Anyone responsible for a large production database can tell you that ensuring your database is healthy and performing optimally can be difficult and time-consuming. Even with battle-tested dashboards, the latest monitoring tools, and a deep understanding of your application, the phrase “Hey, is something up with the database?” strikes fear into the hearts of even the most experienced operators.
Today, we are launching a powerful new set of capabilities in PlanetScale called Insights Anomalies, designed to simplify answering this question. The goal is to provide a crystal clear overview of your database’s health and make it easy to troubleshoot when something goes wrong. This post will explore Insights Anomalies and show how we implemented it.
Insights Anomalies
If you head to the “Insights” tab in your PlanetScale database, you’ll see a new “Anomalies” section. There, you’ll find a graph representing your database’s health over time, as measured by the number of queries that took longer than expected.
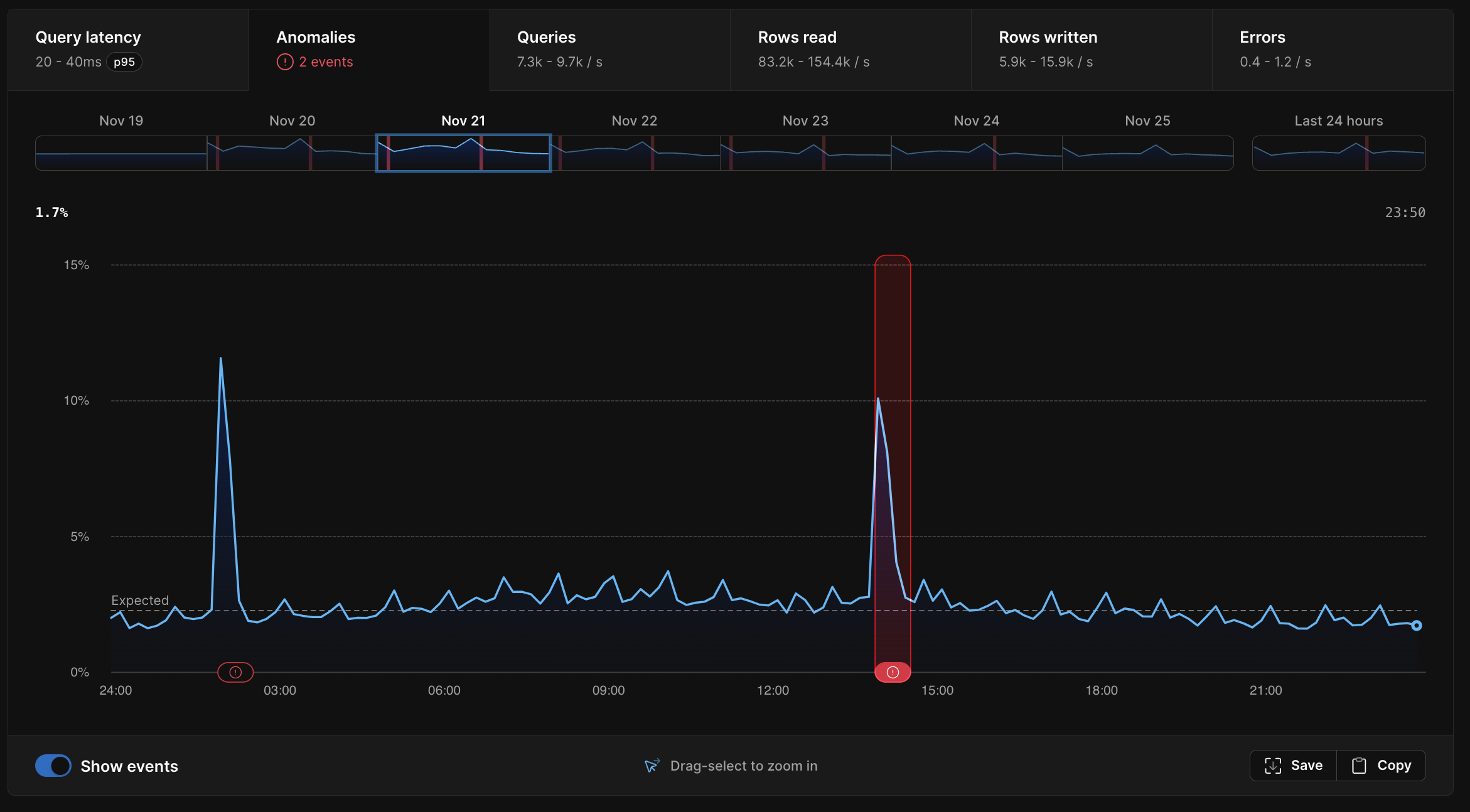
Any periods where your database was unhealthy (represented by large values in the graph) will be highlighted with a red icon representing a performance anomaly. Clicking on an anomaly will bring up a detailed view with pertinent information to help understand the causes of an anomaly.
