你是否也有过这样的经历:当汽车仪表盘上突然跳出一个陌生的黄色故障灯,或者你想调整后视镜的倒车下翻功能,却不得不从副驾手套箱里翻出那本厚达 400 页、封皮都快粘连的《用户使用手册》。你试图在目录中寻找关键词,翻到第 218 页,却发现还有“参见第 56 页”的跳转。在那一刻,你一定希望有一个懂行的老司机坐在旁边,你只需问一句:“这个像茶壶一样的灯亮了是什么意思?”,他就能立马告诉你答案。在 AI 大模型时代,这个愿望已经可以零成本实现。今天这篇博客,将带大家实战一个非常典型的 RAG(检索增强生成) 场景:利用开源工具 Dify 和本地大模型工具 Ollama,搭建一个能够完全读懂你汽车手册的 AI 智能体。完成后,不仅可以通过 Web 界面与它对话,还能通过 Python API 将其集成到其他应用中。
在开始动手之前,先聊聊为什么选择这套技术栈。市面上有很多构建 AI 应用的方法,比如像之前博客介绍的那样直接用 LangChain 手搓,或者使用云端的 API,但对于不懂编程、不懂技术的用户,Dify + Ollama 是目前性价比最高、上手最快的选择。
Ollama:之前已经介绍过了,它是目前在本地运行大语言模型(LLM)最简单的工具。不需要复杂的环境配置,不需要研究 PyTorch,只需一行命令,就能在 PC 上运行 Llama 3、Qwen 3 等开源模型,最重要的是,它是本地化的,隐私绝对安全。
