可能会发现一个有点奇怪的现象。
这些框架看起来功能很多:
但如果真的去翻源码或者架构,我们会发现一个事实:
很多 Agent 系统的核心逻辑其实非常简单。
大多数框架,本质上都在实现同一个循环:
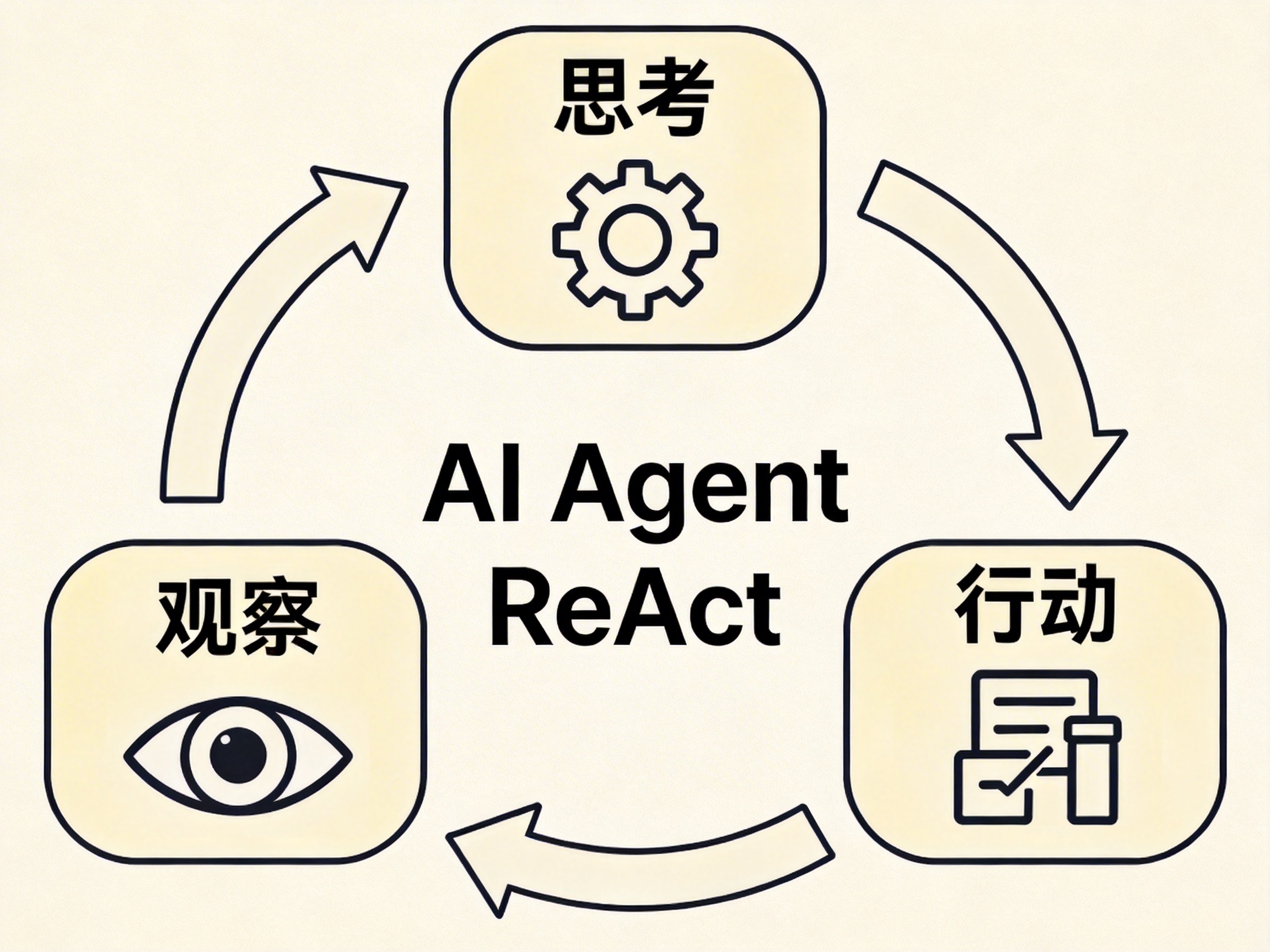
思考 → 行动 → 观察 → 再思考也就是所谓的 ReAct( Reasoning + Acting )。
第一次看到这个结构的时候,我其实有点意外。
因为它简单得有点不像一个“AI 架构”。
但后来越看越发现:
几乎所有 Agent 系统,都离不开这个循环。
先说一个很基础的问题。
大模型本身其实只会做一件事:
根据输入生成一段文本。
比如用户问:
帮我总结一下 AI Agent 的技术趋势模型可以直接生成一段总结。
但如果任务变复杂一点,比如:
写一份 AI Agent 行业分析报告这件事情如果是人来做,一般不会一步完成。
大多数人会这样做:
我们会发现,这其实是一个多步骤过程。
每一步都在决定:
下一步该做什么。
问题就在这里。
普通的大模型并不会自动拆分这些步骤,它只会根据当前输入生成一个结果。
但现实世界的大多数任务,其实都是一种 连续决策过程。
所以如果想让 AI 真的去“完成任务”,就必须给它一种机制,让它可以:
这就是 ReAct 想解决的问题。
ReAct 这个概念来自一篇论文:
ReAct: Synergizing Reasoning and Acting in Language Models
这篇论文的想法其实很简单:
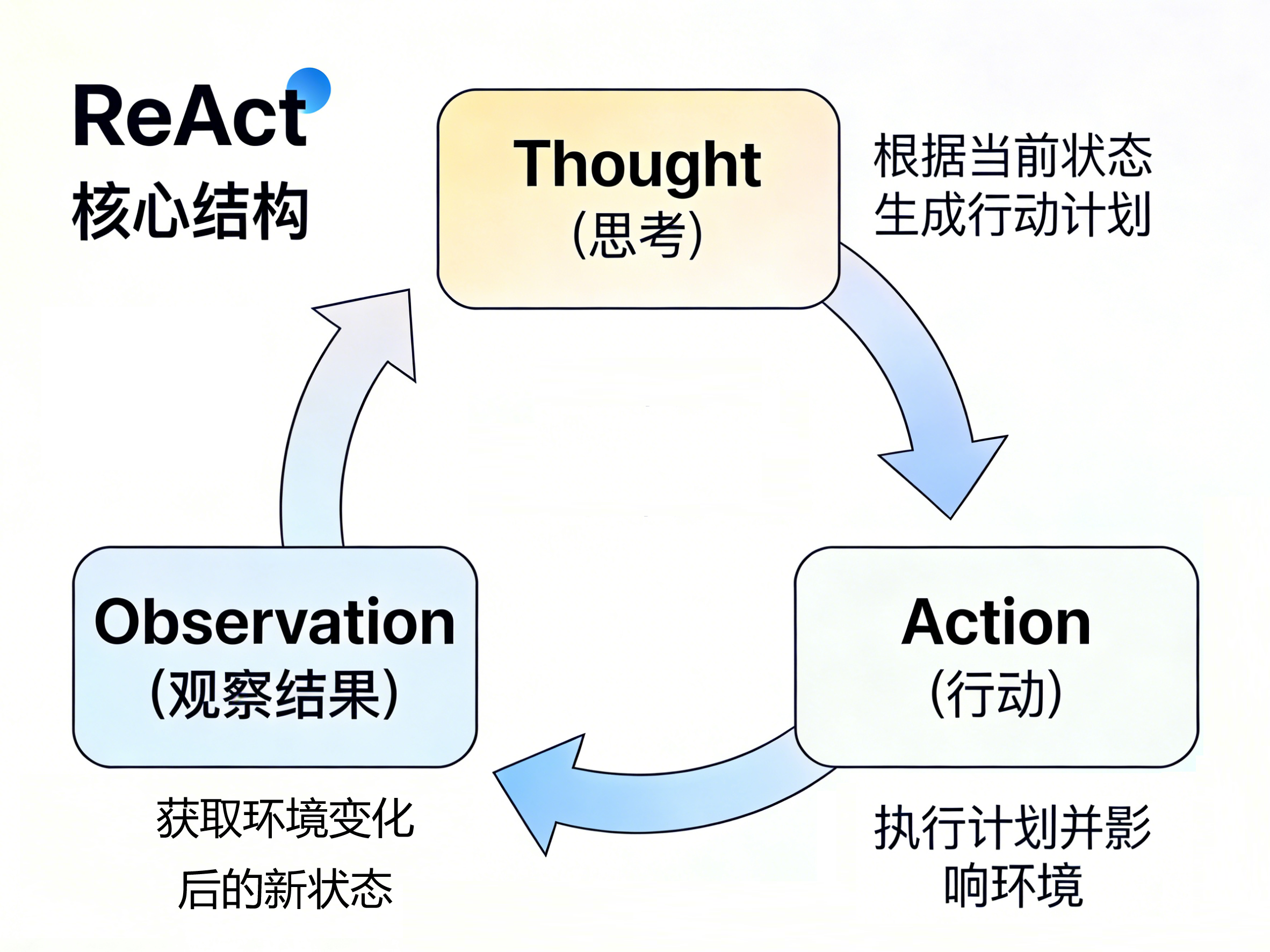
让模型在推理过程中,不只是输出最终答案,而是同时输出三种信息:
Thought(思考)
Action(行动)
