Any good DBA will tell you to "select only what you need." It's one of the most common aphorisms, and for good reason! We don't ever want to select data that we're just going to throw away. One way this advice manifests itself is to not use SELECT * if you don't need all the columns. By limiting the columns returned, you're selecting only what you need.
Pagination is another way to "select only what you need." Although, this time, we're limiting the rows instead of the columns. Instead of pulling all the records out of the database, we only pull a single page that we're going to show to the user.
There are two primary ways to paginate in MySQL: offset/limit and cursors. Which method you choose depends on your use case and your application's requirements. Neither is inherently better than the other. They each have their own strengths and weaknesses.
The importance of deterministic ordering
Before we talk about the wonders of pagination, we need to talk about deterministic ordering. When your query is ordered deterministically, it means that MySQL has enough information to order your rows in the exact same way every single time. If you sort your rows by a column that is not unique, MySQL gets to decide which order to return these rows in. Let's look at an example.
Given this table full of people named Aaron:
| id | first_name | last_name |
|----|------------|-----------|
| 1 | Aaron | Francis |
| 2 | Aaron | Smith |
| 3 | Aaron | Jones |
Let's run a query to order those people by their first name:
SELECT
*
FROM
people
ORDER BY
first_name
Because all three people have the same first name, MySQL gets to decide which order to return the rows in! Depending on certain factors, the order may change. This is because the ordering is not deterministic enough.
This result set is valid because it is ordered by first_name:
| id | first_name | last_name |
|----|------------|-----------|
| 2 | Aaron | Smith |
| 1 | Aaron | Francis |
| 3 | Aaron | Jones |
But so is this result set, because it also is ordered by first_name:
| id | first_name | last_name |
|----|------------|-----------|
| 3 | Aaron | Jones |
| 2 | Aaron | Smith |
| 1 | Aaron | Francis |
We haven't given MySQL specific enough instructions to produce a deterministically ordered set of results. We've asked it to order the rows by first_name, and it has dutifully complied, but it may not put them in the same order every time.
The easiest way to produce deterministic ordering is to order by a unique column because every value will be distinct, and MySQL will have no choice but to return the rows in the same order every time. Of course, that's not very helpful if you need to order by a column that's not unique! In that case, appending a unique column to your ordering does the trick. In most cases, simply adding the id is the best way to go.
SELECT
*
FROM
people
ORDER BY
first_name, id -- Add ID to ensure deterministic ordering
Now MySQL knows that when given two first_name values that are the same, it should then look at the id column to determine the order. This is deterministic ordering, and it's a prerequisite to effective pagination.
Offset/limit pagination is likely the most common way to paginate in MySQL because it's the easiest to implement. With offset/limit pagination, we're taking advantage of two SQL keywords: OFFSET and LIMIT. The LIMIT keyword tells MySQL how many rows to return, while OFFSET tells MySQL how many rows to skip over.
SELECT
*
FROM
people
ORDER BY
first_name, id
LIMIT
10 -- Only return 10 rows
OFFSET
10 -- Skip the first 10 rows
In this example, we're selecting all the people from the people table, ordering them by first_name and id, and then limiting the result set to 10 rows. We're also skipping the first 10 rows, returning rows 11-20.
To construct an offset/limit query, you need to know the page size and the page number. The page size is how many records you want to show per page, and the page number is what page you want to show. The LIMIT is determined by the page size, and the OFFSET is determined by both the page size and the page number.
To calculate the correct offset, multiply the page_number - 1 by the page_size. This ensures that when your user is on the first page, the offset calculates to 0, meaning you're not skipping any rows.
SELECT
*
FROM
people
ORDER BY
first_name, id
LIMIT
10 -- page_size
OFFSET
10 -- (page_number - 1) * page_size
One of the great strengths of offset/limit pagination is that it's easy to implement and easy to understand. It doesn't require tracking any state over time; each request can stand alone. It doesn't matter what pages the user has visited before. The query construction is always the same. The math is simple. The query is simple.