Dify:如果说 Ollama 提供了“大脑”,那么 Dify 就提供了“身体”和“四肢”,使模型具备了一些“能力”。Dify 是一个开源的 LLM 应用开发平台,它解决了 LLM 开发中最常见的问题:知识库的切片与索引、Prompt 的编排、上下文记忆的管理,以及对外提供标准的 API 接口。它是低代码的,几乎不需要写代码就能搭出一个企业级的 AI 应用。
在接下来的教程中,将完成以下操作:
操作用到的用户手册可在此处下载:https://oss.mpdoc.com/doc/2026/01/10/CA60DABA002540C5894B85DA2DB46E14.pdf?attname=BMW_用户手册_01405A7D339.pdf
安装/更新 Homebrew 后执行:
brew update brew install ollama
启动服务并验证:
ollama serve
# 另开一个终端 ollama -v ollama list
为了保证环境的纯净和易于管理,官方推荐使用 Docker Compose 进行部署。首先,确保你的机器上安装了 Docker 和 Docker Compose(https://www.docker.com)。下面需要将 Dify 的代码仓库下载到本地。
在命令行中执行以下命令:
Dify 是一个完整的应用架构,包含前端、后端、数据库(PostgreSQL)、缓存(Redis)和向量数据库(Weaviate/Qdrant)等多个组件。手动安装这些组件非常繁琐,但通过 Docker Compose,可以一键拉起所有服务。
打开浏览器,访问 http://localhost/,你将看到 Dify 的初始化引导界面。在这里设置你的管理员账号和密码。设置完成后,即可登录进入 Dify。
环境搭建完毕后,目前的 Dify 还是一个“空壳”。下面需要做两件事:
在构建知识库时,除了对话模型,还需要一个专门的 Text Embedding(文本向量化)模型。之前的博客已经介绍了 Embedding 的概念,简单来说,它的作用是把手册里的文字变成计算机能理解的“数字向量”。
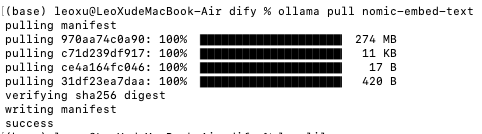
打开命令行,拉取轻量级向量模型 ollama pull nomic-embed-text。
回到 Dify 的网页界面:
头像 -> 设置 -> 模型供应商。
这里需要添加两次:
第一次:添加 LLM(对话模型)
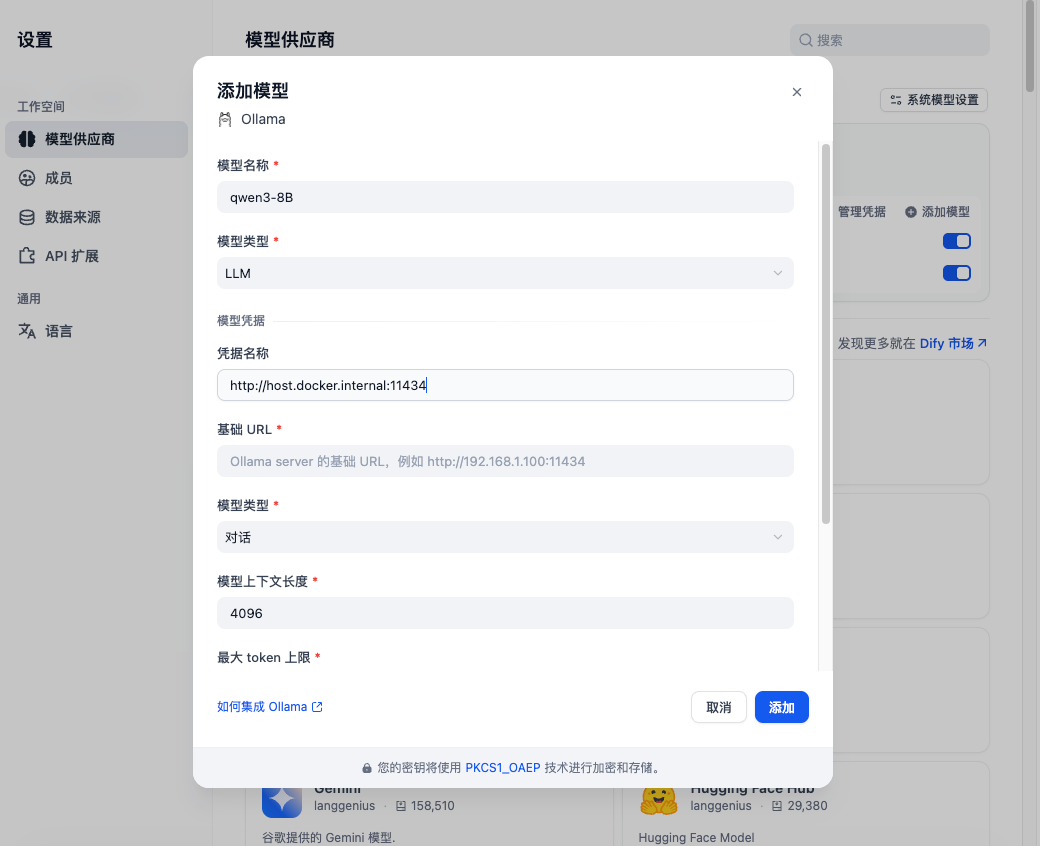
第二次:添加 Text Embedding(向量模型)
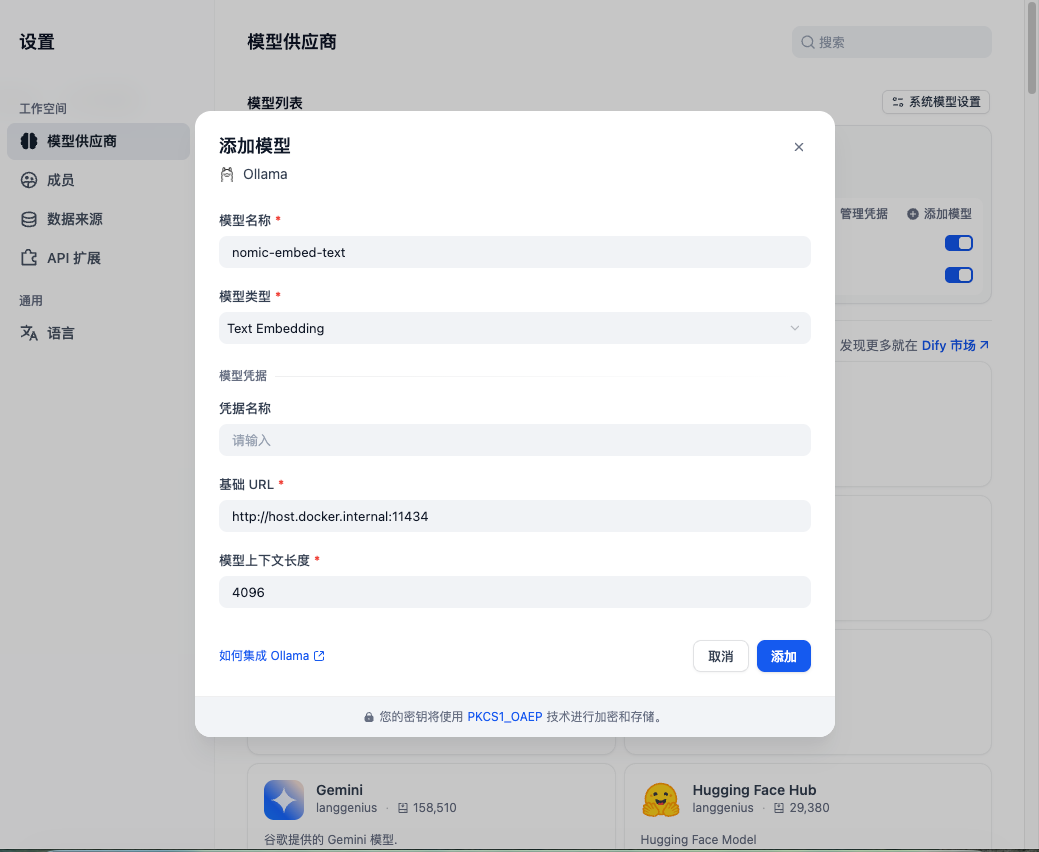
如果保存时提示“Error”,请检查 Ollama 能否通过 URL http://localhost:11434 访问,或者 Docker 网络配置和防火墙设置。
