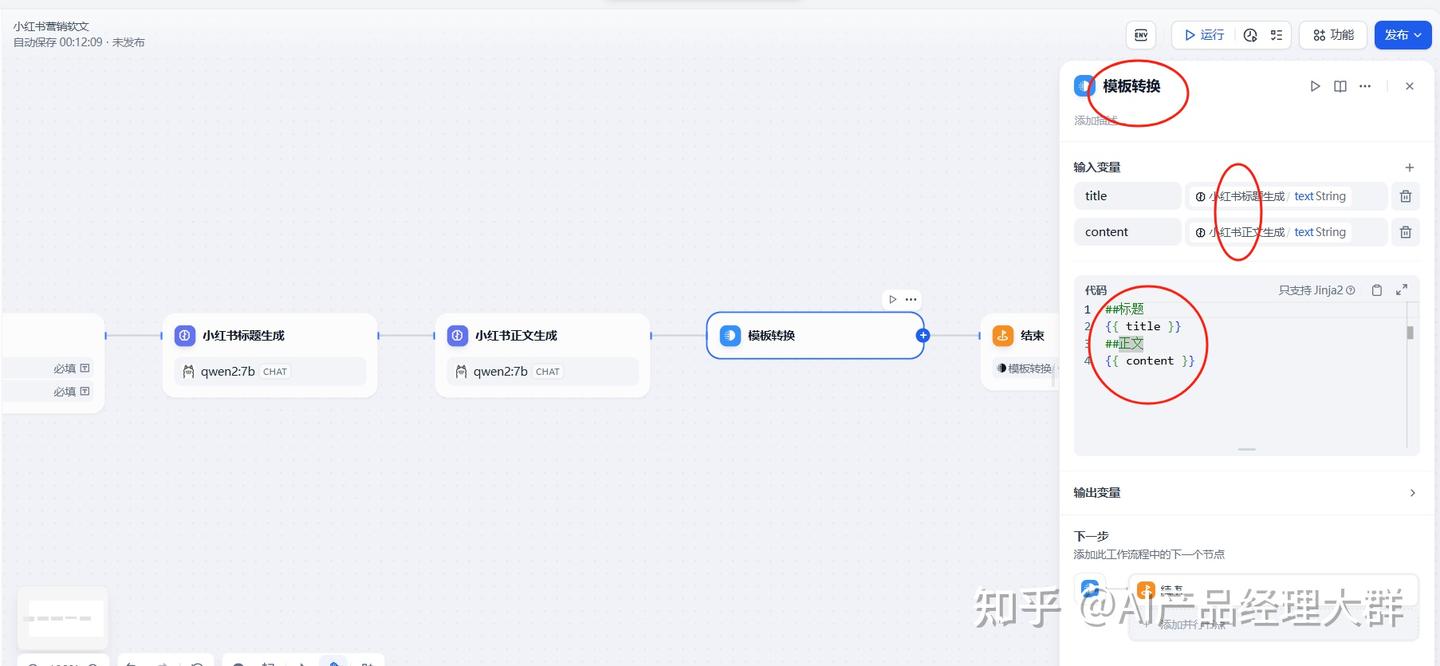
5) 프로세스 종료
여기서 상고 4의 패널에서 다음 노드를 종료로 추가하고 출력 정보를 설정합니다
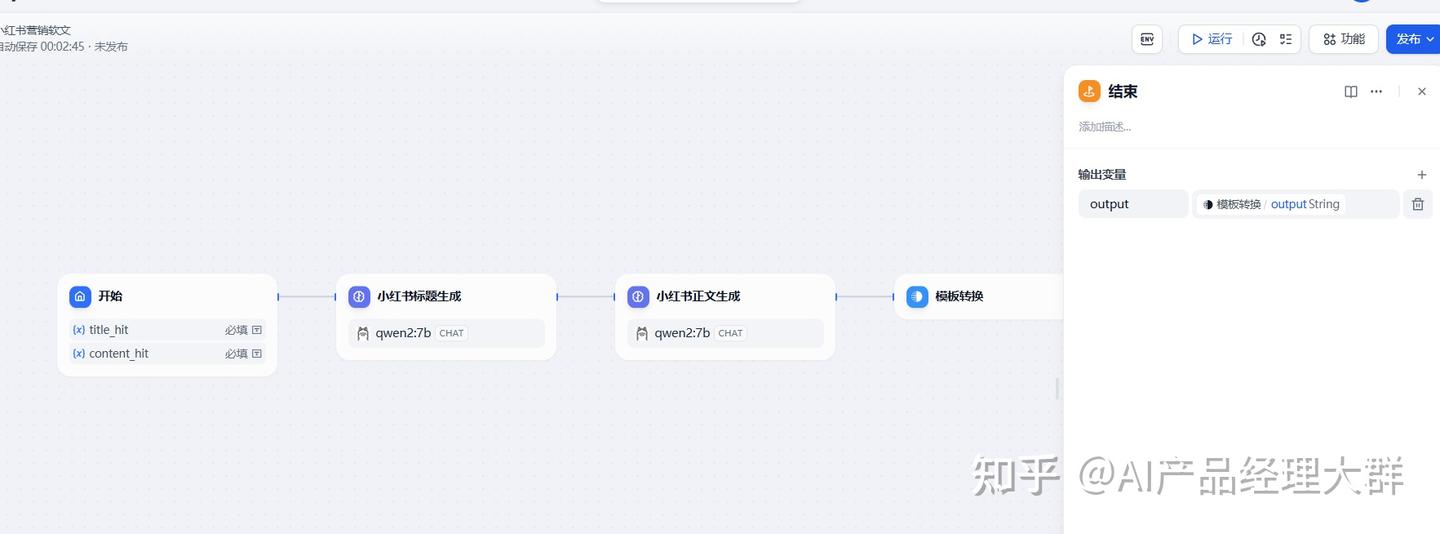
이제 우리의 전체 프로세스가 완료되었습니다. 캔버스에서 전체 프로세스가 표시됩니다:
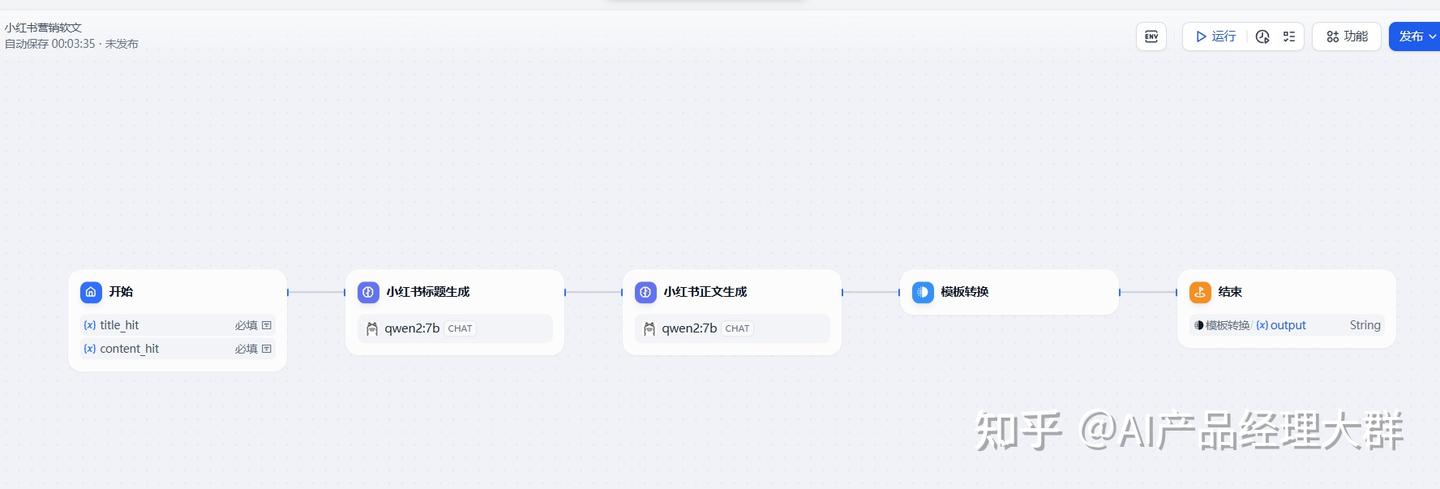
프로세스를 지정한 후 실행 버튼을 선택하여 테스트할 수 있습니다:
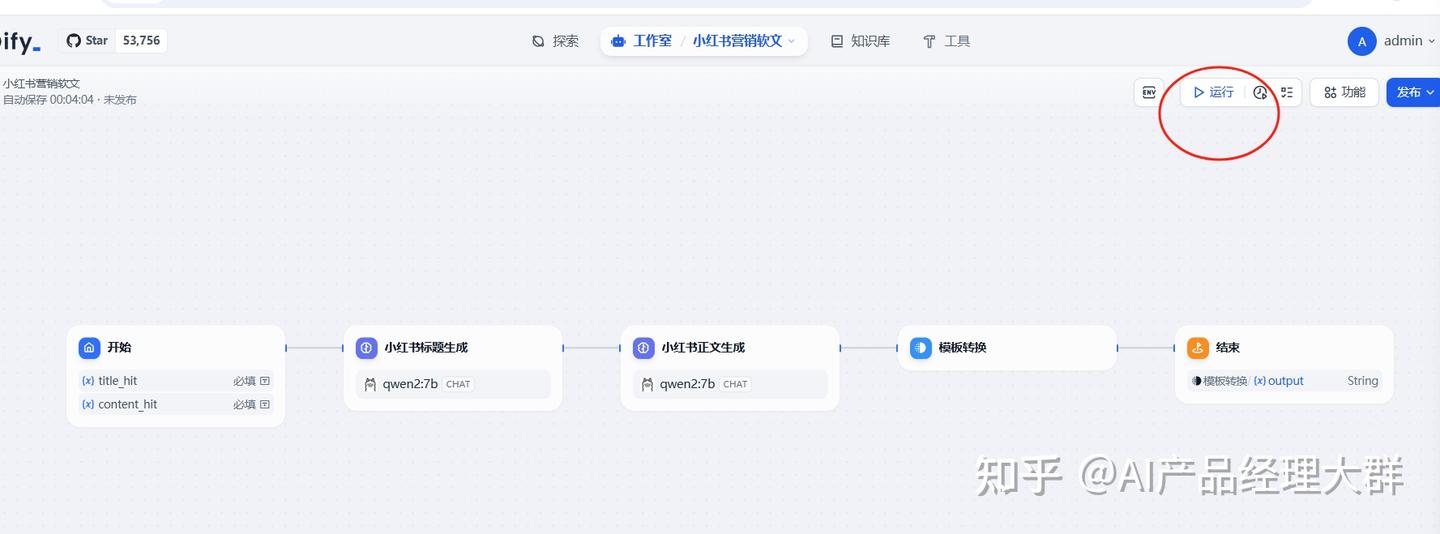
실행을 클릭하면 입력 제목과 본문의 힌트를 요청하며, 다음과 같은 이미지와 같습니다:
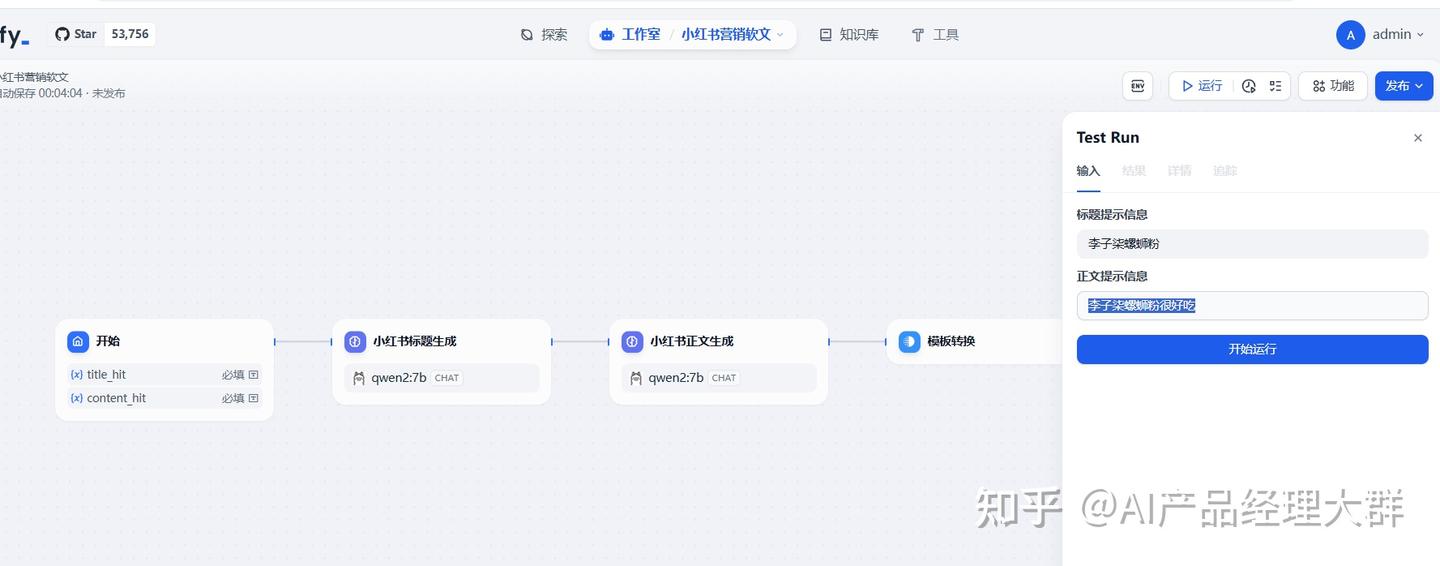
필요에 따라 채워넣으세요. 채우기가 끝난 후 '시작 실행'을 클릭하고 잠시 기다리면 결과를 볼 수 있습니다:
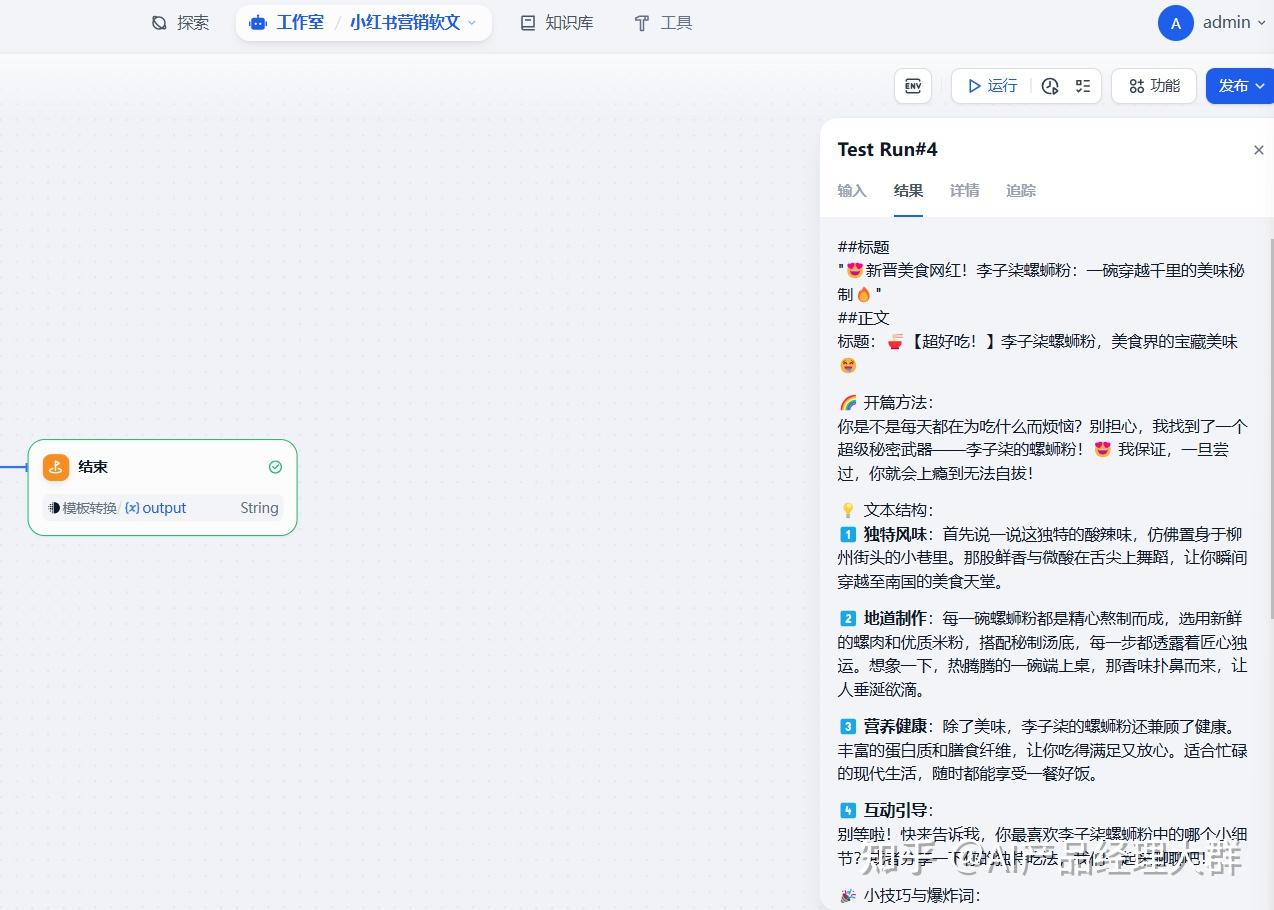
위는 Dify에서 워크플로우를 사용하는 예시입니다. 위 내용은 주로 데모이기 때문에 자세한 설명은 많이 하지 않았습니다. 여기서는 사용자의 요구에 따라 맞춤 설정할 수 있으며, 틀림없는 설명은 없지만 핵심적인 내용은 여기서 명시해 드립니다:
1. 워크플로우를 사용하기 위해서는 먼저 일을 분해하여 각 단계를 연결할 수 있도록 해야 합니다.
2. 여기서 AI를 사용하려면 LLM 노드를 선택하고, 다른 일을 하려면 다른 노드를 선택하세요.
3. AI의 사용 정확도는 당신의 프롬프트에 따라 달라지며, System 부분의 설명을 최대한 상세하게 작성하는 것이 중요합니다.
4. 모든 프롬프트는 인터넷에서 검색할 수 있습니다.
一、지식 베이스 준비
이곳에 준비된 지식베이스 형식은 거의 제한 없습니다. 일반적으로 대화 시나리오에서는 QA 모드를 선택하는 경우가 많습니다. 예를 들어, 고객 서비스 대화는 매우 적합합니다. 따라서 저는 인터넷에서 고객 서비스 관련 용어를 찾았습니다. 내용은 다음과 같습니다:
### 새 프로젝트를 만드는 방법은 무엇인가요? 새 프로젝트를 만들려면 페이지 상단 우측의 "새 프로젝트" 버튼을 클릭하고, 프로젝트 이름을 입력하고, 프로젝트 템플릿(있는 경우)을 선택한 다음 "만들기"를 클릭합니다. 프로젝트는您的 프로젝트 목록에 나타납니다. ### 태스크에 마감일을 추가하는 방법은 무엇인가요? 태스크 상세 페이지에서 마감일 영역을 클릭하고 날짜를 선택한 다음 저장합니다. 태스크의 마감일은 태스크 목록에 표시됩니다. ### Google Calendar와 동기화하는 방법은 무엇인가요? "설정" 페이지로 이동하여 "統合" 옵션을 찾고, "Google Calendar"를 선택한 다음 지침에 따라 권한 부여 및 동기화를 수행합니다. 동기화 후, 모든 프로젝트 태스크의 마감일이您的 Google Calendar에 표시됩니다. ### 태스크에 우선순위를 설정할 수 있나요? 예, 태스크 상세 페이지에서 태스크의 우선순위를 설정할 수 있습니다. "우선순위" 드롭다운 메뉴를 클릭하고 "높음", "중간" 또는 "낮음"을 선택합니다. 설정된 우선순위는 태스크 목록에 표시됩니다. ### 제 계정 이메일 주소를 변경하는 방법은 무엇인가요? "계정 설정" 페이지로 이동하여 "개인 정보" 섹션에서 이메일 주소 옆의 "편집" 버튼을 클릭하고 새 이메일 주소를 입력한 다음 저장합니다. 