Another strength of this method is that pages are directly addressable. Users who want to navigate from page 1 directly to page 10 can do so quite easily, provided your interface exposes page links. (This is not the case with cursor pagination.) Convincing arguments have been made that directly addressable pages shouldn't ever be exposed to users because they have no semantic meaning. For example, what does page 84 mean? Why not just expose "next" and "back" buttons? That's a decision that you'll have to make for your application! Many users are used to seeing directly addressable page numbers, and it can be helpful to skip several pages ahead instead of one page at a time. It's up to you to decide what's best for your application, but if you need directly addressable pages, you will need to use offset/limit pagination.
Offset/limit pagination and drifting pages
One weakness of offset/limit pagination is that pages can drift. This is true of cursor-based pagination as well, but it's more likely to happen with offset/limit pagination.
Let's look at an example in which your user is viewing page one with ten records. The last person they see on this page is "Judge Bins." They don't see her yet, but "Sonya Dickens" should be the first person on page 2.
| id | first_name | last_name |
|----|------------|-----------|
| 1 | Phillip | Yundt |
| 2 | Aaron | Francis |
| 3 | Amelia | West |
| 4 | Jennifer | Becker |
| 5 | Macy | Lind |
| 6 | Simon | Lueilwitz |
| 7 | Tyler | Cummerata |
| 8 | Suzanne | Skiles |
| 9 | Zoe | Hill |
| 10 | Judge | Bins |
|----|------------|-----------| Page break
| 11 | Sonya | Dickens |
| 12 | Hope | Streich |
| 13 | Kristian | Kerluke |
| 14 | Stanton | Fisher |
| 15 | Rasheed | Little |
| 16 | Deron | Koss |
| 17 | Trevor | Daniel |
| 18 | Vernie | Friesen |
| 19 | Jody | Littel |
| 20 | Jorge | Nienow |
While your user is viewing the page, the person with the id of 2 (Aaron Francis) is deleted.
| id | first_name | last_name |
|----|------------|-----------|
| 1 | Phillip | Yundt |
| 3 | Amelia | West |
| 4 | Jennifer | Becker |
| 5 | Macy | Lind |
| 6 | Simon | Lueilwitz |
| 7 | Tyler | Cummerata |
| 8 | Suzanne | Skiles |
| 9 | Zoe | Hill |
| 10 | Judge | Bins |
| 11 | Sonya | Dickens | <-- Sonya is now on page one!
|----|------------|-----------| Page break
| 12 | Hope | Streich | <-- This is now the first person on page two
| 13 | Kristian | Kerluke |
| 14 | Stanton | Fisher |
| 15 | Rasheed | Little |
| 16 | Deron | Koss |
| 17 | Trevor | Daniel |
| 18 | Vernie | Friesen |
| 19 | Jody | Littel |
| 20 | Jorge | Nienow |
| 21 | Mara | Grady |
The user navigates to page two, and the first person they see is Hope Streich. Because we're naively skipping over the first ten rows, Sonya Dickens has been skipped altogether. Sorry Sonya. Your user never sees her unless they navigate back to page one.
Paginating ever-changing data is not an easy problem to solve, and this may be an acceptable tradeoff for you. Even cursor-based pagination is prone to some of these movements, but it's less likely to happen.
The way that the OFFSET keyword works is that it discards the first n rows from the result set. It doesn't simply skip over them. Instead, it reads the rows and then discards them. This means that as you work into deeper and deeper pages of your result set, the performance of your query will degrade. This is because the database must read and discard more rows as you move through the result set.
Very deep pages can take multiple seconds to load. This is a big issue with offset/limit pagination, and it's one reason cursor-based pagination is so popular. Cursor-based pagination doesn't have this performance drawback because it doesn't use the OFFSET keyword.
There is a technique known as a "deferred join" that can optimize offset/limit pagination.
The deferred join technique is an optimization solution that enables more efficient pagination. It performs the pagination on a subset of the data instead of the entire table. This subset is generated by a subquery, which is joined with the original table later. The technique is called "deferred" because the join operation is postponed until after the pagination is done.
SELECT * FROM people
INNER JOIN (
-- Paginate the narrow subquery instead of the entire table
SELECT id FROM people ORDER BY first_name, id LIMIT 10 OFFSET 450000
) AS tmp USING (id)
ORDER BY
first_name, id
This technique has been widely adopted, and there are libraries available for popular web frameworks such as Rails (FastPage) and Laravel (Fast Paginate).
