Connection pooling is a commonly used technique in modern applications to manage database connections efficiently. It involves creating a cache of database connections that the application can use as needed. Instead of creating a new connection for each request to the database, the application retrieves a connection from the pool. After the application finishes using the connection, it is returned to the pool to be reused later, rather than being closed outright.
Benefits of connection pooling
Using connection pooling in your application offers several advantages:
Performance
Connection pooling reduces the overhead of establishing new database connections. Connections are reused instead of being created and closed for each request. This is especially useful for applications that require frequent, small interactions with the database.
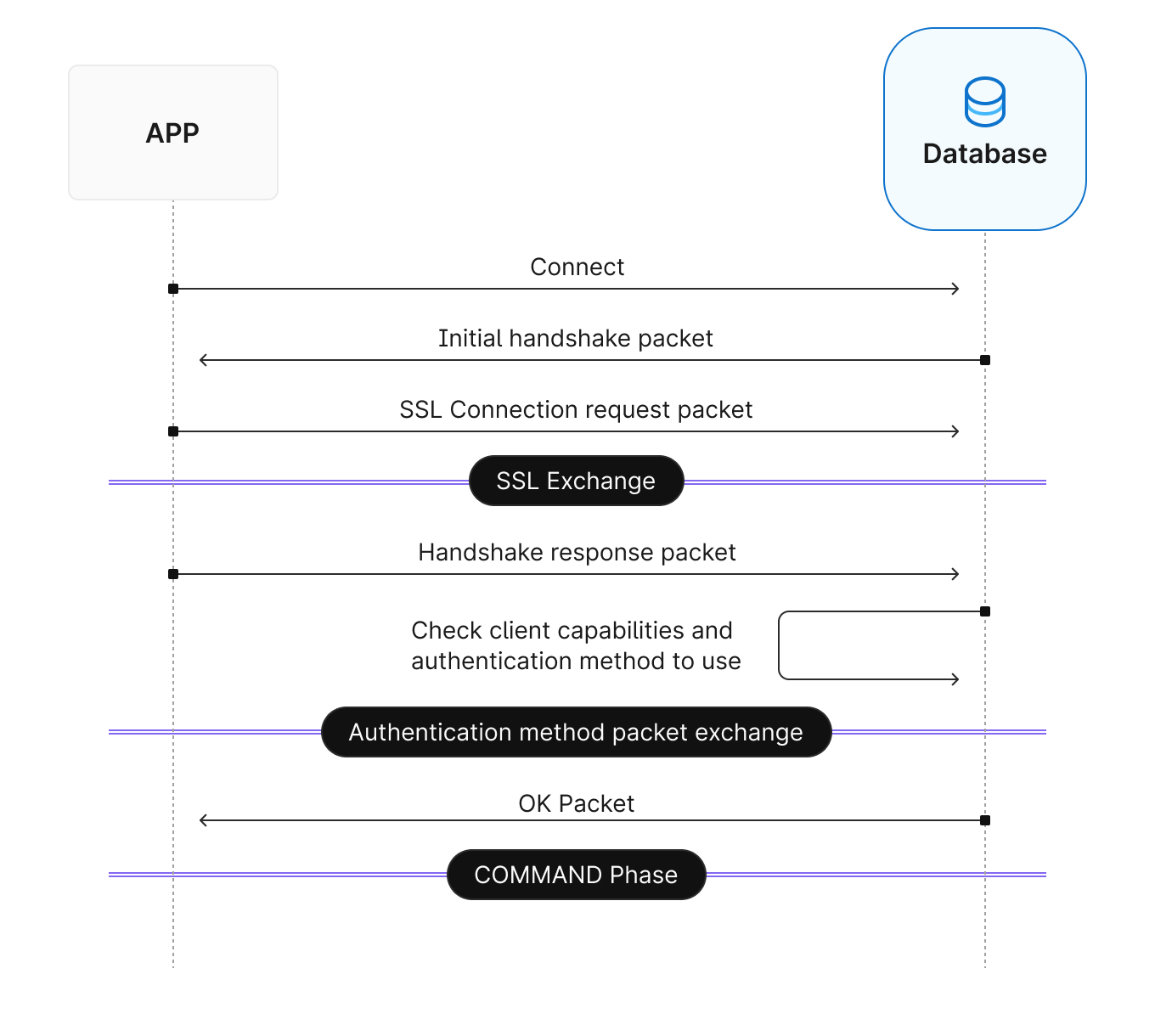
The diagram above illustrates a typical MySQL SSL connection establishment phase when an application connects to a database over a network. This initial handshake phase can add up to 50ms of overhead. However, by implementing connection pooling, applications can significantly reduce their response time per request by saving the 50ms overhead. This improvement in performance can greatly benefit the overall functionality of the applications.