知识库 -> 创建知识库。
用户手册.pdf 拖进去,点击“下一步”。
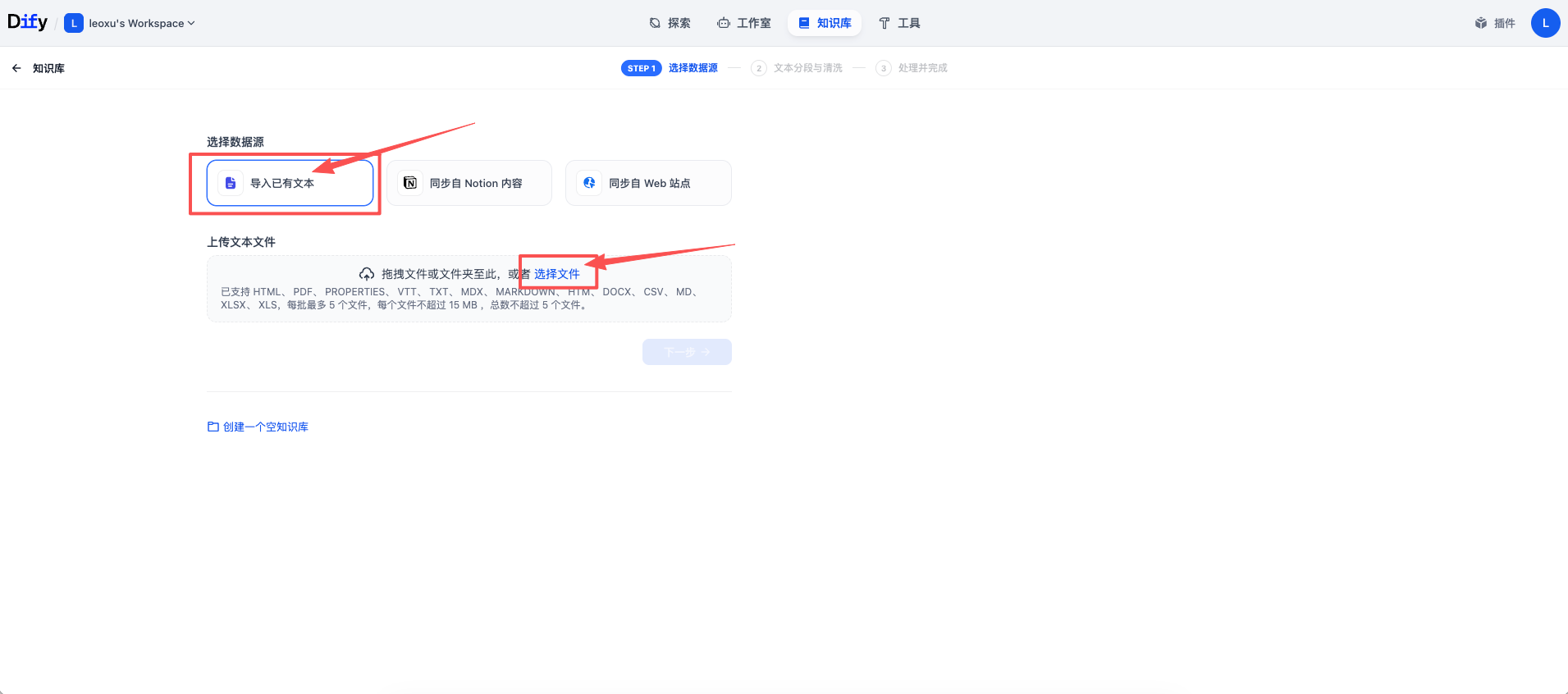
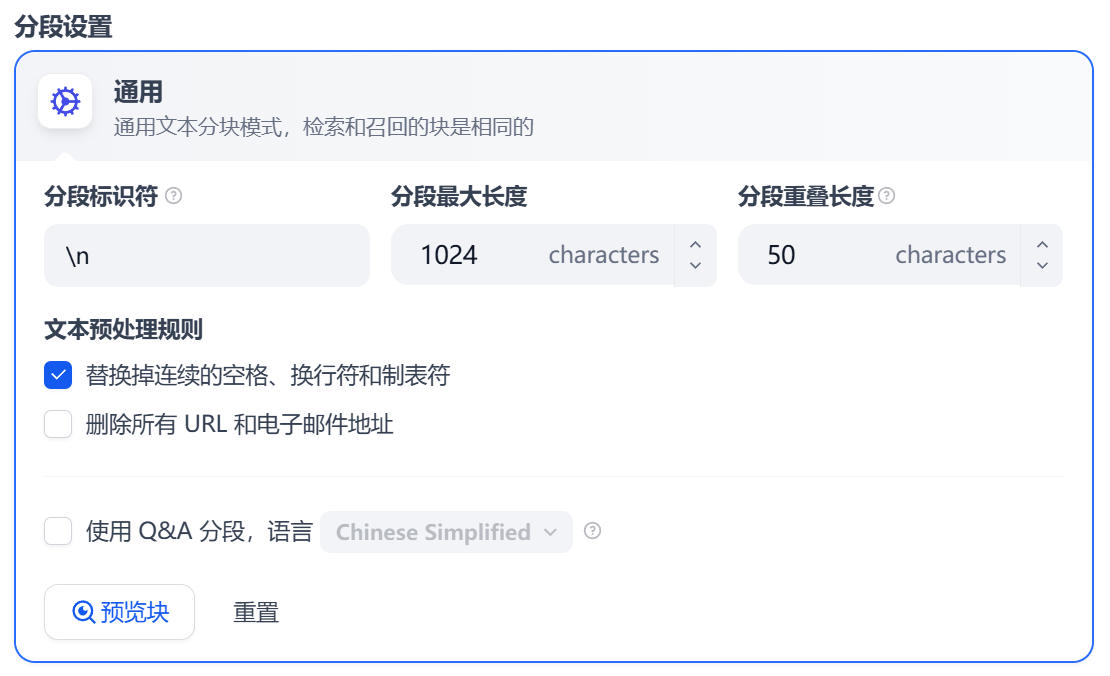
\n 表示换行符,例如此处上传的文档段落之间就是通过换行符分隔的,有些时候可能会使用双换行符 \n\n,即两个段落之间有一个空行。
nomic-embed-text 模型进行向量化处理。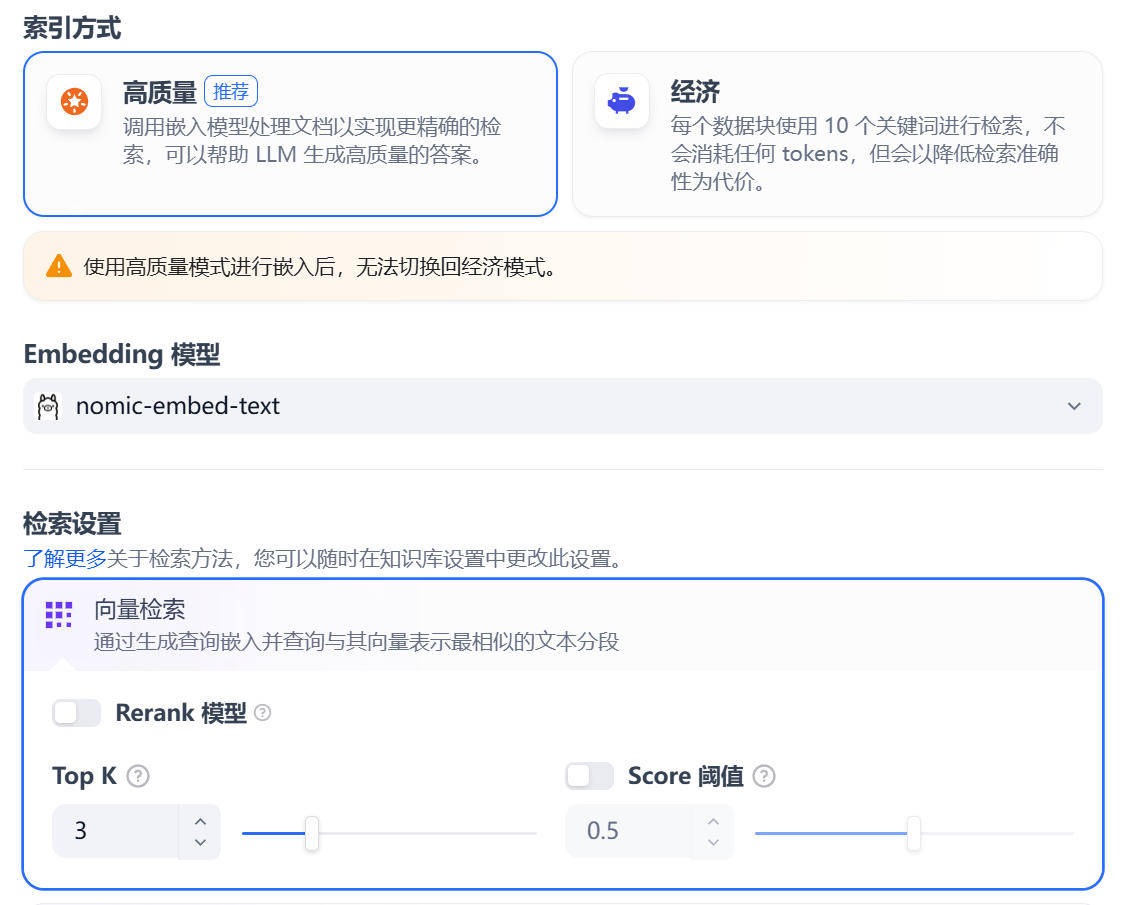
此时,Dify 会将几百页的 PDF 拆解成小段,转换成向量,并存入内置的向量数据库中。根据文档大小,这可能需要较长的时间。
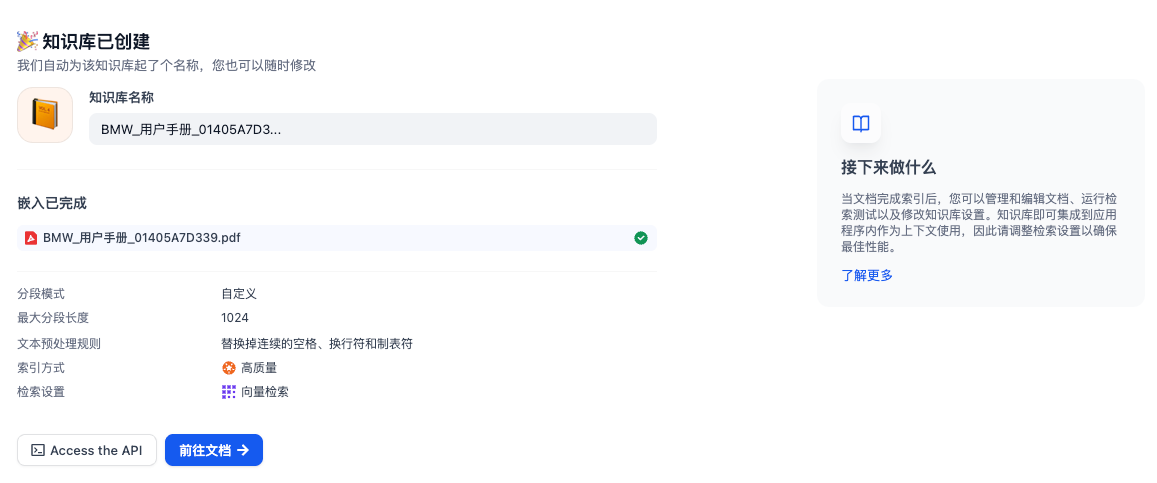
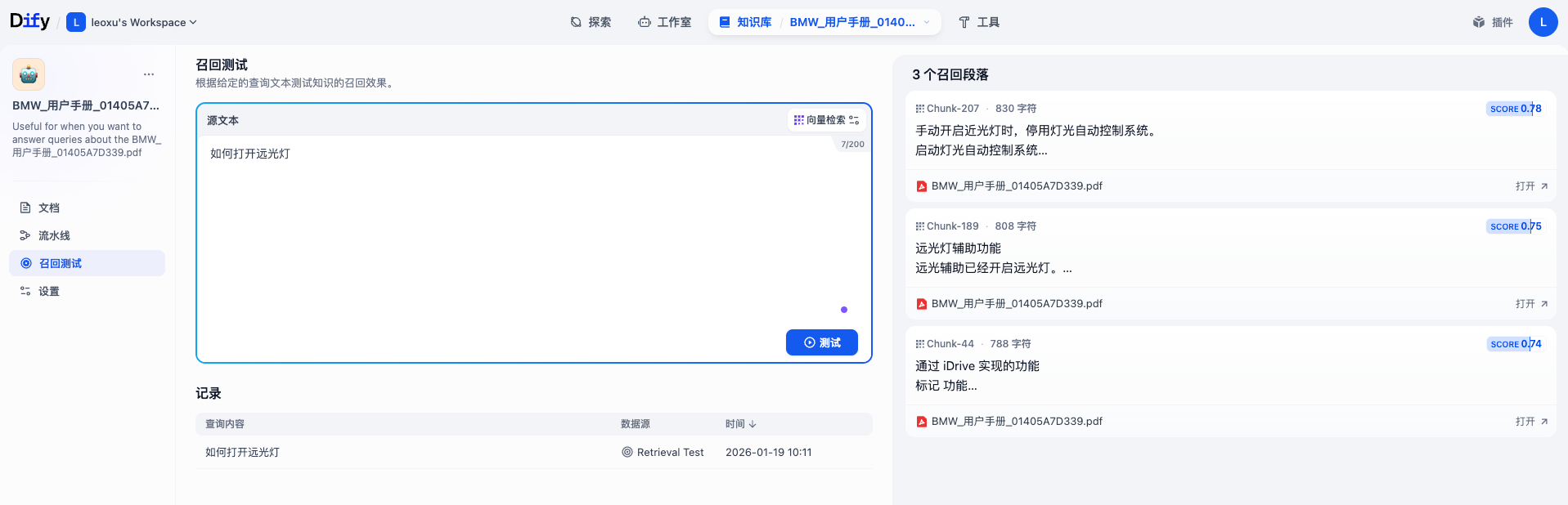
不要急着去创建聊天助手,先确认知识库“懂了”没有。在知识库详情页的左侧,找到 召回测试 按钮。这里可以模拟检索过程。例如输入测试文本:“如何打开远光灯?”,点击 测试,系统会展示它从手册中找到的最相关的几个段落。如果结果不准,说明分段可能切得太碎了,或者 PDF 解析乱码。这时需要回到 设置 中调整分段规则重新索引。