변경 사항을 완료하려면 새 이메일 주소를 검증해야 합니다. ### 비밀번호를 잊으셨나요? 로그인 페이지에서 "비밀번호를 잊으셨나요" 링크를 클릭하고, 등록한 이메일 주소를 입력한 다음, 비밀번호 재설정 링크를您的 이메일 주소로 전송합니다. 이 링크를 통해 새 비밀번호를 설정할 수 있습니다. ### 팀 멤버를 프로젝트에 초대하는 방법은 무엇인가요? 프로젝트 페이지에서 "멤버 초대" 버튼을 클릭하고, 초대할 멤버의 이메일 주소를 입력한 다음 그들의 역할(예: 관리자, 편집자 등)을 선택합니다. "초대 보내기"를 클릭하면 초대 이메일이 수신자에게 전송됩니다. ### 제 구독 계획을 확인하는 방법은 무엇인가요? "계정 설정" 페이지로 이동하여 "구독" 섹션에서 현재 구독 계획, 다음 청구 날짜 및 비용 세부 정보를 확인할 수 있습니다. ### 제 구독 계획을 업그레이드하는 방법은 무엇인가요? "계정 설정"의 "구독" 섹션에서 "계획 업그레이드" 버튼을 클릭하고, 업그레이드할 계획을 선택한 다음 결제를 확인합니다. 업그레이드는 즉시 적용되며 비용은 비례하여 계산됩니다. ### 제 구독을 취소할 수 있나요? 예, 제 구독을 언제든 취소할 수 있습니다. "계정 설정"의 "구독" 섹션에서 "구독 취소" 버튼을 클릭하고 지침에 따라 취소 작업을 완료합니다. 구독을 취소한 후에도 현재 청구 기간 동안 유료 기능을 사용할 수 있습니다. ### 제 태스크 목록이 사라졌어요. 어떻게 해야 하나요? 올바른 프로젝트를 선택했는지 확인하세요. 왼쪽 메뉴의 프로젝트 목록에서 프로젝트를 다시 선택할 수 있습니다. 문제가 해결되지 않으면 페이지를 새로고침하거나 로그아웃한 다음 다시 로그인해 보세요. ### 제가 알림 이메일을 받지 못하는 이유는 무엇인가요? 알림 설정을 확인하여 관련 알림 옵션이 활성화되어 있는지 확인하세요. 활성화되었지만 여전히 받지 못하면 스팸 폴더를 확인하고, 우리의 이메일 주소를 연락처로 추가하세요. ### 시스템이 "작업 실패"를 표시하면 어떻게 해야 하나요? 이는 네트워크 문제로 인해 발생할 수 있으므로 네트워크 연결을 확인하고 다시 시도하세요. 문제가 계속되면 고객 서비스에 문의하고 관련 오류 정보와 스크린샷을 제공하세요. ### 시스템 업데이트 후 제 일부 데이터가 손실되었어요. 어떻게 복구할 수 있나요? 시스템 업데이트 후 데이터 손실이 발생한 경우, 즉시 고객 서비스에 문의하세요. 우리는 시스템 백업을 통해 손실된 데이터를 복구하는 데 도움을 드리겠습니다. 하지만 문제 발생 후 24시간 이내에 연락하는 것이 좋습니다. ### 소프트웨어 버그를 신고하는 방법은 무엇인가요? 소프트웨어 버그를 발견한 경우, "도움말 센터"로 이동하여 "문제 보고"를 클릭하고 "보안 버그"를 선택한 다음 관련 정보를 기입하세요. 우리의 기술 팀은 빠르게 처리할 것입니다. ### 제 프로젝트가 로드되지 않아요. 어떻게 해야 하나요? 먼저 네트워크 연결을 확인하고 다른 기기에서 접근해 보세요. 문제가 해결되지 않으면 브라우저 캐시를 지우거나 다른 브라우저를 사용해 보세요. 문제가 해결되지 않으면 고객 서비스에 문의하세요.
