One of the earliest realizations we made at PlanetScale is that the world of databases had been practically untouched by DevOps practices. The benefits of DevOps are numerous, including faster product delivery and continuous integration, so why wouldn’t we want this for our database?
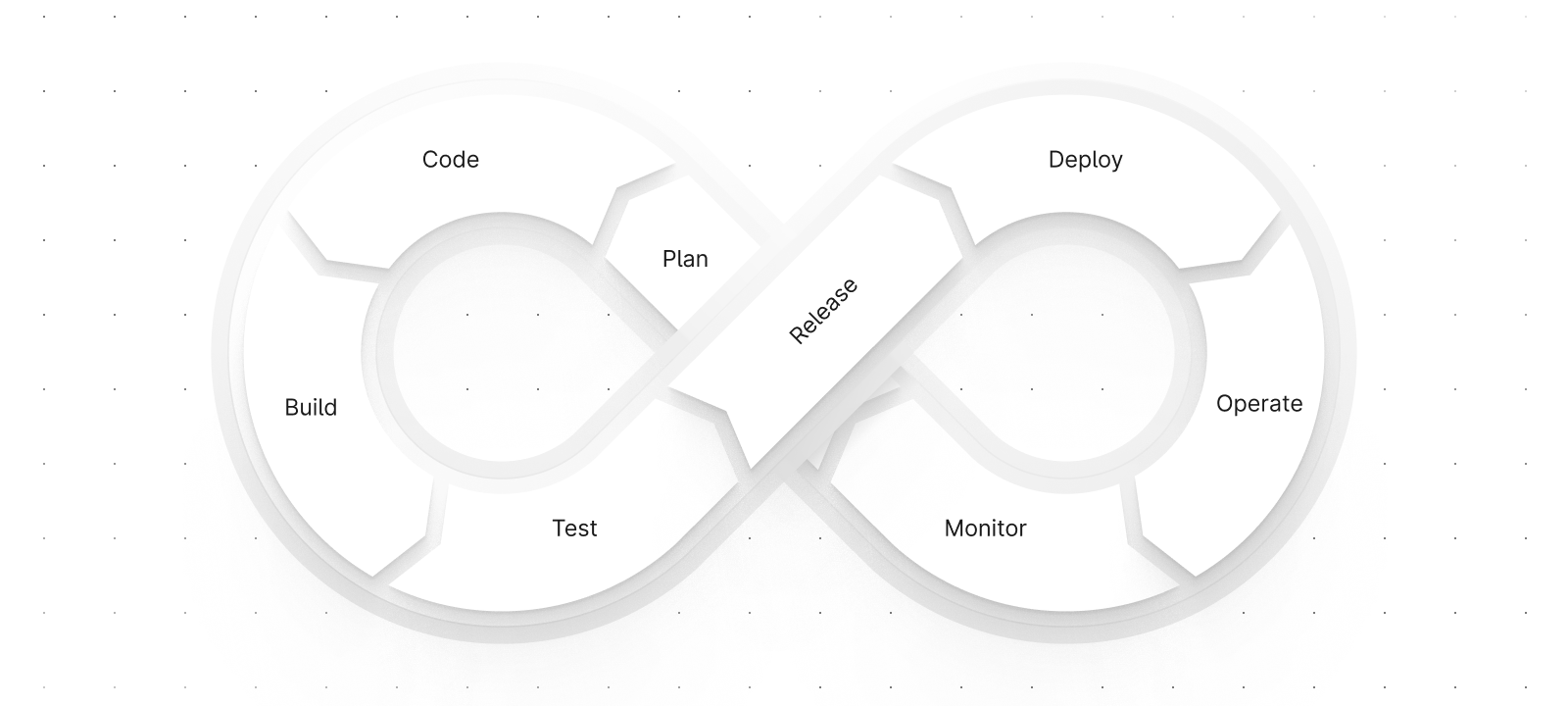
When you see a description of DevOps, it is usually accompanied by the cycle shown in the above graphic. However, it mostly only applies to stateless workloads.
Building out a DevOps toolchain allows you to write code, build, test, deploy, and monitor with tools like GitHub, CircleCI, Kubernetes, and Datadog. Over the last decade, these tools and many like them have become ubiquitous within the space, but databases are nowhere to be seen.
Until PlanetScale, the database has existed outside of the DevOps cycle. It has existed as an amorphous blob of state that engineers and operators have to tip toe around. Nobody has thought to ask, why can’t the database be a nimble and additive part of the software development process?
Continuous Deployment
A critical part of DevOps is being able to continually deploy code. This not only enables your business to move quickly and iterate, it means your local development isn’t far behind production. Instead of shipping stamped versions of software, you are always deploying. Continually deploying code is largely a solved problem, however, any features that have more depth than UI changes will likely require schema changes at the database level.
