Our product design process is more lightweight and collaborative than many companies. We don’t have a rigid set of rules we follow. We don’t have product managers. We do just enough design exploration work to feel confident in the direction. Perhaps most interestingly, we don’t do design “handoffs” — we code right alongside the engineers on our teams.
Keeping planning light
Our company roadmap is determined by our leadership team working in tandem with engineering and product design. This is a mix of work that furthers the company’s vision, exposes more of the power of Vitess, and addresses customer feedback. These projects are prioritized and product design begins exploring possible solutions. For larger or less-defined features, sketches on paper or iPad are usually the most efficient way to start focusing in on the preferred direction.

Low-fidelity sketches of deploy requests and schema reverts
Starting with a prototype
Once a direction starts to become clear, we move into high-fidelity mockups in Figma. Sometimes it’s helpful to experiment with a specific element in Codepen. For more intricate user flows, we’ve found it useful to build prototypes in Figma to share with team members. With Figma’s prototyping features, it’s easy to create a realistic UX complete with long-running processes, state changes, and UI transitions. Designers can even observe others while they navigate through a prototype, often revealing friction points needing smoothed out.
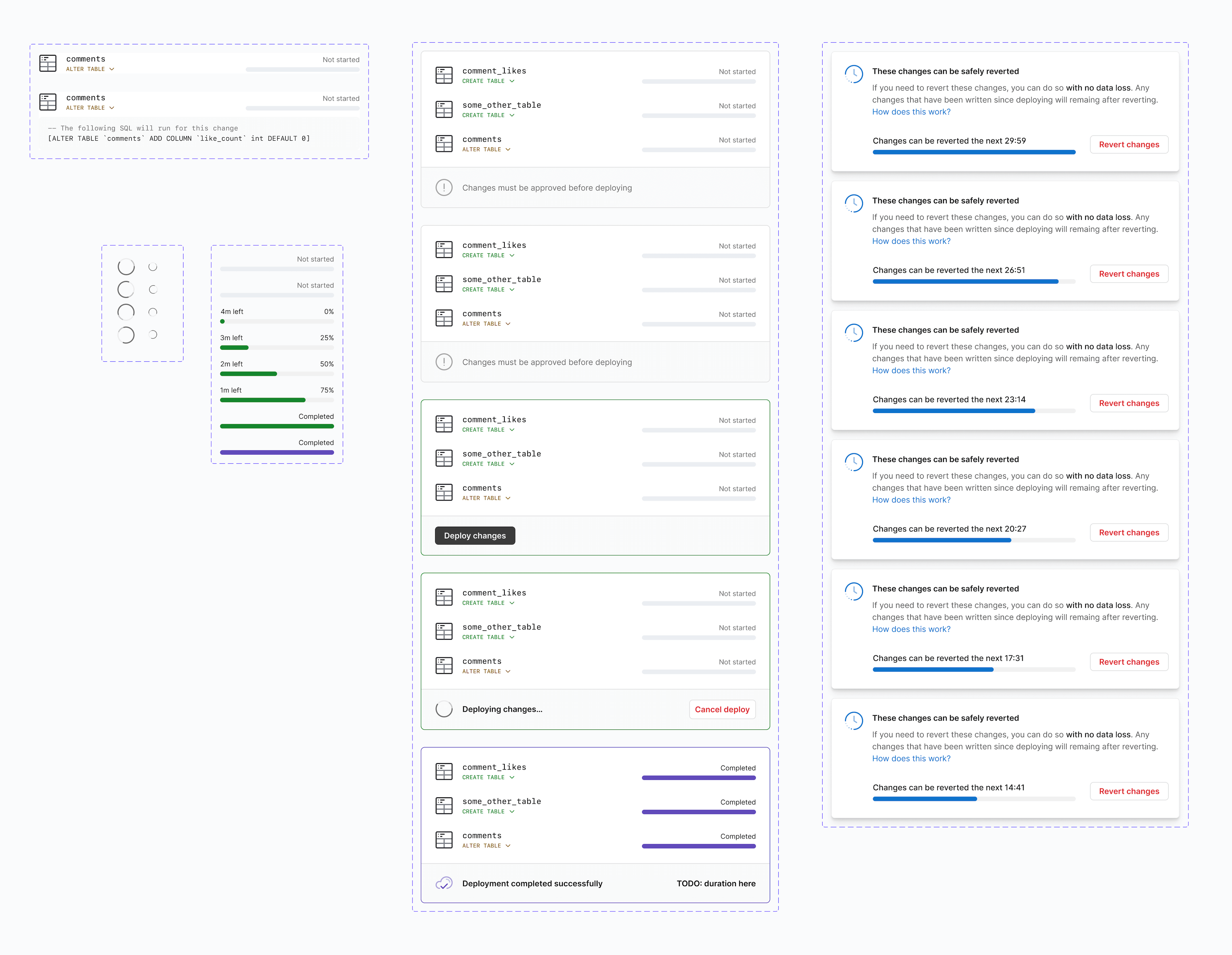
Getting to code quickly
We don’t spend time mocking up every possible UI state. If everyone involved is feeling comfortable with the core parts of the design, we move into code and continue refining the UI there. From here on out, the process is a close collaboration with the engineering team. Our product designers are able to write HTML/JSX and CSS and we can help build out basic components in our Next.js/Typescript application. We try to address all of the structural and styling pieces, leaving the engineers with something as close to fill-in-the-blanks as possible.
return (
<>
{true /* TODO: if anything in deploy queue */ && (
<div className='rounded-b border-t px-3 py-2'>
<p>
{true /* TODO: if queue length = 1 */ && <>There is a deployment queued to deploy</>}
{false /* TODO: if queue length > 1 */ && (
<>There are {/* TODO: queue length */} deployments queued to deploy</>
)}
({/* TODO: loop over queue, comma-separate links */}
<Link href={/* TODO: DR link */}>
<a>#{/* TODO: DR number */}</a>
</Link>)
</p>
</div>
)}
</>
)
Annotating TODOs in a React component
We will often kick off feature development by adding the necessary feature flags and checks to the API and front-end. These flags allow us to enable new features for specific people and teams. Later, the entire company and early-access customers can be included before shipping to everyone.
Our employees have a high level of trust with each other and the autonomy to decide how best to approach a problem, implement a solution, and ship it. Because our product designers can code, we can avoid the standard handoff process. In our experience, this results in less friction between teams and a better product for our customers.