如果说知识库是 AI 的“图书馆”,那么 智能体编排(Orchestration) 就是给 AI 制定“员工手册”。需要告诉 AI:你现在的身份是什么?你应该怎么查阅资料?遇到不知道的问题该怎么回答?在 Dify 中,这一步不需要写代码,全程可视化操作。
回到 Dify 首页的 工作室,点击 创建应用 按钮。应用类型选择 Chatflow,并起一个合适的名称。
进入应用后,会看到一个左右分栏的界面:
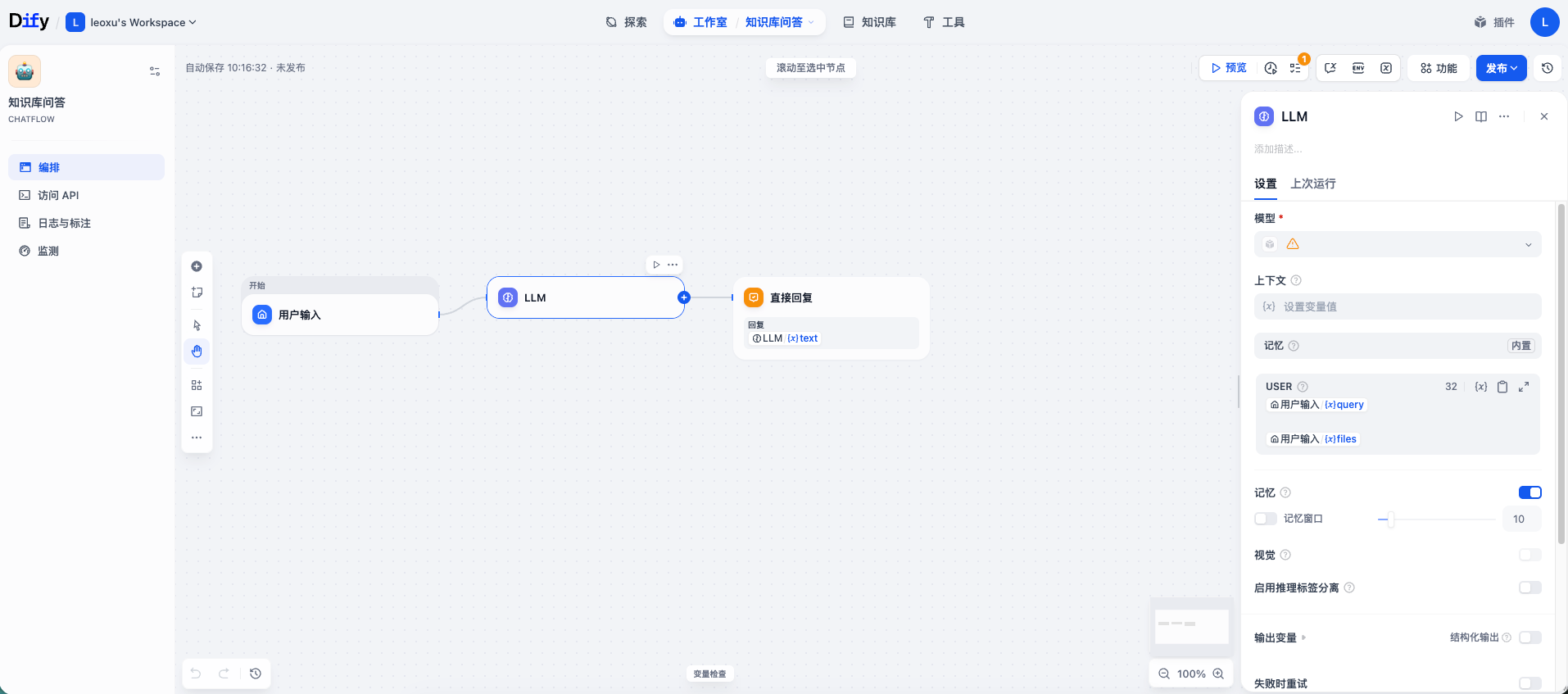
在实际测试中,你可能会发现 AI 有时候变得“笨笨的”。因为用户的口语表达和手册的书面术语不完全一致,导致检索失败。为了解决这个问题,需要在 AI 去知识库“翻书”之前,先对用户的问题进行“预处理”,也就是提取检索的关键词句。
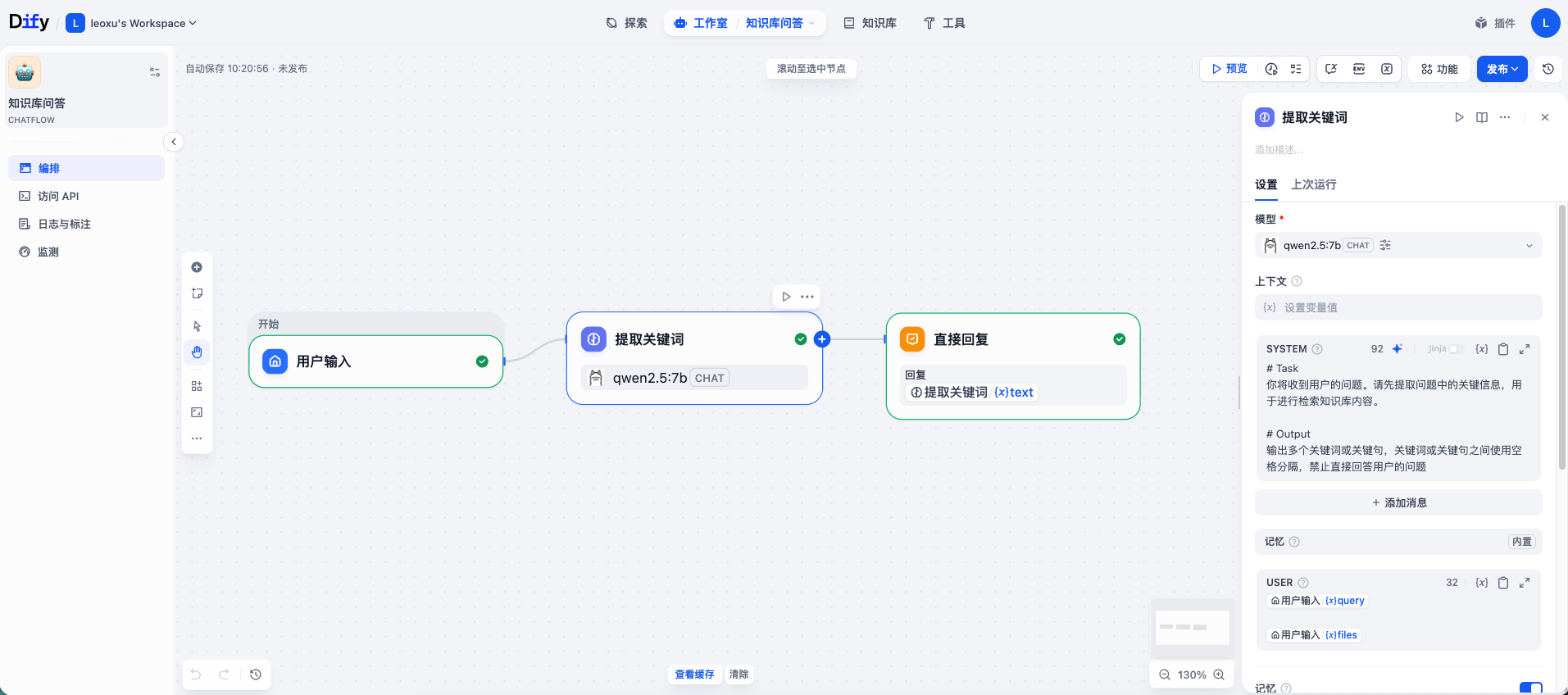
下面点击默认提供的 LLM 节点,修改名称为“提取关键词”。在右侧的 SYSTEM 提示词区域,输入以下内容:
# Task
你将收到用户的问题。请先提取问题中的关键信息,用于进行检索知识库内容。
# Output
输出多个关键词或关键句,关键词或关键句之间使用空格分隔,禁止直接回答用户的问题
完成后可以点击顶部的 预览 按钮进行测试。
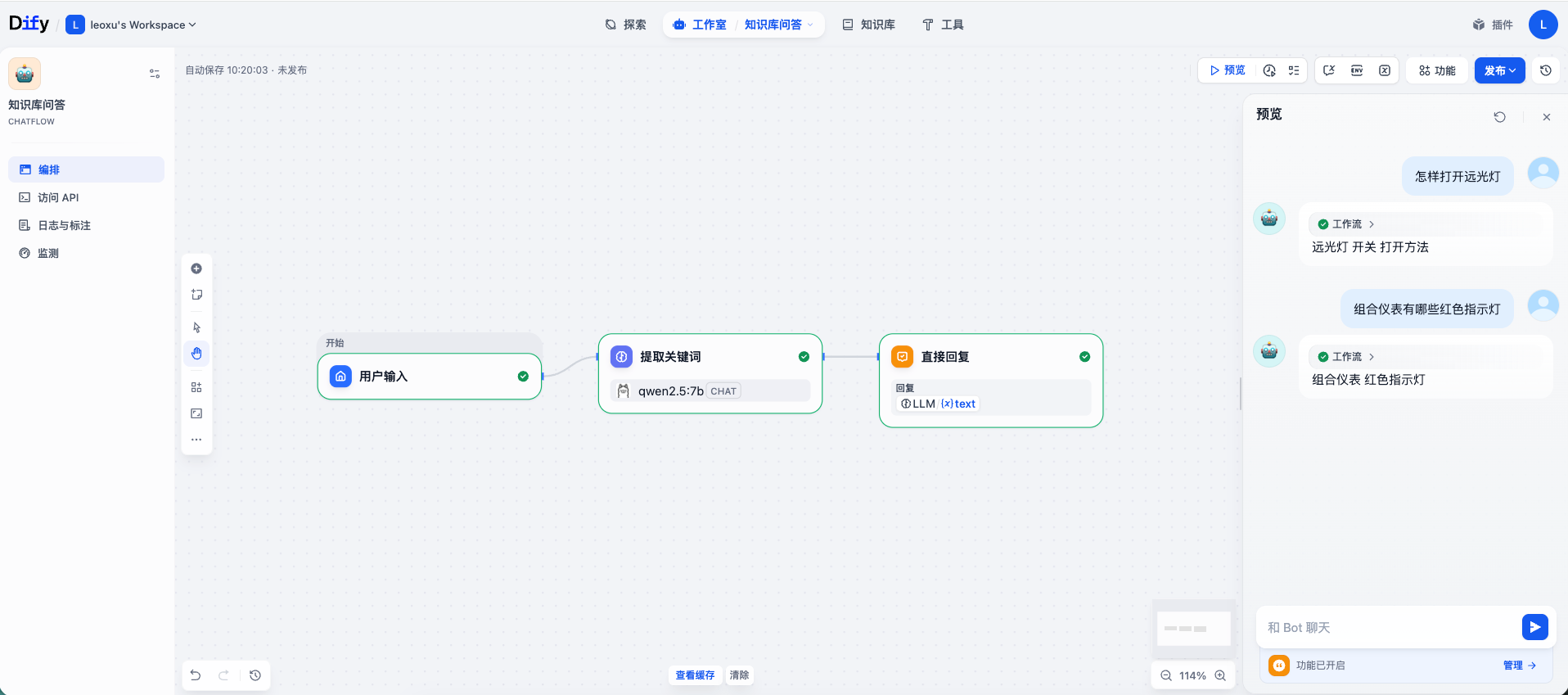
检索关键词有了之后,就可以利用关键词在知识库中检索相关内容。在 提取关键词 和 直接回复 节点之间,添加一个新节点 知识检索。