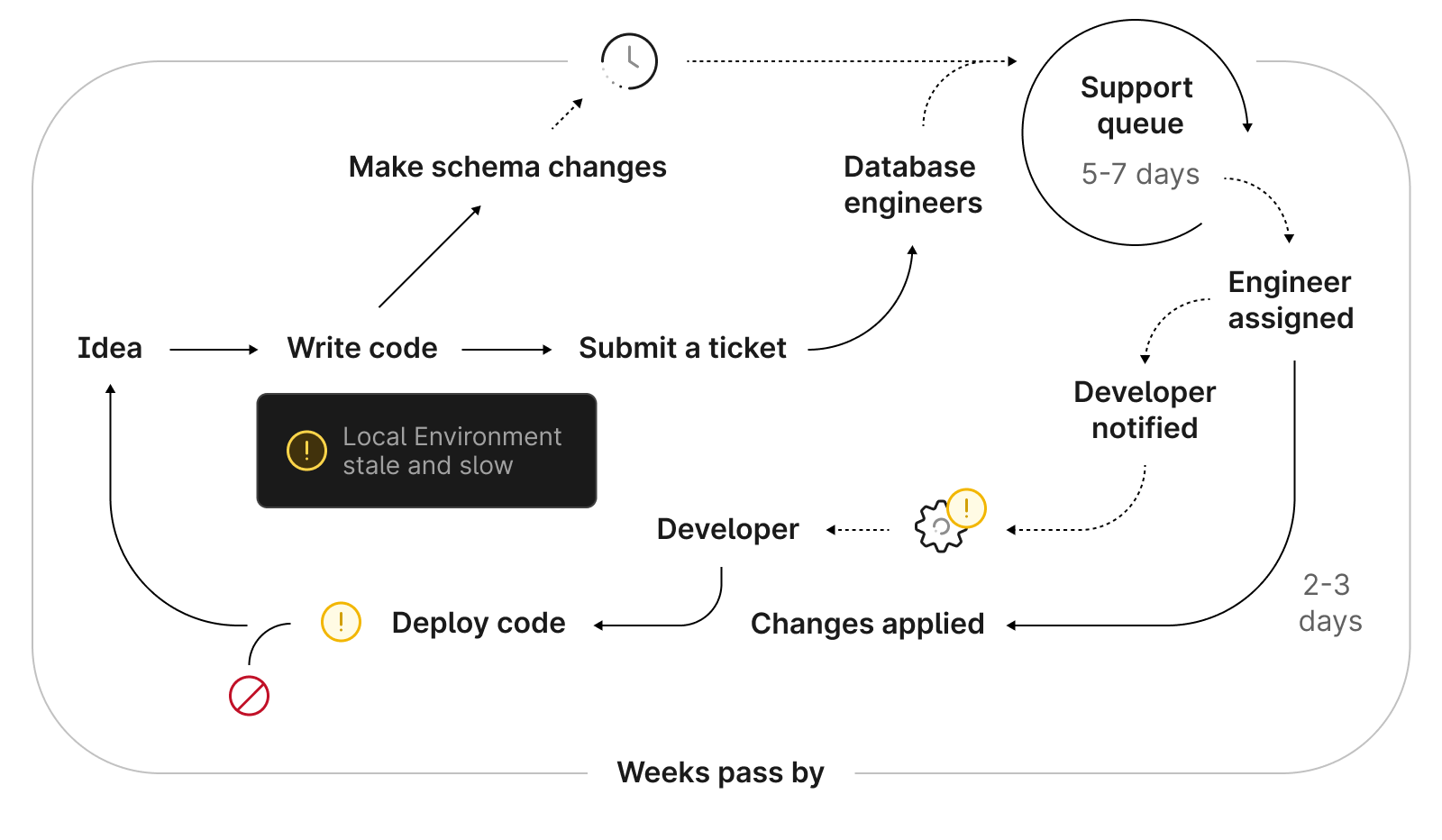
With the current state of legacy databases, engineers are left to manually apply database operations, such as schema changes, out of band of the typical CI/CD process. In more complex or higher scale environments, engineers may even need to open a ticket for a DBA team to apply schema changes in service of avoiding downtime or data loss. This can add weeks to a process that should be fast.
In contrast to the DevOps cycle above, the schema change process looks like this:
How PlanetScale enables DevOps
We set about to build something totally new: A database that can be natively part of the DevOps process. Database changes should be deployed and contain the semantics we’ve become used to in code deployments: automation, safeguards, and rollbacks.