여기에 빈 파일을 만들고, 위의 내용을 복사한 후 저장합니다. 저장된 파일 이름은: 고객 지식 질문과 답변 코퍼스.md입니다. 다음 그림과 같습니다:
이어서 Dify의 dashboard에 접속하여 위의 지식 베이스를 찾고, 지식 베이스를 생성합니다:
이후에는 Dify의 dashboard에 접속하고, 위의 지식 베이스를 찾아 지식 베이스를 생성합니다:
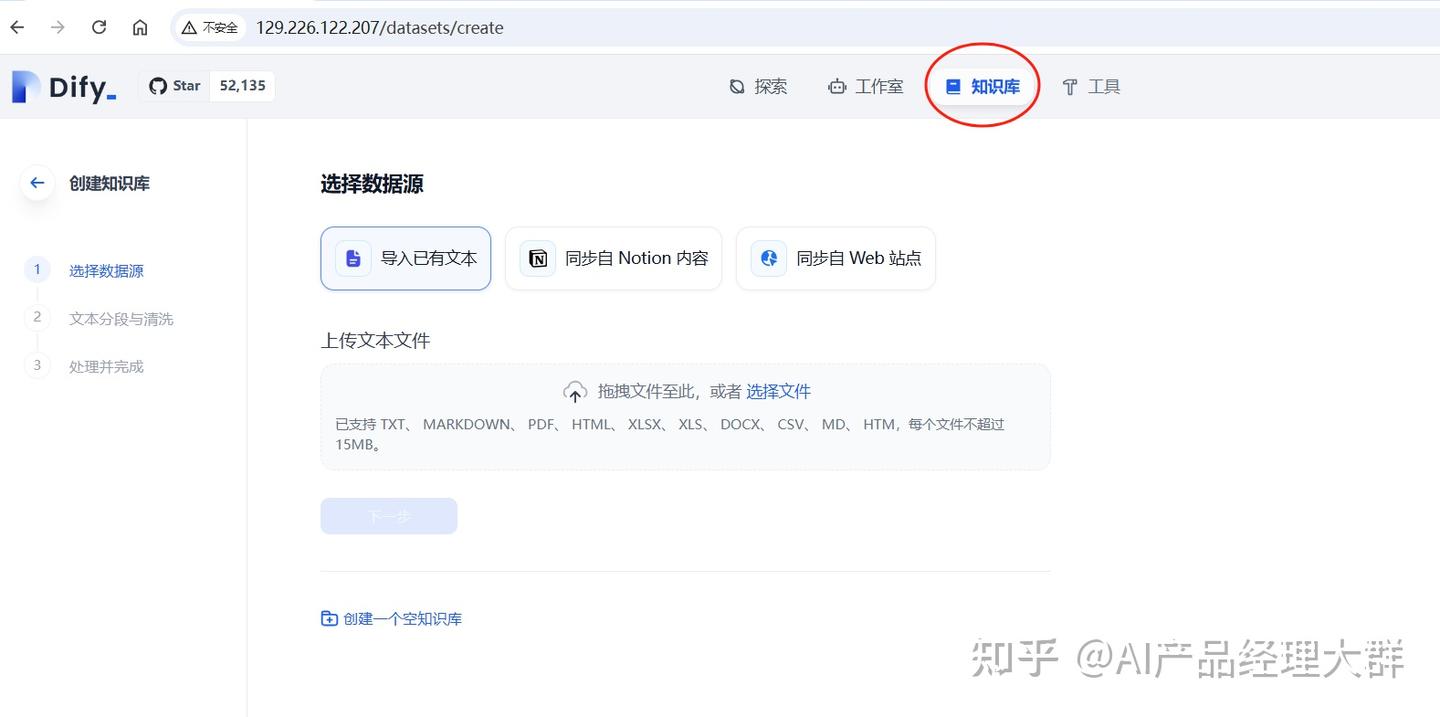
기존의 텍스트를 가져오기를 선택합니다(나머지 두 가지, nation과 web 사이트는 나중에 설명합니다), 그리고 이전에 만든 《고객 지식 질문과 답변 코퍼스.md》를 업로드합니다:
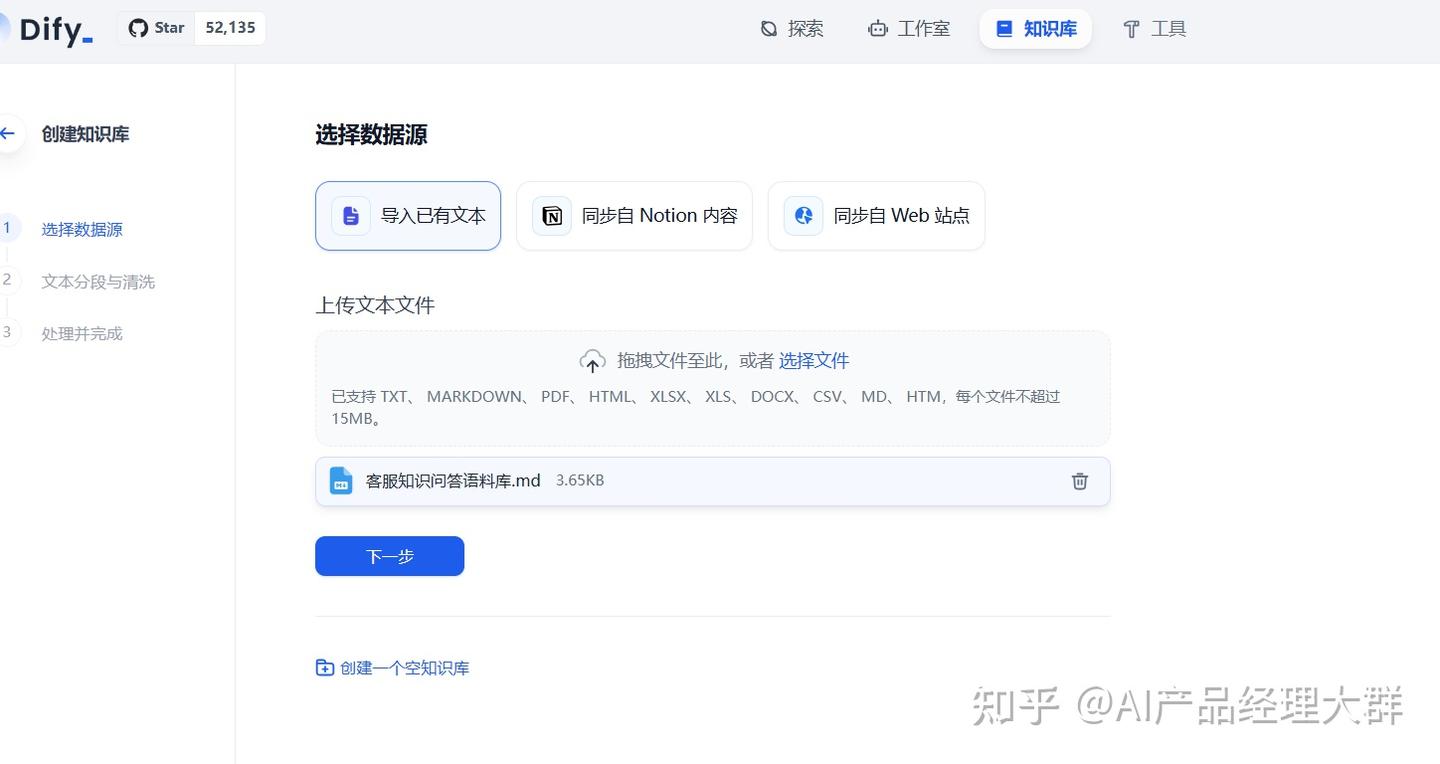
다음으로 다음으로 클릭합니다:
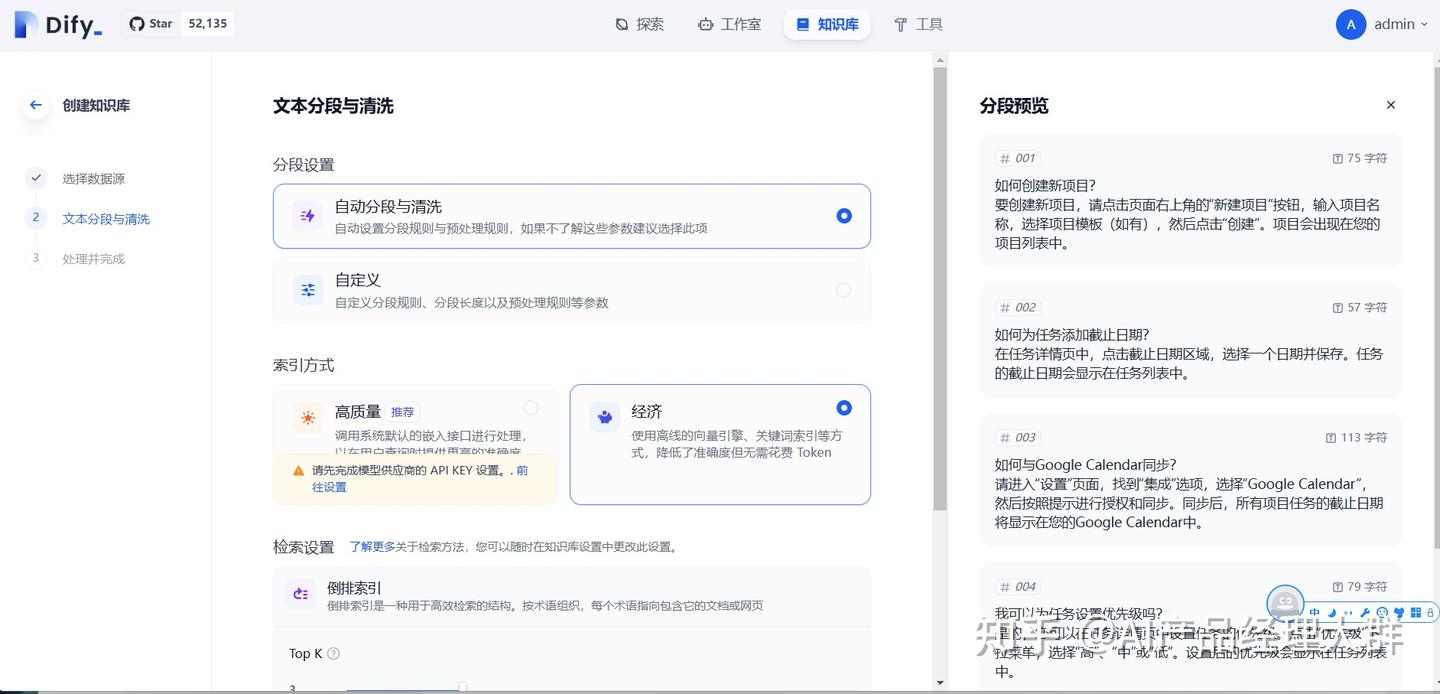
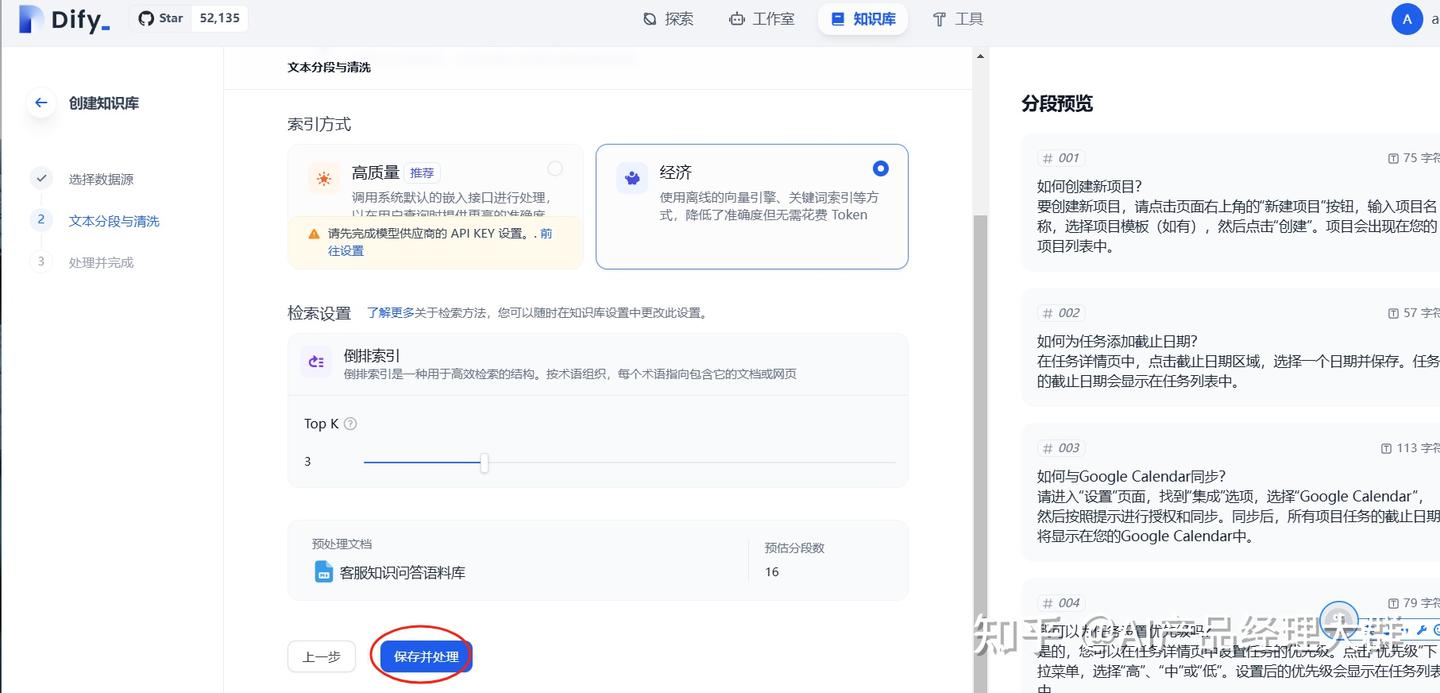
여기서는 거의 기본값을 유지할 수 있습니다. 하지만 주의해야 합니다:
1) 인덱스 방식
일반적으로 경제적인 옵션을 선택하는 것이 좋습니다. 이것은 무료이기 때문입니다. 만약 고품질 옵션을 선택하면 openai를 사용해야 하며 비용이 발생합니다. 따라서 무료인 경우 경제적인 옵션을 선택하면 됩니다.
