Azure的AKS是Azure托管的Kubernetes服务。AKS支持多种容器网络模式,可以很好的和Azure的VNET集成。AzureCNI增强版与其他云厂商的Kubernetes服务的容器网络方案相比有一定的优势,主要表现在:部署灵活、节省IP地址资源等。Azure的AKS容器网络实现有多种模式,包括:
Kubenet是最基本的模式,Kubenet是最基本的模式,它使用 bridge 和host-local CNI 插件实现了基本的cbr0。
Kubenet主要有两个主要功能:
如下图中,两个Node,分别各有两个Pod,通过Kubenet创建cbr0,每个Pod通过Kubenet创建的veth pair连接到cbr0上,Node的eth0也挂载到cbr0上。具体Pod见通信流量走向如下:
跨Node的Pod间通信,需要在VNET中创建用户自定义路由(UDR),来实现每Node上Pod的路由。比如下图中,如果Pod1(10.0.0.1)和Pod3(10.0.1.1)进行通信,

首先创建相应的VNET:
|
az network vnet create -g whhk -n vnet01 \ --address-prefixes 10.0.0.0/16 -l eastus az network vnet subnet create -g whhk -n vlan01 \ --vnet-name vnet01 --address-prefixes 10.0.0.0/22 vnet_id=$(az network vnet show -g whhk -n vnet01 -o tsv --query id) vlan_id=$(az network vnet subnet show -n vlan01 -g whhk \ --vnet-name vnet01 -o tsv --query id) |
创建Service Principal并授权:
|
az ad sp create-for-rbac -n whforaks --skip-assignment appid=$(az ad sp list --display-name whforaks -o tsv --query "[0].appId") az role assignment create --assignee $appid --scope $vnet_id --role "Network Contributor" |
创建网络采用Kubenet的AKS:
|
az aks create \ -g whhk \ -n aks01 \ -l eastus \ --node-count 2 \ --network-plugin kubenet \ --service-cidr 172.16.1.0/24 \ --dns-service-ip 172.16.1.10 \ --pod-cidr 10.244.0.0/16 \ --docker-bridge-address 172.17.0.1/16 \ --vnet-subnet-id $vlan_id \ --service-principal $appid \ --client-secret $passwd |
获取AKS管理权限:
|
az aks get-credentials -g whhk -n aks01 $ kubectl get node NAME STATUS ROLES AGE VERSION aks-nodepool1-52243381-vmss000000 Ready agent 4m54s v1.20.9 aks-nodepool1-52243381-vmss000001 Ready agent 5m40s v1.20.9 |
创建一个workload:
|
kubectl create deployment nginx --image nginx kubectl scale deployment nginx --replicas=3 |
登录到一个node上:
|
nodename=$(kubectl get node \ -o jsonpath='{.items[0].metadata.labels.kubernetes\.io\/hostname}') kubectl debug node/$nodename -it \ --image=mcr.microsoft.com/aks/fundamental/base-ubuntu:v0.0.11 |
查看网络配置情况,kubenet默认采用cbr0的bridge,地址分配了10.244.1.0/24的地址段给这个Node的pod使用:
|
cd /host/etc/cni/net.d/ # cat 10-containerd-net.conflist { "cniVersion": "0.3.1", "name": "kubenet", "plugins": [{ "type": "bridge", "bridge": "cbr0", "mtu": 1500, "addIf": "eth0", "isGateway": true, "ipMasq": false, "promiscMode": true, "hairpinMode": false, "ipam": { "type": "host-local", "subnet": "10.244.1.0/24", "routes": [{ "dst": "0.0.0.0/0" }] } }, { "type": "portmap", "capabilities": {"portMappings": true}, "externalSetMarkChain": "KUBE-MARK-MASQ" }] } |
因为新版的AKS都采用containerd作为容器的runtime,我们安装containerd客户端crictl,由于是创建一个container进入的node,所以,要指定endpoint所在的位置/host/run/containerd/containerd.sock:
|
tar vxf crictl-v1.22.0-linux-amd64.tar.gz cp crictl /usr/local/bin #crictl -r unix:///host/run/containerd/containerd.sock ps CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID eb53b4069ba54 81869ce15b0c7 3 minutes ago Running debugger 0 58009a9d2e180 22e1944b0c1a7 81869ce15b0c7 46 minutes ago Running debugger 0 421b2a77c8e3c ade5453416e2f 87a94228f133e About an hour ago Running nginx 0 035488dda252d 0fac789b8c32b 87a94228f133e About an hour ago Running nginx 0 80e82d5d19e65 72bb25828d032 54b145bf08825 About an hour ago Running konnectivity-agent 0 e8d0f563161fb a7c4e81f6250d e83e576296711 About an hour ago Running kube-proxy 0 f97a7109cbbeb 706dceab4bfae efd9c9d9e8376 About an hour ago Running azure-ip-masq-agent 0 dfdb927c75681 |
查看Pod信息:
|
# crictl -r unix:///host/run/containerd/containerd.sock pods POD ID CREATED STATE NAME NAMESPACE ATTEMPT RUNTIME 58009a9d2e180 7 minutes ago Ready node-debugger-aks-nodepool1-52243381-vmss000000-r7cpt default 0 421b2a77c8e3c 50 minutes ago Ready node-debugger-aks-nodepool1-52243381-vmss000000-b9lgn default 0 035488dda252d About an hour ago Ready nginx-6799fc88d8-ltwhl default 0 80e82d5d19e65 About an hour ago Ready nginx-6799fc88d8-mr2q6 default 0 e8d0f563161fb About an hour ago Ready konnectivity-agent-7c8fdfddf4-xngd9 kube-system 0 dfdb927c75681 About an hour ago Ready azure-ip-masq-agent-k5gtp kube-system 0 f97a7109cbbeb About an hour ago Ready kube-proxy-6xznd kube-system 0 |
进入到Pod内,查看IP和Mac地址:
|
# crictl -r unix:///host/run/containerd/containerd.sock exec \ -it ade5453416e2f sh # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 3: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether d6:12:5a:78:49:25 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.244.1.3/24 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::d412:5aff:fe78:4925/64 scope link valid_lft forever preferred_lft forever |
再回到Node里查看bridge的mac表:
|
# brctl show bridge name bridge id STP enabled interfaces cbr0 8000.debc876c458c no vetha11a2630 vethaf749be9 # brctl showmacs cbr0 port no mac addr is local? ageing timer 2 86:a2:71:a1:60:b4 yes 0.00 2 86:a2:71:a1:60:b4 yes 0.00 1 ae:4d:2f:54:9c:07 yes 0.00 1 ae:4d:2f:54:9c:07 yes 0.00 2 d6:12:5a:78:49:25 no 19.94 |
可以看到,pod的mac地址在cbr0的mac转发表里。
|
$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-6799fc88d8-fd5sq 1/1 Running 0 92m 10.244.0.6 aks-xxxx-vmss000001 nginx-6799fc88d8-ltwhl 1/1 Running 0 92m 10.244.1.3 aks-xxxx-vmss000000 nginx-6799fc88d8-mr2q6 1/1 Running 0 93m 10.244.1.2 aks-xxxx-vmss000000 |
