Version: 5.4.1
JSR是Java Specification Requests的缩写,意思是Java规范提案.是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求.任何人或组织都可以向JCP提交JSR,以向Java平台增添新的API和服务.JSR已成为Java界的一个重要标准.
JSR223定义了可集成在Java平台上运行的一系列脚本语言.比如Groovy,JavaScript等.
JSR223 采样器允许脚本用于样本执行或一些创建/更新变量必须的计算。
当采样器运行时,如果你不需要生成样本结果,调用以下方法:
SampleResult.setIgnore();
这个调用会产生以下影响:
JSR223 测试元素有一个特性(编译),它可以显著提升性能。要从这个特性中获取好处:
使用脚本文件代替内嵌它们。这将使 JMeter 编译并缓存它们,如果这个特性适用于脚本引擎(ScriptEngine)。
或使用脚本文本并检查Cache compiled script if available(缓存编译过的脚本如果可用)属性。
当使用这个特性时,确保你的脚本代码没有使用 JMeter 变量或者 JMeter 函数调用,因为缓存只会缓存第一次替换。使用脚本参数代替。
要从缓存和编译中获得好处,使用的脚本语言引擎必须实现 JSR 223 编译接口(Groovy 是其中之一,beanshell 和 javascript 不是)
当使用 Groovy 做为脚本语言并且不检查Cache compiled script if available(推荐使用缓存),你应该设置 JVM 属性 -Dgroovy.use.calssvalue=true 因为 Groovy 2.4.6 版本内存泄漏,查看:
缓存大小通过 JMeter 属性控制(jmeter.properties):
jsr223.compiled_scripts_cache_size=100
不同于 BeanShell 采样器,解释器不在调用间保存。
JSR223 测试元素使用脚本文件或脚本文本并且选中 Cache compiled script if available(缓存编译过的脚本如果可用)并编译,如果脚本引擎支持这个特性,这将极大的提升性能。
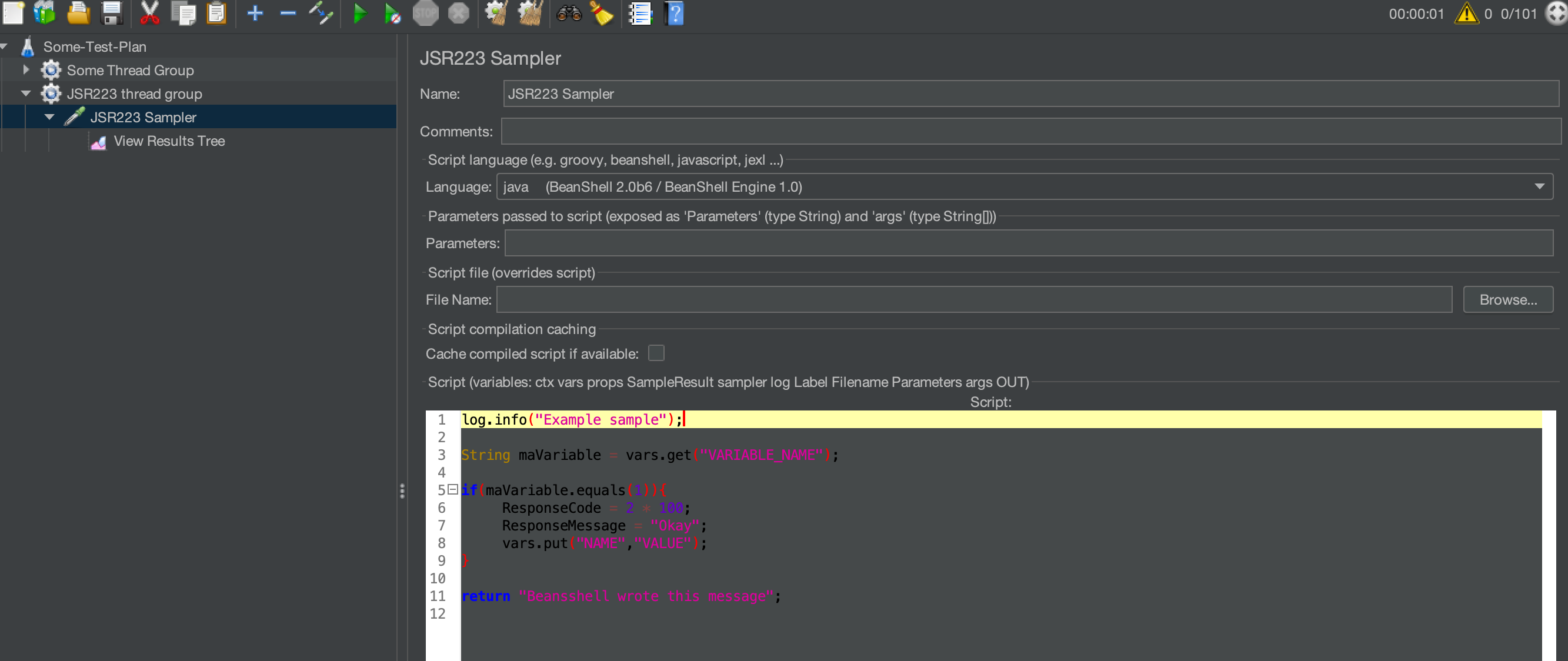
在将脚本字段传递给解释器之前,JMeter 会处理函数和变量引用,所以引用只会解释一次。脚本文件中变量和函数引用将一字不差的传到解释器,它很可能导致语法错误。为了使用运行时变量,请使用合适的属性方法,例如:
props.get("START.HMS");
props.put("PROP1","1234");
| 参数 | ||
|---|---|---|
| 属性 | 描述 | 必填 |
如果支持脚本文件,那么优先使用脚本文件,否则使用脚本。
调用脚本前,一些变量会装配。注意有 JSR223 变量 - 例如:它们可以直接用于脚本。
vars.get("VAR1");
vars.put("VAR2","value");
vars.remove("VAR3");
vars.putObject("OBJ1",new Object());
props.get("START.HMS");
props.put("PROP1","1234");
样本结果 响应数据设置来自脚本的返回结果。如果脚本返回 null ,它可以,通过使用方法 SampleResult.setResponseData(data) 直接设置响应,返回数据类型要么是 String 要么是 byte 数组。返回数据类型默认“text”,但是可以通过方法SampleResult.setDataType(SampleResult.BINARY)设置二进制。
样本结果变量给予脚本所有字段和方法的访问权。例如,脚本有权限访问方法setStopThread(boolean) 和 setStopTest(boolean)。
不同于 BeanShell 采样器, JSR223 采样器不设置 ResponseCode,ReponseMessage 并且样本状态借助于脚本变量。当前修改这些数据唯一的办法是通过样本结果方法:
除了硬件性能,测试计划(Test Plan)设计也同样会影响 JMeter 运行有效线程数量。线程数量还将依赖你的服务速度(更快的服务器使 JMeter 工作更快,因为服务器响应更快)。与任何负载测试(Load Testing)工具一样,如果不恰当的设置线程数量,你将面临“协调遗漏(Coordinated Omission)”问题,它会给你错误或不精确的结果。如果你需要大规模负载测试,考虑在多个机器上使用分布式模式(或者不用)运行多个 CLI JMeter 实例。当使用分布式模式时,结果文件在控制器节点(Controller node)中组合,如果使用多个自主实例,样本结果可以组合起来以供后续分析。为了测试 JMeter 如何在给定的平台上执行,可以使用 JavaTest 采样器。它不需要任何网络访问,因此可以对最大可达吞吐量给出一些头绪。
JMeter 有延迟线程创建的选择,直到线程开始采样。例如:在任何线程组延迟和线程自身启动(ramp-up)时间。这将允许对于一个很大的总线程数量,具有不同时激活太多的能力。