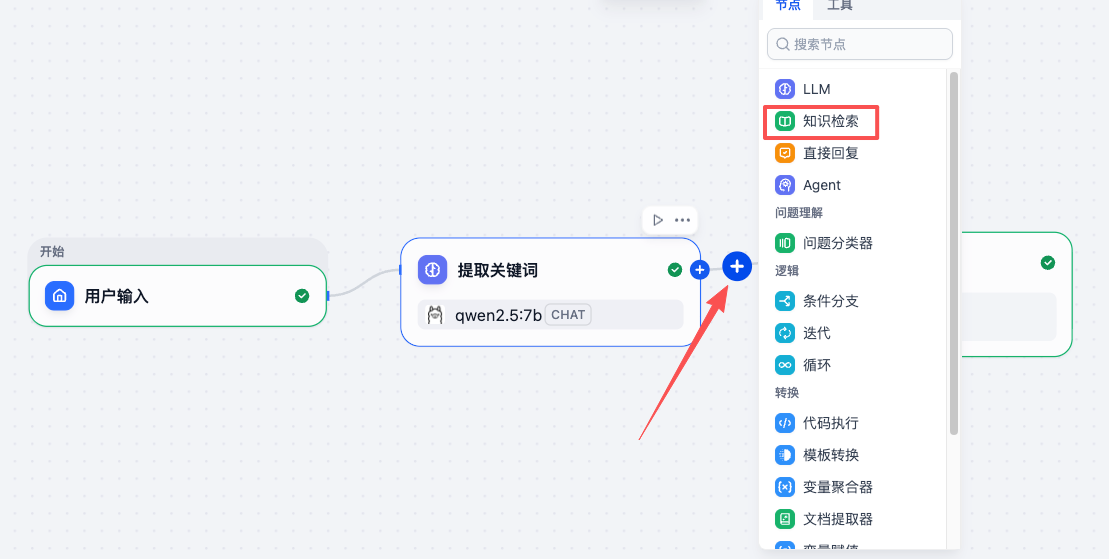
将 查询文本 改为 提取关键词 节点的输出,知识库 选择刚刚创建的“用户手册”知识库。
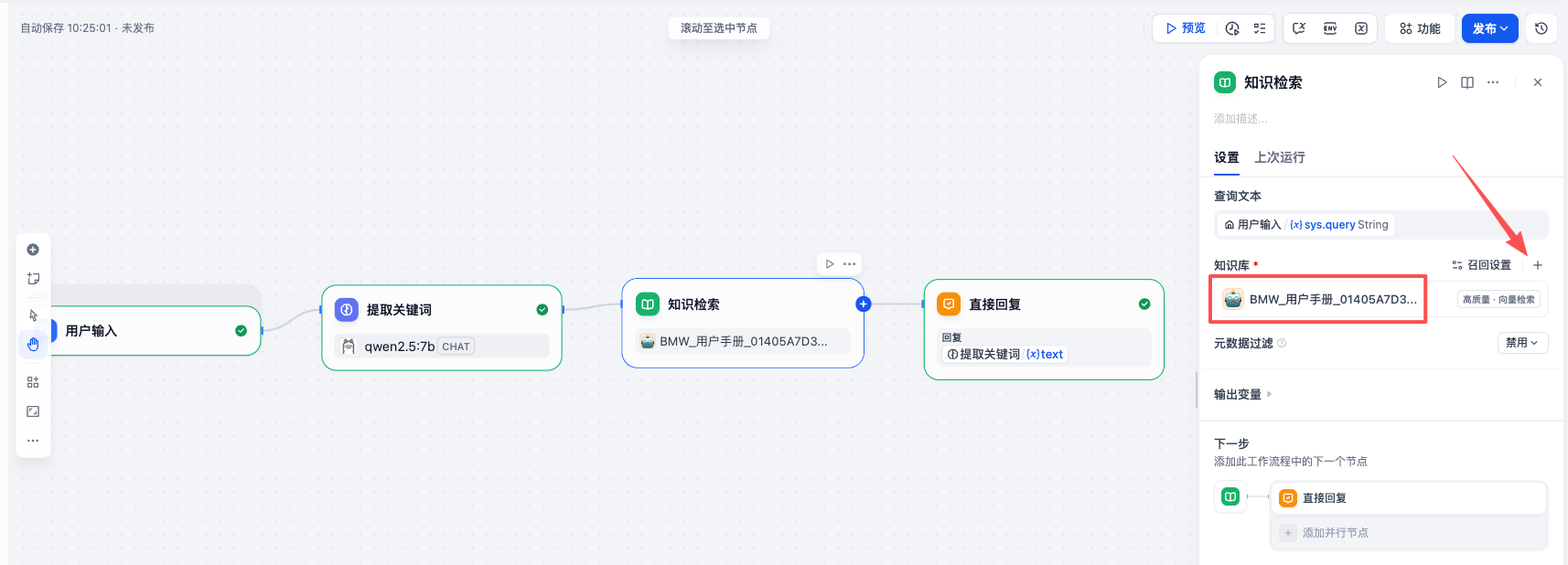
从知识库中检索到 相关信息(Context,上下文) 后,接下来就是让 AI 根据这些信息回答用户的问题了。在 知识检索 和 直接回复 节点之间,添加一个 LLM 节点 名称为 回答问题。
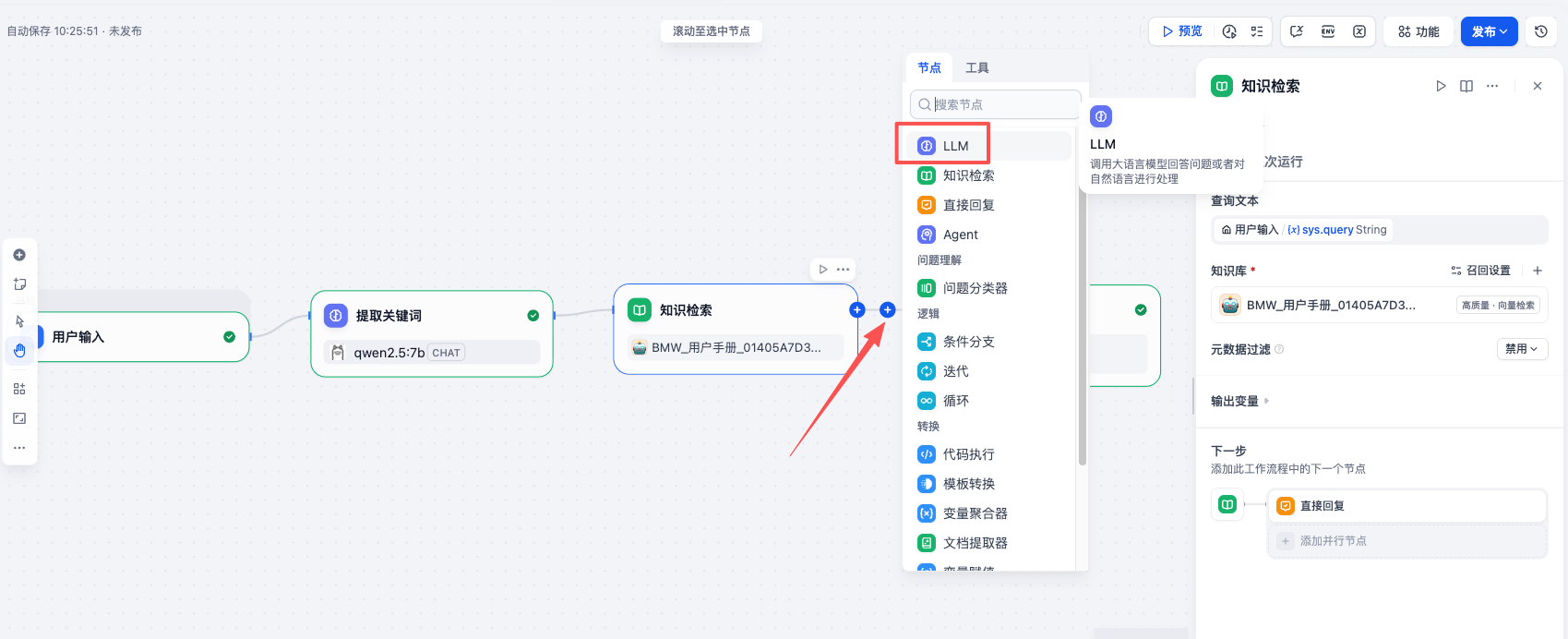
在右侧的 上下文 中选择 知识检索 节点输出的结果 result,SYSTEM 提示词区域,输入下面的提示词,这段提示词使用了 Role-Constraints-Goal 框架,能有效防止 AI 产生幻觉。
# Role
你是一位经验丰富的汽车维修与使用专家。你的任务是根据【Context】提供的内容,准确、简洁地回答用户关于车辆使用的问题。
# Constraints
1. 必须完全基于【Context】中的信息回答,严禁凭空捏造或利用外部知识回答手册未涉及的内容。
2. 如果【Context】中没有相关信息,请直接回答:“很抱歉,当前手册中未找到关于该问题的说明。”
3. 回答步骤要清晰,如果是操作指南,请按 1. 2. 3. 分点列出。
4. 语气要专业、耐心、乐于助人。
