If you’ve ever had a large number of commands you need to run against a MySQL database, having to manually type them into the client of your choice can be a bit of a pain. Luckily, using the PlanetScale CLI, you can easily batch commands to your PlanetScale database using script files on your local dev computer!
In this guide, I’ll show you how to create an empty database and populate it with data using a sql script file. Before you follow along, please make sure you have the following:
You’ll also need to have a script available to run if you don’t have one yet. I’ll be using the following script, which is a snippet from the go-bookings-api sample repository:
CREATE TABLE hotels(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
address VARCHAR(50) NOT NULL,
stars FLOAT(2) UNSIGNED
);
INSERT INTO hotels (name, address, stars) VALUES
('Hotel California', '1967 Can Never Leave Ln, San Francisco CA, 94016', 7.6),
('The Galt House', '140 N Fourth St, Louisville, KY 40202', 8.0);
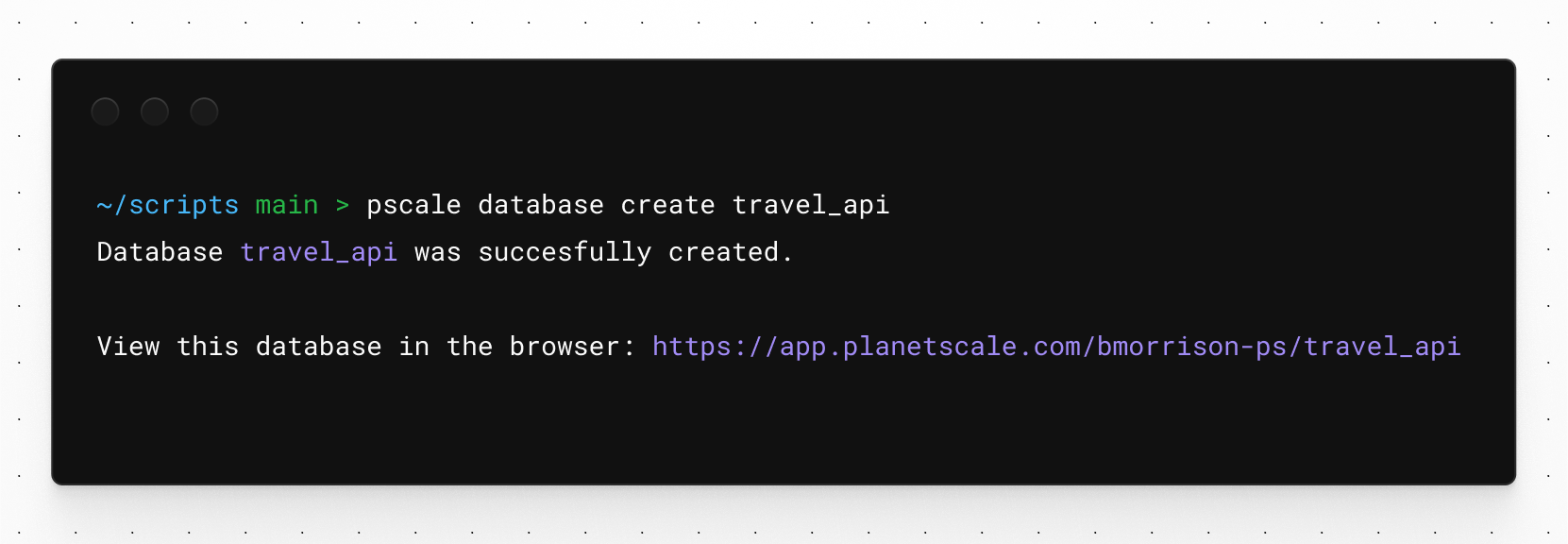
Save the above SQL to a new file on your system called create_db_script.sql. Open a terminal in the same directory where you saved the file. Start by running the pscale database create command followed by a database name to create a new database.
