从一串文本中切分出一个一个的词条,并对每个词条进行标准化
1、standard分词器:默认将词汇单元转换成小写形式,去掉领用词和标点符号,中文按单字切分
2、simple分词器:先通过非字母字符来分割文本信息,然后奖词汇单元统一为小写形式。也会去掉数字类型字条
3、whitespace分词器:能去掉空格;但不能大小写转换,不支持中文;也不进行标准化处理
4、language分词器:特定语言分词器,不支持中文
ik_max_word: 将文本做最细精度的拆分; 尽可能多的拆分出词语
ik_smart: 做粗粒度的拆分; 已被分出的词语将不会再次被其它词语占有
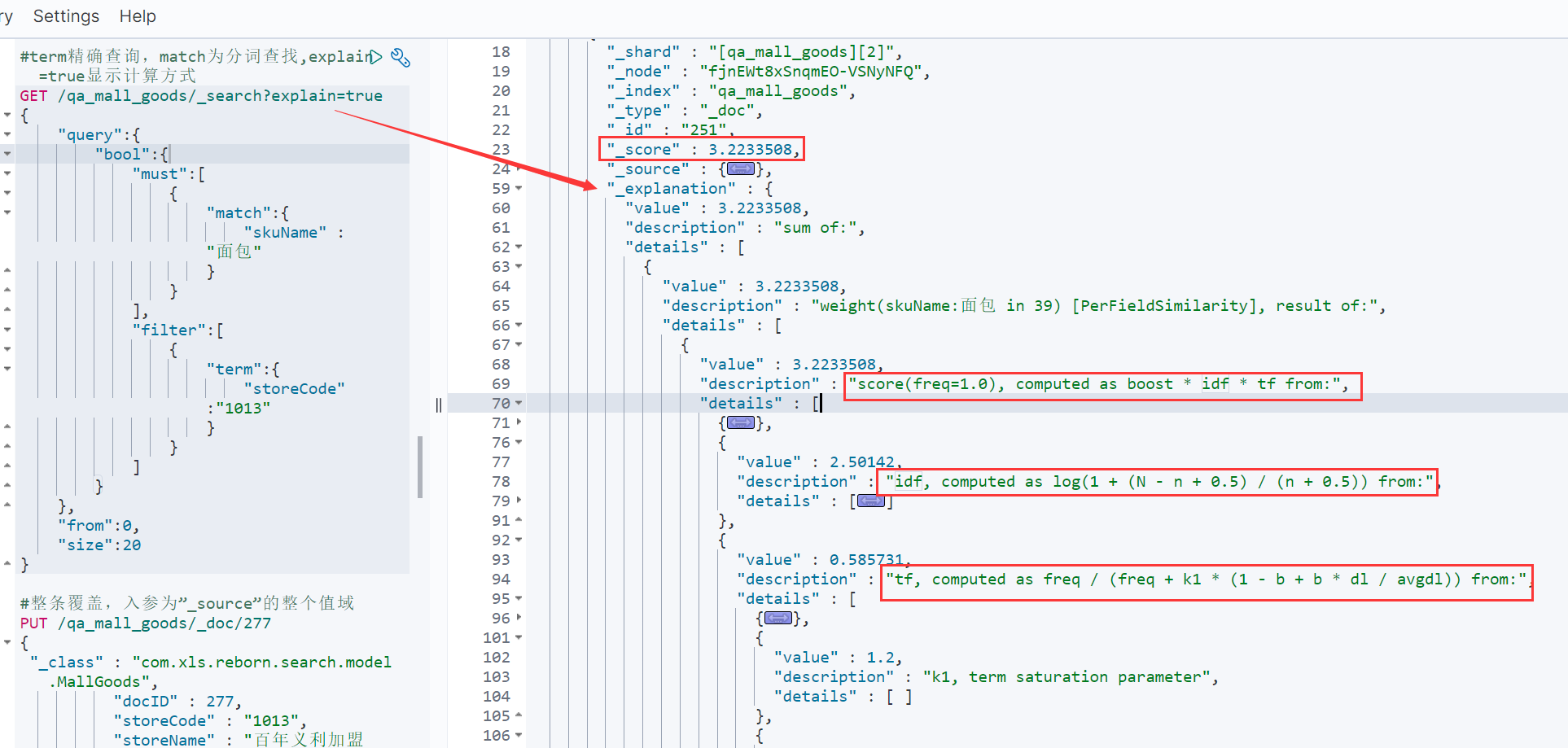
TF:词条在当前文档里出现频率,次数越多相关度超高
IDF:词条在所有文档里出现频率,次数越多相关度越低
explain=true显示计算方式; 结果_score计算结果,"_explanation"显示计算过程
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。