When we were first building PlanetScale’s API, we needed to figure out what type of identifier we’d be using. We knew that we wanted to avoid using integer IDs so that we wouldn’t reveal the count of records in all our tables.
The common solution to this problem is using a UUID (Universally Unique Identifier) instead. UUIDs are great because it’s nearly impossible to generate a duplicate and they obscure your internal IDs. They have one problem though. They take up a lot of space in a URL: api.planetscale.com/v1/deploy-requests/7cb776c5-8c12-4b1a-84aa-9941b815d873.
Try double clicking on that ID to select and copy it. You can’t. The browser interprets it as 5 different words.
It may seem minor, but to build a product that developers love to use, we need to care about details like these.
Nano ID
We decided that we wanted our IDs to be:
- Shorter than a UUID
- Easy to select with double clicking
- Low chance of collisions
- Easy to generate in multiple programming languages (we use Ruby and Go on our backend)
This led us to NanoID, which accomplishes exactly that.
Here are some examples:
izkpm55j334uz2n60bhrj7e8qoucu12dag1x
These are much more user-friendly in a URL: api.planetscale.com/v1/deploy-requests/izkpm55j334u
ID length and collisions
An ID collision is when the same ID is generated twice. If this happens seldomly, it’s not a big deal. The application can detect a collision, auto-generate a new ID, and move on. If this is happening often though, it can be a huge problem.
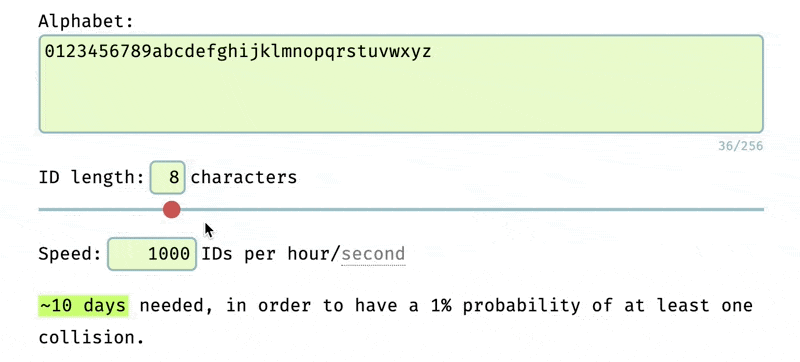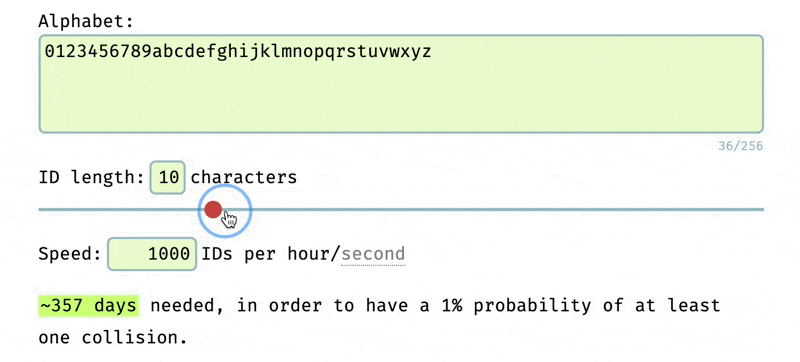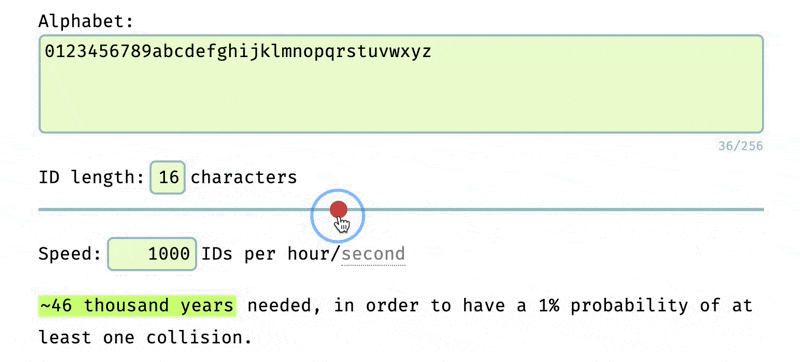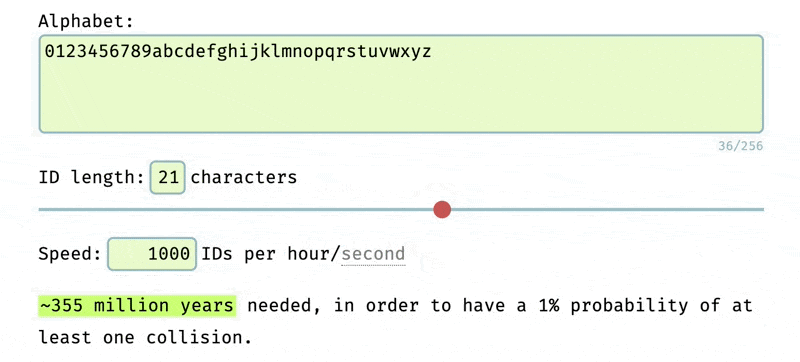
The longer and more complex the ID, the less likely it is to happen. Determining the complexity needed for the ID depends on the application. In our case, we used the NanoID collision tool and decided to use 12 character long IDs with the alphabet of 0123456789abcdefghijklmnopqrstuvwxyz.