Database health
You may wonder what “unhealthy” means in this context, and what quantity the database health graph represents. The anomaly graph shows the percentage of queries that were unusually slow. An “unusually slow” query is defined as having an execution time exceeding two standard deviations above the mean (also known as 2σ1 or the 97.7th percentile), for queries with the same pattern over the last week. To determine this threshold we perform the following steps:
- Aggregate query response time distribution by SQL fingerprint, and store a probabilistic sketch of that distribution in MySQL.
- Use the stored sketches to determine the 2σ threshold for each incoming query’s fingerprint over the last week.
- Count the number of incoming queries in each pattern that exceeded the threshold.
It’s worth examining why it’s necessary to go to the trouble of calculating the threshold on a per-query pattern basis, instead of using a more straightforward metric like a global latency percentile, as a proxy for database health2. By comparing each incoming query to the response time baseline for its specific query pattern, we can make an apples-to-apples comparison for each query pattern. Queries that have always been slow will only be considered in the anomaly calculation if they are substantially slower then they have been in the past. If the outlier percentage is elevated, we know that the same query patterns are now taking longer than they did over the last week. This provides a strong signal that the database is encountering a resource bottleneck, and does not result in false positives due to shifting database workloads.
In our experience observing this metric on internal PlanetScale databases, we’ve found it to be a reliable indicator of when we’re pushing a database beyond its limits.
Troubleshooting Anomalies
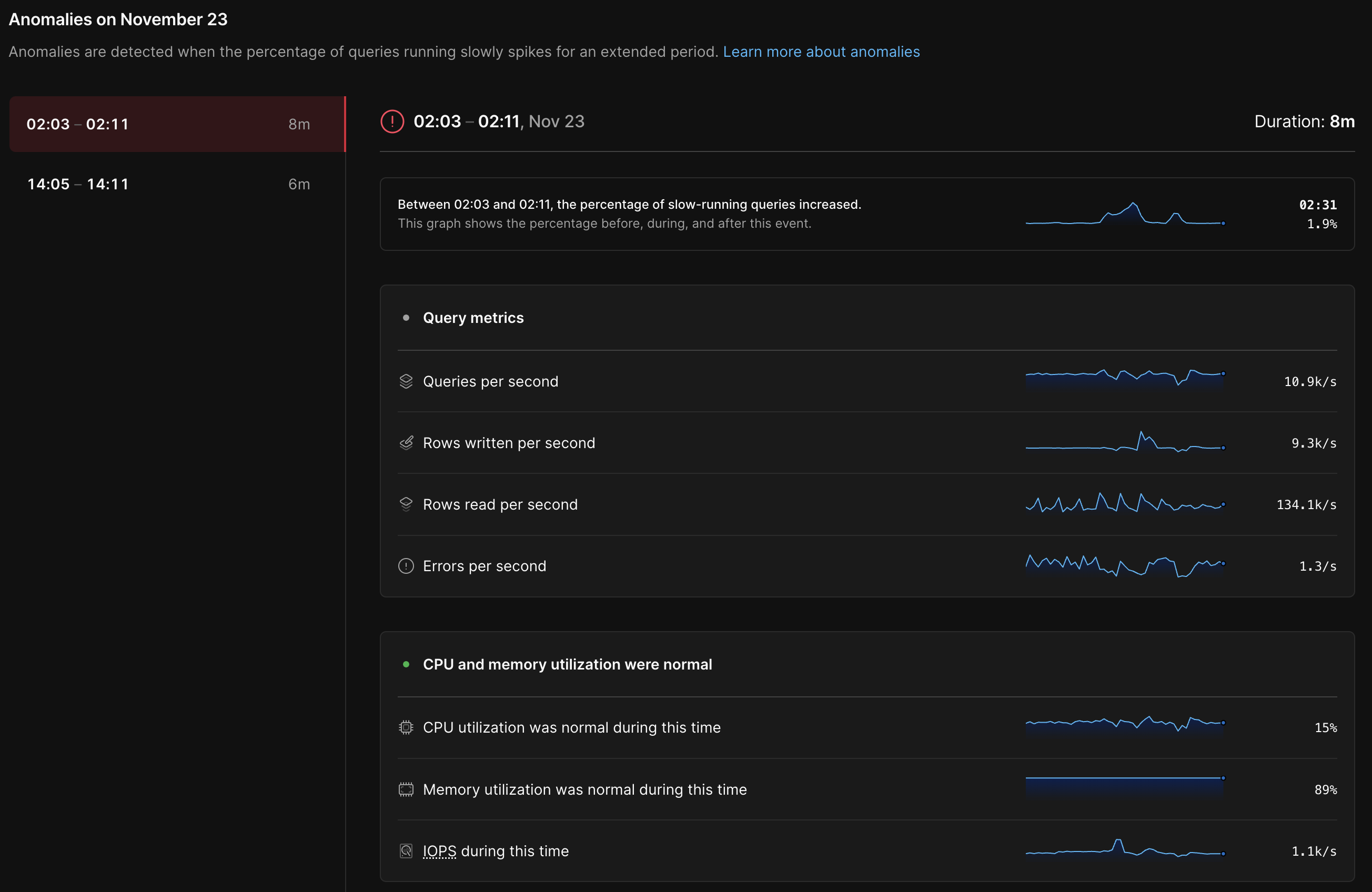
Determining when an anomaly is occurring (or not occurring) is a valuable capability in its own right. Still, it’s equally important to uncover the root causes. To make this easier, Insights lists relevant metrics for each anomaly. In particular, we show:
- High-level query metrics, such as the number of rows read and written per second
- Utilization metrics for the underlying database resources, such as CPU and disk usage (IOPS)
- A list of backups and deploy requests running when the anomaly occurred since these operations have the potential to consume shared resources
Seeing time series metrics side-by-side with overall database health before, during, and after the anomalous period often makes it very clear where the bottleneck is, as in this example, where there is an approximately 300% increase in rows written per second during the anomaly.
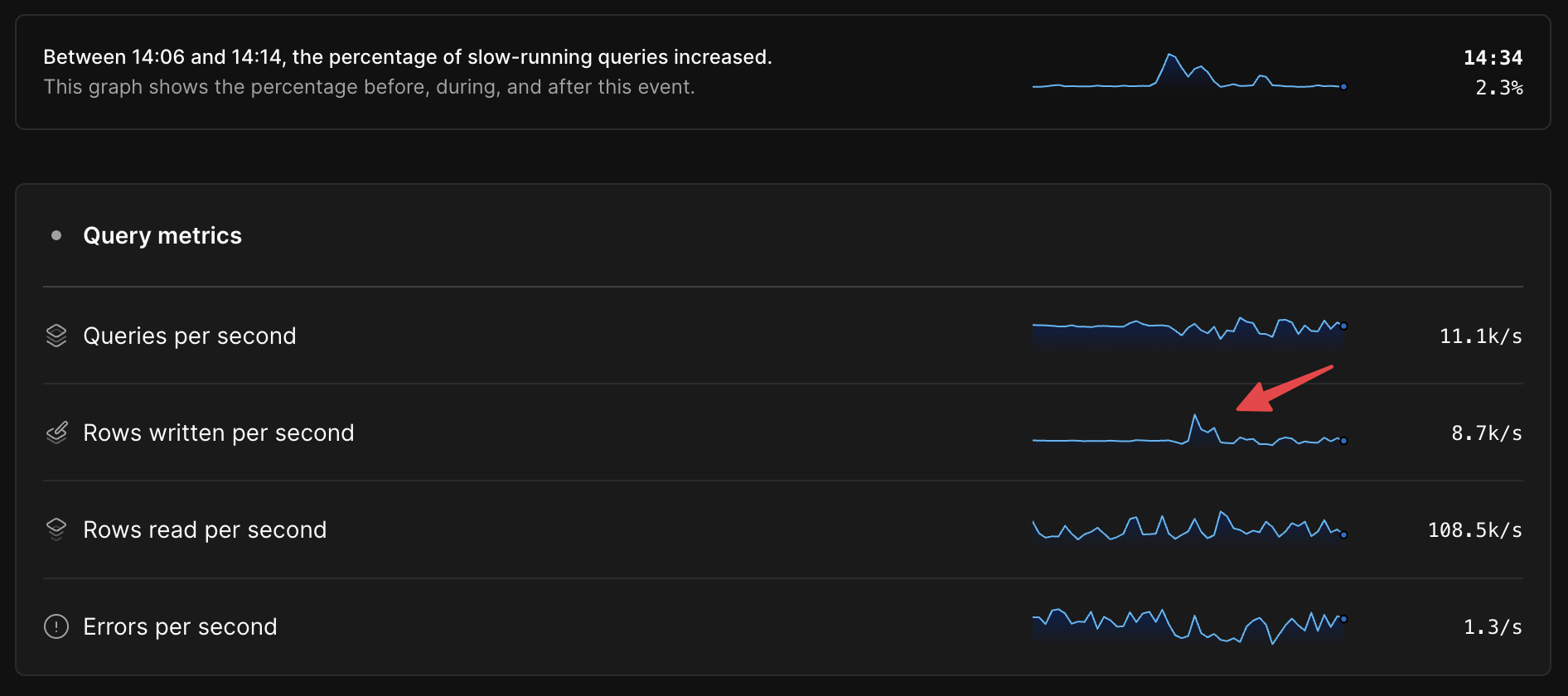
In some cases, we can go deeper than high-level aggregate metrics like reads/writes per second and tell you which specific query patterns are most likely to be at the root of an anomaly.