Here is a graph showing the performance of a deferred join vs. the standard offset/limit pagination method, taken from our blog post introducing the FastPage Rails gem.
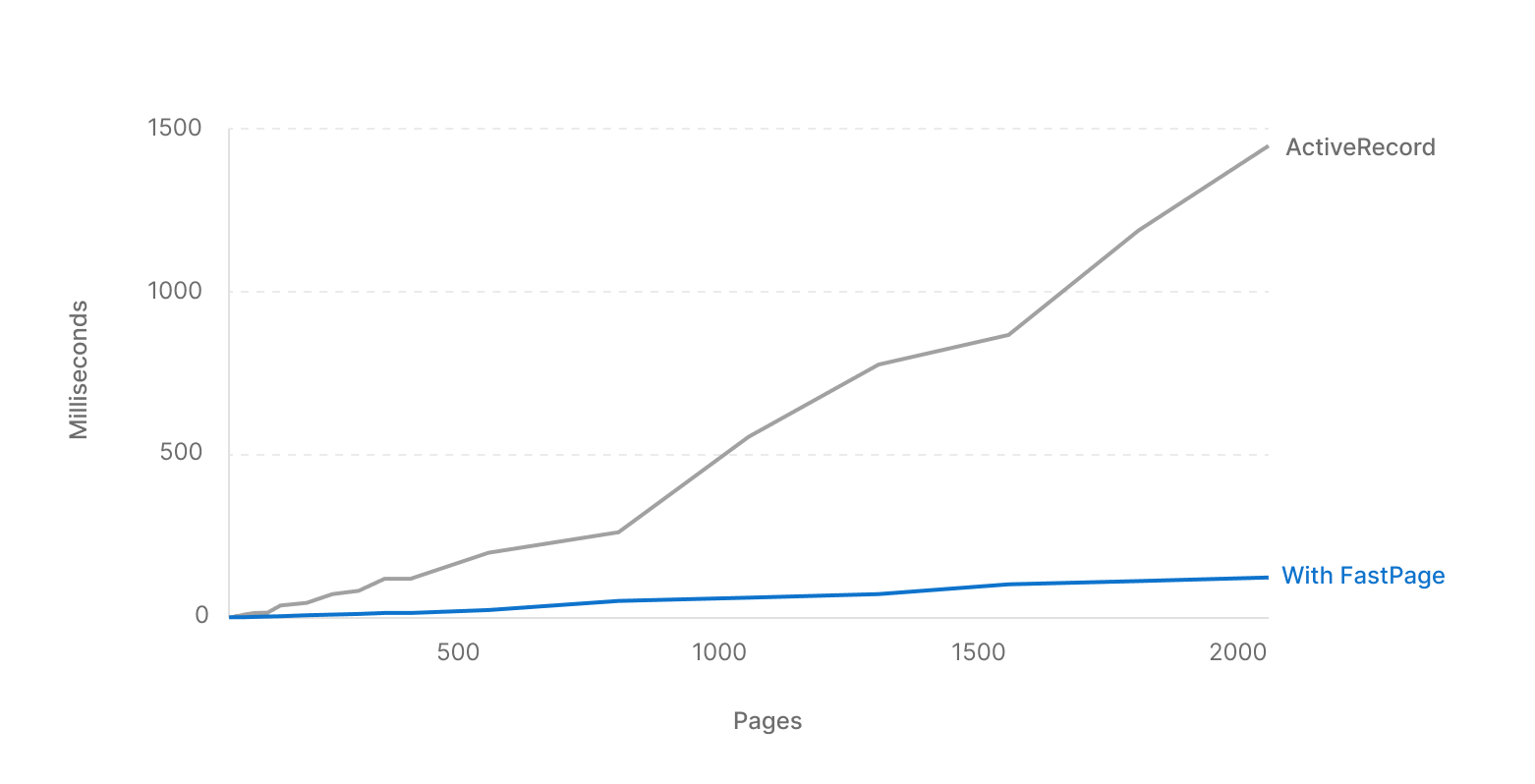
As you can see, the deferred join method is much faster than the standard offset/limit pagination method, especially for deeper pages.
If you do decide that offset/limit is the right choice for your application, then you should consider using a deferred join technique to optimize your queries.