2) 검색 설정
여기는 기본적으로 3으로 설정되어 있으며, 나중에 실제 상황에 따라 조정할 수 있습니다
마지막으로 저장하고 처리하면 됩니다
저장한 후에는 지식베이스 아래에서 이전에 추가한 예측을 볼 수 있습니다
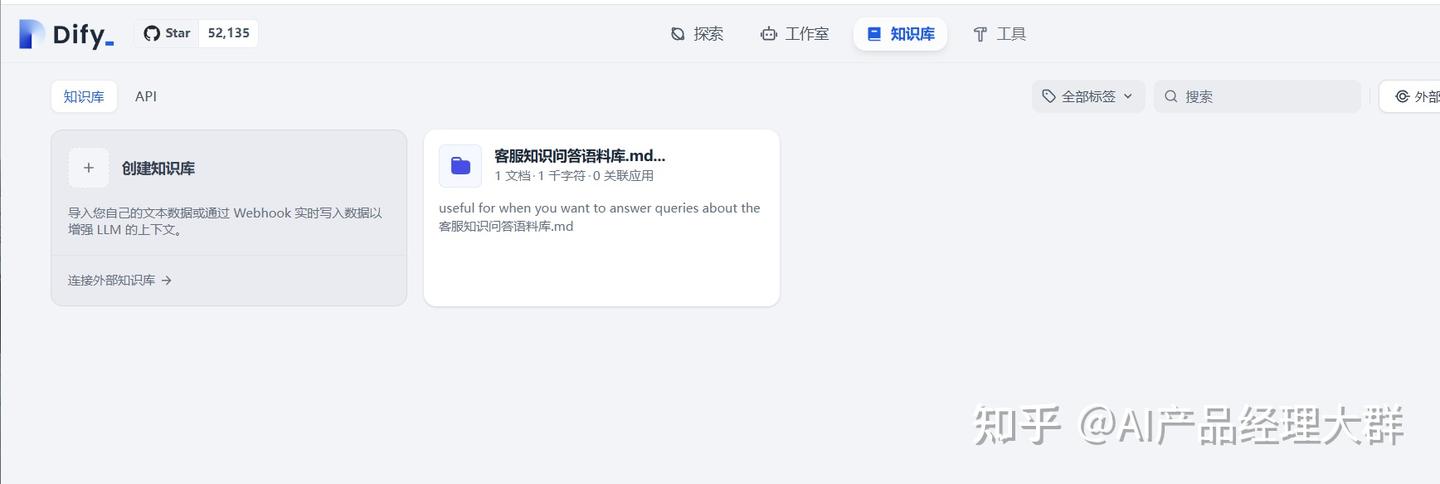
3. 지식베이스 사용
지식베이스를 추가한 후에는 이를 사용해야 하므로, 이전에 만든 챗봇으로 돌아가서 클릭합니다
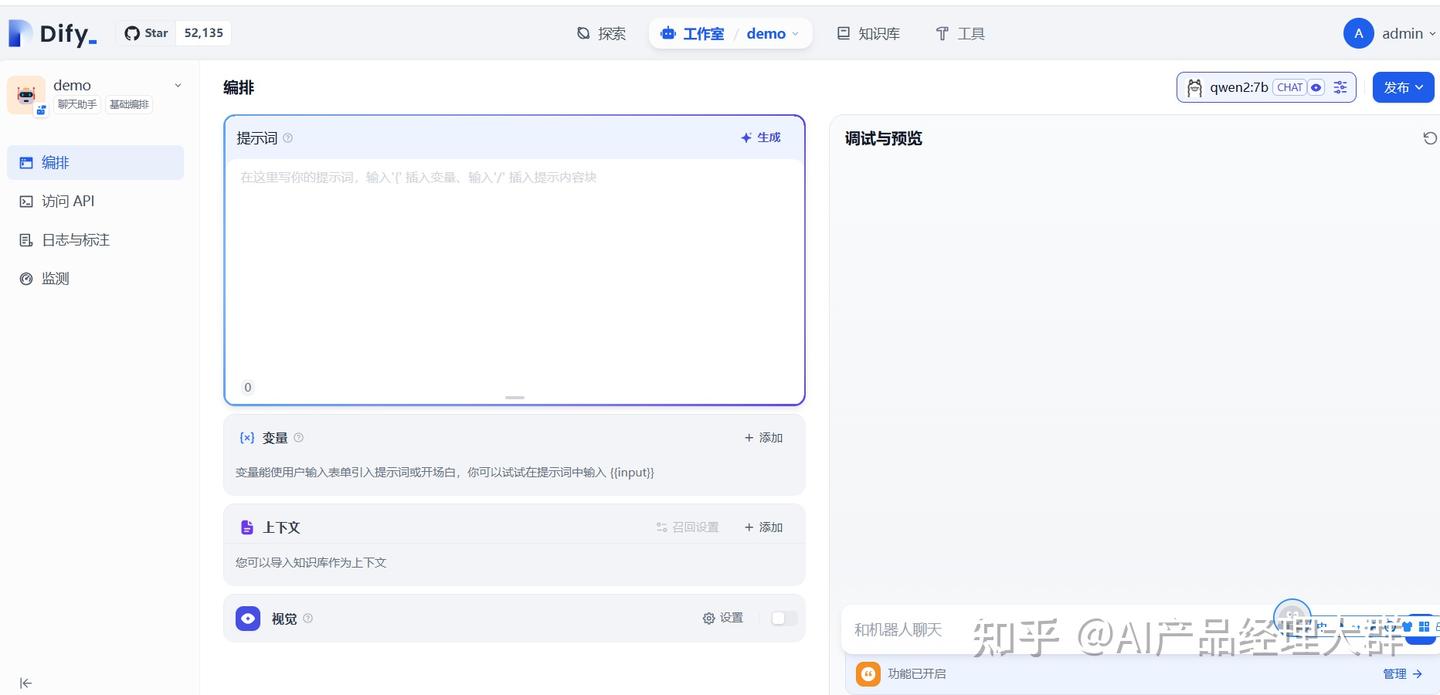
위 그림에서 상하문맥이 보이며, '추가'를 선택하여 이전에 만든 지식베이스를 추가합니다
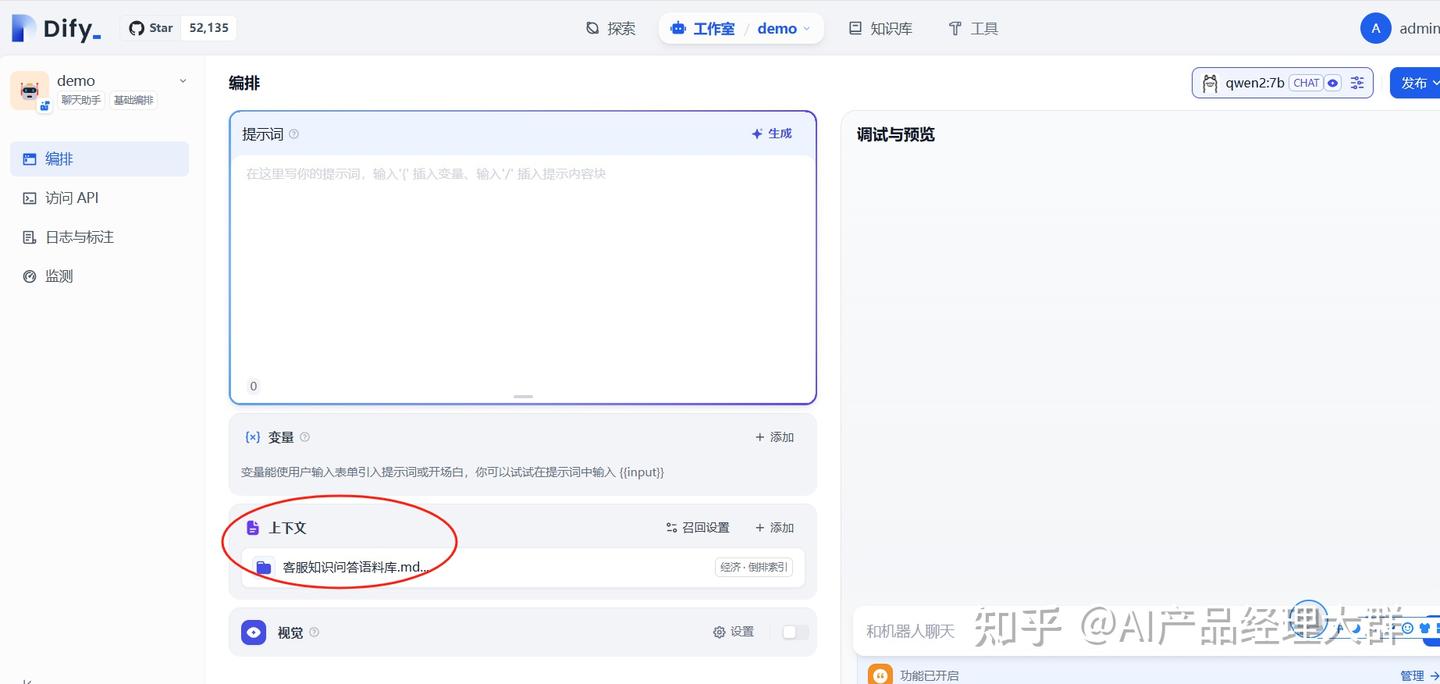
추가한 후에는 오른쪽에서 디버깅과 미리보기를 할 수 있습니다
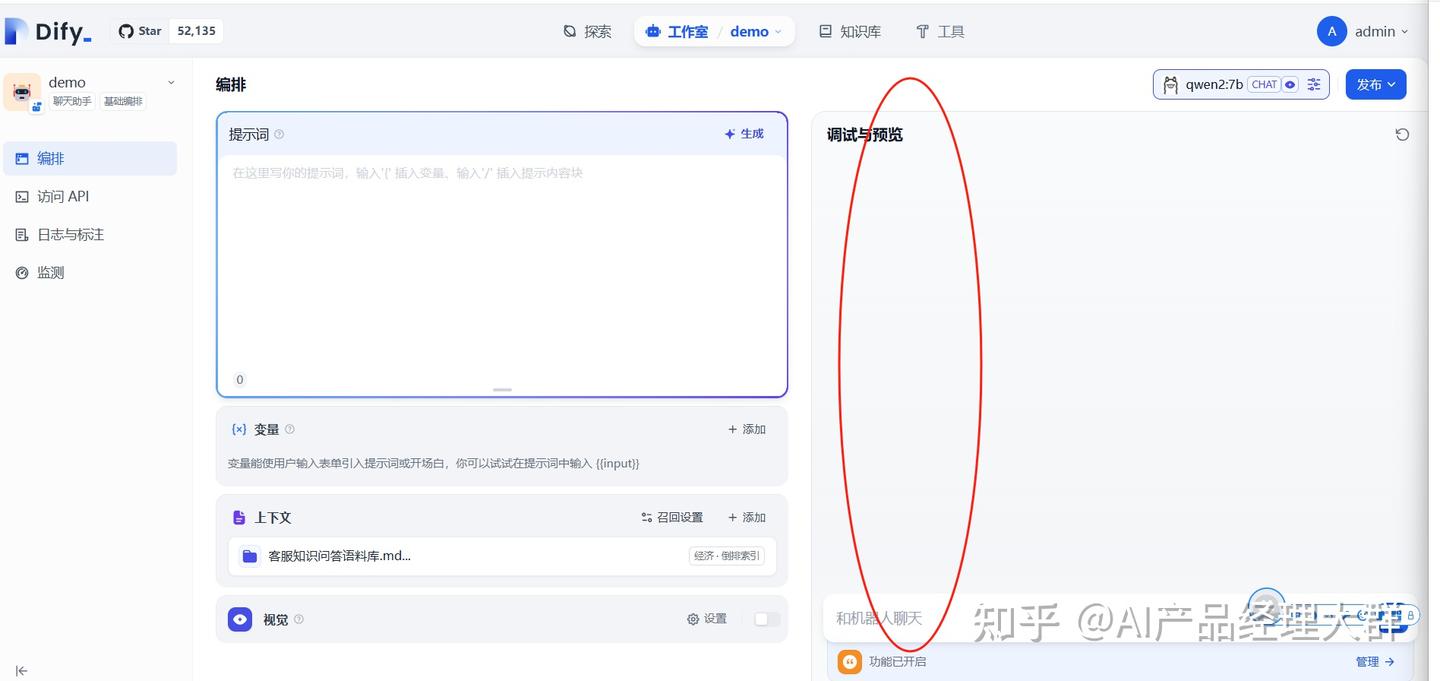
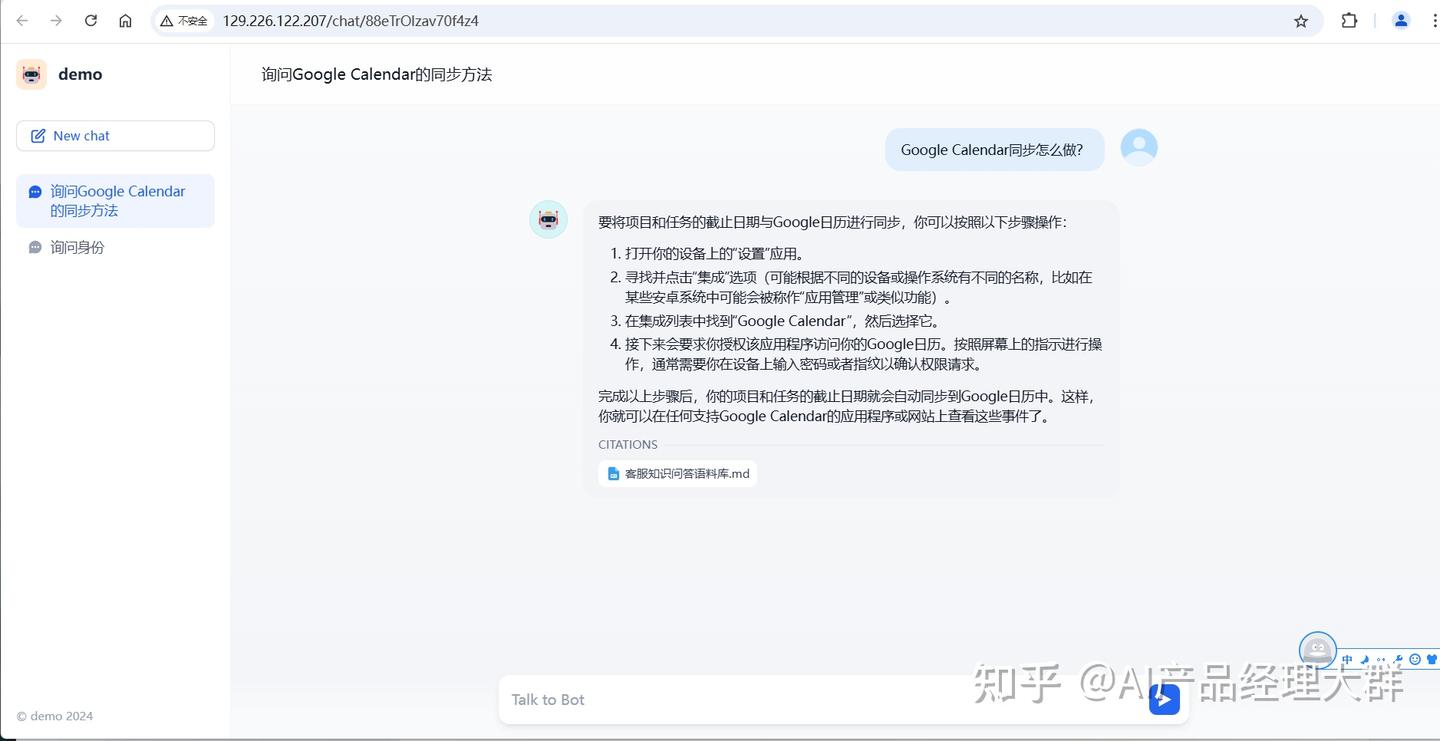
지금까지의 지식베이스와 유사한 주제로 질문을 하세요, 예를 들어: Google Calendar 동기화는 어떻게 하나요?
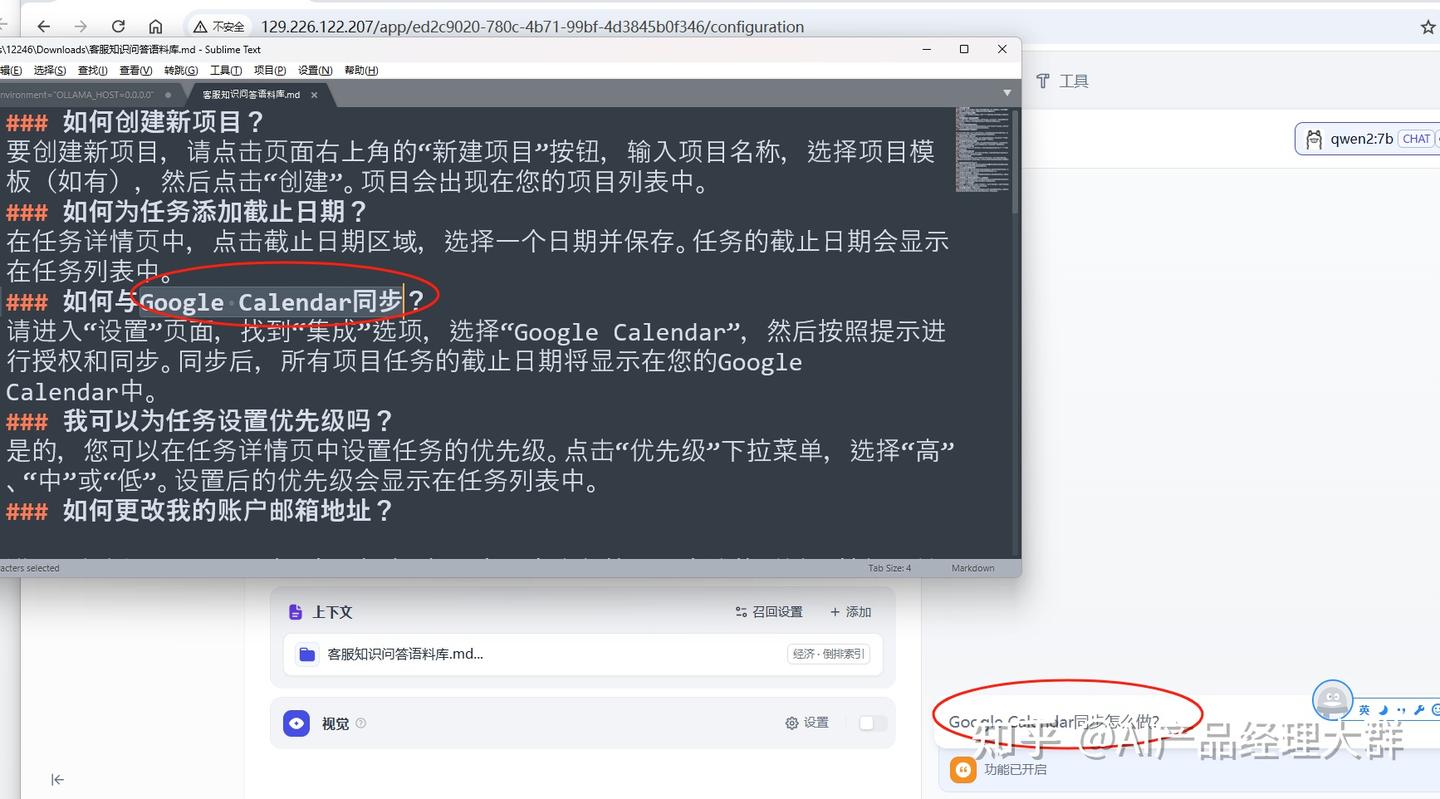
잠시 기다려보세요, 그의 답변 결과를 확인해 보겠습니다:
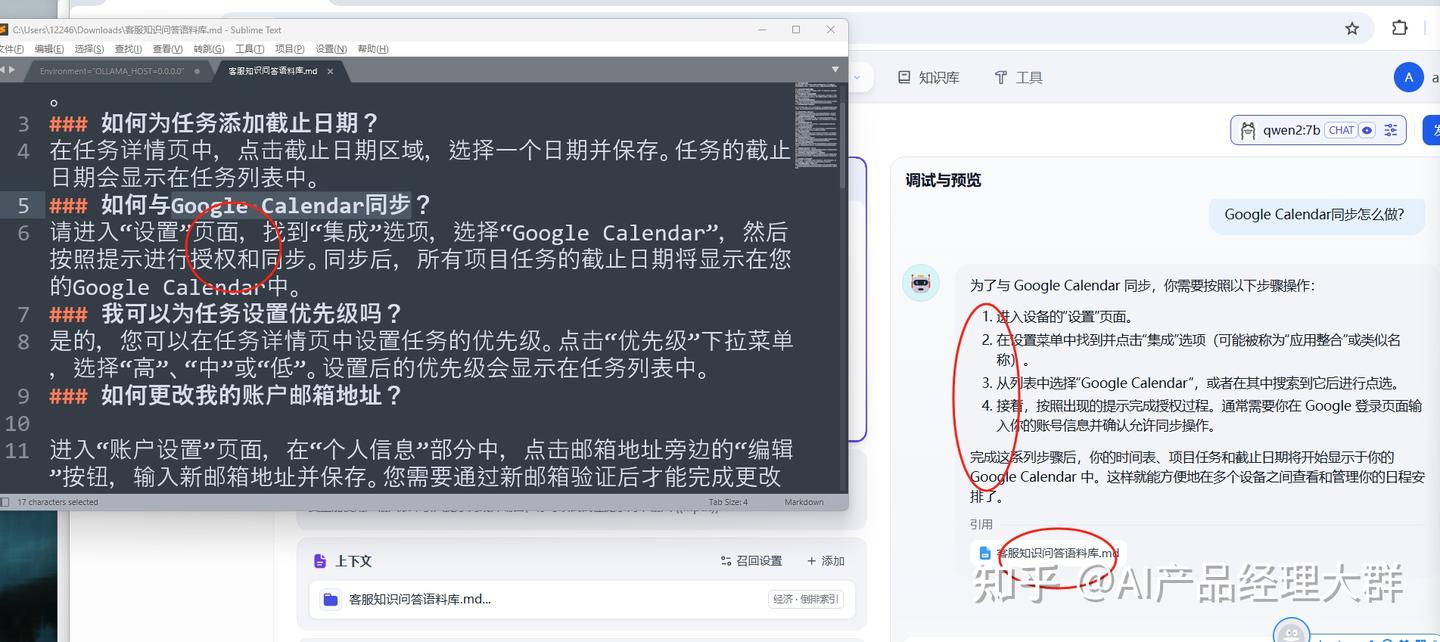