pscale database create travel_api
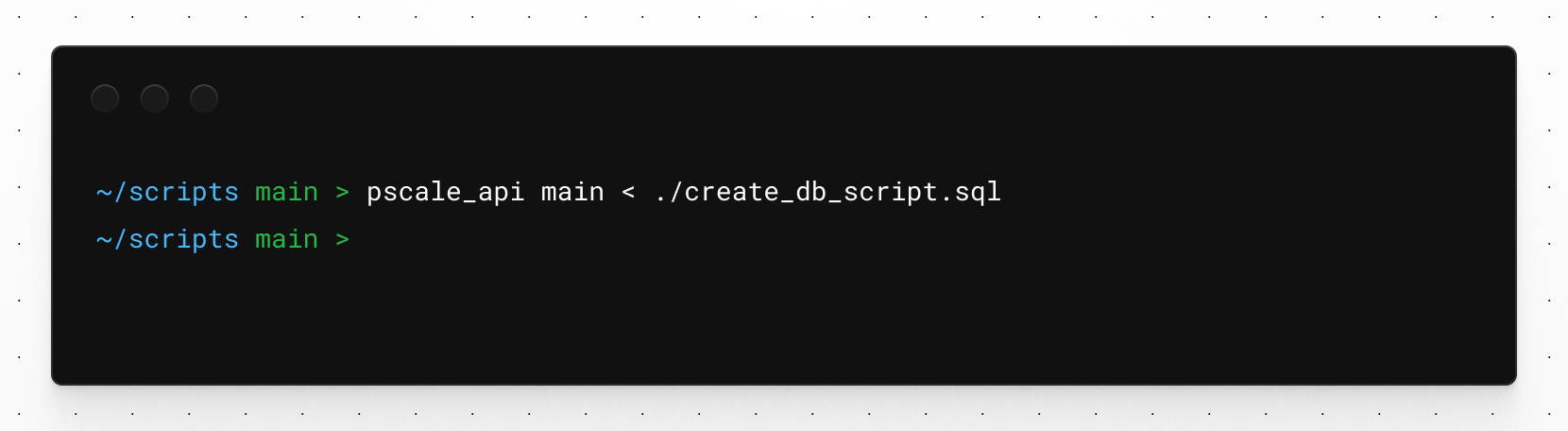
Since creating a database on PlanetScale creates the main branch by default, we can use this branch along with the pscale shell command to pipe in the commands from that script file saved earlier. You won’t receive any output if the script ran successfully.
pscale shell travel_api main < ./create_db_script.sql
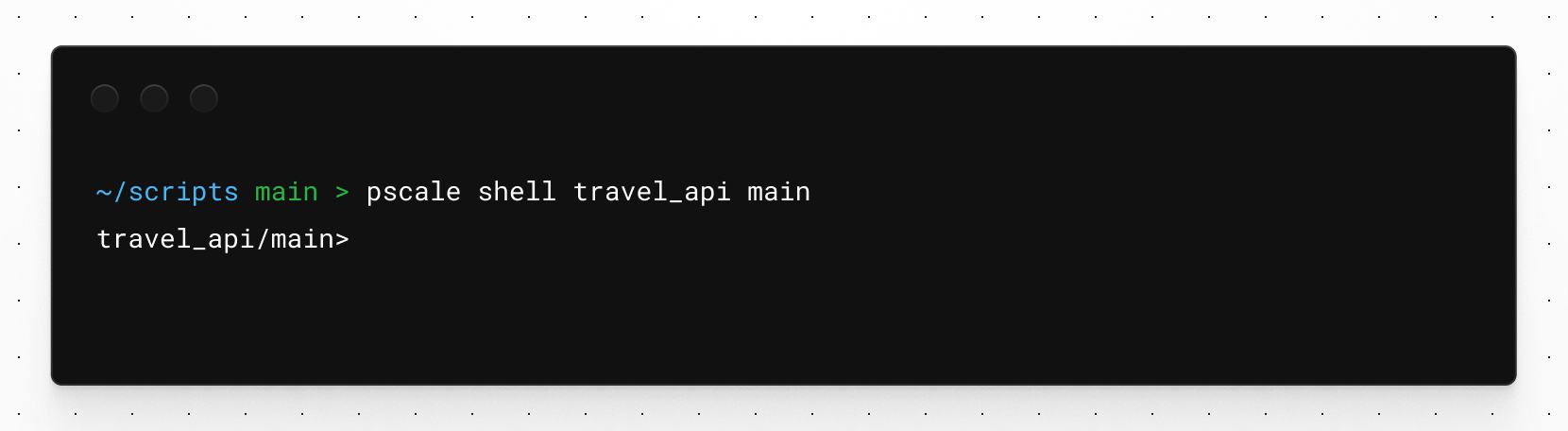
Now we can use the shell again to run commands manually on the database. You’ll notice the prompt changes to show database_name/branch_name> instead of your default terminal prompt.