Observation(观察结果)例如:
Thought: 需要先查一下最新的 Agent 技术趋势
Action: search("AI Agent trend 2025")
Observation: 返回搜索结果然后继续:
Thought: 需要整理这些资料
Action: summarize(content)
Observation: 得到总结整个过程看起来大概是这样:
Thought → Action → Observation
↑
└──── 再回到 Thought换句话说,模型不再是“一次回答完问题”,而是在执行过程中不断调整下一步动作。
如果用程序员的视角来看,ReAct 其实没那么神秘。
它本质上就是一个循环。
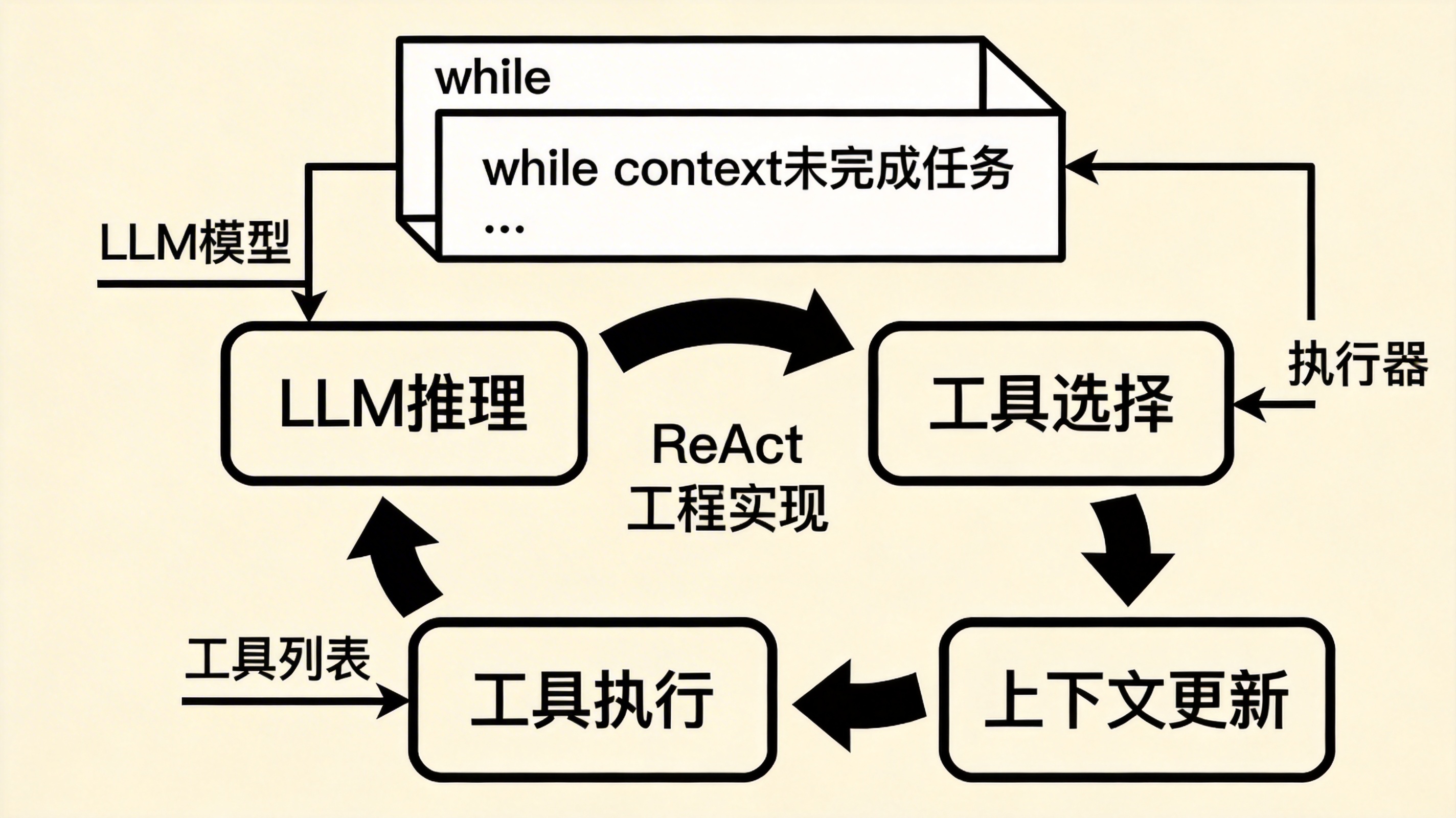
伪代码甚至可以写得很简单:
while (task_not_finished)
{
thought = LLM(reasoning)
action = choose_tool(thought)
observation = run_tool(action)
update_context(observation)
}模型负责做一件事:
决定下一步要做什么系统负责做另一件事:
执行工具
拿到结果
把结果再喂给模型整个系统就可以不断运行,直到任务完成。
很多 Agent 框架,其实只是把这个循环封装得更好用而已。
这个循环真正解决的问题其实只有一个:
让 AI 在执行过程中可以不断修正自己的决策。
举个简单例子。
如果用户说:
查一下最近最火的 AI Agent 框架Agent 可能会这样工作:
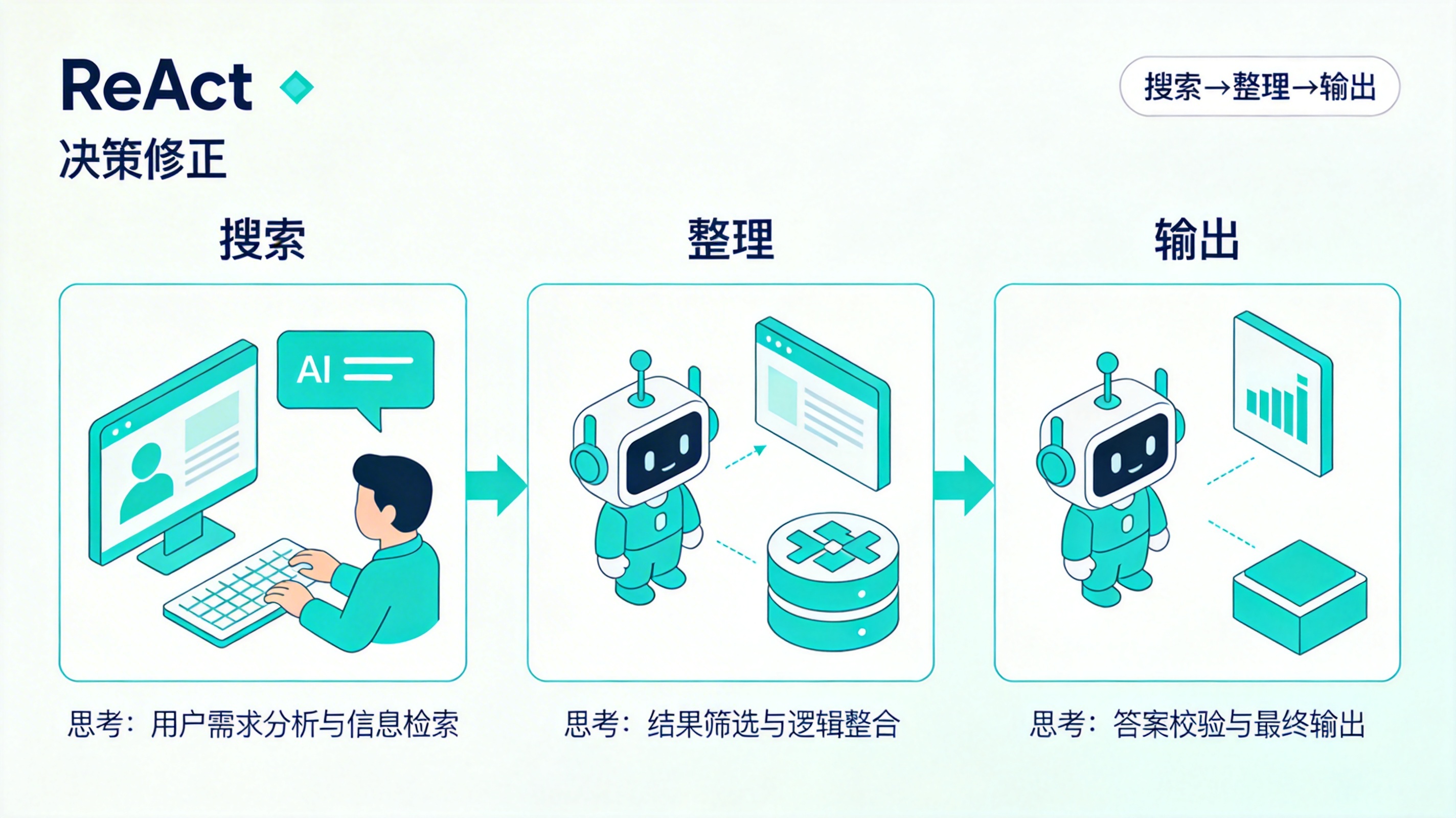
第一步:
Thought: 需要先搜索
