Note
Note: The Scaler Pro plan has since been renamed to the Base plan.
Today, we're announcing a new generation of PlanetScale plans and pricing. Most prominently: we're replacing our Teams plan with a new "Scaler Pro" offering that combines the best of our current plans and enterprise offerings for companies of all sizes. These plans allow customers to select exactly the resources they need for their workloads.
As we've onboarded thousands of customers, large and small, one of the most common pieces of feedback we've received is that customers are unsure how to map our pricing model onto their business. Reads and writes are easy to understand conceptually, but they don't map back to capacity planning that businesses are accustomed to. Many customers want more control than the traditional serverless model provides and clarity on how it compares to products like Amazon RDS and Google Cloud SQL.
The serverless pricing model is an interesting framework for databases, but many real-world workloads need to be delineated in more concrete metrics with as little variability as possible. When predictability, stability, and availability matter most, worrying about unbounded and unknown costs is a distraction nobody can afford.
Scaler Pro gives you the controls needed to understand how to grow and scale. Our new plans come with the ability to scale up and down on demand, all with cutting-edge resiliency and availability features. With Scaler Pro, you get a competitive price compared to established Database-as-a-Service (DBaaS) solutions while gaining significantly more features.
This is something we haven't done lightly. We pride ourselves on the innovations we've made in our serverless database pricing model and still aim to be the best database for serverless.
Scaler Pro pricing
Scaler Pro databases are priced on a combination of resources (CPU and memory) and disk storage. Every database has a 'cluster size' encompassing the components that make up a PlanetScale database. Much like our existing plans, we only charge for the storage allocated in your tables, but not binary logs or other metadata.
Refer to our Plans documentation for a full list of Scaler Pro configuration options and pricing.
Now let's dive into what goes into a PlanetScale Scaler Pro database, how it stacks up next to common alternatives that you might already be using, and what you're buying when you provision one.
What is in a PlanetScale database?
When you think of your PlanetScale database, what do you imagine? For some, a 'serverless database' means something mystical; others are probably picturing a complex web of virtual machines, hard drives, network switches, and all of the pieces in between.
Let's look at a Scaler Pro database in the PlanetScale product and break it down a bit:
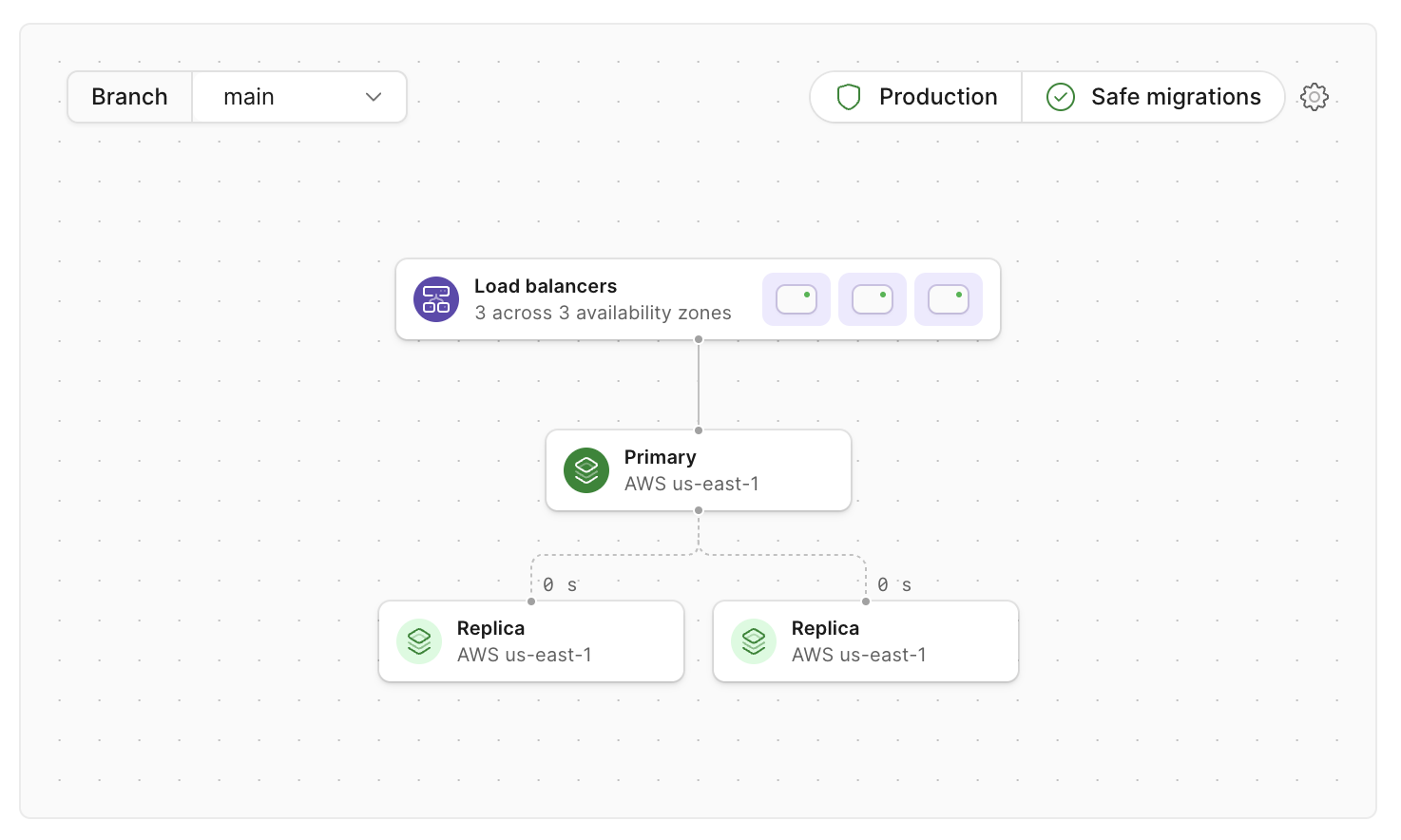
In this diagram, the most important components are the primary and replicas. Each of these is an instance of MySQL and the Vitess components around it to handle orchestrating failovers, backups, etc.
Why is this important? It's where the data is! Underneath it all, PlanetScale uses standard MySQL replication to replicate your data and exists in multiple availability zones. All Scaler Pro production branches by default are:
- Replicated across three availability zones in GCP or AWS
- Configured to use MySQL's
semi-syncto ensure that writes are persisted across at least two availability zones before being acknowledged to the client - Monitored continuously with Orchestrator, which handles planned and unplanned failovers
For Scaler Pro databases, this means that any piece of data you write will exist in at least two redundant block storage volumes that span failure domains, ensuring that the data will be there when you need it. With the Vitess-native Orchestrator looking over your database, the loss of a virtual machine or other problem will be swiftly remediated without a human involved.
Beyond that, PlanetScale runs even more infrastructure behind the scenes: backups are taken by spinning up MySQL instances on-demand that validate existing backups and create new ones, a bespoke pipeline to power PlanetScale Insights, and much more.
Amazon RDS vs. Scaler Pro and Availability Zones
In order to create logical and geographic redundancy, cloud providers split up their regions into multiple isolated datacenters that they call availability zones (AZs). In us-east-1, there are six of them: us-east-1a through us-east-1f. Each of these has isolated power and networking, and can be leveraged to create more resilient applications and infrastructure by expecting the failure of one or more of them in your code.
It may come as no surprise, but Amazon is very familiar with the tradeoffs necessary to run MySQL databases. To better understand what Scaler Pro is offering, we can compare it to the different tiers of RDS databases:
- Single-AZ
- Multi-AZ with one standby
- Multi-AZ with two readable standbys
We can quickly eliminate single Availability Zone (AZ) from consideration for production workloads: it doesn't offer any failover capabilities, no redundancy for the degradation of an availability zone, and resiliency to losing data is limited to backups. A Single-AZ database might be great for small or staging workloads, but not much more. This would be the equivalent of a development branch on PlanetScale.
Looking at Multi-AZ, things get more interesting. This option includes a "standby" instance to which all writes are synchronously replicated, ensuring that if the primary availability zone were to vanish, all of the acknowledged queries would be contained in the second availability zone, just a failover away. This is great for resiliency but not availability. Failover times are a minute or longer, and no read replicas are available for scaling database traffic.
Finally, we land on Multi-AZ with two readable standbys. This option includes a primary and two replica databases and ensures that any writes to the primary have been acknowledged by at least one replica.
If you've been reading along, this will sound familiar — a PlanetScale Scaler Pro database has the same semantics! The biggest benefits of this option are that you gain two replica instances that you can use to scale your reads, and much faster failovers due to the live databases that are running and ready to take traffic.