Now that we're thoroughly versed on the offset/limit method let's talk about cursor-based pagination. Cursor-based pagination is a method of pagination that uses a "cursor" to determine the next page of results. It's important to note that this differs from a database cursor, which is a different concept. When discussing cursors in the context of pagination, we're using the word to mean a pointer, an identifier, a token, or a locator.
The idea behind cursor-based pagination is that you have a cursor that points to the last record that the user saw. When the user requests the next page of results, they must send along the cursor, which we use to determine where to start the next page of results.
Instead of using the OFFSET keyword, we use the cursor to construct a WHERE clause that filters out all the rows that the user has already seen.
Let's start with a simple example. Let's say we have a table of people and want to paginate the results by the id. When the user requests the first page of results, there is no cursor, so we return the first ten rows.
SELECT
*
FROM
people
ORDER BY
id
LIMIT
10
MySQL returns the following result set:
| id | first_name | last_name |
|----|------------|-----------|
| 1 | Phillip | Yundt |
| 2 | Aaron | Francis |
| 3 | Amelia | West |
| 4 | Jennifer | Becker |
| 5 | Macy | Lind |
| 6 | Simon | Lueilwitz |
| 7 | Tyler | Cummerata |
| 8 | Suzanne | Skiles |
| 9 | Zoe | Hill |
| 10 | Judge | Bins |
Here is where cursor and offset-based pagination begin to diverge. With cursor-based pagination, we must construct and send the cursor out to the frontend. The cursor is a pointer to the last record that the user has seen. Since we are only sorting by id, the cursor is the id of the last record in the result set. Usually, it would be base64 encoded, but for simplicity, we'll just leave it unencoded.
The backend sends out the results and a cursor of id=10, usually called next_page or something similar.
{
"next_page": "(id=10)",
"records": [
// ...
]
}
When the user requests the next page of results, they must return the cursor to the server. The cursor is used to construct a WHERE clause that filters out all the rows the user has already seen.
SELECT
*
FROM
people
WHERE
id > 10 -- The last id that the user saw was 10, so we start at the next id after 10
ORDER BY
id
LIMIT
10
You can see that in this query, we're not using the OFFSET keyword at all, but instead, we're jumping straight to the next record after the last record that the user saw. This is the key difference between cursor and offset-based pagination!
It gets a bit more complicated if we go back to our original example of sorting by first_name and then id. Since we're sorting by both columns, the cursor must contain both values for the last record that the user has seen.
Let's take this example set of records, which is 20 people sorted by first name, and then ID.
| id | first_name | last_name |
|-------|------------|------------|
| 2 | Aaron | Francis |
| 589 | Aaron | Streich |
| 3896 | Aaron | Corkery |
| 8441 | Aaron | Kreiger |
| 9179 | Aaron | Wolf |
| 10970 | Aaron | Reichert |
| 13082 | Aaron | Collier |
| 13704 | Aaron | Braun |
| 19399 | Aaron | Watsica |
| 25995 | Aaron | Runte |
|-------|------------|------------| Page break
| 26794 | Aaron | Mayer |
| 32075 | Aaron | Hahn |
| 32471 | Aaron | Bahringer |
| 40612 | Aaron | Abbott |
| 41202 | Aaron | Willms |
| 41571 | Aaron | Nienow |
| 46556 | Aaron | Glover |
| 48501 | Aaron | Boyle |
| 50628 | Aaron | Schmeler |
| 51656 | Aaron | Williamson |
In this case, the last record the user sees on page 1 has an id of 25995. This information alone is not enough for the cursor! We must also add the first_name since it is part of the sort order. The cursor for the last record on page 1 is (first_name=Aaron, id=25995).
When the user sends back the cursor, we can construct a WHERE clause that filters out all the rows the user has already seen. This time, it requires a little more thought because we're sorting by two columns. We'll add a first_name filter to show any names after "Aaron," but since first_name has many duplicates, we'll also add an id filter to show any "Aaron"s that have an id after the last id that the user saw.
SELECT
*
FROM
people
WHERE
(
(first_name > 'Aaron') -- Names after Aaron
OR
(first_name = 'Aaron' AND id > 25995) -- Aarons, but after the last id that the user saw
)
ORDER BY
first_name, id
LIMIT
10
As you add more columns to the sort order, you'll need to add more filters to the WHERE clause.
