2025-03-21 11:03 abce 阅读(106) 评论() 收藏 举报
本文将介绍读取和应用 oplog 条目的并行机制,从单个复制buffer到两个复制buffer的转变,以及新引入(和已废弃)的服务器状态度量。
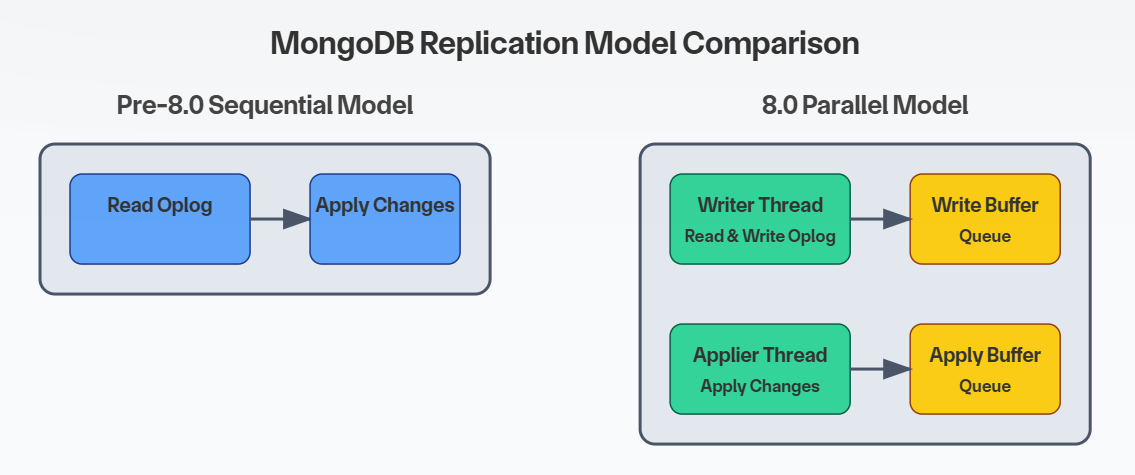
以前的版本中,复制主要遵循顺序的过程:
1.读取oplog的条目:副本会从主节点读取oplog条目,并写入到本地的buffer中。
2.应用oplog条目:副本将这些oplog条目应用到本地数据库。
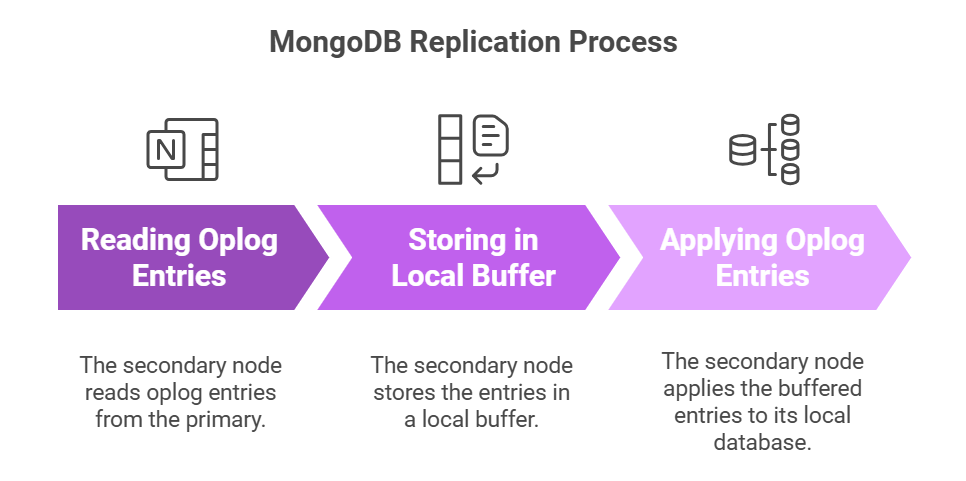
这种顺序的方法虽然有效,但在工作负荷较高的情况下往往会出现瓶颈,因为副本只能以线性方式处理条目。
MongoDB 8.0 引入并行方法,改变了处理方式:
·写线程: 从主节点读取新的 oplog 条目,并将其写入本地 oplog。
·应用线程: 异步将本地oplog中的变更应用到副本的数据库。
因为写和应用两个活动变成了并行的,mongodb 8.0 就将replication buffer从单个转变成了两个:
1.Write Buffer: 接收来自主节点的oplog
2.Apply Buffer: 在应用到本地数据库之前,临时存放来自主节点的oplog
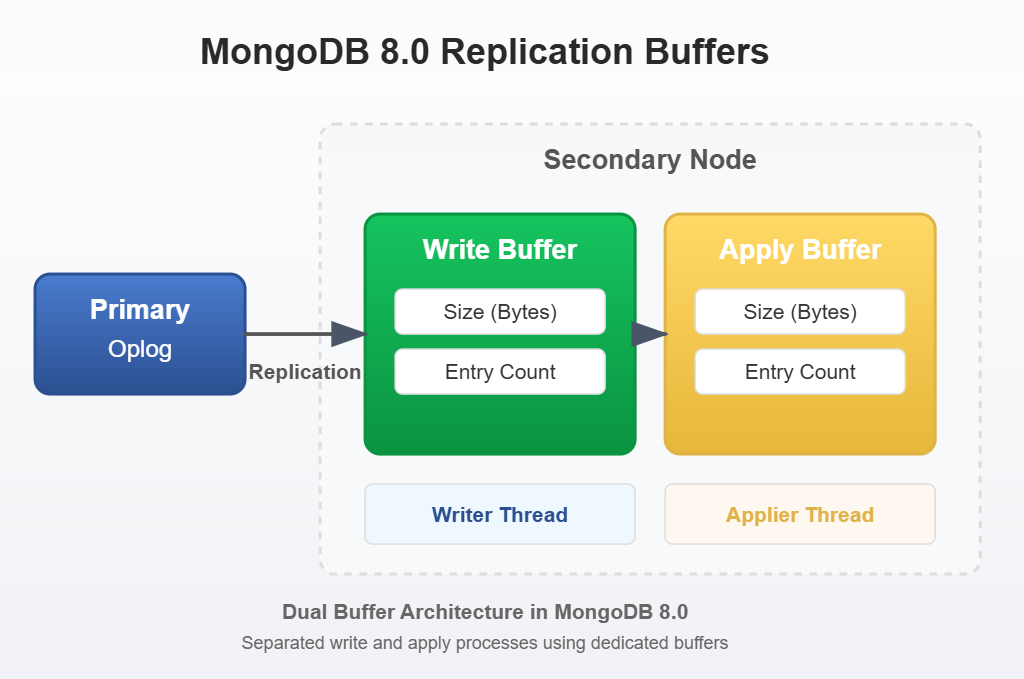
这一架构变化意味着任何引用replication buffer的指标或命令现在都需要考虑两个独立的缓冲区,每个缓冲区都有自己的大小、数量和吞吐量指标。
为了反映这些内部变化,MongoDB 8.0 在 serverStatus 中引入了新指标,并废弃了旧指标。让我们来看看都有哪些变化:
|
种类 |
废弃的指标 |
新指标(mongodb 8.0) |
|
常规复制指标 |
·metrics.repl.buffer.count ·metrics.repl.buffer.maxSizeBytes ·metrics.repl.buffer.sizeBytes |
- |
|
apply buffer 指标 |
- |
·metrics.repl.buffer.apply ·metrics.repl.buffer.apply.count ·metrics.repl.buffer.apply.maxCount ·metrics.repl.buffer.apply.maxSizeBytes ·metrics.repl.buffer.apply.sizeBytes |
|
write buffer指标 |
- |
·metrics.repl.buffer.write ·metrics.repl.buffer.write.count ·metrics.repl.buffer.write.maxSizeBytes ·metrics.repl.buffer.write.sizeBytes |
|
写相关指标 |
- |
·metrics.repl.write ·metrics.repl.write.batchSize ·metrics.repl.write.batches ·metrics.repl.write.batches.num ·metrics.repl.write.batches.totalMillis |

有了这些新指标,可以更密切地跟踪 oplog 条目的生命周期。例如,可以看到有多少条目正在等待应用,有多少正在排队等待写入。还可以观察写入的批大小和时间,从而更深入地了解复制效率。
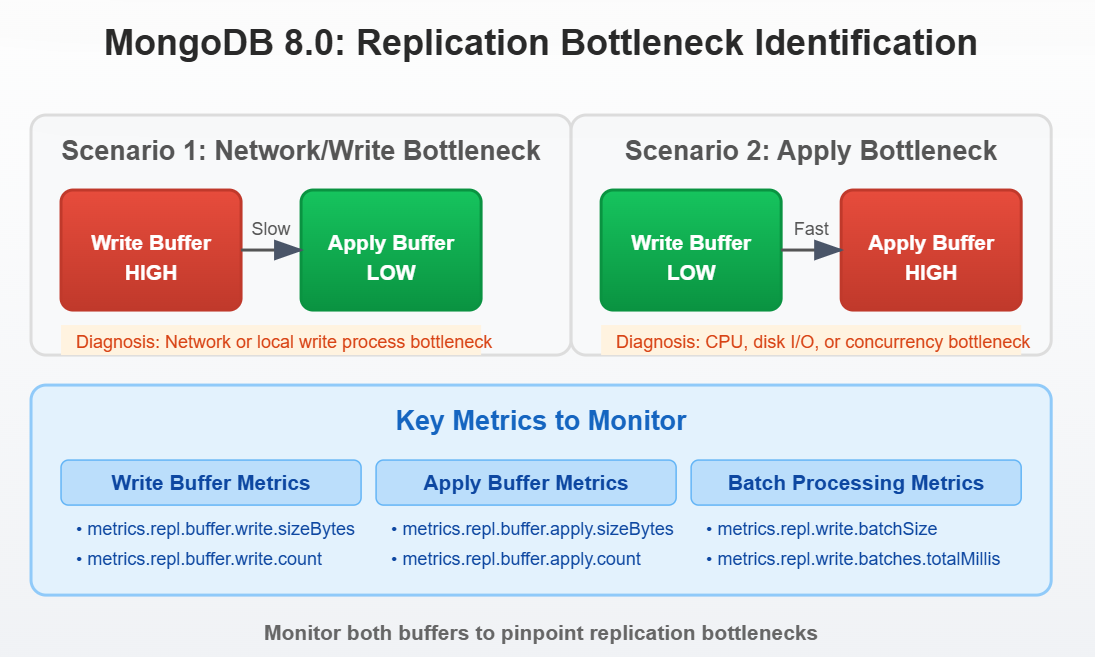
查看 metrics.repl.buffer.write.sizeBytes 和 metrics.repl.buffer.apply.sizeBytes 了解数据可能堆积的位置:
·如果写缓冲区指标稳定增长,而应用缓冲区却很小,那么瓶颈可能是网络或本地写进程。
·如果应用缓冲区一直很大,则表明副本在应用 oplog 条目方面延迟,这可能是 CPU 限制、磁盘 I/O 或并发设置造成的。
使用 metrics.repl.write.batchSize 和 metrics.repl.write.batches.totalMillis 衡量副本节点处理每个批次的效率:
· batchSize: 批大小持续较大可能会提高整体效率,但可能会暂时增加资源使用量。
· batchches.totalMillis:总时间过高可能表明系统写入或应用某些批次的时间过长。请考虑扩展资源或评估并发设置。
副本延迟仍然是一个需要关注的重要指标。虽然没有直接反映在这些新指标中,但是apply buffer 大可能是副本要开始延迟的先行指标。结合 apply.sizeBytes 和 write.sizeBytes 监控复制延迟,可以让你全面了解副本与主节点保持同步的速度。
1.更新监控仪表盘
2.调整警报阈值
根据 metrics.repl.buffer.count 触发的警报需要重新校准。可能需要对应用缓冲区和写缓冲区发出不同的警报,而不是单一的阈值。
3.向团队传达变更信息
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。