For developers building out an application, a transactional datastore is the obvious and proven choice, but with success comes scale limitations. A monolithic database works well initially, but as an application sees growth, the size of its data will eventually grow beyond what is optimal for a single server.
Implementing read replicas can improve your performance but will likely add lag between your primary and your replicas, leading to performance or correctness issues for your application. These complexities can sometimes require major architectural changes, leading to a suboptimal user experience and difficult compromises, having to choose between application performance or data consistency. Scaling write traffic is even more challenging; for example, even the largest MySQL database will see performance issues at a certain point.
Horizontal sharding
This is not a new challenge; organizations have faced it for years, and horizontal sharding is one of the key patterns for solving it. Horizontal sharding refers to taking a single MySQL database and partitioning the data across several database servers, each with an identical schema. This spreads the workload of a given database across multiple database servers, which means you can scale linearly simply by adding more database servers as needed. Each of these servers is called a “shard.” Having multiple shards reduces the read and write traffic handled by a single database server and makes it possible to keep the data on a single database server at an optimal size. However, since you are dealing with multiple servers rather than one, this adds additional complexity to query routing and operational tasks like backup and restore, schema migration, and monitoring.
Vertical vs. horizontal scaling for MySQL databases
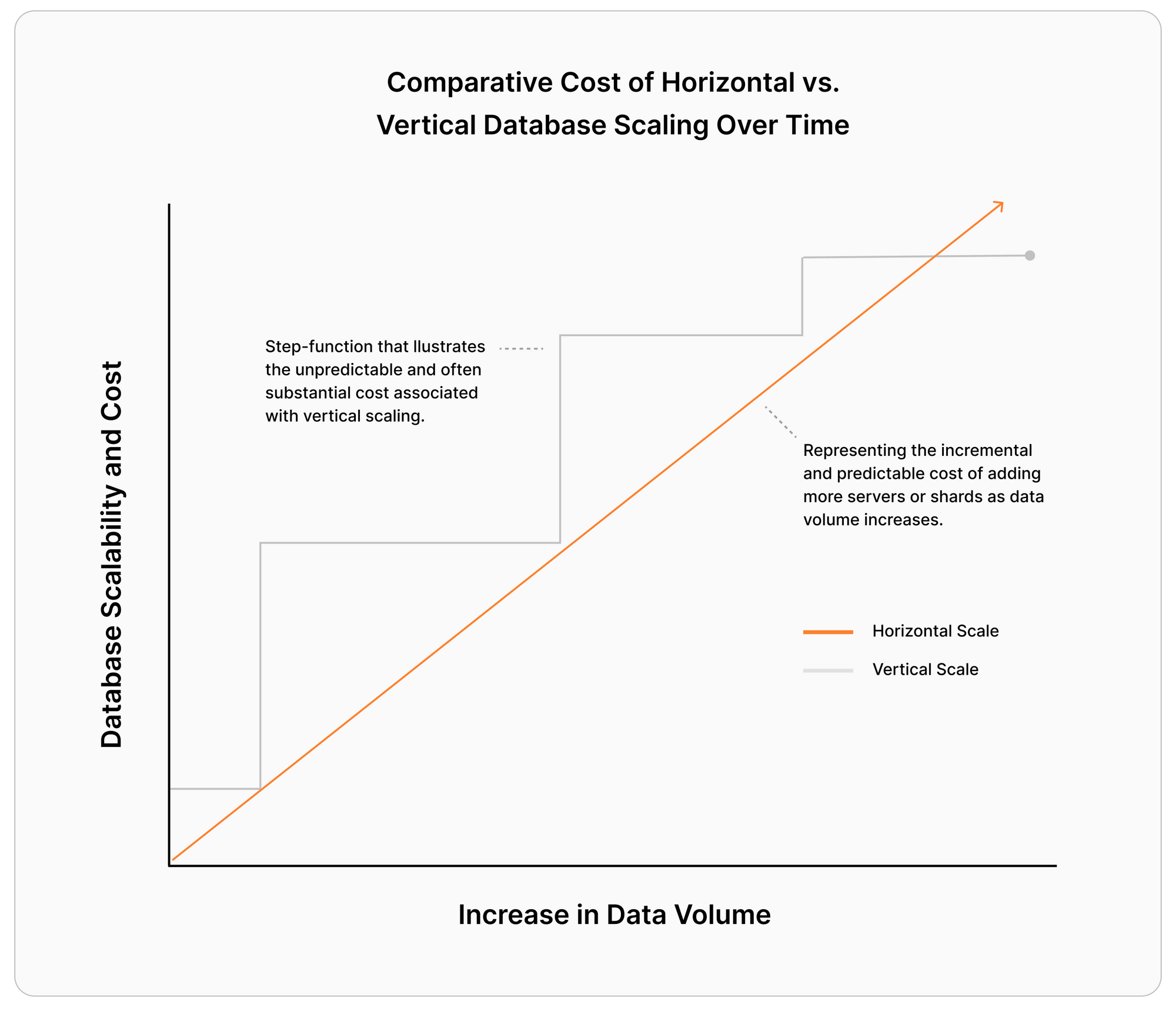
When you are first getting started, you are likely only vertically scaling your database by increasing the size of your cloud instance or buying bigger machines with more CPU cores, RAM, and other storage space available. This can improve the speed and capacity of your MySQL database, enabling it to handle more connections, execute queries faster, and scale up more effectively.