在10.244.1.3的pod上ping其他两个pod,都能够ping通:
|
# ping 10.244.1.2 PING 10.244.1.2 (10.244.1.2) 56(84) bytes of data. 64 bytes from 10.244.1.2: icmp_seq=1 ttl=64 time=0.059 ms 64 bytes from 10.244.1.2: icmp_seq=2 ttl=64 time=0.090 ms 64 bytes from 10.244.1.2: icmp_seq=3 ttl=64 time=0.070 ms ^C --- 10.244.1.2 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 55ms rtt min/avg/max/mdev = 0.059/0.073/0.090/0.012 ms # ping 10.244.0.6 PING 10.244.0.6 (10.244.0.6) 56(84) bytes of data. 64 bytes from 10.244.0.6: icmp_seq=1 ttl=62 time=0.983 ms 64 bytes from 10.244.0.6: icmp_seq=2 ttl=62 time=1.02 ms 64 bytes from 10.244.0.6: icmp_seq=3 ttl=62 time=0.985 ms ^C --- 10.244.0.6 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 4ms rtt min/avg/max/mdev = 0.983/0.994/1.016/0.039 ms |
在node上抓包:
|
# tcpdump icmp -i eth0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes 10:45:01.811855 IP 10.244.1.3 > 10.244.0.6: ICMP echo request, id 488, seq 1, length 64 10:45:01.812767 IP 10.244.0.6 > 10.244.1.3: ICMP echo reply, id 488, seq 1, length 64 10:45:02.813014 IP 10.244.1.3 > 10.244.0.6: ICMP echo request, id 488, seq 2, length 64 10:45:02.813963 IP 10.244.0.6 > 10.244.1.3: ICMP echo reply, id 488, seq 2, length 64 10:45:03.814281 IP 10.244.1.3 > 10.244.0.6: ICMP echo request, id 488, seq 3, length 64 10:45:03.815166 IP 10.244.0.6 > 10.244.1.3: ICMP echo reply, id 488, seq 3, length 64 |
只能看到跨节点的包,node内的数据包只经过node内的Bridge,不经过eth0.
查看VNET中的路由:
|
az network route-table list -g mc_whhk_aks01_eastus --query \ "[].{address:routes[].addressPrefix[],nextHop:routes[].nextHopIpAddress[]}" [ { "address": [ "10.244.0.0/24", "10.244.1.0/24" ], "nextHop": [ "10.0.0.5", "10.0.0.4" ] }] |
可以看到指向不同node的Pod地址段。节点外访问Pod IP的路由都是有这些UDR完成的。AKS每创建一个Node,就会生成一条相应的路由。这种方式对UDR的数量有一定要求,扩展性受到一定的限制。
AKS的第二种网络模式是Azure CNI模式。在Azure CNI 1.2.0之前,采用的是Bridge模式,之后采用了Transparent模式。Bridge模式中会存在Kube-DNS的5s延迟问题,而在Transparent模式中得到了解决。这两种模式的逻辑结构如下,可以看出在Transparent模式下,Azure CNI采用的是三层路由的方式:
Bridge模式: Transparent模式:
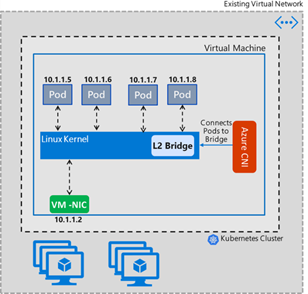
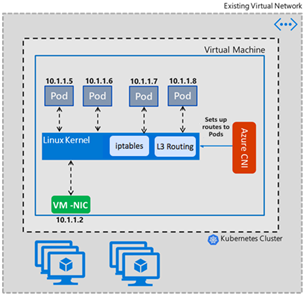
在Azure CNI方案中,Pod和Node都在同一个VNET的Subnet中,Node在创建时,会预先预留Node中Pod所有所需要的地址。比如每个Node支持30个Pod,那每个Node创建时,就在VNET中预留30个IP地址给Pod使用。
Pod的IP地址在VNET中是可见的,所以在VNET中的网络节点可以直接访问Pod,而不需要用户自定义路由(UDR)来帮助实现。
具体如下图:
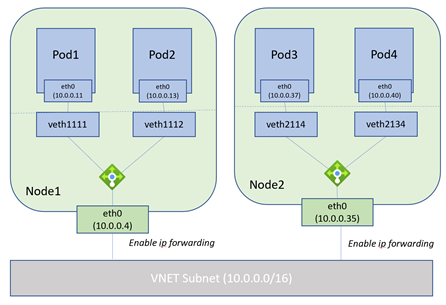
可以看到VM和Pod的地址是在相同网段中的。Azure VNET中SDN的Network Manager会根据Pod的IP地址把流量转发到相应的Node上。
创建VNET:
|
az network vnet create -g aks -n cni-vnet \ --address-prefixes 10.0.0.0/16 -l eastus |
创建Subnet:
|
az network vnet subnet create -g aks -n vlan01 \ --vnet-name cni-vnet --address-prefixes 10.0.0.0/20 |