Because Insights records and stores exact query counts for 100% of your database’s query patterns, we can compare the execution rate of every query pattern with the overall database health metrics and identify highly correlated queries. In the example below we see an obvious correlation between the overall database health metric and the execution rate of an expensive query run intermittently by a background job.
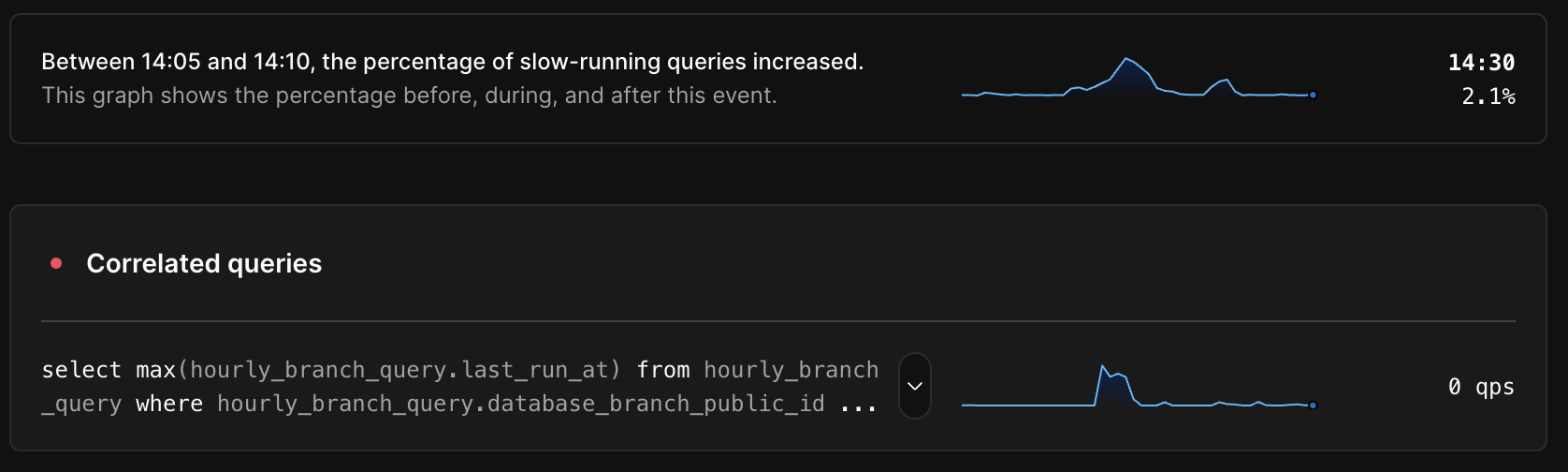
To find the correlated queries shown in an anomaly, we calculate the Pearson correlation coefficient between the execution rate for each query pattern and the overall database health metric during the anomaly plus a fixed window before and after. We then return the queries with the highest correlation coefficient. Not all anomalies have correlated queries, for example, those caused by running a backup on an under-provisioned database cluster, so we exclude results with a correlation coefficient below a certain threshold. When correlated queries are present, it can shave hours off the time it takes to find the root cause.
Try it today
All PlanetScale databases have access to the Anomalies tab in Insights today. You can read more in the PlanetScale Insights Anomalies documentation. User feedback helps us tune the system to improve accuracy, so please let us know about your experience, positive or not, by sharing on Twitter or contacting us.
- There’s nothing magical about 2σ or the 97.7th percentile. This value is used because it’s a fairly common choice for defining a statistical outlier.
- For a deeper dive on the motivations behind using 2σ outliers to gauge system health, check out this excellent talk from two Google engineers at SREcon22