는 여기서의 답변이 거의 고객 서비스 용어와 일치합니다. 이는 Dify에 추가된 지식 베이스가 모델에 의해 인식되어 사용되고 있음을 나타냅니다. 마지막으로 우리는 이 모델을 발행할 수 있습니다:
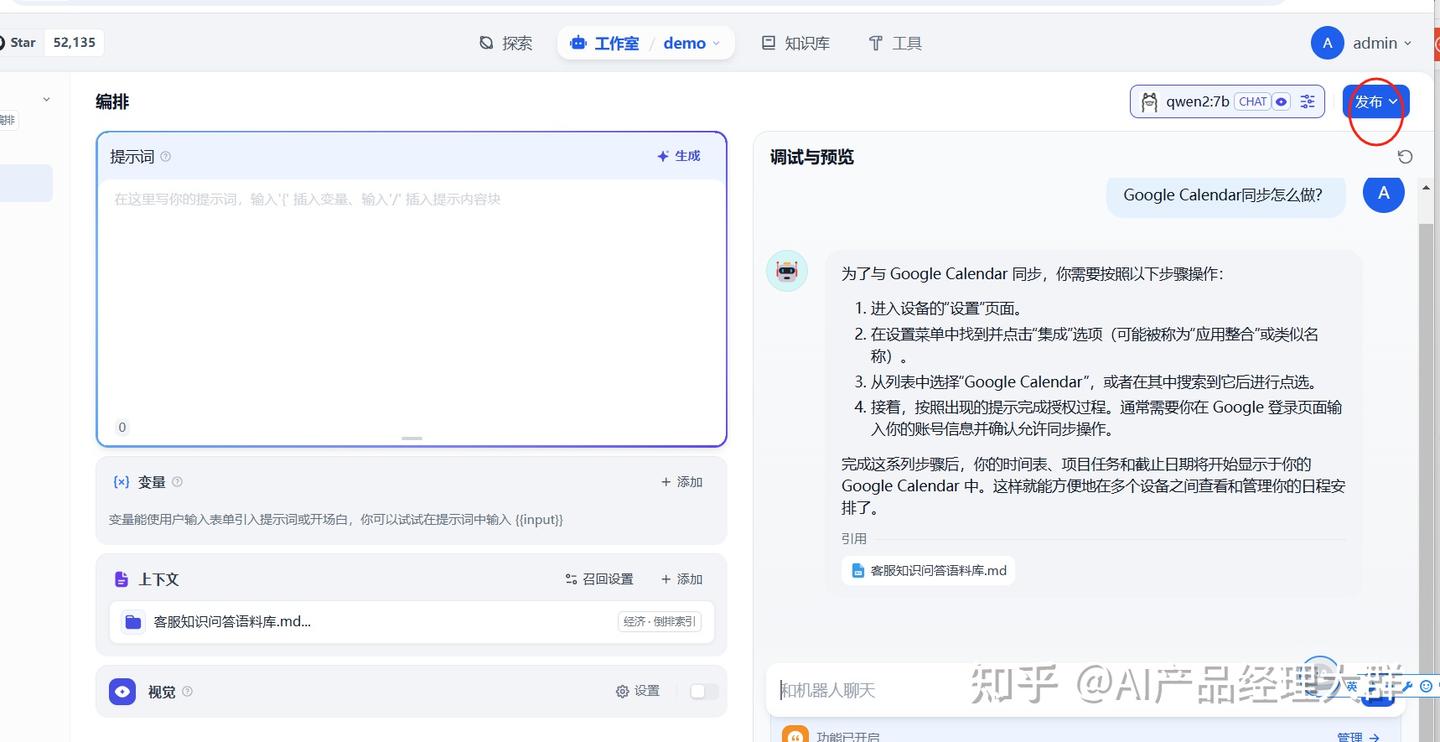
발행 후, 모든 채팅이 현재 지식 베이스에 따라 매칭되어 참조됩니다.
참고:
1. 특정 산업에서는 지식 베이스의 정확도가 높을수록 AI 대형 모델의 참조 답변이 더 좋아지며, 지식 베이스의 내용이 나쁠 경우 AI 대형 모델의 참조 답변도 매우 나빠집니다.
이전 글에 따르면, 모두 수직 산업에서 업무를 할 수 있는 것은 아닐까요?
직장은 게임이지만, 게임은 인생의 전부가 아닙니다. 당장의 이득과 손실에 너무 매몰되지 마시고, 불안감에 항상 묶이지 마십시오. 자신에게 더 많은 힘을 쌓도록 노력하십시오. 미래의 당신은 분명 지금의 당신을 감사할 것입니다. 그때 당신은 발견할 것입니다. 인생의 주도권이 결국 자신의 손에 마음껏 쥐게 되었을 때입니다.
이 글에서는 Dify를 배포 및 설치하고, 이전의 대형 모델과 결합하여 상호작용하는 방법을 보여드리겠습니다.