Scalability
Connection pooling significantly improves an application’s ability to handle a large number of concurrent connections. By reusing existing connections, the overhead of connection establishment is removed, freeing up the CPU for other tasks. This results in an increased ability to handle more concurrent requests simultaneously for the application.
Traffic shaping
Connection pooling helps manage database resources by limiting the number of active connections. When there is a load spike at the application layer, the connection pool will throttle some of the requests and make them wait before allocating a connection for them to use. This prevents the database from being overwhelmed, which can lead to degraded performance or crashes. The database can continue to serve at maximum capacity utilization.
When connection pooling isn’t enough
Connection pooling at the application level is a useful tool, but it has limitations in solving all scalability problems. While it manages and reuses connections, it does not inherently scale the database to handle the increased load. When thousands of concurrent requests are made, the database’s resources, such as CPU, memory, and disk I/O, can be overwhelmed, resulting in performance degradation or database crashes.
As the scale of the application grows, its load increases, and it becomes necessary to deploy it on multiple servers. However, as the number of servers increases from a few to hundreds or thousands, this can potentially overload the database. Moreover, new applications connecting to the same database can also overwhelm it.
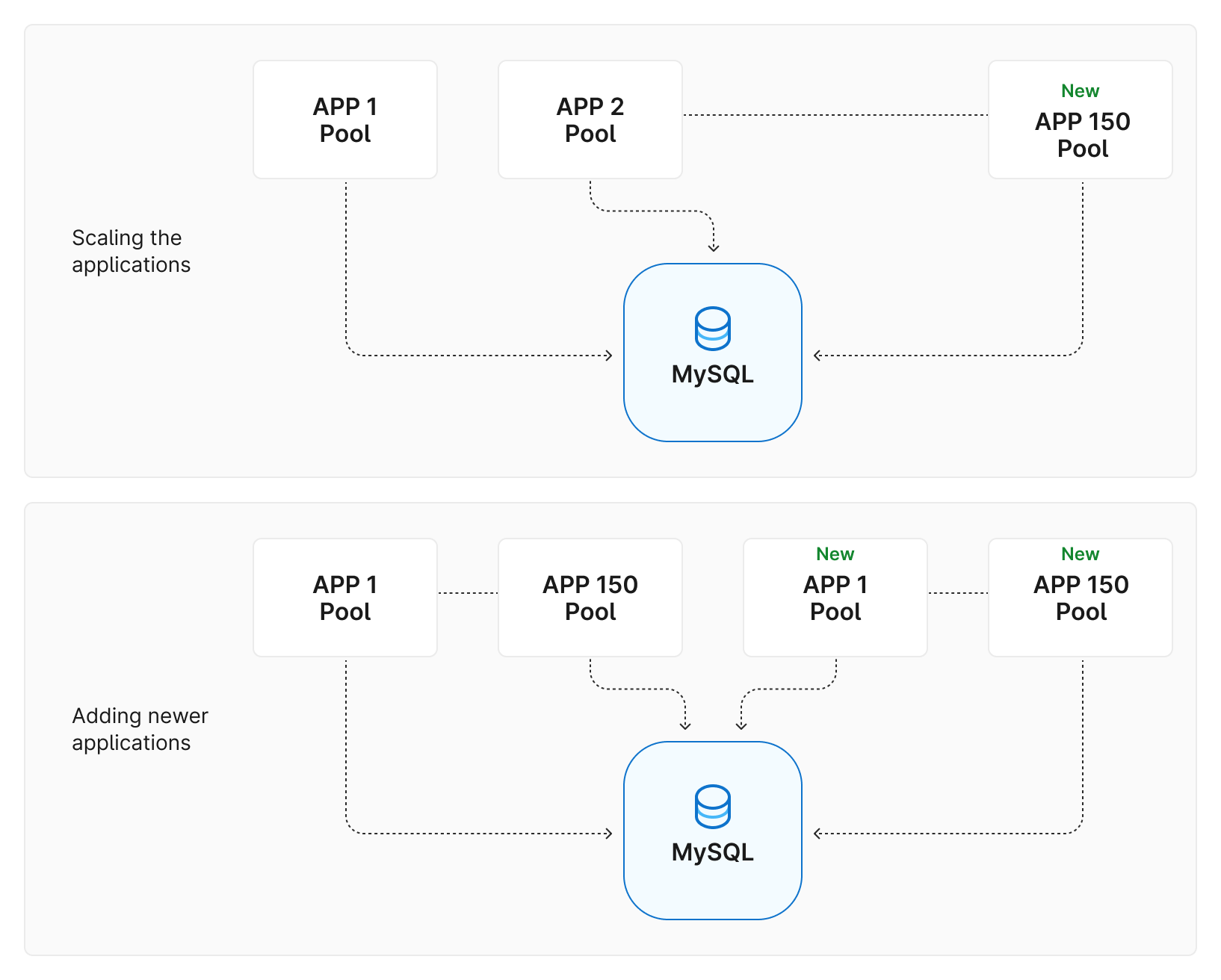
Inefficient use of database connections can also occur at the application-level connection pooling. The application servers may not always be equally loaded, and the application might not have correctly capped the database connections, resulting in a waste of connections. As a result, the application servers that require those connections may not be able to acquire them when the database connection limits are reached.
Connection pooling at scale
In 2010, YouTube encountered similar challenges, leading to the development of Vitess and its first component, Vttablet. Vttablet acted as a MySQL proxy and was primarily responsible for managing the connection pool. By allowing client applications to connect only to Vttablet, the need for a connection pool at the application level was eliminated. This meant that connections could be centrally managed in Vttablet, with the maximum number of allowed connections being configurable in Vttablet, rather than growing unbounded as the number of applications increased. This significantly reduced the strain on the database and improved scalability.
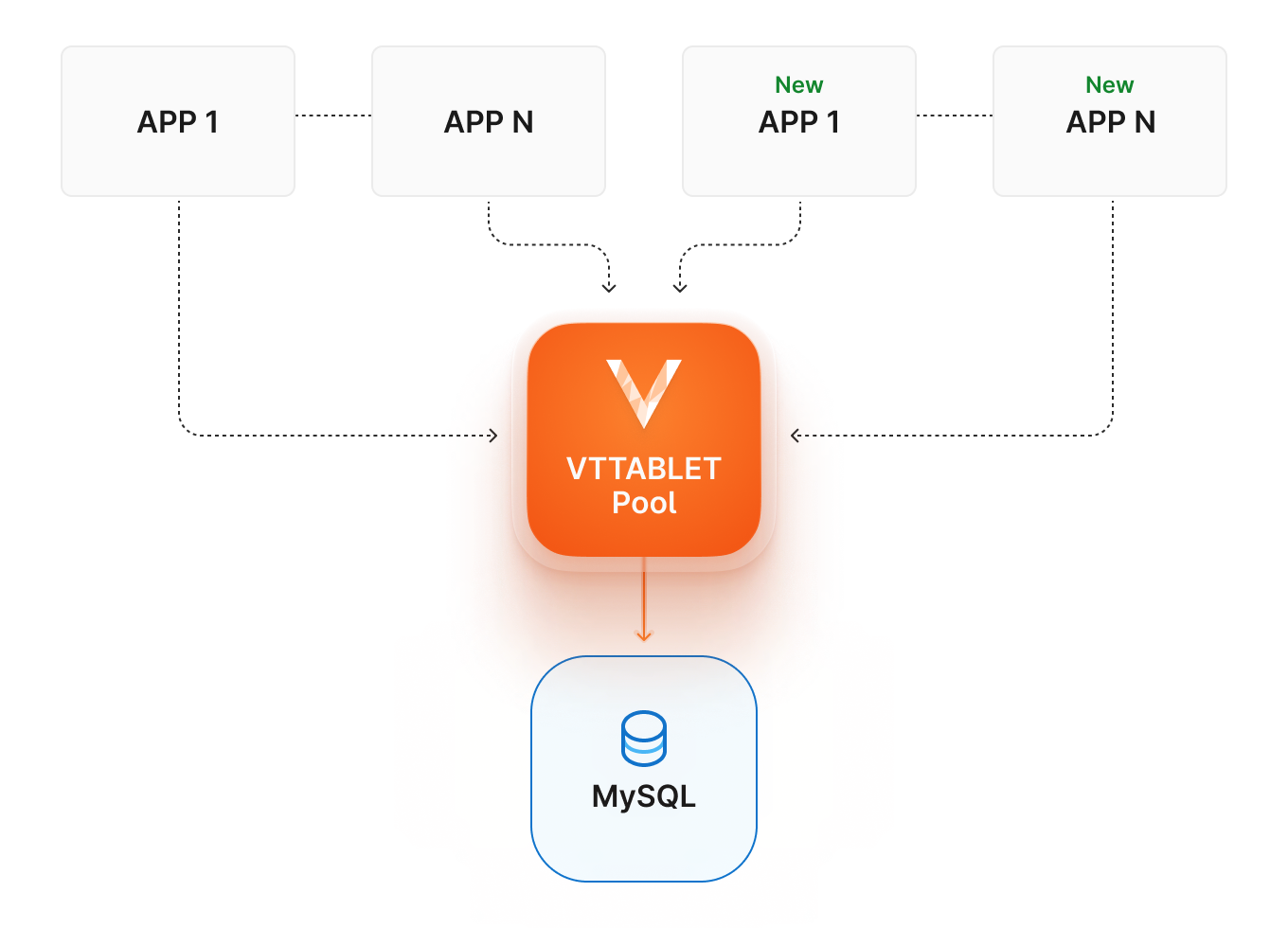
To handle concurrent requests at scale, the connection pool implementation in Vttablet was designed to be lockless, using atomic operations and non-blocking data structures with lock-free algorithms. This approach enables Vitess to efficiently manage large numbers of concurrent requests, further improving its scalability and performance.
Connection settings
MySQL provides a wide range of session-level system settings that can be adjusted for each connection. However, when using connection pooling, all connections in the pool share the same settings. Any modifications made to a connection will render it unusable for other requests, as it becomes "tainted". Therefore, either settings changes made to a connection must be restored to their original values or the connection should be closed after the operation is complete to ensure the stability of the connection pool. It is important to consider the potential impact of frequent modifications to connection settings, as these can degrade performance with increasing numbers of requests.
For a very long time, Vitess did not honor the modification of system settings on connections. If provided, they were ignored in order to preserve the benefits of connection pooling. However, when Vitess began supporting the MySQL protocol, different ORMs (object relation mapping) for multiple languages could connect to Vitess using the language’s default MySQL connector. These ORMs issue SET statements to change the connection settings at the beginning of the connection, and they expect these connections to behave in a certain way.
