有个供内部员工使用的后台管理系统,每天会从上游的一个oa系统的接口同步员工数据,oa系统侧维护了每个员工的id、名称、工作城市等等各类信息,接口响应如下:

这个id就算是员工的唯一标识,就像工号一样,不会变的那种。因此,我们把接口数据拿到后,就直接落地到我们本地数据库的表中,表的主键虽然设定为自增主键,但是在程序里,我们会直接用oa系统给我们的这个id来设置本地表id的值后再插入。
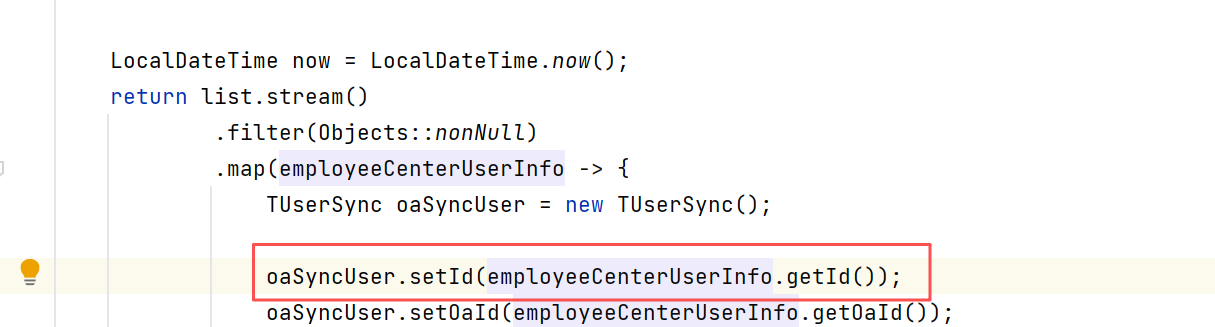
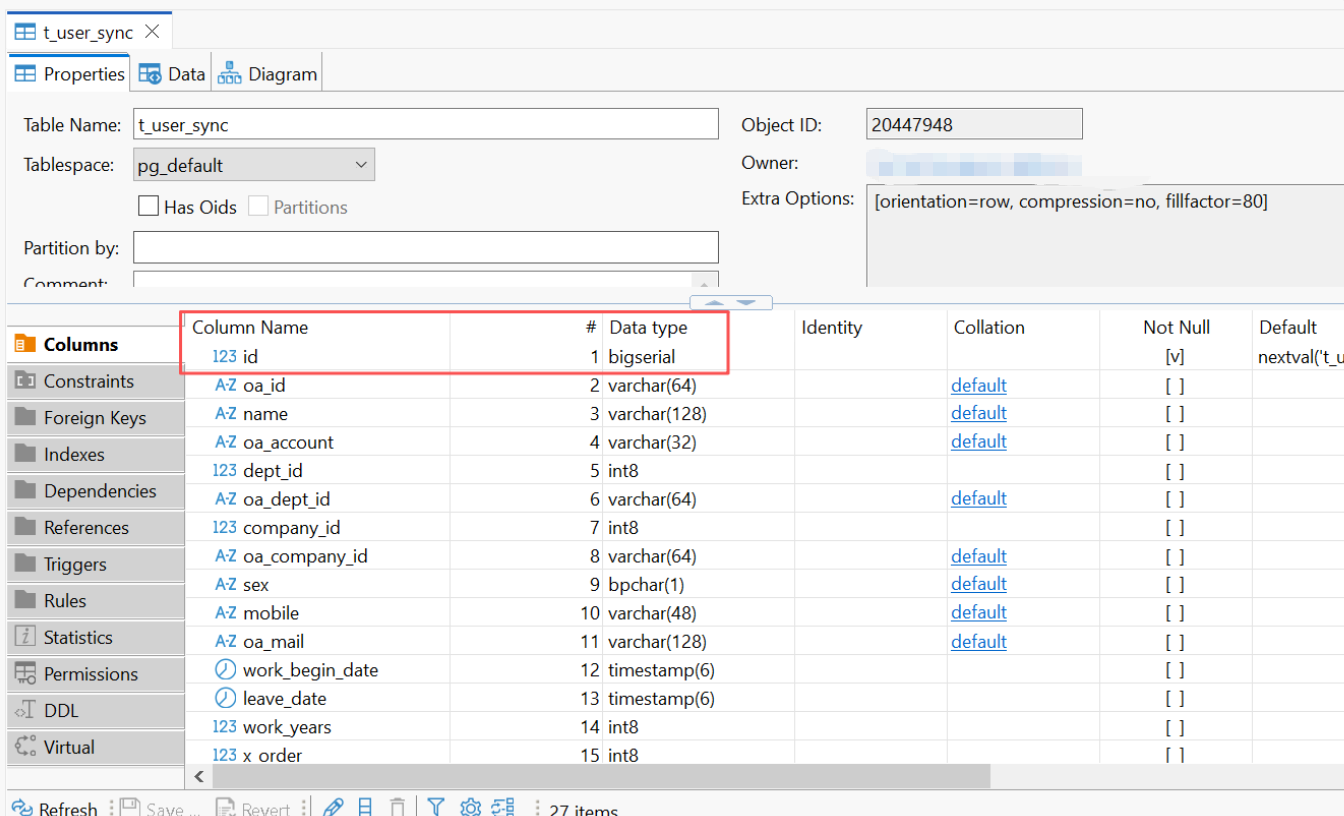
表结构:
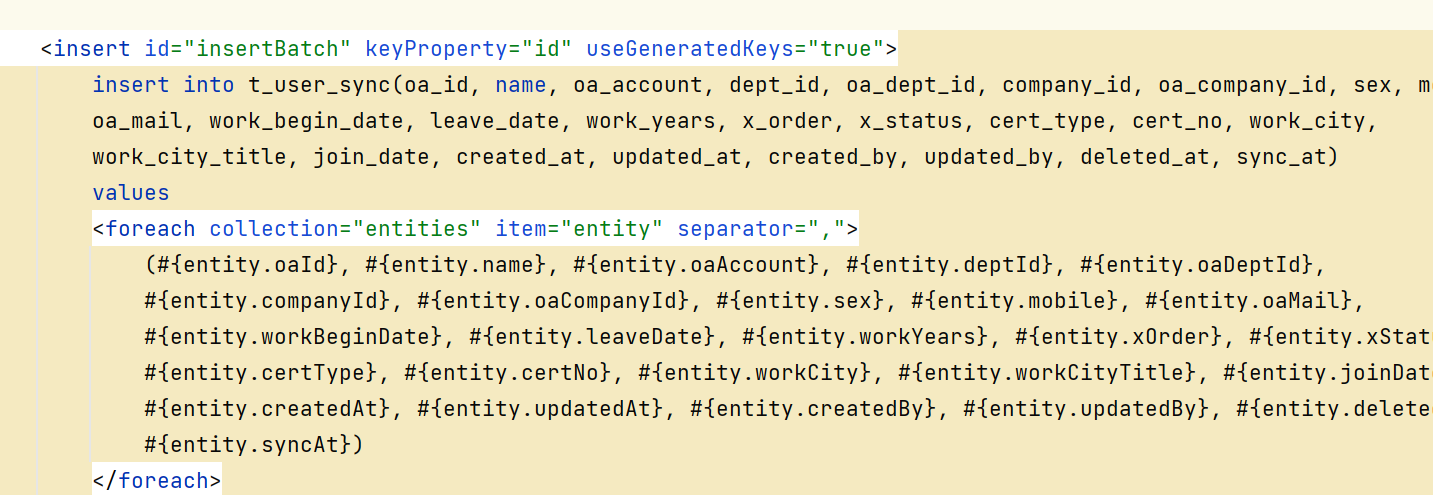
sql如下:这个sql是自动生成的,默认生成出来的是不带id这种主键字段的,我们手动加了一下:
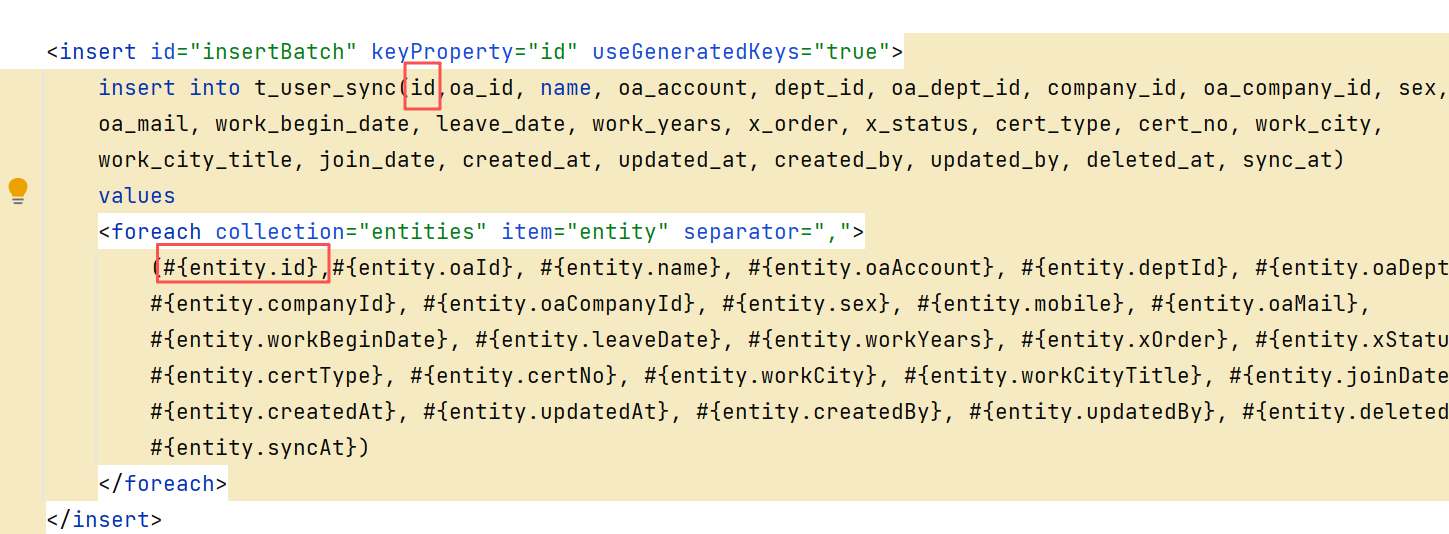
手动加上id字段:
结果,最近弄了一个员工报商业保险的活动,简单来说,就是存储一下数据:用户id 、对应的商业保险id。
报保险的过程中,发现用户表缺了些数据没同步,如用户证件号(报保险需要)、城市等,所以就加了一下这几个字段。
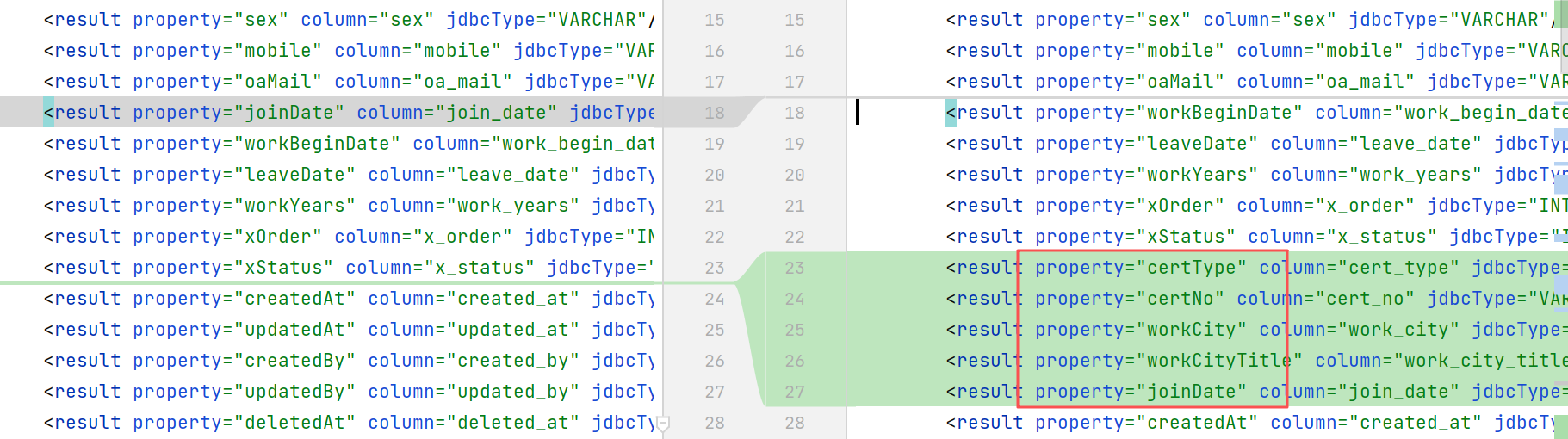
新增完字段后,mapper.xml代码自动生成,也没仔细看,结果就把之前手动加的id字段给冲掉了:
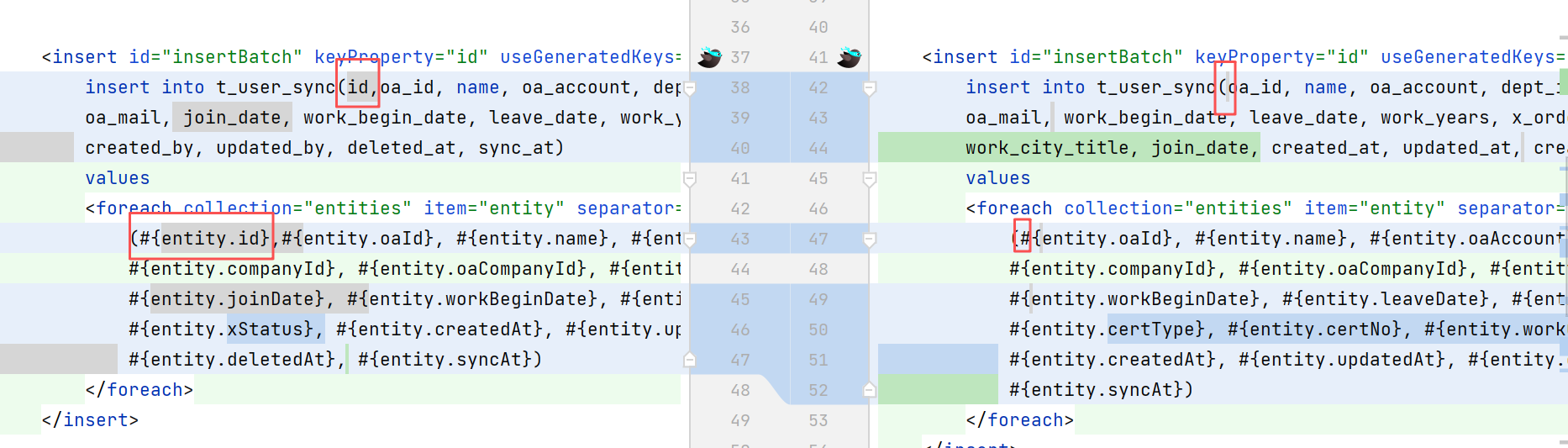
这个上线后,由于在程序中没有指定id字段,就导致本地表中的id变成了使用自增的方式(postgresql,从序列中获取下一个id的值,类似mysql中自增)。
而且,从oa系统同步员工信息到我方系统,每天都是靠一个定时任务在跑,每天跑的时候:
1、从oa侧获取员工列表数据
2、清空本地表
3、批量插入从oa侧获取的员工数据
这就导致,员工的id,上线后,每天都在变,每天都在变。
当时我查问题看到这个问题的时候,吓了一跳,当时员工报商业保险正如火如荼呢,我一想:难道得赶紧通知全公司的人,重新报了?而且,当时业务的人和保险公司约定的提供保险人员名单的时间也没几天了。。。
后面我又仔细看了下,发现问题还没有那么大。
就是在数据先落地到t_user_sync这个表(这个表和上游oa侧数据保持一模一样,只读不写,便于定位问题)后,还有个定时任务,将数据从t_user_sync转移到我们实际的用户表(sy_user),这个表我们会进行增删改查等等。
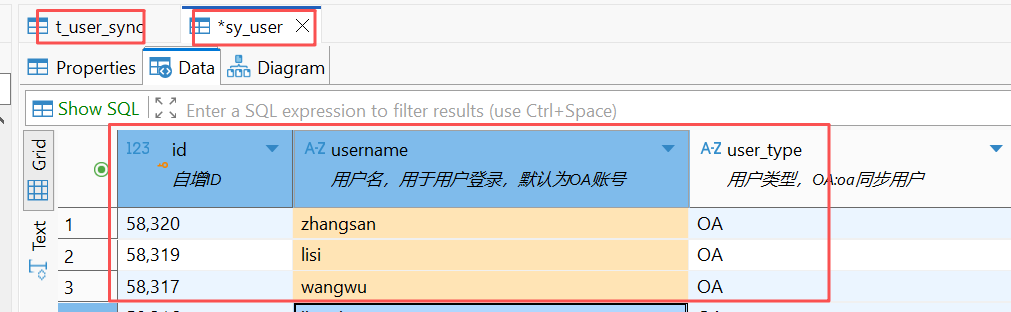
这个定时任务,在将t_user_sync转移到sy_user的过程中,是增量同步的。如,发现zhangsan这个用户时,先查一下sy_user里有没有,没有才插入,插入时,sy_user的id也是用的t_user_sync的id(也就是oa侧的id),有就更新。
这个增量同步机制,救了我,导致的结果是,虽然t_user_sync中id错了,且每天都在变;但sy_user中的id虽然也是错的,但是不会每天变,而是用到第一次同步t_user_sync时的id。
只要sy_user表中的id不变,错的也影响不大,至少员工报保险的相关表中的关联关系是没问题的:
员工id 员工名称 保险名称
11111(错的) 张三 xxx商业保险
而我们这个系统中,其他地方也有用到这个用户id的,虽然由于用户id变化导致了关联关系错乱,但是影响毕竟业务影响没那么大,到时候再修复即可。
其实,这个问题就是粗心造成的,当然,客观上,现在手里系统太多,精力分散也是一个原因。
另外,这个自动生成代码的机制,后期看看这块是否可以优化吧,能把id字段一起生成到xml中是最好。
如果实在不行的话,也应该考虑,这种表的id字段,就设置为非自增、非空,必须让程序手动设置,也能及时发现问题。
介绍背景前,先讲讲etl吧:
在我从业没几年的时候,当时由于接触的都是mysql这种oltp这类业务为主,有时候看到一些招聘岗位写etl,不知道是啥意思。也是这几年才大概了解:
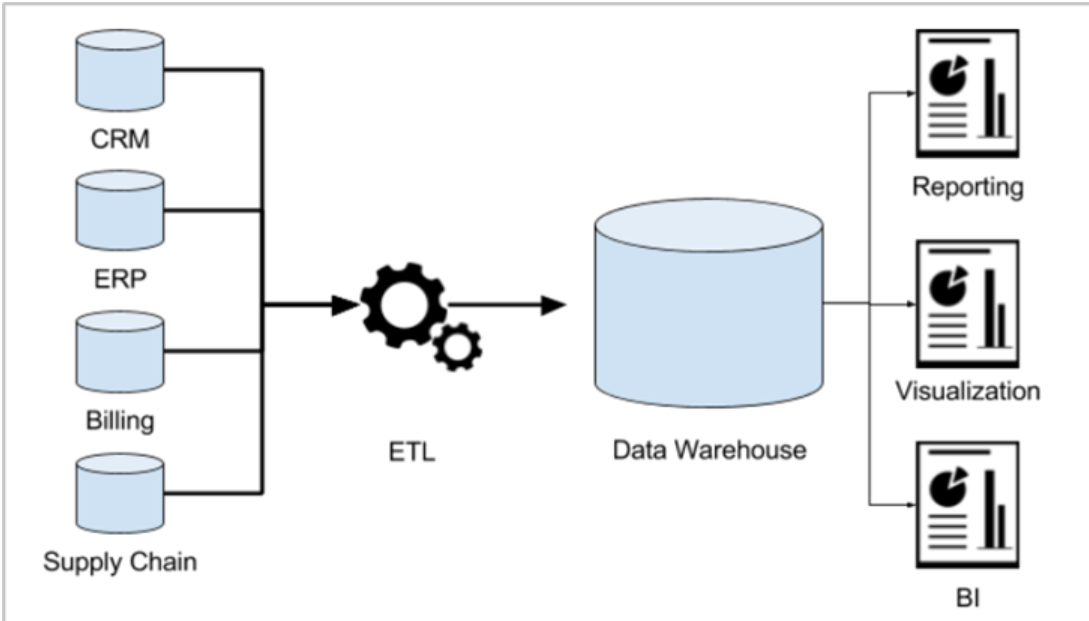
将企业中分散的数据,集中的输入到数据仓库中的过程,就是 ETL。
Extract(提取): 从多个异构数据源(如数据库、文件系统、API等)中提取原始数据。数据源可以是关系型数据库(如MySQL、PostgreSQL)、非关系型数据库(如MongoDB、Cassandra)、文件(如CSV、JSON)、API或流式数据源。
Transform(转换): 对提取的数据进行清洗、标准化、聚合、去重等操作,以满足业务需求或数据分析的要求。这一步可能涉及数据类型转换、格式转换、业务规则应用、数据聚合、数据质量校验等。
Load(加载): 将转换后的数据加载到目标存储系统中,通常是数据仓库或数据湖中,供后续的数据分析、报表或机器学习等用途。加载的方式可以是全量加载、增量加载或实时加载。
像我们公司,数据库种类又多(oracle、mysql、pg、国产),系统又多,好多系统还是买的,你想要某个系统的数据,要么走接口,要么通过人家的表。一方面,好多买的系统,不喜欢对外提供接口(商业上的考虑,毕竟数据是无价的,让你难以迁移,也就是这几年,感觉新的软件系统才开始注重对外提供api);另一方面,有时候表很多,有些表也很大,自己写接口去每天同步,工作量也不小,还要申请api key/api secret,还要开通网络,也是挺麻烦的,最终就慢慢习惯了、妥协了,通过数仓etl同步,还是能省一些事吧。
另一个c端系统,重要性比上面那个系统重要多了,这两天也出了一个问题。
这个系统,本来是一个外包同事在维护,由于他所在的公司和我们公司不再合作了,他也就跟着离职了(其实可以和新外包公司签约,不过他说新外包公司不太喜欢)。他开发完成了最后一个功能并完成测试后,还没来得及系统上线,所以上线的事就我来弄。
我整理了一下上线的各种变更,如sql、nacos配置、xxljob、版本jar包、前端包等等一大堆,写了个文档就提交变更流程了。
其中一个sql,是给某个数仓同步表加id字段(并新建了序列,设置id字段通过序列来自增),我当时还专门研究了一下:
我们有两个表,jy_sync_h_logasset (当前表)、jy_sync_h_logasset_history(历史表),两个表的结构类似,只是一个存储最近几个月的数据(jy_sync_h_logasset ),一个存储几个人前的数据(jy_sync_h_logasset_history)。系统会定期把几个月前的数据,从当前表,转移到历史表里去,保证当前表的数据量不要太大,影响查询速度。
这两个表,有一个问题,就是表没有设置id这种主键,为啥没主键呢,因为jy_sync_h_logasset 这个表的数据,是通过数仓的etl操作,从其他上游数据库搬运过来的。
jy_sync_h_logasset 对应的上游的话,不一定是一个表,可能是一个视图,或者是一个sql,比如select name,oa_account from employee这种,它的sql中,就没有查询id字段,或者是多表join那种(一对多),就是算有id,也会导致id重复。
所以,我猜测是这个原因,导致我方的这个表,是没有id字段的,也没弄主键。
一个表,没有主键,据我所知,在分页查询时,容易不稳定,某一条记录可能会在这一页出现,在下一页继续出现,一般我们解决这种分页查询不稳定的问题,都是会按照某个字段排序,而一般首选就是id字段。
对于这个没有id字段的表来说,分页查询应该是容易出问题的,所以我猜测,这就是本次sql变更(加id字段,创建序列,设置id字段从序列取值)的原因。
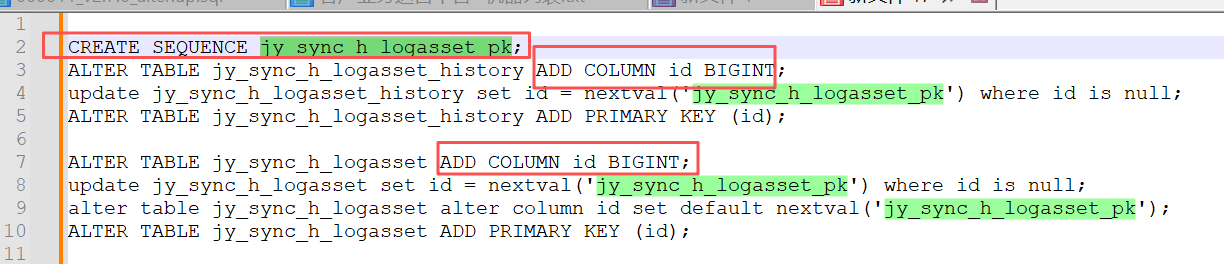
我当时为啥注意这个sql呢,我发现他只建了一个序列,然后两个表都用了这个序列,我当时多看了两眼,只是有点奇怪,一般来说,每个表会设置一个自己的序列。后来我看到,在将jy_sync_h_logasset表中几个月前的数据转移到jy_sync_h_logasset_history的定时任务中,代码里设置了jy_sync_h_logasset_history的id就直接使用jy_sync_h_logasset中的id,也就是说,jy_sync_h_logasset_history实际并不会使用序列中的值作为id,我也就没管了。当然,出事的确实也不是这个问题。
周四下午,和运维一块,看着他做完上线变更,想着又了了一个事。结果周五早上,8点多,就给我发消息,说有个xxljob的定时任务失败了。
我赶紧吃完饭,抱着电脑去找他,看了下,发现报错的原因是:
一个etl_status的表中,没有查到当天的记录,这个表的用途是:数仓在给我们推送完各个表的数据后,会在etl_status中写入一条成功记录。
既然这次报错是没查到数仓写的成功记录,是不是数据推送失败了呢,我们赶紧联系了数仓的同事,数仓同事过了会告诉我们说,是数仓在往jy_sync_h_logasset写记录时,报错了,提示对jy_sync_h_logasset_pk这个序列的权限不足。然后我过去找他,仔细聊了下,比如,他那边的一次数仓etl任务,总共要推10个表过来,如果其中一个表失败了,就会导致:不写入etl_status成功记录。但已经推送成功的表(如这里成功了9个表)的数据并不会回退。
问题是搞清楚了,还是粗心导致的,我当时完全没有想起来序列要给数仓用户授权这个事。
但这个问题看起来小,导致的影响还是比较大的,由于我们定位这个问题及修复(给数仓用户增加权限,数仓重新推送)花了一些时间,修复时已经过了某个特定的时点了,导致我方已经没有时间再来跑xxljob了(某个xxljob任务由于下游系统的限制,要求必须在某个时点之前跑才行),只能是让业务同事去通知客户道歉。
部门的领导也介入了这个事情,下周就得系统梳理下现状,再看看有没有在这种异常情况下进行补救的措施,当然,我们这边其实是可以补救的(数仓重新推送数据后,我方也重新执行xxljob相关任务),但是我们系统还有下游(现在就是下游系统不支持过了某个时间点后进行补救),这块还得再看看怎么弄。
小小的问题,大大的影响,出了问题再来处理,一般成本是最高的,也会带来更多的工作,如事故汇报、针对事故的改进措施等。还是得防患于未然,治未病。
当然,我简单看了下,希望postgresql可以做到:新增的序列,不用每次单独授权,而是在数据库级别进行授权。

下周再研究下吧,和dba沟通下,避免现在权限管的太细导致的问题。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。