This gives us a 1% probability of a collision in the next ~35 years if we are generating 1,000 IDs per hour.
If we ever need to increase this, the change would be as simple as increasing the length in our ID generator and updating our database schema to accept the new size.
Note
PlanetScale makes deploying database schema changes a breeze with branching, deploy requests, and a Git-like development workflow.
Generating NanoIDs in Rails
Our API is a Ruby on Rails application. For all public-facing models, we have added a public_id column to our database. We still use standard auto-incrementing BigInts for our primary key. The public_id is only used as an external identifier.
Example schema
We add the public_id column as well as a unique constraint to protect from duplicates.
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`public_id` varchar(12) DEFAULT NULL,
`name` varchar(255) NOT NULL,
`created_at` datetime(6) NOT NULL,
`updated_at` datetime(6) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_public_id` (`public_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Auto generating IDs
We built a concern that could be shared across all our models to autogenerate IDs for us. In Rails, a concern is a shared module that can be shared across models to reduce duplication. Whenever our application creates a new record, this code runs and generates the ID for us.
# app/models/user.rb
class User < ApplicationRecord
# For each model with a public id, we include the generator
include PublicIdGenerator
end
Here is the generator that creates the ID and handles retries in the small chance of a duplicate.
# app/models/concerns/public_id_generator.rb
require "nanoid"
module PublicIdGenerator
extend ActiveSupport::Concern
included do
before_create :set_public_id
end
PUBLIC_ID_ALPHABET = "0123456789abcdefghijklmnopqrstuvwxyz"
PUBLIC_ID_LENGTH = 12
MAX_RETRY = 1000
PUBLIC_ID_REGEX = /[#{PUBLIC_ID_ALPHABET}]{#{PUBLIC_ID_LENGTH}}\z/
class_methods do
def generate_nanoid(alphabet: PUBLIC_ID_ALPHABET, size: PUBLIC_ID_LENGTH)
Nanoid.generate(size: size, alphabet: alphabet)
end
end
# Generates a random string for us as the public ID.
def set_public_id
return if public_id.present?
MAX_RETRY.times do
self.public_id = generate_public_id
return unless self.class.where(public_id: public_id).exists?
end
raise "Failed to generate a unique public id after #{MAX_RETRY} attempts"
end
def generate_public_id
self.class.generate_nanoid(alphabet: PUBLIC_ID_ALPHABET)
end
end
Generating NanoIDs in Go
NanoID generators are available in many languages. At PlanetScale, we also have a backend service in Go that needs to generate public IDs as well.
Here is how we do it in Go:
// Package publicid provides public ID values in the same format as
// PlanetScale’s Rails application.
package publicid
import (
"strings"
nanoid "github.com/matoous/go-nanoid/v2"
"github.com/pkg/errors"
)
// Fixed nanoid parameters used in the Rails application.
const (
alphabet = "0123456789abcdefghijklmnopqrstuvwxyz"
length = 12
)
// New generates a unique public ID.
func New() (string, error) { return nanoid.Generate(alphabet, length) }
// Must is the same as New, but panics on error.
func Must() string { return nanoid.MustGenerate(alphabet, length) }
// Validate checks if a given field name’s public ID value is valid according to
// the constraints defined by package publicid.
func Validate(fieldName, id string) error {
if id == "" {
return errors.Errorf("%s cannot be blank", fieldName)
}
if len(id) != length {
return errors.Errorf("%s should be %d characters long", fieldName, length)
}
if strings.Trim(id, alphabet) != "" {
return errors.Errorf("%s has invalid characters", fieldName)
}
return nil
}
Wrap up
Creating a great developer experience is one of our big priorities at PlanetScale. These seemingly small details, like being able to quickly copy an ID, all add up. NanoIDs were able to solve our application requirements without degrading developer experience.