As you've seen, cursor-based pagination is more complicated to implement than offset-based pagination. Constructing the cursor and the WHERE clause requires more thought. You also have to keep track of that little piece of state: the cursor. This isn't inherently bad, and not all complexity is reducible, but it's something to keep in mind. Most frameworks have cursor-based pagination built in, so you may not have to implement it manually.
Another drawback to cursor-based pagination is that it's impossible to address a specific page directly. For instance, if the requirement is to jump directly to page five, it's not possible to do so since the pages themselves are not explicitly numbered, and there is no way to create a cursor without knowing the last record that has been seen. You can only navigate to the next page.
One of the advantages of cursor-based pagination is its resilience to shifting rows. For example, if a record is deleted, the next record that would have followed is still displayed since the query is working off of the cursor rather than a specific offset.
Let's go back to our Sonya Dickens example. The last person they see on this page is "Judge Bins." They don't see her yet, but "Sonya Dickens" should be the first person on page 2.
| id | first_name | last_name |
|----|------------|-----------|
| 1 | Phillip | Yundt |
| 2 | Aaron | Francis |
| 3 | Amelia | West |
| 4 | Jennifer | Becker |
| 5 | Macy | Lind |
| 6 | Simon | Lueilwitz |
| 7 | Tyler | Cummerata |
| 8 | Suzanne | Skiles |
| 9 | Zoe | Hill |
| 10 | Judge | Bins | <-- The cursor points here
|----|------------|-----------| Page break
| 11 | Sonya | Dickens |
| 12 | Hope | Streich |
| 13 | Kristian | Kerluke |
| 14 | Stanton | Fisher |
| 15 | Rasheed | Little |
| 16 | Deron | Koss |
| 17 | Trevor | Daniel |
| 18 | Vernie | Friesen |
| 19 | Jody | Littel |
| 20 | Jorge | Nienow |
While they are viewing page one, "Aaron Francis" is deleted.
| id | first_name | last_name |
|----|------------|-----------|
| 1 | Phillip | Yundt |
| 3 | Amelia | West | <-- Aaron Francis is deleted
| 4 | Jennifer | Becker |
| 5 | Macy | Lind |
| 6 | Simon | Lueilwitz |
| 7 | Tyler | Cummerata |
| 8 | Suzanne | Skiles |
| 9 | Zoe | Hill |
| 10 | Judge | Bins | <-- The cursor *still* points here
|----|------------|-----------| Page break
| 11 | Sonya | Dickens | <-- Sonya is the first person after the cursor
| 12 | Hope | Streich |
| 13 | Kristian | Kerluke |
| 14 | Stanton | Fisher |
| 15 | Rasheed | Little |
| 16 | Deron | Koss |
| 17 | Trevor | Daniel |
| 18 | Vernie | Friesen |
| 19 | Jody | Littel |
| 20 | Jorge | Nienow |
This time, it doesn't matter! The cursor points to the last record that the user saw, and the next record is still Sonya Dickens. We tell the database, "the last record I saw was ID 10, and I want to see the next ten records." The database doesn't care that some records were deleted. It just knows that the next record is Sonya Dickens.
This is true even if the cursor is pointing to a record that was deleted. If the cursor points to a record that was deleted, we're still telling the database, "the last record I saw was ID 10, and I want to see the next ten records." Again, the database doesn't care that the record was deleted. It just knows that the next record is Sonya Dickens.
Cursor-based pagination can be much more performant than offset/limit simply because it accesses much less data. Instead of generating a result set and throwing away everything before the offset, the database can start at the offset and return the next N records. This is especially true if the offset is large. You will need to consider a proper indexing strategy to ensure the database can efficiently find the necessary records.
Conclusion
Pagination is a common requirement for almost every web application or API. Now you understand the different types of pagination and the tradeoffs that come with each.
Offset/limit is nice because it's easy to implement and understand, and you can directly address pages. Some downsides are that it can be slower as you navigate deeper into the pages, and it is more prone to drift.
Cursor-based pagination is nice because it is more performant and more resilient to shifting rows. Some of the downsides are that it is more complicated to implement, and you cannot directly address pages.
Which method you choose is up to you, but hopefully, this article has given you a better understanding of the tradeoffs, and you can now make an informed decision.