To support these connection-level settings, Vitess had to deviate from its original connection pooling method. In Vitess release v7.0, it allowed system settings to be modified on the connection. This makes the connection reserved for the application session and it cannot be returned to the connection pool. As the connection is taken out of the pool and cannot be returned, this turns off the connection pooling benefits for that session. As these kinds of reserved connections are no longer part of the connection pool, they can grow without any upper limit on their numbers, eventually leading to MySQL running out of connections and making the database unavailable for application use.
To limit the impact of reserved connections on the total number of connections to MySQL, Vitess used a few techniques before the release of v15.0:
Limiting the impact of reserved connections: Technique 1
When an application issues a SET statement on a connection to modify the system settings, Vitess first validates the current system settings for those variables. If the desired connection settings are already identical to the MySQL settings, the SET statement is ignored by Vitess, and the connection is not reserved for the session.
For instance, let’s consider an application sending a query such as set unique_checks = 0. Vitess will then send a query select 0 from dual where @@unique_checks != 0 to MySQL. If the query returns a row, it means that the connection setting is being modified, the session will be marked to use a reserved connection, and the new setting will be applied to the connection. Otherwise, a reserved connection is not required and the SET statement can be ignored.
Limiting the impact of reserved connections: Technique 2
MySQL 8.0 provides the capability to modify in-memory system settings temporarily for a query’s duration using SQL comments through the SET_VAR hint. This query hint sets the session value of a system variable temporarily and does not "taint" the connection when the settings are applied, making it possible to reuse the connection.
Building on the previous example, once Vitess recognizes that the unique_checks setting is being altered, all subsequent queries within that session are rewritten. For example, the query insert into user (id, name) values (1, ‘foo’) will be rewritten as insert /*+ SET_VAR(unique_checks=0) */ into user (id, name) values (1, ‘foo’).
However, it’s essential to note that not all settings can be used with SET_VAR. For those that are not permitted, reserved connections must still be used.
By utilizing the techniques mentioned above, we have reduced the use of reserved connections to the extent possible, thus retaining the advantages of using a connection pool. However, due to the limited number of system settings that can be used with SET_VAR, there are still system settings that must be applied to the connection, causing the connection to be pulled out of the connection pool and leading to degraded database performance.
When the connection settings feature was launched, Vitess users were advised to use it sparingly. We recommended setting MySQL default settings to align with the ORM’s SET statements to minimize the possibility of using reserved connections and to avoid the issue of running out of connections. However, over time, Vitess users discovered that this approach is not always feasible, especially when multiple applications with different ORMs are running on a single Vitess cluster. Each ORM may set a different value for the same setting, making the MySQL default settings ineffective, resulting in a high number of reserved connections being used. Therefore, this issue needs to be addressed at the Vitess level.
Settings pool
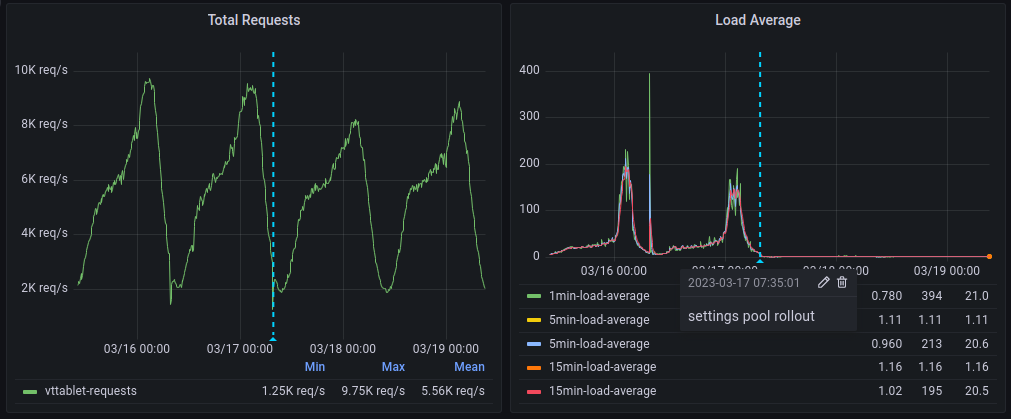
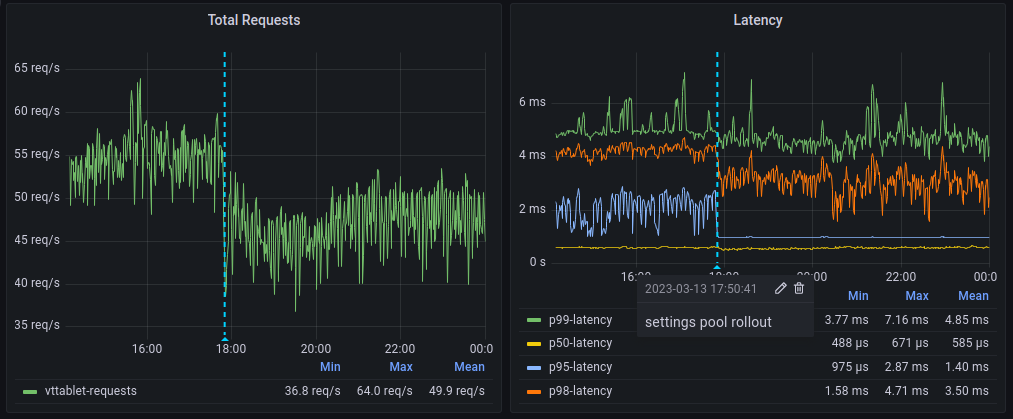
In Vitess 15, a new connection pool, the "settings pool", was introduced. The settings pool can handle modified connections without compromising the benefits of connection pooling. Vitess now tracks and manages connections in which system settings have been modified. This process is transparent to the application but provides all the advantages of connection pooling while still allowing per-connection settings. When an application submits a query to Vitess for execution, Vitess can retrieve the correct connection from the connection pool, with or without settings applied, based on the settings specified by that application on that session, and then execute the query.
Currently, this feature is behind a flag and can be enabled using queryserver-enable-settings-pool in Vttablet.
At PlanetScale, we have started to roll out this feature and are already seeing improvements in query latency and load on Vttablet for customers who previously relied on reserved connections due to their application ORMs.