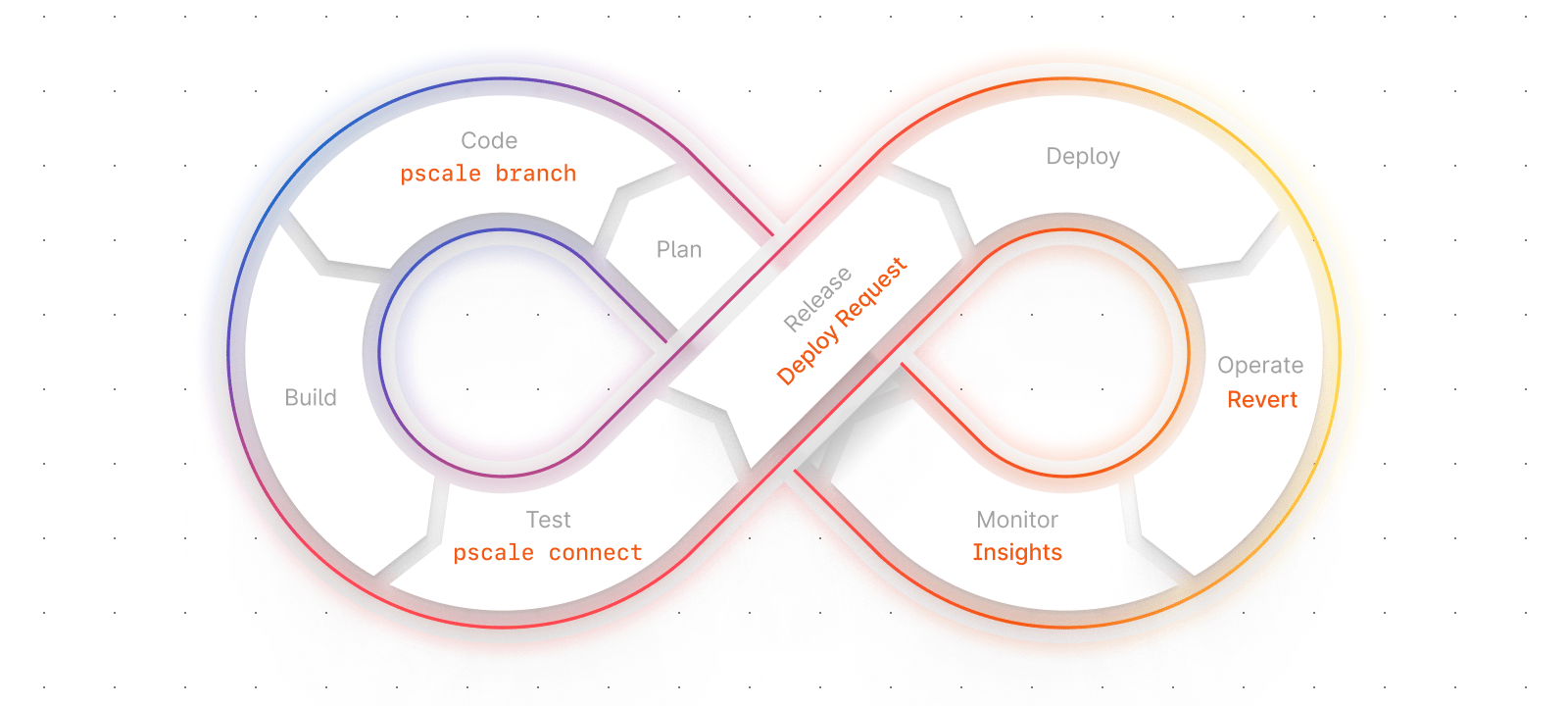
PlanetScale development branches
At the beginning of the feature development process, a developer will normally create a git branch to work against. With PlanetScale, you can also create a database branch to pair with your git branch and act as your development environment. PlanetScale branches are essentially isolated copies of your database that developers can create to test schema changes before deploying to production. This ensures that developers are building against a production-like environment without risk. Another benefit of database branches is that they are cloud-hosted, meaning engineers can share the environment for collaboration or previews.
Next in the process is CI, PlanetScale also has a role to play here. Our CLI means you can automate the task of creating branches that can serve as an isolated testing environment. Schema changes can be applied and tested on real data without risk to production.
Deploy requests
When you are ready to deploy, you can use PlanetScale Deploy Requests to safely put your schema changes into production. Deploy requests allow you to comment on suggested changes, as well as require approval and sign off. Once everything is good to go, your schema changes will roll into production online and without locking. This can be automated as part of your CD process without any manual steps. If your deploy causes errors, you can instantly roll back your database deploy without data loss, and the old version of the schema will be reinstated.
Query monitoring
The final critical part of the DevOps cycle is monitoring. PlanetScale Insights gives you the ability to monitor queries in real time. You also get an interactive graph with an overlay showing when deploys have happened contrasted against your performance data. This allows you to gain insight and continually improve your application’s performance.
There we have it, the principles of the DevOps lifecycle applied to an ACID compliant relational database.