This seems great, but it’s the age-old short-term solution: just purchase more resources to make room for scale. There comes a point when there are more benefits to horizontally scaling your database for performance and cost reasons.
Cost of overprovisioning your database
It’s inefficient to make big leaps in hardware to overprovision for potential spikes in traffic or use. With this method, you will end up paying for resources that you don’t have an immediate need for just to prepare for anticipated spikes in traffic. Once you outgrow your current machine, the next you invest in could easily be 50% larger, while you really only end up using 10% of it.
When infrastructure costs no longer align with the business requirements due to constant over-provisioning, teams often explore horizontal scaling methods where, instead of adding more resources on a single instance, you add more instances to handle increasing workloads. This level of granularity enables you to add smaller hosts and invest in your infrastructure more efficiently.
The problems with sharding at the application layer
Some companies have implemented horizontal sharding at the application level. In this approach, all of the logic for routing queries to the correct database server lives in the application. This requires additional logic at the application level, which must be updated whenever a new feature is added. It also means that the application needs to implement cross shard features. Additionally, as data grows and the initial set of shards runs out of capacity, “resharding” or increasing the number of shards while continuing to serve traffic becomes a daunting operational challenge.
Pinterest took this approach after trying out the available NoSQL technology and determining that it was not mature enough at that time. Marty Weiner, a software engineer who worked on the project, noted, “We had several NoSQL technologies, all of which eventually broke catastrophically.” Pinterest mapped their data by primary key and used it to map data to the shard where it resided. Sharding in this way provided scale but traded off cross shard joins and the use of foreign keys. Similarly, Etsy took this approach when moving to a sharded database system but added a two-way lookup primary key to the shard_id and packed shards onto hosts, automating some of the work of managing shards. In both cases, however, ongoing management of shards, including splitting shards after the initial resharding, presented significant challenges.
From experiences like these, there is an increasing need to separate sharding logic from the application as it introduces a plethora of complexity, making the application and your database harder to manage, which, in turn, drains developer capacity and pulls your team away from building and improving on great products for your customer base.
Horizontal sharding with Vitess
Alongside sharding at the application layer, another approach to horizontal sharding emerged. Engineers at YouTube began building out the open source project Vitess in 2010. Vitess sits between the application and MySQL databases, allowing horizontally sharded databases to appear monolithic to the application. In addition to removing the complexity of query routing from the application, Vitess provides master failover and backup solutions that remove the operational complexity of a sharded system, as well as features like connection pooling and query rewriting for improved performance.
Companies like Square (read about their journey of sharding Cash app), Slack, JD.com, Hubspot, and many more have used Vitess to scale their MySQL databases. JD.com, one of the largest online retailers in China, saw 35 million queries per second (QPS) run through Vitess during a peak in traffic on Singles Day. Slack has migrated all their databases to Vitess, surviving the massive influx of traffic from the transition to work from home in 2020. Both Etsy and Pinterest have moved some of their workloads to Vitess because of the management benefits Vitess provides. Vitess has repeatedly demonstrated its ability to run in production against high workloads with a better experience than sharding at the application layer.
See Deepthi Sigireddi, a maintainer and tech lead for Vitess, talk more about Vitess features in an excerpt from a recent tech talk:
Watch the full recording of the Vitess talk here.
Using PlanetScale for MySQL sharding
“We wanted PlanetScale and Vitess to bring to MyFitnessPal what Kubernetes brought to application delivery and deployment. Databases are hard. We would rather PlanetScale manage them.”
However, running Vitess at scale still requires a whole engineering team with the right experience. Not all organizations have the depth that Slack and Square do. Because of this, PlanetScale democratizes many Vitess features and capabilities, including horizontal sharding, online schema migrations, and more. With PlanetScale, you can unlock all of the power of Vitess in a much shorter time and without all of the required expertise, risk, and potential errors that come with running it yourself. PlanetScale is the only MySQL-compatible database platform built on top of Vitess.
At PlanetScale, we’ve built a managed database platform offering both Postgres and Vitess databases. With Vitess, anyone can access this level of scale for their MySQL databases. You can start small with a single MySQL instance and scale up as you grow. When the time comes to horizontally shard, you’ll design a sharding scheme on top of your existing PlanetScale database; there is no need to change databases just because you need to scale. At the same time, you gain the benefits of the PlanetScale database platform with features like database branching, safe and non-blocking schema changes, schema reverts, built-in query performance analytics with Insights, and much more alongside the benefits of Vitess.
This blog post was initially posted on October 22, 2020. We have updated it with updated information.