Overview
Ever find yourself building a database only to start questioning what data types you should use for a specific column? In this entry of the MySQL data types series, we’ll explore the various ways you can save strings and text to a database to help demystify the options you have as a developer, starting with VARCHAR and CHAR.
VARCHAR vs CHAR
VARCHAR is probably the most widely used data type for strings. It stores a string of variable length up to a maximum of 65,535 characters. When creating a VARCHAR field, you’ll be able to specify the maxmimum number of characters the field will accept using the VARCHAR(n) format, where n is the maximum number of characters to be stored. Due to the fact that is is variable length, it will only allocate enough disk space to store the contents of the string, not the full length of the contents passed in.
VARCHAR also allocates a little bit of extra space with each value stored. Depending on the space required to store the data, 1 or 2 bytes of overhead will be allocated. If the space required is less than 255 bytes, a 1 byte prefix will be added, otherwise a 2 byte prefix will be used. The exact space required to store a value depends on the character set used (more on that in a bit).
CHAR is another method to store strings, but it has a maximum length of 255 and is fixed length. As with VARCHAR, you may optionally set the maximum number of characters in a CHAR field with the CHAR(n) format. If not specified, n defaults to 1. The values stored in a CHAR column are right-padded with empty spaces, so it will always store n characters regardless of the string being saved. In certain circumstances, this can actually increase performance of the database.
Factoring in the charset
While most programming languages use characters from the English language, humans across the world write and read using different types of characters. This can be something simple like Ñ in Spanish, or something very different like データベース in Japanese. To address this, MySQL has different character sets (or charsets) to address the symbols used in different languages. Character sets affect the way text is stored in the database, but also affect the amount of storage space allocated when saving data.
For example, when using the default charset of utf8mb4, MySQL will allocate 4 bytes per character stored. Factoring this in, along with a maximum row size of 65,535 bytes across ALL columns, you'd realistically only be able to create a VARCHAR column with a maximum length 16,383 characters due to the storage requirements for each character.
Visualizing the differences
When saving data to a CHAR field, one side effect is that any trailing spaces in the string are effectively lost when the value is saved. In fact, MySQL will not even return trailing spaces when you query data from a CHAR column because it has to assume that the extra spaces are just padding.
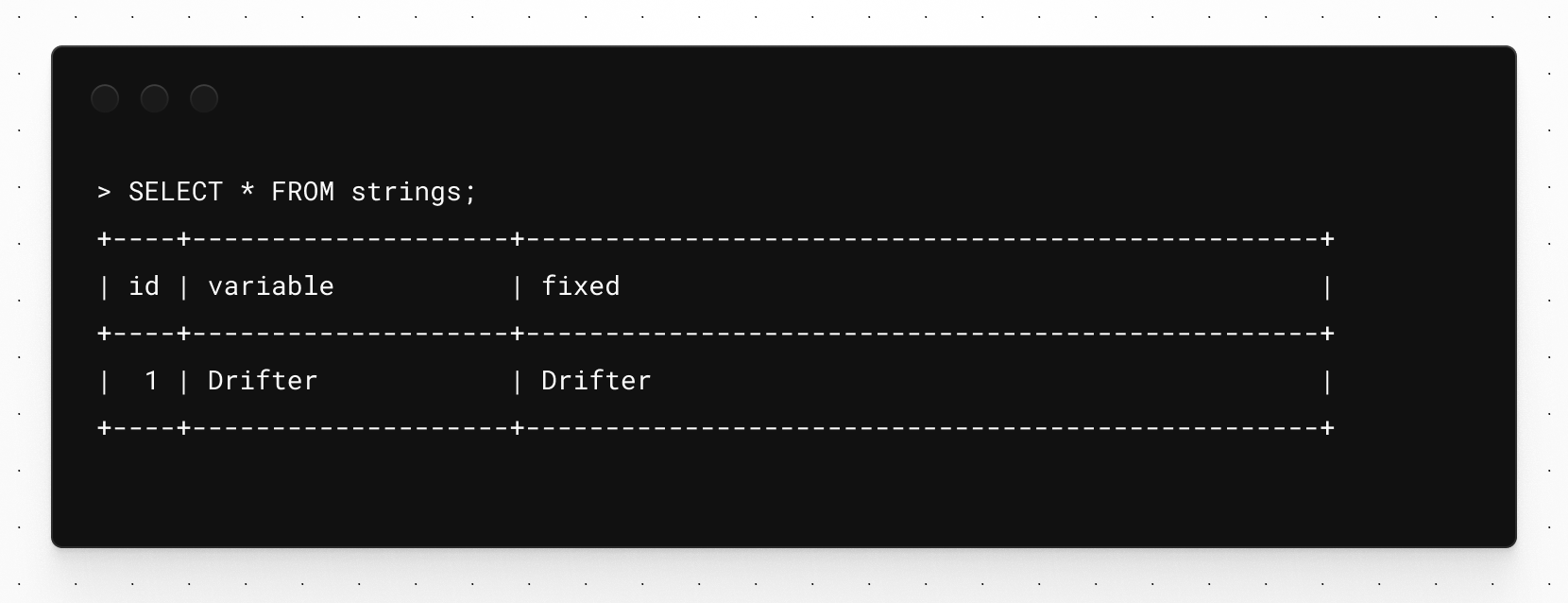
To demonstrate this, let’s create a table with two columns, one VARCHAR(20) and one CHAR(20). We’ll then insert some data with five spaces at the end of it to see how it’s stored.