获取VNET和Subnet的值:
|
vnet_id=$(az network vnet show -g aks -n cni-vnet -o tsv --query id) vlan_id=$(az network vnet subnet show -n vlan01 -g aks \ --vnet-name cni-vnet -o tsv --query id) |
创建AKS:
|
az aks create \ -g aks -n aks-cni -l eastus \ --network-plugin azure \ --vnet-subnet-id $vlan_id \ --docker-bridge-address 172.17.0.1/16 \ --dns-service-ip 10.2.0.10 \ --service-cidr 10.2.0.0/24 \ --node-count 2 |
获取AKS管理密钥:
|
az aks get-credentials -g aks -n aks-cni |
查看Node信息:
|
$ kubectl get node NAME STATUS ROLES AGE VERSION aks-nodepool1-14830056-vmss000000 Ready agent 3m21s v1.20.9 aks-nodepool1-14830056-vmss000001 Ready agent 3m51s v1.20.9 |
创建Deployment:
|
kubectl create deployment nginx --image nginx kubectl scale deployment nginx --replicas=10 |
登录Node:
|
nodename=$(kubectl get node \ -o jsonpath='{.items[0].metadata.labels.kubernetes\.io\/hostname}') kubectl debug node/$nodename -it \ --image=mcr.microsoft.com/aks/fundamental/base-ubuntu:v0.0.11 |
查看CNI的配置信息:
|
$ cd /host/etc/cni/net.d/ $ cat 10-azure.conflist { "cniVersion":"0.3.0", "name":"azure", "plugins":[ { "type":"azure-vnet", "mode":"transparent", "ipsToRouteViaHost":["169.254.20.10"], "ipam":{ "type":"azure-vnet-ipam" } }, { "type":"portmap", "capabilities":{ "portMappings":true }, "snat":true } ] } |
可以看到地址管理不再是host-local,而是有Azure-vnet-ipam来管理。CNI的类型也给成了Azure-vnet。
查看Azure-vnet-ipam的日志,可以看到Node在启动时,从VNET中预留的地址。Kubenet默认时110个pod每Node,Azure CNI默认是30个Pod每Node。在日志中我们看到了预留的30个地址。由于Vnet的Subnet是新创建的,所以预留的地址是连续的:
|
$ more /host/var/log/azure-vnet-ipam.log 2021/11/04 09:54:50 [18965] [ipam] Pool request completed with pool:&{as:0xc0002bf740 Id:10.0.0.0/20 IfName: eth0 Subnet:{IP:10.0.0.0 Mask:fffff000} Gateway:10.0.0.1 Addresses:map[ 10.0.0.10:0xc000309180 10.0.0.11:0xc0003091c0 10.0.0.12:0xc000309200 10.0.0.13:0xc000309240 10.0.0.14:0xc000309280 10.0.0.15:0xc0003092c0 10.0.0.16:0xc000309300 10.0.0.17:0xc000309340 10.0.0.18:0xc000309380 10.0.0.19:0xc0003093c0 10.0.0.20:0xc000309400 10.0.0.21:0xc000309440 10.0.0.22:0xc000309480 10.0.0.23:0xc0003094c0 10.0.0.24:0xc000309500 10.0.0.25:0xc000309540 10.0.0.26:0xc000309580 10.0.0.27:0xc0003095c0 10.0.0.28:0xc000309600 10.0.0.29:0xc000309640 10.0.0.30:0xc000309680 10.0.0.31:0xc0003096c0 10.0.0.32:0xc000309700 10.0.0.33:0xc000309740 10.0.0.34:0xc000309780 10.0.0.5:0xc000309040 10.0.0.6:0xc000309080 10.0.0.7:0xc0003090c0 10.0.0.8:0xc000309100 10.0.0.9:0xc000309140] addrsByID:map[] IsIPv6:false Priority:0 RefCount:1 epoch:0} err:<nil>. |
查看Pod的IP地址,在vmss000000上的Pod,IP地址在预留的地址范围内:

Ping VNET中的其他Node和Pod,可以看到在没有用户自定义路由的情况下,网络都是通的:
|
root@hello-675bdb4bf9-9qxc7:/app# ifconfig eth0 | grep inet | grep -v inet6 inet 10.0.0.11 netmask 255.255.240.0 broadcast 0.0.0.0 root@hello-675bdb4bf9-9qxc7:/app# ping 10.0.0.4 PING 10.0.0.4 (10.0.0.4) 56(84) bytes of data. 64 bytes from 10.0.0.4: icmp_seq=1 ttl=64 time=0.040 ms 64 bytes from 10.0.0.4: icmp_seq=2 ttl=64 time=0.081 ms 64 bytes from 10.0.0.4: icmp_seq=3 ttl=64 time=0.054 ms ^C --- 10.0.0.4 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 48ms rtt min/avg/max/mdev = 0.040/0.058/0.081/0.018 ms root@hello-675bdb4bf9-9qxc7:/app# ping 10.0.0.35 PING 10.0.0.35 (10.0.0.35) 56(84) bytes of data. 64 bytes from 10.0.0.35: icmp_seq=1 ttl=63 time=1.05 ms 64 bytes from 10.0.0.35: icmp_seq=2 ttl=63 time=1.13 ms 64 bytes from 10.0.0.35: icmp_seq=3 ttl=63 time=1.13 ms ^C --- 10.0.0.35 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 4ms rtt min/avg/max/mdev = 1.051/1.100/1.126/0.051 ms root@hello-675bdb4bf9-9qxc7:/app# ping 10.0.0.37 PING 10.0.0.37 (10.0.0.37) 56(84) bytes of data. 64 bytes from 10.0.0.37: icmp_seq=1 ttl=62 time=1.08 ms 64 bytes from 10.0.0.37: icmp_seq=2 ttl=62 time=1.11 ms ^C --- 10.0.0.37 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 2ms rtt min/avg/max/mdev = 1.077/1.095/1.113/0.018 ms |
Azure CNI虽然解决了Pod地址采用VNET地址的问题,使得Pod可以和VNET中的网络节点进行通信。但Azure CNI有以下一些问题:
为了解决上面提到的几个问题,AKS推出了增强版的Azure CNI。
增强版Azure CNI中,网卡和Pod的IP地址分别属于不同的Subnet,同时Node创建时不会预留大量的IP地址,每创建Pod时再获取相应的Pod IP地址:
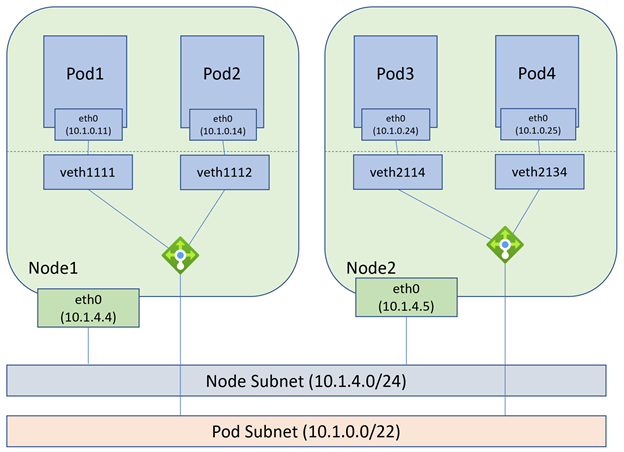
目前Pod Subnet必须和Node的Subnet在一个VNET中,将来可以位于不同的VNET中。
Azure的Host Network采用VFP的方式实现主机的虚拟交换,增强版的Azure CNI模式下,VFP把同一个主机的Node和Pod作为两个不同的Network Container来进行处理,等于同一个VM上有两组不同的网络规则,如下图:
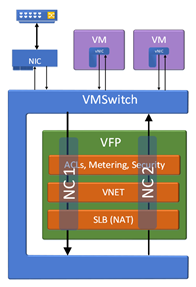
创建VNET,以及Node Subnet和Pod Subnet:
|
az group create -n cni -l eastus az network vnet create -g cni -n whkubenet \ --address-prefixes 10.1.0.0/16 -l eastus az network vnet subnet create -g cni -n podvlan \ --vnet-name whkubenet --address-prefixes 10.1.0.0/22 az network vnet subnet create -g cni -n nodevlan \ --vnet-name whkubenet --address-prefixes 10.1.4.0/24 vnet_id=$(az network vnet show -g cni -n whkubenet -o tsv --query id) podvlan=$(az network vnet subnet show -n podvlan -g cni \ --vnet-name whkubenet -o tsv --query id) nodevlan=$(az network vnet subnet show -n nodevlan -g cni \ --vnet-name whkubenet -o tsv --query id) |
目前增强的Azure CNI是Preview阶段,需要安装Preview的扩展插件:
|
az extension add --name aks-preview az extension update --name aks-preview az feature register --namespace "Microsoft.ContainerService" \ --name "PodSubnetPreview" az feature list -o table \ --query "[?contains(name, 'Microsoft.ContainerService/PodSubnetPreview')].{Name:name,State:properties.state}" |
创建AKS集群:
|
az aks create -n akscni -g cni -l eastus \ --max-pods 250 \ --node-count 2 \ --network-plugin azure \ --vnet-subnet-id $nodevlan \ --pod-subnet-id $podvlan |
获取管理权限:
|
az aks get-credentials -n akscni -g cni |
创建workload:
|
kubectl create deployment nginx --image nginx kubectl scale deployment nginx --replicas=5 |
查看Pod IP地址分配,Pod分配在两个Node上,地址段是预先定义的Pod地址段,与Node地址段不相同。


登录Node,
|
nodename=$(kubectl get node \ -o jsonpath='{.items[0].metadata.labels.kubernetes\.io\/hostname}') kubectl debug node/$nodename -it \ --image=mcr.microsoft.com/aks/fundamental/base-ubuntu:v0.0.11 |
查看CNI信息,可以看到和普通的Azure CNI配置相同:
|
# cat 10-azure.conflist { "cniVersion":"0.3.0", "name":"azure", "plugins":[ { "type":"azure-vnet", "mode":"transparent", "ipsToRouteViaHost":["169.254.20.10"], "ipam":{ "type":"azure-cns" } }, { "type":"portmap", "capabilities":{ "portMappings":true }, "snat":true } ] } |
查看/host/var/log/zure-vnet.log,可以看到Node给Pod分配IP地址、添加路由等日志。
在Node中查看路由信息,可以看到每个Pod都有相应的静态路由:

增强版的CNI中,可以每个Node Pool采用不同的Pod Subnet,如下图:

新Node Pool的Node地址仍然在Node的Subnet中,但通过创建新的Pod地址段,新建Node Pool中的Pod,会采用新的地址段。
|
az network vnet subnet create -g cni -n podvlan2 \ --vnet-name whkubenet --address-prefixes 10.1.8.0/22 podvlan2=$(az network vnet subnet show -n podvlan2 -g cni \ --vnet-name whkubenet -o tsv --query id) |
|
az aks nodepool add --cluster-name akscni -g cni -n newnodepool \ --max-pods 250 \ --node-count 2 \ --vnet-subnet-id $nodevlan \ --pod-subnet-id $podvlan2 \ --no-wait |
Node IP地址:

Pod IP地址:

可以看到,新的Node Pool中的Pod采用了新的地址段。
通过这种方法,可以非常方便的规划、扩展计算资源池,解决Pod地址不够用的问题。
通过创建安全规则,允许第一个Node Pool中的Pod访问Node,禁止第二个Node Pool中的Pod访问Node。
创建NSG规则:
|
az network nsg create -n aksnsg -g cni -l eastus az network nsg rule create -g cni \ --nsg-name aksnsg \ --name icmp_permit \ --priority 200 \ --source-address-prefixes '10.1.0.0/22' \ --destination-address-prefixes '10.1.4.0/24' \ --access Allow \ --protocol ICMP \ --direction Inbound az network nsg rule create -g cni \ --nsg-name aksnsg \ --name icmp_deny \ --priority 300 \ --source-address-prefixes '10.1.8.0/22' \ --destination-address-prefixes '10.1.4.0/24' \ --access Deny \ --protocol ICMP \ --direction Inbound az network vnet subnet update -n nodevlan \ --vnet-name whkubenet -g cni \ --network-security-group aksnsg |
登录第一个Node Pool的Pod:

地址段是10.1.0.0/22地址段的Pod,是第一个Node Pool中的Pod。

可以Ping通Node地址段中的VM。
登录第二个Node Pool的Pod:

地址段是10.1.8.0/22地址段的Pod,是第二个Node Pool中的Pod。

Ping Node地址段的VM,网络不通,被NSG规则Deny。
由于Node Pool的Pod采用不同的Subnet,可以非常方便的对Workload进行一些规则的定义,实现精选的安全设计和部署。
Azure的AKS有多种容器网络的实现方式,包括:
Kubenet:Kubenet的方式,实现起来简单,PodIP地址在创建AKS时指定。但每创建一个Node就需要增加一条UDR路由,使得扩展性受限
Azure CNI:Azure CNI非常好的解决了Pod地址暴露在VNET的问题。VNET中的网络节点可以非常方便的和Pod进行通信。但这种方案PodIP地址消耗VNET地址段相对较多。在每个Node创建时,都要预留相应的IP地址段在Node中。同时不能追加Pod地址段,使得扩展性也受到一定的限制
Azure CNI增强版:Azure CNI增强版非常好的解决了上面两种方法的问题,通过分离Node和Pod的Subnet,在新的NodePool中添加新的PodSubnet的方式,方便的实现了AKS网络层面的扩展需求,同时可以节约大量的IP地址段。
AKS的用户,可以根据业务的实际需求,可以选择不同的方式进行部署。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。