Taylor Barnett, Matt Robenolt |
Today we are introducing the PlanetScale serverless driver for JavaScript, a Fetch API-compatible database driver.
This new driver and infrastructure update brings you:
- The ability to store and query data in PlanetScale from environments such as Cloudflare Workers, Vercel Edge Functions, and Netlify Edge Functions.
- Infrastructure improvements that enable global routing and improve connection reliability and performance.
Tip
We put together a demo application that demonstrates how to implement this with Cloudflare Workers, Vercel Edge Functions, and Netlify Edge Functions.
Until today, you could not use PlanetScale in these environments because they require external connections to be made over HTTP and not other networking protocols. Connections with other MySQL drivers speak the MySQL binary protocol over a raw TCP socket. Our new driver uses secure HTTP, which allows you to use PlanetScale in these constrained environments. The driver works in any environment that uses the Fetch API.
In addition to Cloudflare Workers, Vercel Edge Functions, and Netlify Edge Functions, other serverless environments from these and other providers like AWS typically need databases to support hundreds, thousands, or even tens of thousands of database connections. PlanetScale has always handled these high concurrent connections effortlessly, but our underlying infrastructure change provides a much faster connection path.
The next generation of PlanetScale infrastructure
Backing our new driver is a new HTTP API and global routing infrastructure to support it. Note: The HTTP API is currently not documented, but we plan on documenting it when we’re ready to officially release it.
Outside of restrictive environments, an HTTP interface for our database connectivity gives us other benefits in serverless environments, such as a modern TLS stack for faster connections with TLS 1.3, connection multiplexing with HTTP/2, protocol compression with gzip, brotli, or snappy, all of which lead to a better experience for serverless environments.
Our new infrastructure and APIs also enable global routing. Similar to a CDN, global routing reduces latency drastically in situations where a client is connecting from a geographically distant location, which is common within serverless and edge compute environments. A client connects to the closest geographic edge in our network, then backhauls over long-held connection pools over our internal network to reach the actual destination. Within the US, connections from US West to a database in US East reduce latency by 100ms or more in some cases, even more as the distance increases.
How to use the PlanetScale serverless driver for JavaScript
First, install the package in your environment:
npm install @planetscale/database
You can see the driver's code and documentation here.
The driver will first have you connect with a PlanetScale-provided host, username, and password. In your database Overview page, click the Connect button and select “@planetscale/database” from the “Connect with” dropdown. You can copy and paste the host, user, and password into your code. When deploying your code, we recommend creating environment variables in the serverless platform of your choice to store these variables.
import { connect } from '@planetscale/database'
const config = {
host: '<host>',
username: '<user>',
password: '<password>'
}
Then, once your connection configuration is set, you will connect to and execute a SQL command on PlanetScale.
const conn = connect(config)
const results = await conn.execute('SHOW TABLES')
console.log(results)
The driver also handles your SQL sanitization to help prevent security issues like SQL injection. For example, this is useful in queries like the following with a parameter:
conn.execute('SELECT * FROM users WHERE email=?', ['foo@example.com'])
You can read more about the driver and its features in the PlanetScale serverless driver for JavaScript documentation.
Want to try it out?
You can check out the example application code from github and run the application to try out these features. In the app, you can choose to have the data pulled from a PlanetScale database using Cloudflare Workers, Vercel Edge Functions, or Netlify Edge Functions.
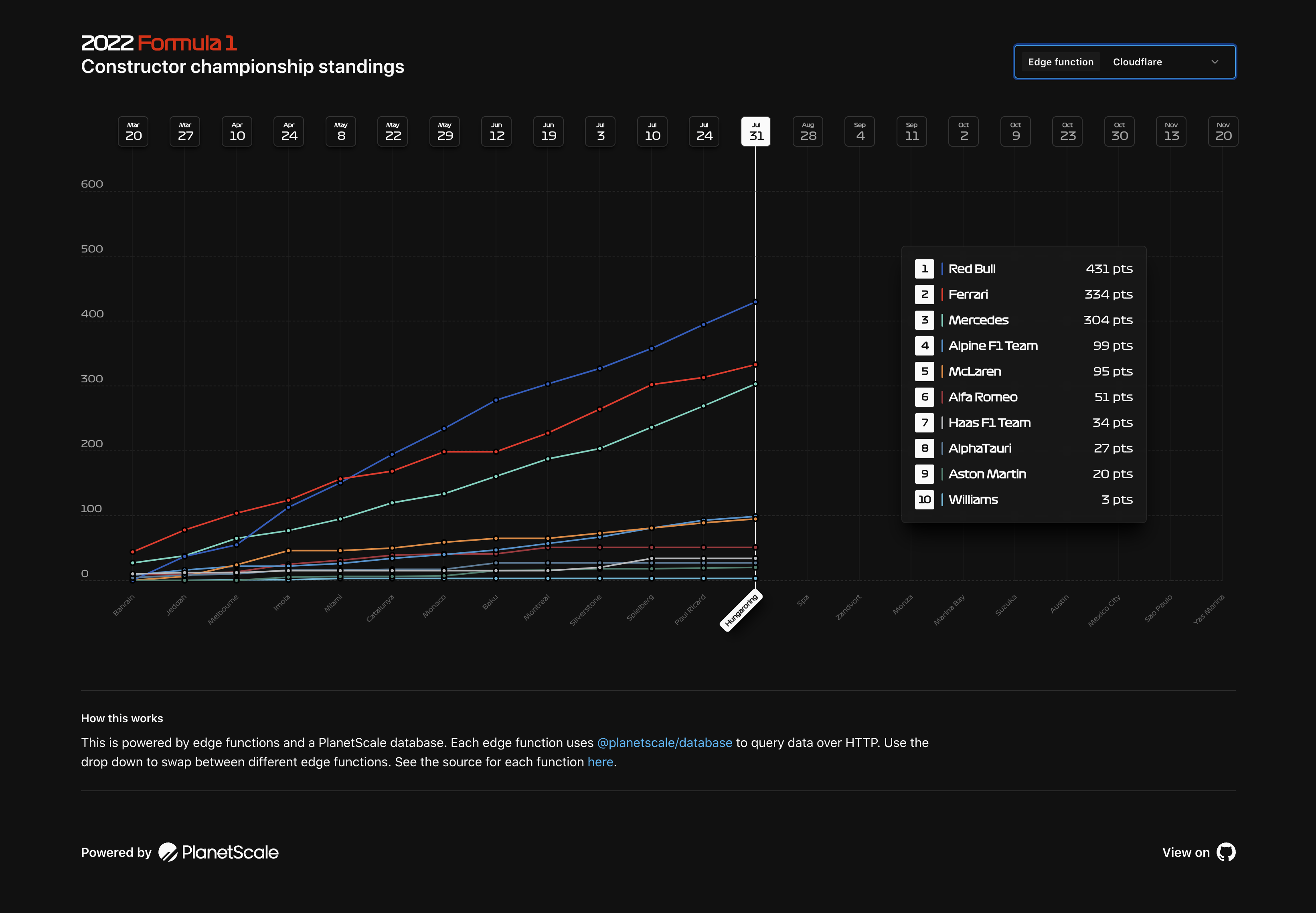
We have separated how each of these functions works. You can see the Cloudflare Workers, Vercel Edge Functions, and Netlify Edge Functions examples in their own subdirectory.
Try it out yourself
Ready to try out the driver in your serverless and edge compute platform of choice? Get started in the PlanetScale documentation.
Tweet at us @planetscale or post in our GitHub Discussion group to share your experience with the new driver.