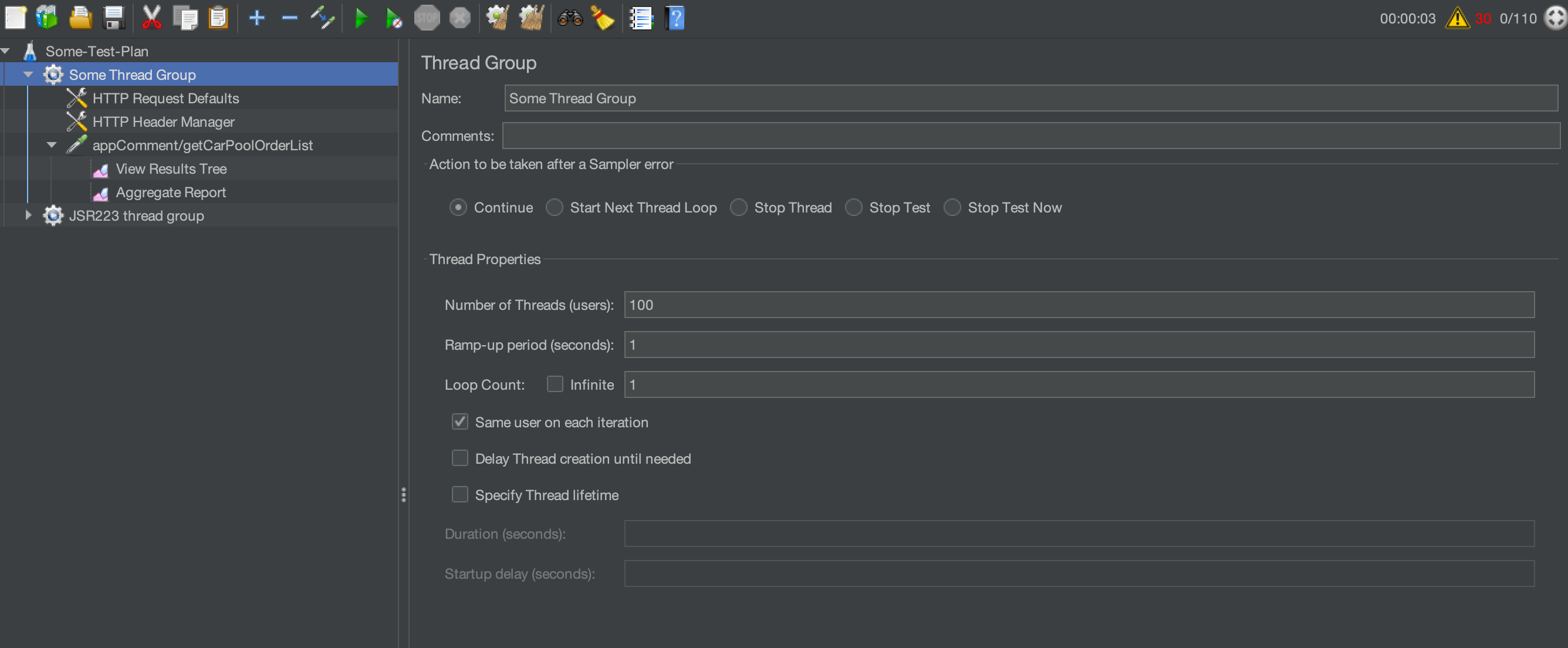
所以没有一个理论能直接得到最大线程数量。
聚合报告在你的测试中为每个不同命名的请求在表格中创建一行。它为每个请求汇总返回信息并提供请求次数、最短时间(同一个样本,ms)、最长时间(同一个样本,ms)、平均时间(结果集中的平均时间,ms)、错误率(请求错误比例)、近似吞吐率(请求/秒)和每秒 KB 吞吐量。一旦完成测试,吞吐量是整个测试期间的真实吞吐量。
吞吐量是从采样器目标的角度计算的(例如:在 HTTP 样本情况下的远程服务器)。JMeter 把生成请求的时间算入总时间。如果其它采样器和计时器在同一个线程中,他们将会增加总时间,并因此减少吞吐量。所以两个完全相同不同名字的采样器相对两个有相同名字的采样器只有一半的吞吐量。要从聚合报告中获取最佳结果,选择正确的采样器名字很重要。
计算中位数和 90% Line(第90百分位)值需要额外的内存。JMeter 现在通过相同的消耗时间联合样本,到目前为止,它使用的内存更少。然而,对于超过几秒钟的样本,可能只有少数样本有相同的时间,这种情况下需要消耗更多的内存。注意,之后您可以使用此侦听器重新加载CSV或XML结果文件,这是避免对性能造成影响的推荐方法。
从 JMeter 2.12 开始,你可以配置 3 个你要计算的百分比值,可以通过设置属性完成:
- aggregate_rpt_pct1:默认 第 90 区间
- aggregate_rpt_pct2:默认 第 95 区间
- aggregate_rpt_pct3:默认 第 99 区间
时间以毫秒为单位。
| Label | # Samples | Average | Median | 90% Line | 95% Line | 99% Line | Min | Max | Error % | Throughput | Received KB/sec | Sent KB/sec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
中位数 是一个把样本分为两等份的数字。一半样本小于中位数,另一半比中位数大。【有的样本可能等于中位数。】这是一个标准的统计学测量。中位数和第 50 百分位是相同的。
90% Line 第 90 百分位是低于 90% 样本的值。剩余的样本至少和这个值一样长。这个一个标准的统计学测量。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。