Dify 설치는 간단합니다. Docker를 사용하여 바로 실행할 수 있으므로, 반드시 서버에 Docker 및 Docker Compose 환경이 설치되어 있는지 확인해야 합니다.
Docker 설치는 《docker》를 참고하세요.
Docker Compose 설치는 《docker-compose 설치》를 참고하세요.
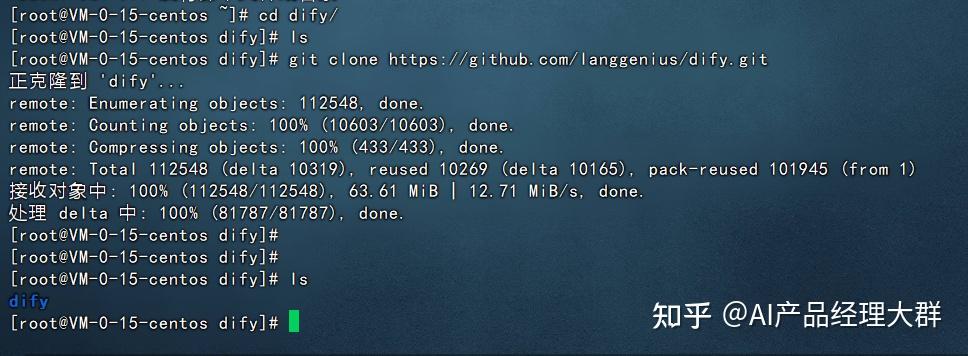
Dify는 오픈 소스 코드이므로, GitHub에서 그 코드를 로컬로 클론해야 합니다:
명령어를 입력하세요;
git clone https://github.com/langgenius/dify.git 다음과 같이:
이제 Dify를 시작합니다. defy/docker 디렉토리로 들어가면 해당 docker-compose.yml 파일을 볼 수 있습니다.

다음 명령어를 실행하여 시작합니다.
#拷贝env文件
cp -r middleware.env.example .env
#执行环境
. .env
#启动dify
docker-compose up -d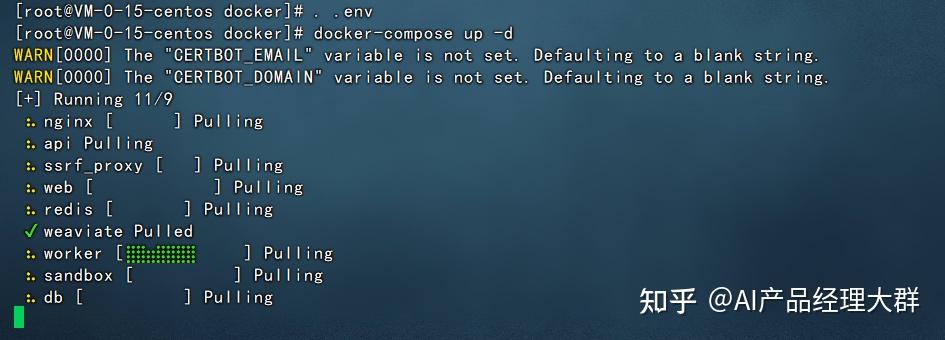
잠시 기다리면 Dify가 시작됩니다.
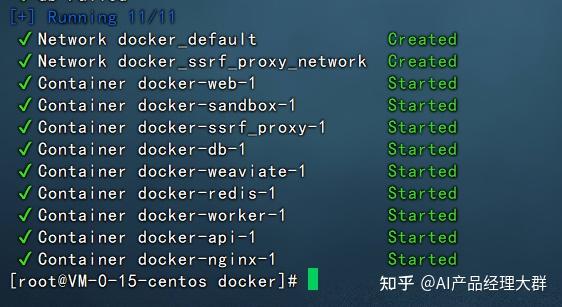
시작이 완료되면 docker ps를 사용하여 10개의 docker 인스턴스가 실행 중인 것을 볼 수 있습니다.
