Pandas是Python中最强大的数据分析库,它的名字来源于"Panel Data"(面板数据)和"Python Data Analysis"(Python数据分析)的组合。Pandas在金融、统计、社会科学、工程等领域都有广泛应用。
Pandas的三大核心优势
高效处理表格数据:轻松应对数百万行的数据集
灵活的数据操作:支持复杂的数据清洗、转换和分析
完美的时间序列支持:内置丰富的时间处理功能
Pandas的安装与导入 :
1、安装Pandas 在命令行中执行以下命令安装最新版Pandas: # pip install pandas 如果需要安装特定版本: pip install pandas==1.3.4 2、导入Pandas 标准导入方式(行业惯例): import pandas as pd # pd是公认的别名 3、验证安装 # 验证安装是否成功 print("Pandas版本:", pd.__version__) try: pd.Series([1, 2, 3]) print("Pandas导入成功!") except ImportError: print("Pandas导入失败,请检查安装")
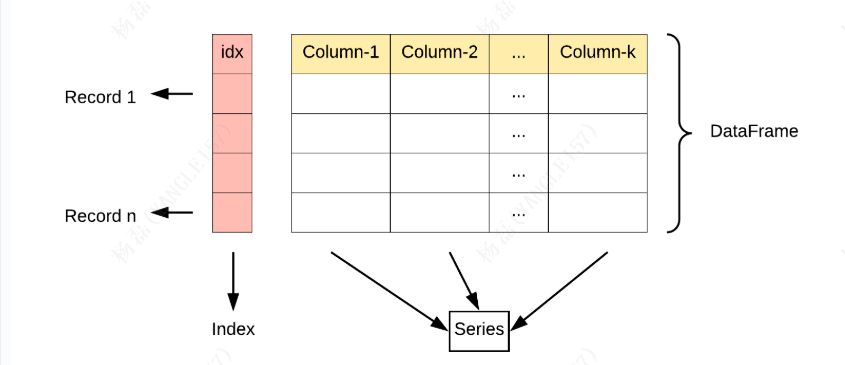
Pandas 主要引入了两种新的数据结构:Series 和 DataFrame。
Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。
一维数组是最简单的数组形式,可以看作是一个有序的元素列表,只有一个维度(行)。

DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。
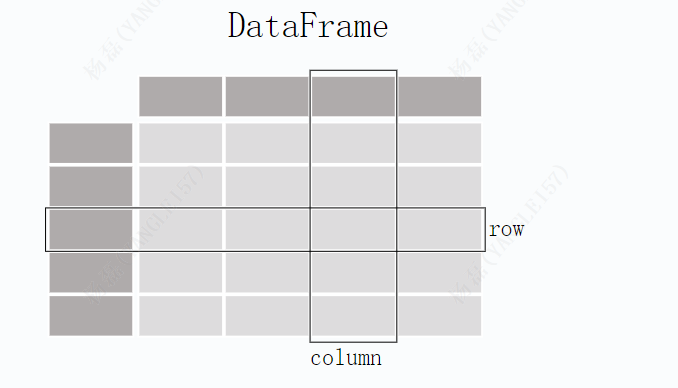
DataFrame 可视为由多个 Series 组成的数据结构:
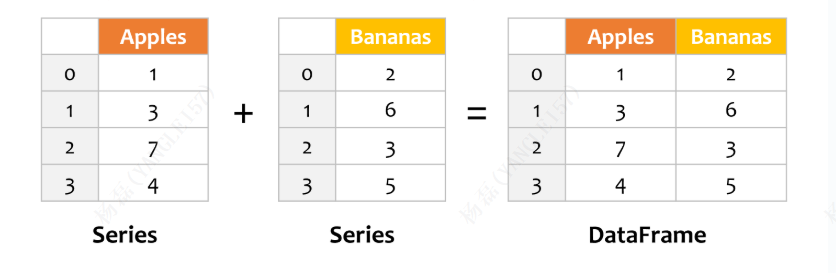
下面这张图展示了两个 Series 对象相加得到一个 DataFrame 对象:
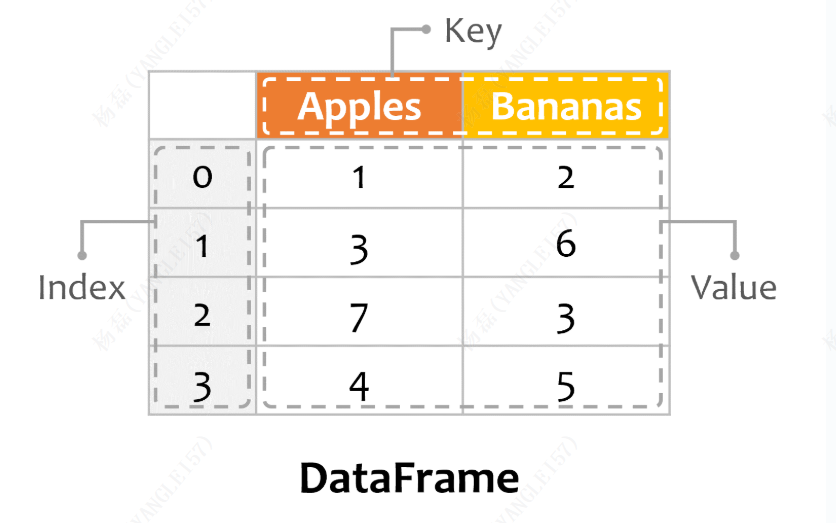
DataFrame 由 Index、Key、Value 组成:
# 创建两个Series对象 ages = pd.Series([25, 32, 28, 35]) names = pd.Series(['张三', '李四', '王五', '赵六']) # 将两个Series对象相加,得到DataFrame,并指定列名 s = pd.DataFrame({'姓名': names, '年龄': ages}) # 显示DataFrame print(s) # 输出结果为: 姓名 年龄 0 张三 25 1 李四 32 2 王五 28 3 赵六 35
Pandas是Python数据分析的基石,掌握它将为你打开数据科学的大门,一步步往前走吧.
参考文档:https://www.runoob.com/pandas/pandas-intro.html
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。