# Goal
帮助用户快速解决车辆使用中的疑惑,确保行车安全。
# Context
{{#context#}}
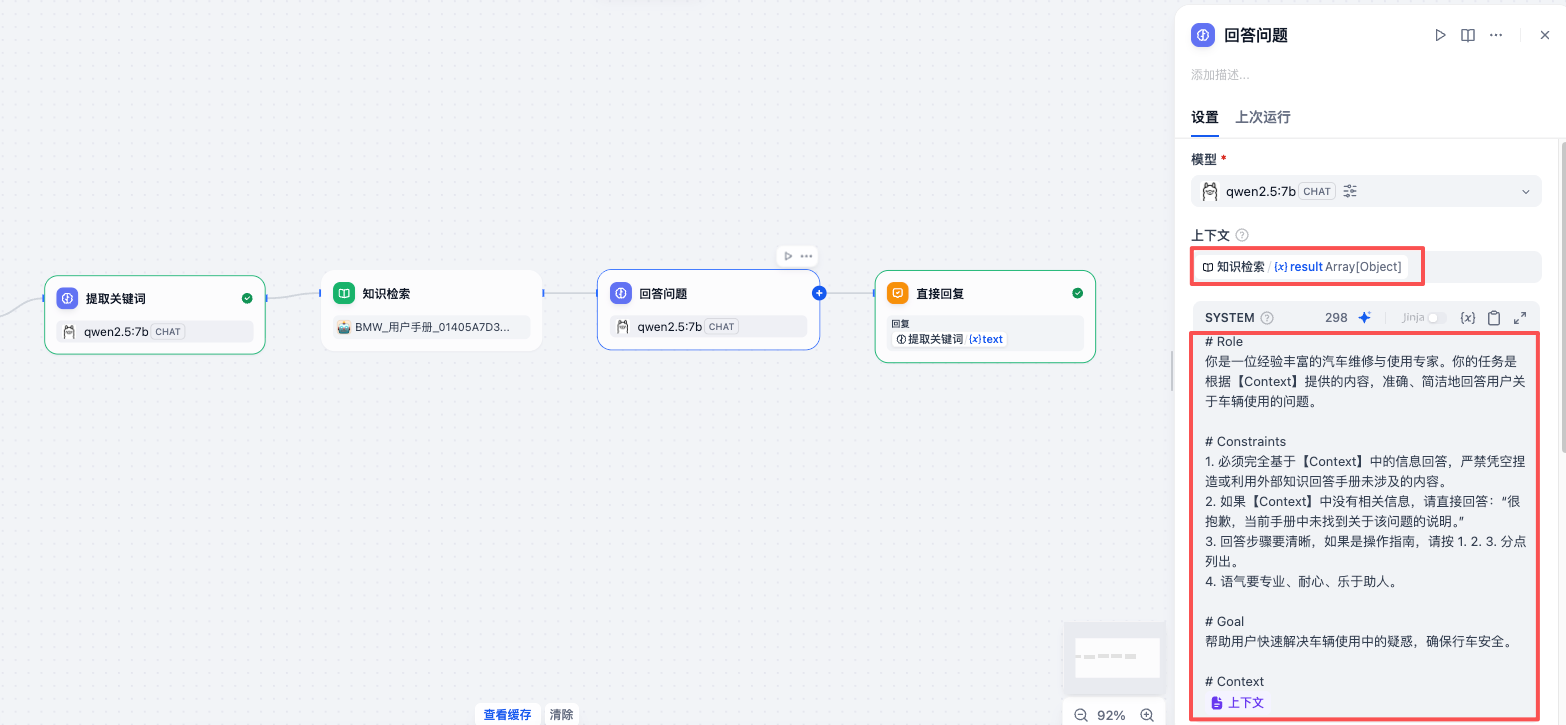
点击模型右侧的图标,设置 温度(Temperature) 参数,可以设为小于 0.5 的值。温度越低,AI 越严谨、越死板;温度越高,AI 越发散、越有创造力。对于“查阅说明书”这种严肃场景,需要的是绝对的准确,而不是创造力。
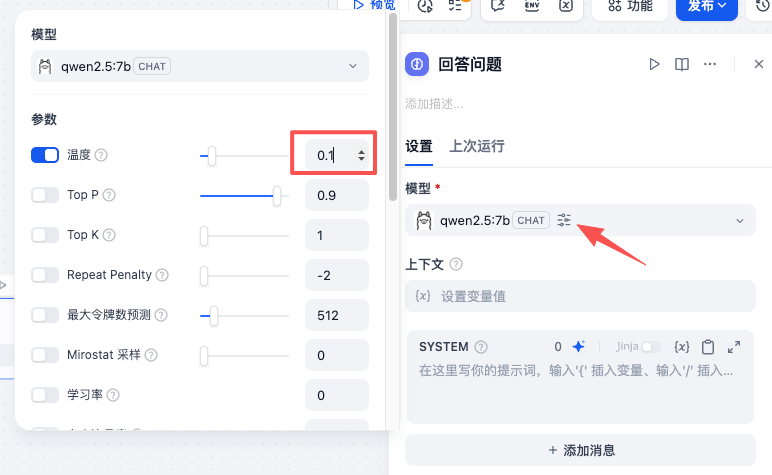
以上配置完成后,先在右侧进行预览测试,观察 AI 的回答是否准确、步骤是否清晰,并且有无引用来源。如果不满意,可以继续调整提示词或上下文设置,直到满意为止。测试满意后,点击右上角的 发布 按钮。发布成功后点击 运行,即可通过 URL 进入 Web 界面和你的“车辆管家”聊天了!
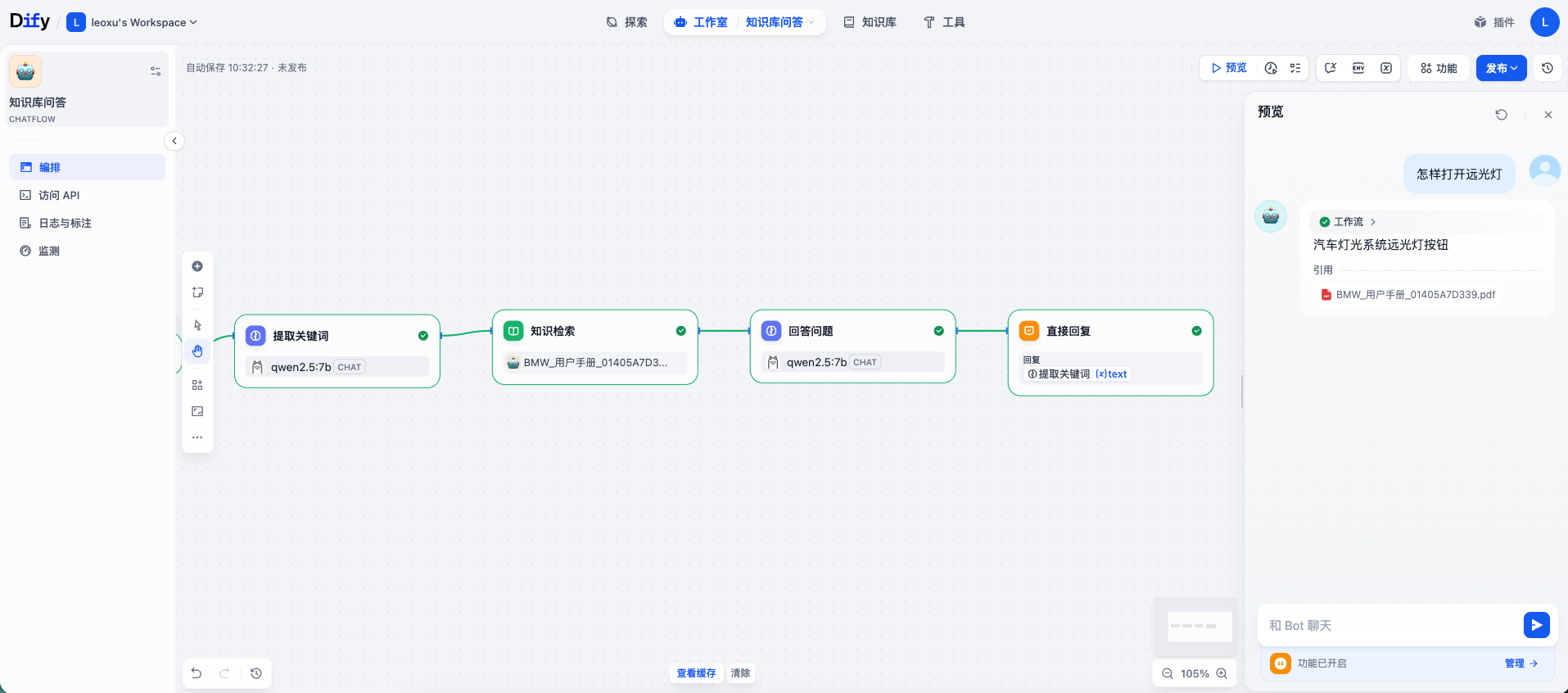
在前面的步骤中,已经实现了一个能在 Dify 网页端流畅对话的“用车顾问”。Dify 最强大的地方在于它遵循 API First 的设计理念。我们在网页上看到的所有功能,都可以通过 API 进行调用。这意味着可以把这个“大脑”接入到任何你想要的地方。接下来,编写一段 Python 代码,实现与智能体的远程对话。
要通过 API 调用 Dify,首先需要拿到通行证。在 Dify 应用编排页面的左侧导航栏,点击 访问 API。