pscale shell travel_api main
Run the show tables command to show that the hotels table was created.
You should see this output:
+----------------------+
| Tables_in_travel_api |
+----------------------+
| hotels |
+----------------------+
Now run a SELECT statement on hotels to see the data that was populated.
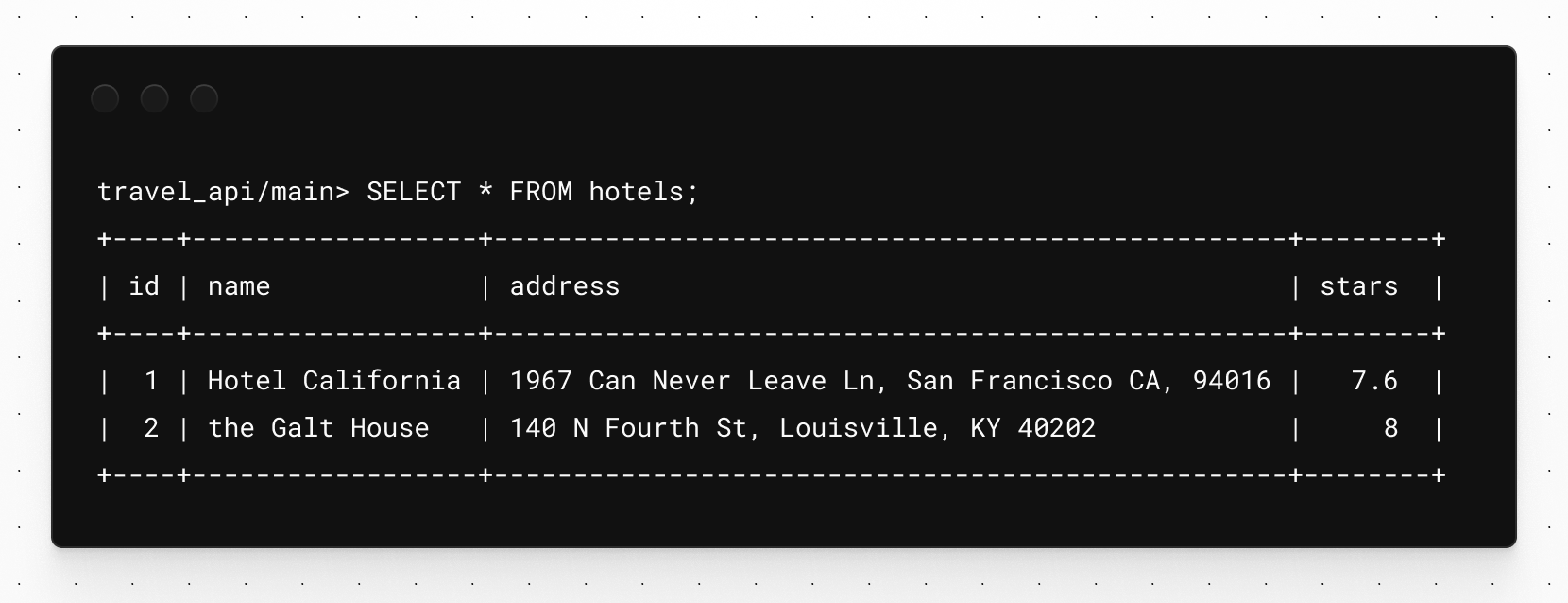
While this was a relatively simple example, imagine a scenario where you need to create and populate an entire schema using just commands. Doing it in this manner can be much simpler than manually entering all these commands in!