Action: search("AI Agent framework")第二步:
Observation: 得到搜索结果
Thought: 需要整理这些框架
Action: summarize()第三步:
Observation: 得到总结
Thought: 可以输出最终结果这个过程其实和人做事情很像。
先找信息,再整理信息,最后给出结果。
如果没有这个循环,模型只能一次性生成一个答案,很难处理中间过程。
在我们做的一个工业控制系统里,这个循环其实非常直观。
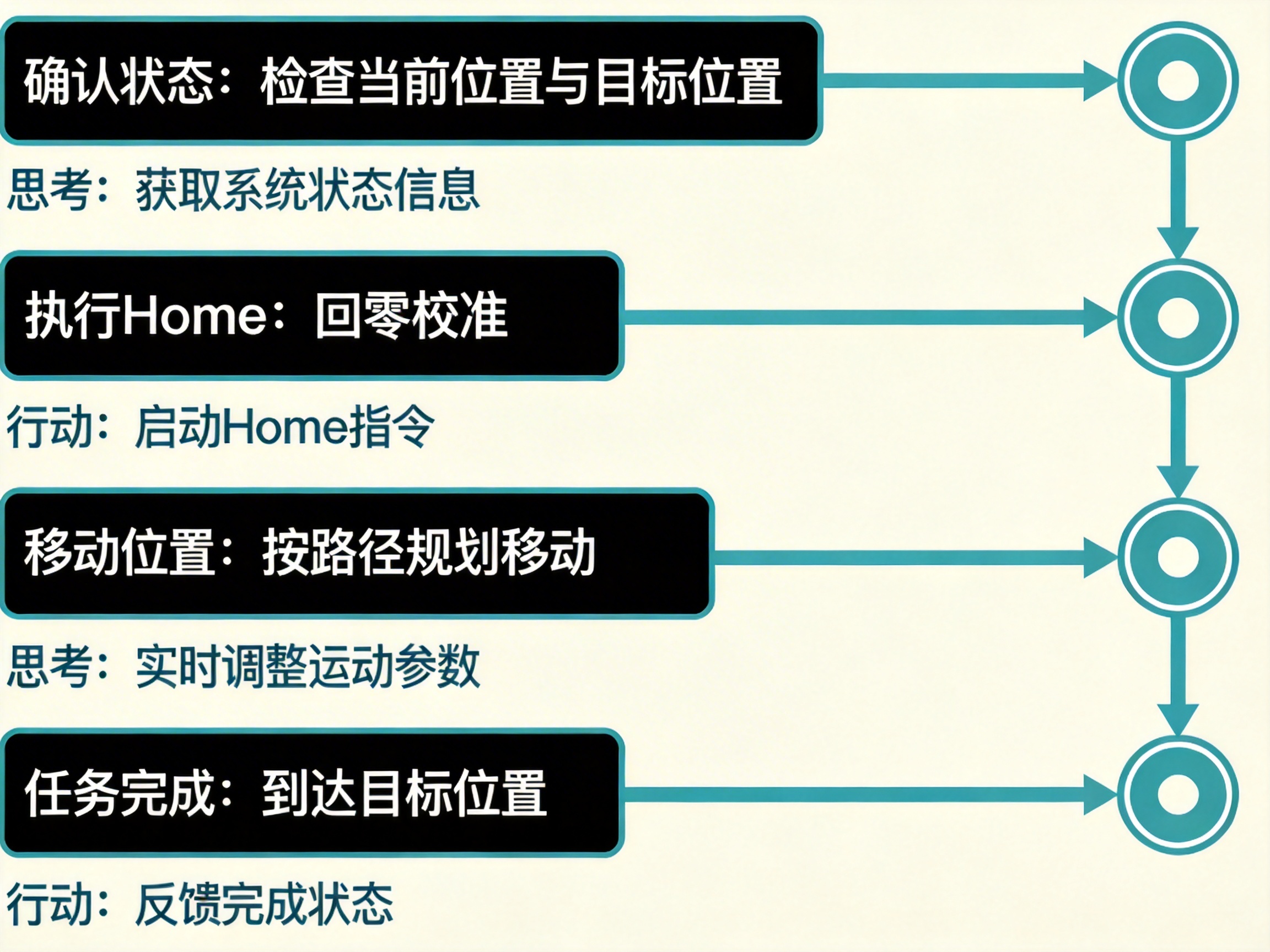
假设用户输入:
把 Stage 移动到 X=100, Y=50Agent 可能会这样执行:
第一步:
Thought: 需要先确认 Stage 是否已经 Home
Action: query_stage_status第二步:
Observation: Stage 未 Home
Thought: 需要先执行 Home
Action: stage_home第三步:
Observation: Stage 已 Home
Thought: 可以执行移动
Action: stage_move(100, 50)第四步:
Observation: Stage 移动成功
Thought: 任务完成如果把这个过程画出来,其实就是:
思考 → 行动 → 观察 → 再思考这和 ReAct 的循环结构是完全一致的。
不管是:
底层其实都离不开这个结构。
差别只是在于:
有些系统在这个循环上增加了更多能力,比如:
但如果把这些东西都拿掉,剩下的核心,其实还是这个 Agent Loop。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。