Because there's such a direct comparison, it's now much easier to understand how much switching to PlanetScale could save you. Let's take a look at an apples-to-apples comparison:
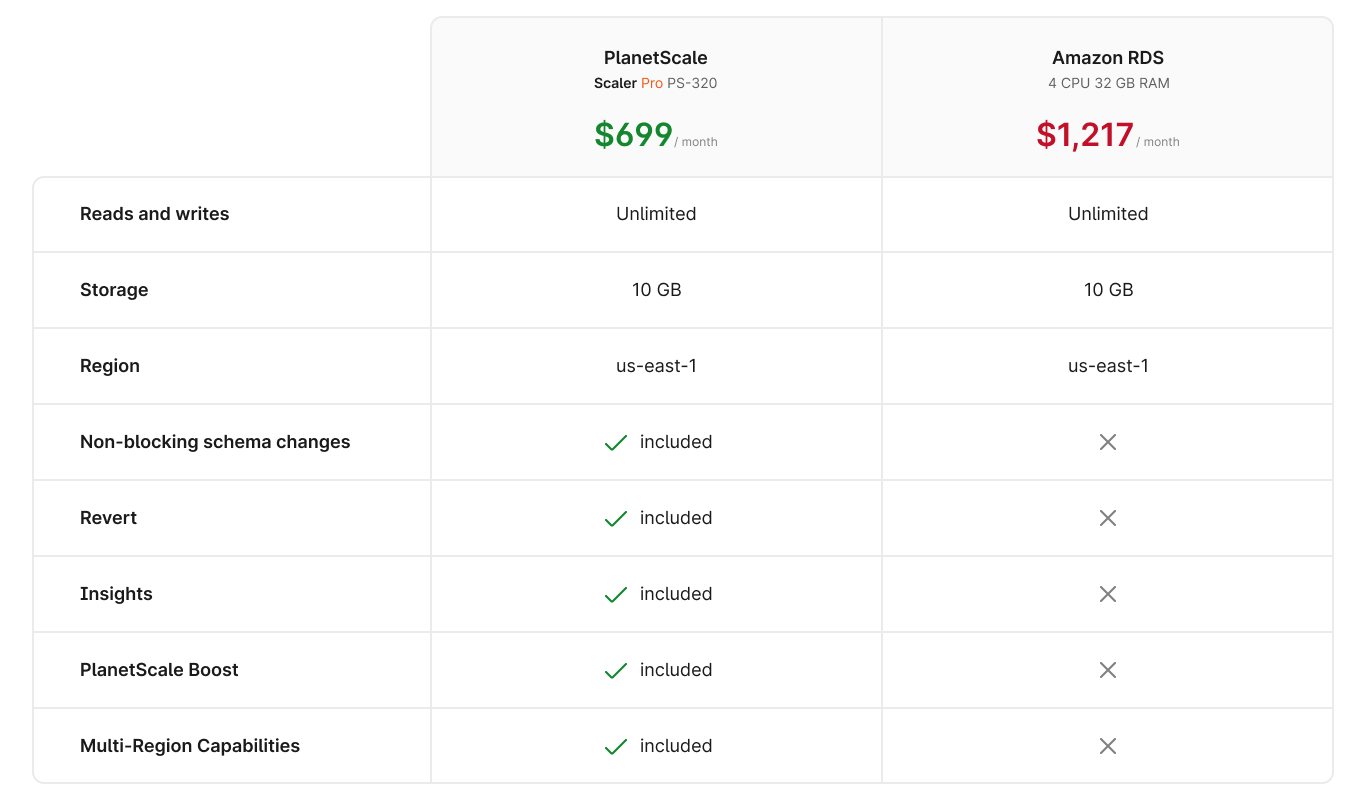
As you can see, PlanetScale offers all of the benefits of a Multi-AZ with two readable standby databases, at the price of a Multi-AZ with one standby database. This is before we add PlanetScale's industry-leading Insights and non-blocking schema changes.
Wrapping up
Whether you're a current PlanetScale customer or are considering switching from RDS or Cloud SQL, as many have already done, we hope the Scaler Pro pricing scheme works for you. It's as easy as clicking a button to migrate an existing Developer or Scaler database today. For more in-depth coverage of the Scaler Pro plan, check out the plans article in our docs.
If you want to give it a try with a new database, plug your RDS database into our Imports tool today and give it a whirl — we don't think you'll be disappointed!
If your RDS database requires more scale than any of the sizes on our current price sheet, reach out to our sales team today — we can accommodate workloads that require terabytes of memory and petabytes of storage.