CREATE TABLE strings(
id INT PRIMARY KEY AUTO_INCREMENT,
variable VARCHAR(20),
fixed CHAR(20)
);
INSERT INTO strings (variable, fixed) VALUES ("Drifter ", "Drifter ");
Now if I run the following SELECT statement, it appears that the returned data is the same.
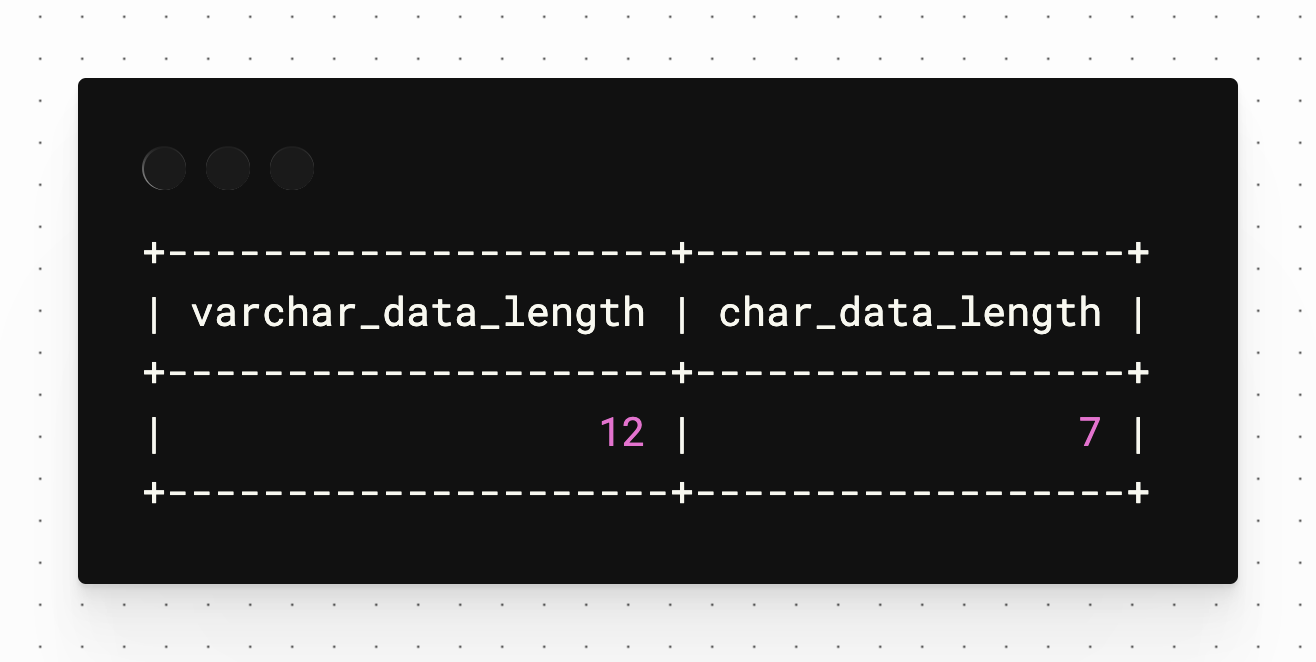
However, if I use the CHAR_LENGTH function to calculate the number of characters used in each field, you’ll notice the data stored in the VARCHAR field (respresented with varchar_data_length) is 12, which considers the 5 extra space characters at the end, whereas the CHAR field only shows 7. This is because MySQL is storing the whitespace at the end of the VARCHAR value, but it assumes the extra space at the end of the CHAR value is the padding that was appended based on the data type.
SELECT CHAR_LENGTH(variable) AS varchar_data_length, CHAR_LENGTH(fixed) AS char_data_length FROM strings;
As stated earlier, VARCHAR values have an extra overhead when the data is written to disk as well. This means that if you are storing the string “Spider” which is 6 characters in length, and you are storing it in both a VARCHAR(6) and a CHAR(6) column, the VARCHAR value will use 25 bytes (4 bytes per character using the utf8mb4 character set plus 1 byte of overhead) of disk space, whereas the CHAR value will use 24 bytes.
However, if you store “Eido” in those same columns, the VARCHAR will only use 5 bytes and the CHAR will still use 6 bytes. Since the CHAR data type is fixed-length, it is right-padded with 2 empty spaces, for a total of 6.
| Value | VARCHAR(6) Stored value | VARCHAR(6) Space used | CHAR(6) Stored value | CHAR(6) Space used |
|---|---|---|---|---|
| "Spider" | "Spider" | 25 bytes | "Spider" | 24 bytes |
| "Eido" | "Eido" | 17 bytes | "Eido " | 24 bytes |
| "Eido " | "Eido " | 25 bytes | "Eido " | 24 bytes |
When to use VARCHAR vs CHAR
Now that you understand the differences between VARCHAR and CHAR, here are a few tips on deciding which data type fits your application best:
Use VARCHAR if:
- You need to store a string with more than 255 characters.
- You find yourself in a rare scenario where you do need to preserve trailing spaces.
Use CHAR if:
You are at or below 255 characters, and you always know the length of the string.
A fixed-length serial number would be a good example of when
CHARis useful.
Further learning
If you'd like to learn more about data types in MySQL, we have an article on the INT data type and one on the JSON data type that you may find useful.
We also have short videos on the following data types: