参考自《安富莱STM32-V4开发板RTX教程》
RTX 操作系统的配置工作是通过配置文件 RTX_Conf_CM.c 实现。在 MDK 工程中打开文件RTX_Conf_CM.c,可以看到如下图所示的工程配置向导:
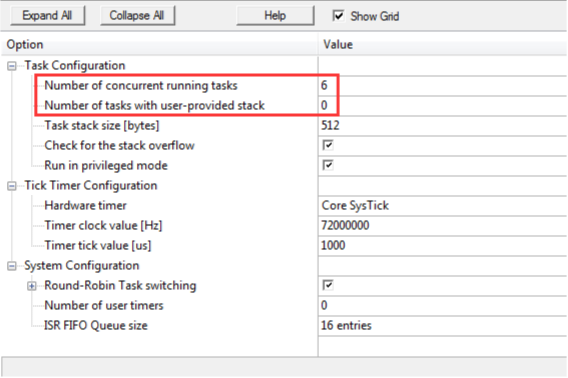
用于任务配置的主要是如下两个参数:
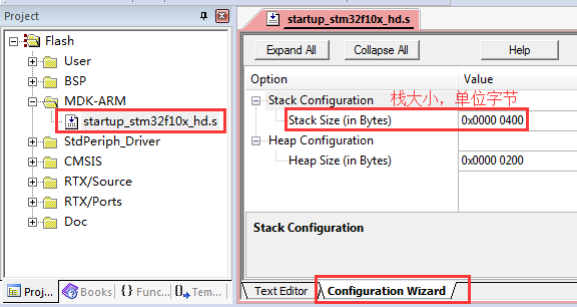
不管是裸机编程还是 RTOS 编程,栈的分配大小都非常重要。局部变量,函数调时现场保护和返回地址,函数的形参,进入中断函数前和中断嵌套等都需要栈空间,栈空间定义小了会造成系统崩溃。 裸机的情况下,用户可以在这里配置栈大小:
不同于裸机编程,在 RTOS 下,每个任务都有自己的栈空间。任务的栈大小可以在配置向导中通过如下参数进行配置:
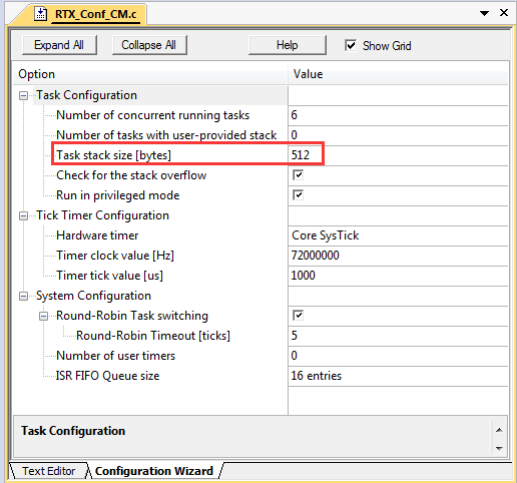
需要大家注意的是,默认情况下用户创建的任务栈大小是由参数 Task stack size 决定的。如果觉得每个任务都分配同样大小的栈空间不方便的话,可以采用自定义任务栈的方式创建任务。采用自定义方式更灵活些。
在 RTOS 下,上面两个截图中设置的栈大小有了一个新的名字叫系统栈空间,而任务栈是不使用这里的空间的。任务栈不使用这里的栈空间,哪里使用这里的栈空间呢?答案就在中断函数和中断嵌套。
由于 Cortex-M3 和 M4 内核具有双堆栈指针,MSP 主堆栈指针和 PSP 进程堆栈指针,或者叫 PSP任务堆栈指针也是可以的。
在 RTX 操作系统中,主堆栈指针 MSP 是给系统栈空间使用的,进程堆栈指针 PSP 是给任务栈使用的。
也就是说,在 RTX 任务中,所有栈空间的使用都是通过 PSP 指针进行指向的。
一旦进入了中断函数已经可能发生的中断嵌套都是用的 MSP 指针。
这个知识点要记住他,当前可以不知道这是为什么,但是一定要记住。
实际应用中系统栈空间分配多大,主要是看可能发生的中断嵌套层数,下面我们就按照最坏执行情况进行考虑,所有的寄存器都需要入栈,此时分为两种情况:
64字节
对于 Cortex-M3 内核和未使用 FPU(浮点运算单元)功能的 Cortex-M4 内核在发生中断时需
要将 16 个通用寄存器全部入栈,每个寄存器占用 4 个字节,也就是 16*4 = 64 字节的空间。
可能发生几次中断嵌套就是要 64 乘以几即可。当然,这种是最坏执行情况,也就是所有的寄存
器都入栈。
(注:任务执行的过程中发生中断的话,有 8 个寄存器是自动入栈的,这个栈是任务栈,进入中
断以后其余寄存器入栈以及发生中断嵌套都是用的系统栈)。
200字节
对于具有 FPU(浮点运算单元)功能的 Cortex-M4 内核,如果在任务中进行了浮点运算,那么
在发生中断的时候除了 16 个通用寄存器需要入栈,还有 34 个浮点寄存器也是要入栈的,也就是
(16+34)*4 = 200 字节的空间。当然,这种是最坏执行情况,也就是所有的寄存器都入栈。
(注:任务执行的过程中发送中断的话,有 8 个通用寄存器和 18 个浮点寄存器是自动入栈的,
这个栈是任务栈,进入中断以后其余通用寄存器和浮点寄存器入栈以及发生中断嵌套都是用的系
统栈。)。
使用如下任一函数即可实现RTX的初始化:
void os_sys_init_user (
void (*task)(void), /* 任务函数 */
U8 priority, /* 任务优先级 (1-254) */
void* stack, /* 任务栈 */
U16 size); /* 任务栈大小,单位字节*/
函数 os_sys_init_user 用于实现 RTX 操作系统的初始化和启动任务的创建,并且使用这个函数做初始化还可以自定义任务栈的大小。
使用这个函数要注意以下几个问题
使用如下四个函数中任一函数即可实现RTX的任务创建:
重点解释os_tsk_crete_user函数:
OS_TID os_tsk_create_user(
void (*task)(void), /* 任务函数 */
U8 priority, /* 任务优先级 (1-254) */
void* stk, /* 任务栈*/
U16 size ); /* 任务栈大小*/
函数 os_tsk_create_use 用于实现 RTX 操作系统的任务创建,并且还可以自定义任务栈的大小。
使用这个函数要注意以下问题
使用如下四个函数中任一函数即可实现RTX的任务删除:
OS_RESULT os_tsk_delete (
OS_TID task_id ); /* 任务 ID */
函数 os_tsk_delete 用于实现 RTX 操作系统的任务删除
使用这个函数要注意以下问题
通过如下函数可设置任务优先级:
OS_RESULT os_tsk_prio (
OS_TID task_id, /* 任务 ID */
U8 new_prio ); /* 新的任务优先级 (1-254) */
函数 os_tsk_prio 用于修改任务的优先级。
**使用这个函数要注意以下几个问题 **
对于使用 Cortex-M3 或者 M4 内核的芯片来说,RTX 操作系统可以让任务运行在特权级或者非特权级模式,这两种模式是 M3 或者 M4 内核本身所具有的特性。
在特权级模式下,用户可以访问和配置系统控制寄存器,比如 NVIC 中断控制器。然而,如果是在非特权级模式下,系统控制寄存器是不允许访问的,一旦访问将导致硬件异常。
主要有以下两种方法进行初始化:
深入了解 Cortex-M3/M4 内核的特权等级就不得不说说两种操作模式,Cortex-M3/M4 支持两种操作模式,两种操作模式分别是:
| 特权级 | 非特权级(用户级) | |
|---|---|---|
| 异常handler的代码 | handler | 错误的模式 |
| 主应用程序的代码 | 线程模式 | 线程模式 |
中断和异常的区别
在 ARM 编程领域中,凡是打断程序顺序执行的事件,都被称为异常(exception)。
除了外部中断外, 当有指令执行了“非法操作”, 或者访问被禁的内存区间, 因各种错误产生的 fault, 以及不可屏蔽中断发生时,都会打断程序的执行,这些情况统称为异常。在不严格的上下文中,异常与中断也可以混用。
另外,程序代码也可以主动请求进入异常状态的( 常用于系统调用)。
当处理器处在线程状态下时,既可以使用特权级,也可以使用用户级;另一方面,handler 模式总是特权级的。在系统复位后,处理器进入线程模式+特权级。
在特权级下的代码可以通过置位 CONTROL[0]来进入用户级。而不管是任何原因产生了任何异常,处理器都将以特权级来运行其服务例程,异常返回后,系统将回到产生异常时所处的级别。用户级下的代码不能再试图修改 CONTROL[0]来回到特权级。它必须通过一个异常 handler,由那个异常 handler 来修改CONTROL[0],才能在返回到线程模式后拿到特权级。
为了避免系统堆栈因应用程序的错误使用而毁坏,我们可以给应用程序专门配一个堆栈,不让它共享操作系统内核的堆栈。在这个管理制度下,运行在线程模式的用户代码使用 PSP,而异常服务例程则使用MSP。这两个堆栈指针的切换是智能全自动的,就在异常服务的始末由硬件处理。
代码的临界段也称为临界区,一旦这部分代码开始执行,则不允许任何中断打断。为确保临界段代码的执行不被中断,在进入临界段之前须关中断,而临界段代码执行完毕后,要立即开中断。
中断锁就是 RTOS 提供的开关中断函数。
简单的说,为了防止当前任务的执行被其它高优先级的任务打断而提供的锁机制就是任务锁。实现任务锁可以通过给调度器加锁或者直接关闭RTOS内核定时器(就是前面一直说的系统滴答定时器)来实现。
使用如下函数可以实现任务锁的开锁和解锁:
void tsk_lock (void);
函数 tsk_lock 用于禁止 RTX 内核定时器中断,因此也就禁止了任务切换。
使用这个函数要注意以下问题:
函数 os_dly_wait 用于任务的延迟.参数 delay_time 用于设置延迟的时钟节拍个数,范围 1-0xFFFE。
注意:同一个任务中 os_dly_wait 和 os_itv_wait 不能混合调用,只能选择其中一个。
函数 os_itv_set 用于设置周期性延迟的时间间隔,此函数必须配合 os_itv_wait 函数一起使用。用户调用函数 os_itv_set 设置了周期性时间延迟的时间间隔后,然后调用函数 os_itv_wait 函数等待时间到。
参数 interval_time 用于设置周期性延迟的时间间隔,单位时钟节拍数,参数范围 1-0x7FFF。
函数 os_itv_wait 函数用于等待周期性延迟时间到,此函数必须配合 os_itv_set 函数一起使用。用户调用函数 os_itv_set 设置了周期性时间延迟的时间间隔后,然后调用函数 os_itv_wait 函数等待时间到。
函数 os_time_get 用于获取系统当前运行时钟节拍数。
函数 os_dly_wait 实现的是周期性延迟,而函数 os_itv_wait 实现的是相对性延迟。
举例:
运行条件:
有一个 bsp_KeyScan 函数,这个函数处理时间大概耗时 2ms。 有两个任务,一个任务 Task1 是用的 os_dly_wait 延迟,延迟 10ms,另一个任务 Task2 是用的os_itv_wait 延迟,延迟 10ms。
不考虑任务被抢占而造成的影响。
实际运行过程效果:
Task1:
bsp_KeyScan+ os_dly_wait(10) ---> bsp_KeyScan + os_dly_wait(10)
|----2ms + 10ms 为一个周期------| |----2ms + 10ms 为一个周期----|
这个就是相对性的含义 。
Task2:
bsp_KeyScan + os_itv_wait ------> bsp_KeyScan + os_itv_wait
|----10ms 为一个周期(2ms 包含在 10ms 内)---| |----10ms 为一个周期------|
这就是周期性的含义。
任务间事件标志组的实现是指各个任务之间使用事件标志组实现任务的通信或者同步机制。
RTX 每个任务创建的时候,会自动创建 16 个事件标志,事件标志被存储到每个任务的任务控制块中。也就是说每个任务支持 16 个事件标志。
发送事件的中断任务在中断函数中应使用isr_evt_set函数对事件标志设置。
实际应用中,建议不要在中断中实现消息处理,用户可以在中断服务程序里面发送消息通知任务,在任务中实现消息处理,这样可以有效的保证中断服务程序的实时响应。同时此任务也需要设置为高优先级,以便退出中断函数后任务可以得到及时执行。
使用如下 6 个函数可以实现 RTX 的事件标志组
void os_evt_set (
U16 event_flags, /* 16 位的事件标志设置 */
OS_TID task ); /* 要设置事件标志的任务 ID */
函数 os_evt_set 用于设置指定任务的事件标志。
使用这个函数要注意以下问题:
void isr_evt_set (
U16 event_flags, /* 16 位的事件标志设置 */
OS_TID task ); /* 要设置事件标志的任务 ID */
相关描述参照os_evt_set。
使用这个函数要注意以下问题:
函数 os_evt_wait_and 用于等待所有事件标志被设置。
OS_RESULT os_evt_wait_and (
U16 wait_flags, /* 16 位的事件标志等待 */
U16 timeout ); /* 超时时间设置 */
使用这个函数要注意以下问题:
函数 os_evt_wait_or用于等待至少一个事件标志被设置。
OS_RESULT os_evt_wait_or (
U16 wait_flags, /* 16 位的事件标志等待 */
U16 timeout ); /* 超时时间设置 */
使用这个函数要注意以下问题:
RTX 的消息邮箱实际上就是消息队列,通过内核提供的服务,任务或中断服务子程序可以将一个消息(注意,RTX 消息邮箱传递的是消息的地址而不是实际的数据)放入到消息队列。同样,一个或者多个任务可以通过内核服务从消息队列中得到消息。通常,先进入消息队列的消息先传给任务,也就是说,任务先得到的是最先进入到消息队列的消息,即先进先出的原则(FIFO)。
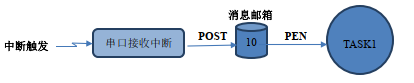
运行过程主要有以下两种情况:
上面就是一个简单 RTX 消息邮箱通信过程。实际应用中,中断方式的消息机制切记注意以下四个问题:
OS_RESULT os_mbx_send (
OS_ID mailbox, /* 消息邮箱 ID标识 */
void* message_ptr, /* 消息指针,即数据的地址 */
U16 timeout ); /* 超时时间设置 */
函数 os_mbx_send 用于向消息邮箱存放数据指针,或者说数据地址。如果消息邮箱已经满了,调用此函数的任务将被挂起,等待消息邮箱可用,直到消息邮箱有空间可用或者超时时间溢出才会返回。
使用这个函数要注意以下问题:
OS_RESULT os_mbx_wait (
OS_ID mailbox, /* 消息邮箱的 ID标识 */
void** message, /* 存放消息指针的变量地址 */
U16 timeout ); /* 超时时间设置 */
函数 os_mbx_wait 用于从消息邮箱中获取消息。如果消息邮箱为空,调用此函数的任务将被挂起,直到消息邮箱有消息可用或是设置的超时时间溢出才会返回。
OS_RESULT isr_mbx_check (
OS_ID mailbox ); /*消息邮箱的 ID标识*/
函数 isr_mbx_check 用来检测消息邮箱剩余空间可以存储的消息个数。建议配合函数 isr_mbx_send 一起使用。
使用这个函数要注意以下问题:
互斥信号量就是信号量的一种特殊形式,也就是信号量初始值为 1 的情况。有些 RTOS 中也将信号量初始值设置为 1 的情况称之为二值信号量。为什么叫二值信号量呢?因为信号量资源被获取了,信号量值就是 0,信号量资源被释放,信号量值就是 1,把这种只有 0 和 1 两种情况的信号量称之为二值信号量。互斥信号量的主要作用就是对资源实现互斥访问。
互斥信号量可以防止优先级翻转,而二值信号量不支持。
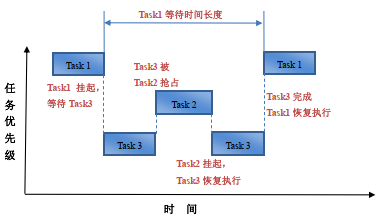
运行条件:
运行过程描述如下:
上面就是一个产生优先级翻转问题的现象。
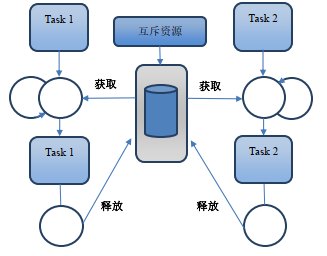
运行条件:
运行过程描述如下:
上面就是一个简单 RTX 互斥信号量的实现过程。
OS_RESULT os_mut_wait (
OS_ID mutex, /* OS_MUT 类型变量 */
U16 timeout ); /* 超时时间 */
函数 os_mut_wait 用于获取互斥信号量资源,如果互斥资源可用,那么调用函数 os_mut_wait 后可以成功获取互斥资源,在此函数的源码将计数值加 1(互斥信号量源码的实现上跟信号量不同)。如果互斥资源不可用,调用此函数的任务将由运行态转到挂起态,等待信号量资源可用,也就是计数值为 0 的时候。如果一个低优先级的任务通过互斥信号量正在访问互斥资源,那么当一个高优先级的任务也通过互斥信号量访问这个互斥资源的话,会将这个低优先级任务的优先级提升到和高优先级任务一样的优先级,这就是所谓的优先级继承,通过优先级继承可以有效防止优先级翻转问题。当低优先级任务释放了互斥资源之后,重新恢复到原来的优先级。
使用这个函数要注意以下问题:
OS_RESULT os_mut_release (
OS_ID mutex ); /* OS_MUT 类型变量 */
函数 os_mut_release 用于释放互斥资源,调用此函数会将计数值减 1。只有当计数值减到 0 的时候其它的任务才可以获取互斥资源。也就是说如果用户调用 os_mut_wait 和 os_mut_release,需要配套使用。通过函数 os_mut_wait 实现互斥信号量计数值加 1,通过函数 os_mut_release 实现互斥信号量计数值减1 操作,这样的话,这两个函数可以实现嵌套调用,但是一定要保证成对调用,要不会造成互斥资源无法
正确释放。 如果拥有互斥资源的任务的优先级被提升了,那么此函数会恢复任务以前的优先级。
使用这个函数要注意以下问题:
在 ANSI C 中,可以用 malloc()和 free()2 个函数动态的分配内存和释放内存,但是,在嵌入式实时操作系统中,调用 malloc()和 free()却是危险的,因为多次调用这两个函数会把原来很大的一块连续内场区域逐渐地分割成许多非常小而且彼此又不相邻的内存块,也就是内存碎片。由于这些内存碎片的大量存在,使得程序到后来连一段非常小的连续内存也分配不到。另外,由于内存管理算法上的原因,malloc()和 free()函数的执行时间是不确定的。 在 RTX 中,操作系统把连续的大块内存按分区来管理。每个分区中包含整数个大小相同的内存块。
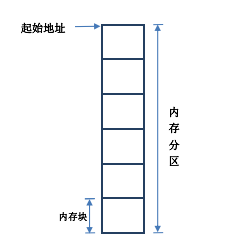
利用这种机制,就可以得到和释放固定大小的内存块。这样内存的申请和释放函数的执行时间就是确定的了。在一个系统中可以有多个内存分区,这样,应用程序就可以从不同的内存分区中得到不同大小的内存块。但是特定的内存块在释放时,必须重新放回到它以前所属于的内存分区。显然,采用这样的内存管理算法,上面的内存碎片文件就得到了解决。
其实 RTX 的内存管理也非常好理解,可以理解成一个二维数组,比如我们定义一个二维数组为:uint8_t mpool[10][32]。对应到 RTX 的内存管理上就是定义了 10 个内存块,每块大小是 32 字节。如果还需要其它大小的内存块,还可以多定义几个其它大小的。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。