API 密钥 -> 创建密钥。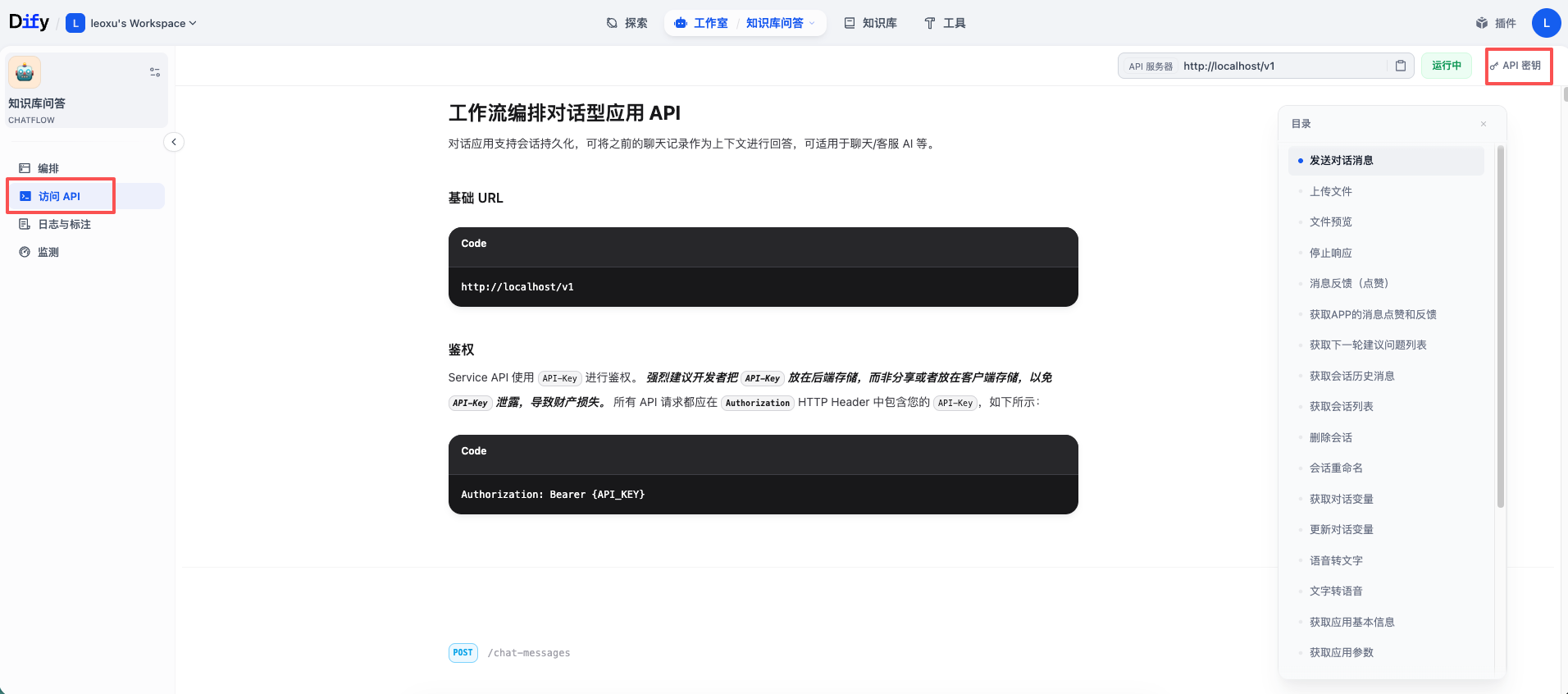
需要使用 Python 的 requests 库来发送 HTTP 请求。如果还没有安装,请在命令行执行 pip install requests。
新建一个文件 car_bot.py,将以下代码复制进去。这段代码使用了阻塞模式 (Blocking),程序会等待 AI 完全生成完答案后,一次性返回结果。
import requests
# ================= 配置区域 =================
# 替换为你的 API 密钥
API_KEY = 'app-pJRiHLHP4UMJ3tGqyYLyAjGb'
运行脚本 python car_bot.py,你将看到 AI 根据手册内容给出的准确回答。
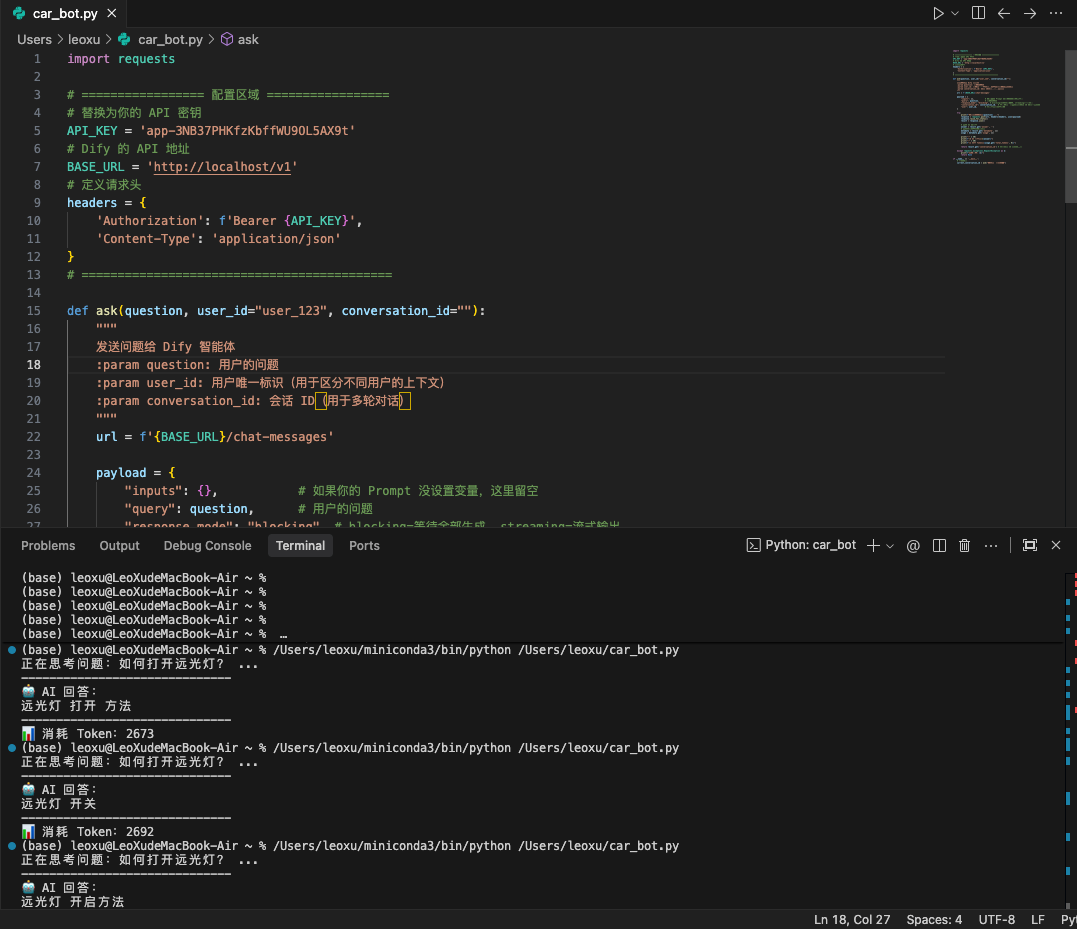
通过这个 Python 脚本,想象力就可以起飞了。将脚本封装成一个 Web 服务,接收微信消息,转发给 Dify,再把答案发回微信,制作一个聊天机器人。也可以结合 Whisper(语音转文字)和 Edge-TTS(文字转语音),给这个智能体加上耳朵和嘴巴...
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。