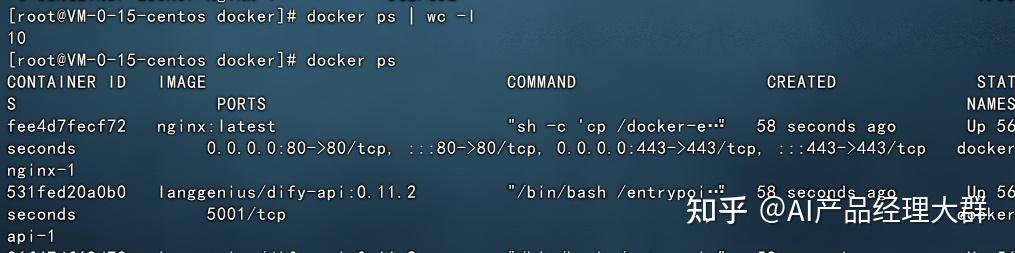
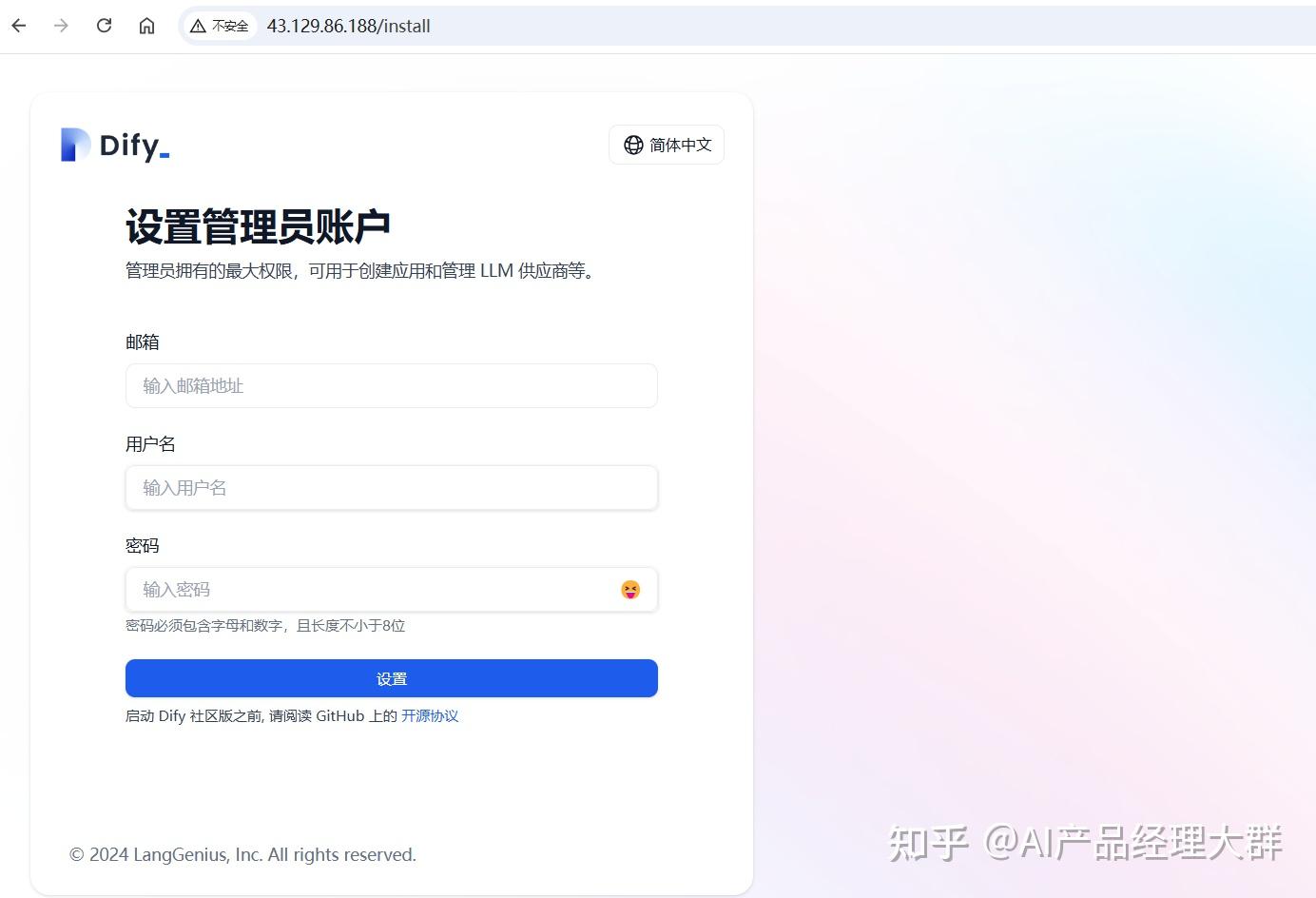
이제 브라우저에서 Dify에 접속할 수 있습니다. 서버의 IP 주소를 입력하면 됩니다:http://128.0.0.1또는 localhost입니다. 포트는 기본값인 80입니다. 최초 접근 시 관리자 계정을 설정해야 합니다:
설정 후 로그인 페이지로 이동하며, 이전에 입력한 관리자 정보를 입력하면 접근할 수 있습니다:
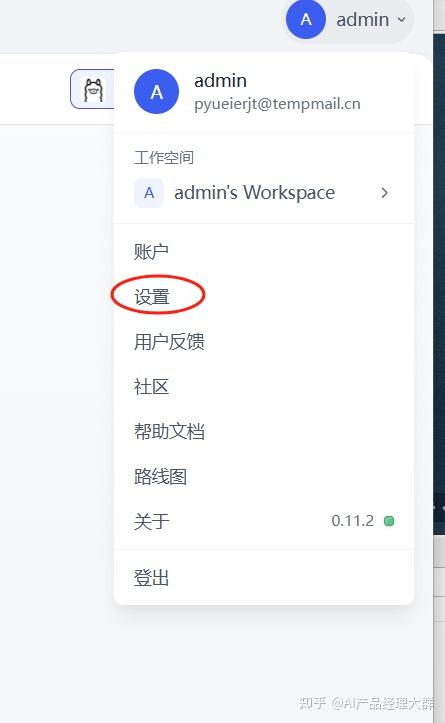
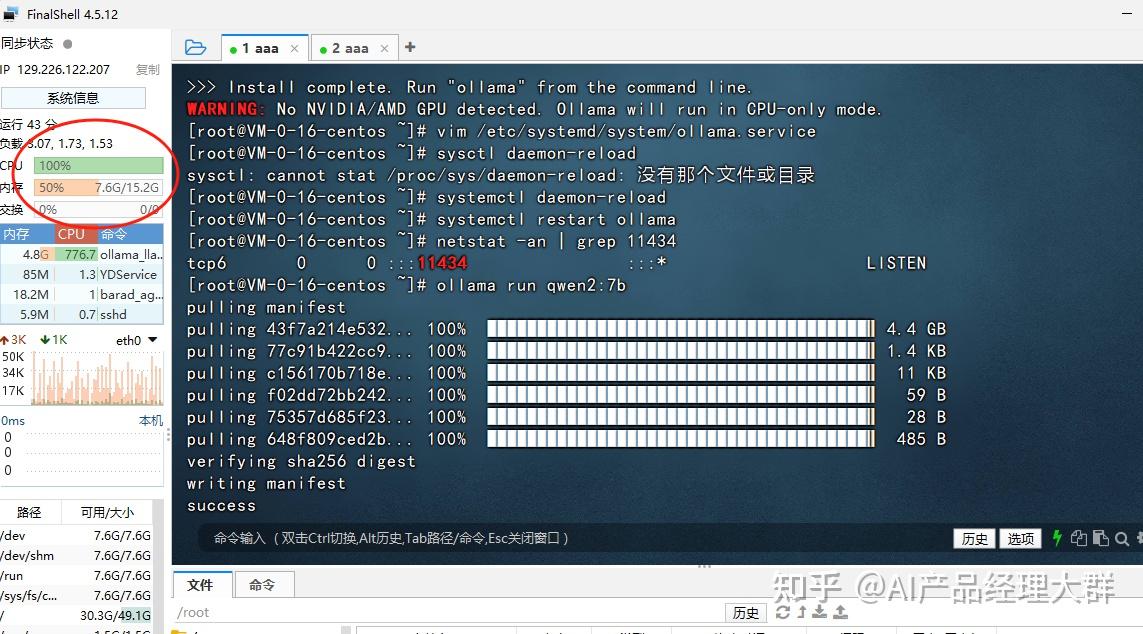
이제 Qwen3-8B 대형 모델을 상속해야 합니다. 먼저 Dify의 dashboard로 들어가서 상단 우측의 프로필 아이콘을 클릭하면 설정 버튼을 볼 수 있습니다:
설정 버튼을 클릭하고 모델 공급자를 선택하세요. 여기서는 이전에 로컬에서 배포한 ollama를 추가하므로 ollama를 선택합니다:
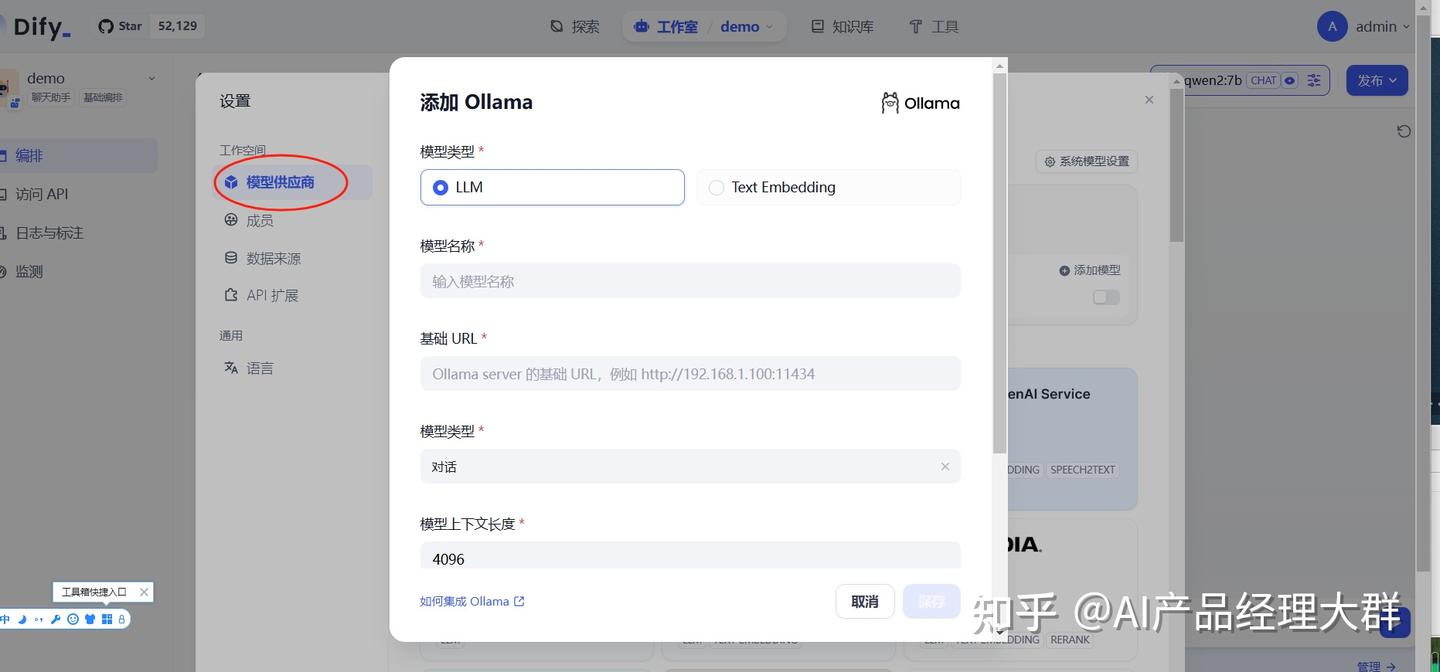
아래와 같은 정보를 입력합니다
模型名称:填写 qwen3:8b이곳의 모델 이름은 임의로 입력할 수 없으며, 서버에서 실행 중인 이름을 입력해야 합니다. 다음 그림과 같습니다:
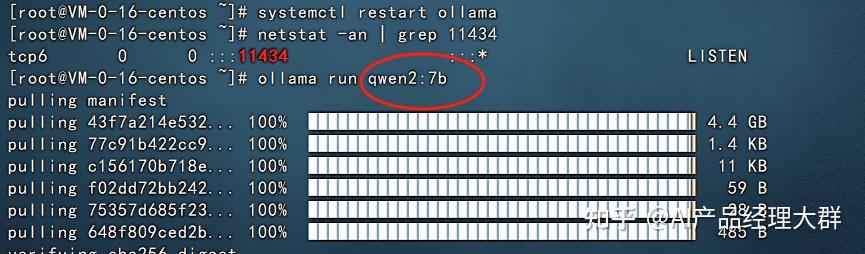
다른 이름을 작성하면 ollama를 구성할 때 404를 찾을 수 없다는 메시지가 표시되므로 여기서 주의해야 합니다. 입력한 이름이 실행되는 모델 이름이 되며, 문자열은 완전히 일치해야 합니다.
基础URL: 这里填写服务器的ip+11434端口即可,例如:http://192.168.1.129:11434
如果ollama在本地,那就是127.0.0.1或者localhost여기서 반드시 접두사를 추가해야 합니다.http://ip, 동시에 포트는 11434입니다. 우리는 앞서 11434 포트를 0.0.0.0/0으로 변경하여 접근할 수 있도록 했습니다.
나머지 정보는 모두 기본값을 유지할 수 있습니다. 여기서 작성한 예시는 다음과 같습니다.
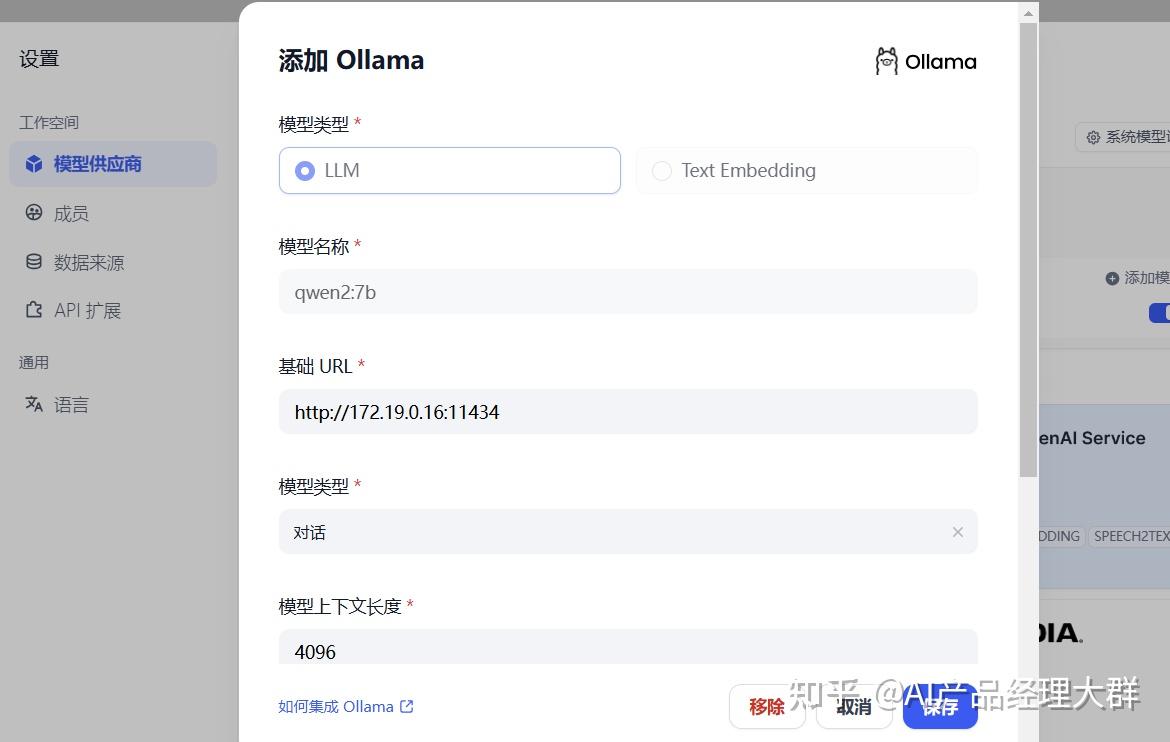
마지막으로 저장을 클릭합니다.
이제 애플리케이션을 생성하는 단계로 이동합니다. 챗봇 도우미를 선택하고 빈 애플리케이션을 생성합니다.
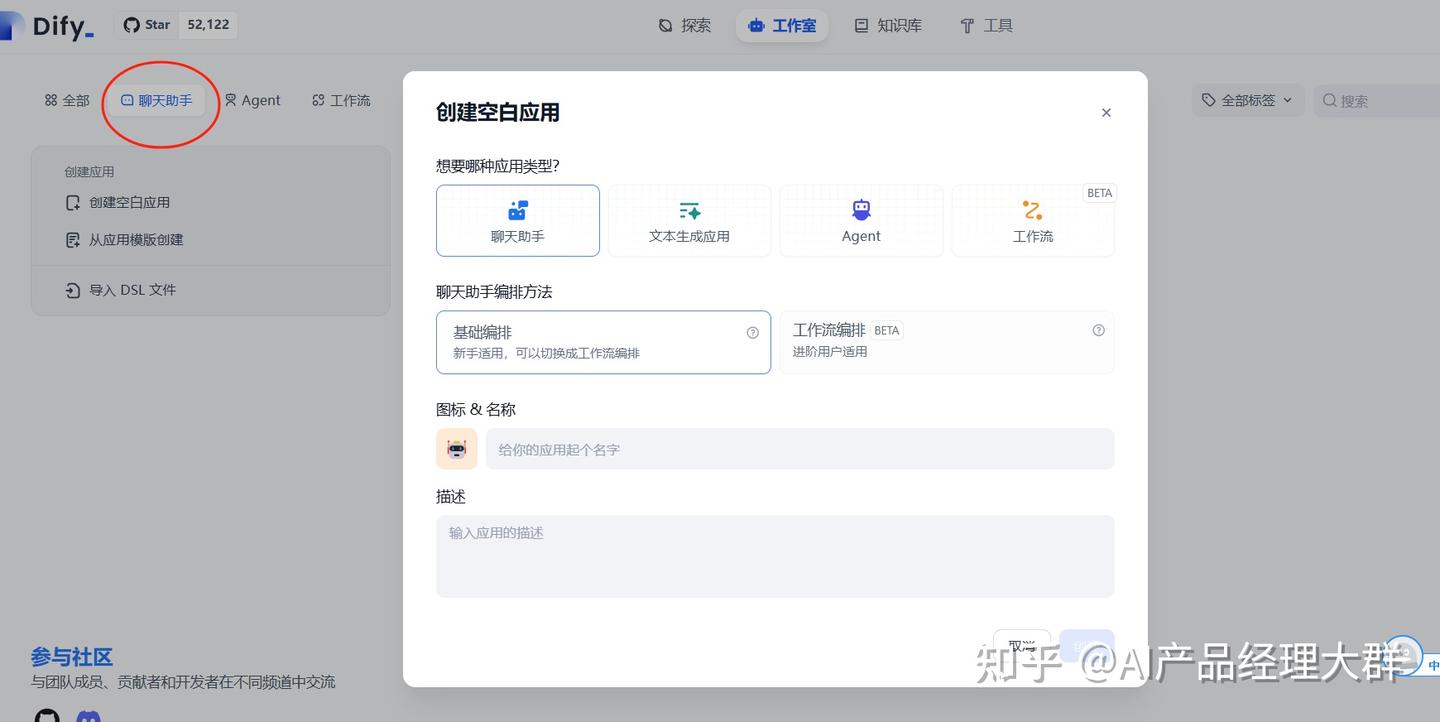
이름과 설명을 작성한 후 생성을 클릭하면 챗봇 도우미 애플리케이션으로 들어갑니다.
그런 다음 우리는 오른쪽 상단에 이전에 추가한 qwen3:8b 모델을 볼 수 있습니다:
오른쪽 상단 작은 창 위의 발행 버튼을 클릭하면
대화 인터페이스로 들어가서 대화를 할 수 있습니다. 예시는 다음과 같습니다:
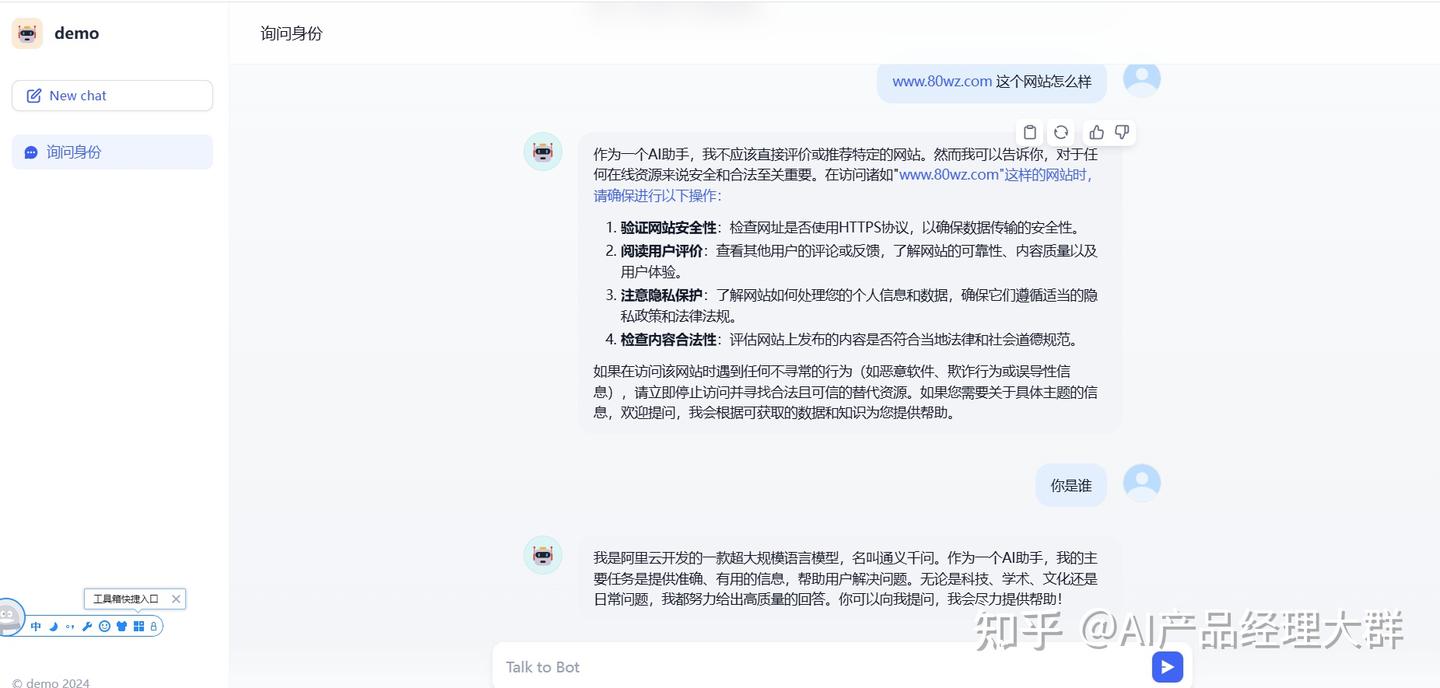
정말 편리하지 않습니까.
특히 주의해야 할 점은 여기의 응답 속도가 서버 구성에 의해 결정된다는 것입니다. 예를 들어 우리는 8C16G의 구성을 사용하고 있으며, 질문할 때 CPU가 완전히 포화 상태가 되고, 답변할 때도 오랫동안 기다려야 합니다.
이상이 바로 우리가 Dify를 사용하여 로컬 배포된 qwen3:8b 대형 모델을 통합하는 사례입니다. 앞으로 우리는 각각의 사례를 소개하여 로컬 지식베이스 통합 등을 통해 비즈니스 시나리오에 더 잘 맞도록 할 것입니다.
SEO 블로그 게시물 생성기(SEO Blog Generator)
고객 리뷰 분석 워크플로우(Customer Review Analysis Workflow)
이메일 보조 워크플로우(Email Assistant Workflow)
텍스트 요약 워크플로우(Text Summarization Workflow)
장편 이야기 생성 워크플로우(Long Story Generator)
세 단계 번역 워크플로우(Three-Step Translation Workflow)
Jina Reader를 기반으로 웹사이트 요약(Summarize website with Jina Reader)
웹 콘텐츠 검색 및 요약 워크플로우(Web Content Search and Summarization Workflow)
Dify 워크플로우 어시스턴트(Workflow Planning Assistant)
질문 분류기 + 지식 + 챗봇(Question Classifier + Knowledge + Chatbot)
지식 검색 챗봇(Knowledge Retreival + Chatbot)
이메일 자동 답장 워크플로우(Automated Email Reply)
커뮤니티 및 생태계: 개발자 커뮤니티, 파트너 및 생태계를 포함하여 지식 공유와 협력을 촉진할 수 있습니다.
이 콘텐츠는 인셔셔RSS(RSS 리더)가 자동으로 집계한 것으로 읽기 참고용입니다. 원문 출처 — 저작권은 원저작자에게 있습니다.