If you can't measure it, you can't improve it. -- 现代管理学大师彼得·德鲁克
推荐系统, 算法驱动型应用系统, 不能通过功能测试来判断, 需要根据各种维度效果来判断;
系统监控通过对系统中多维度细节的监控, 通过对大系统中小系统的监控, 做到对整个系统的监控;
做好正向的监控链条, 做到链条上的关键环节出了问题都可以主动发现;
评测: 用量化的指标衡量系统;
评测体系: 用多维度的量化指标来衡量系统;
无法量化的评测指标 => "推荐系统的调性"
推荐系统的业务目标: 能够最大化的引导平台上的用户消费平台上的内容;
在评测体系中一定存在一个最直接, 终极的指标用来衡量推荐系统最终价值;
局限性:
点击率反映的是推荐产品漏斗第一个环节的匹配效率, 是对个性化匹配程度最直接的衡量;
计算公式分母一定是真正曝光的物品数量, 不能用推荐服务返回的物品数量;
对用户的覆盖
用户覆盖率: 有多少用户能够计算出有效的推荐结果; \(cov_{user} = N_{rec}/N_{total}\)
该指标体现的是推荐系统可以服务, 影响多少用户, 对推荐系统影响力的最直接体现;
几个维度的变化:
用户覆盖率是单一值衡量指标, 可以使用离散变量的分布来体现覆盖情况细节;(单值指标扩展为概率分布)
对物品的覆盖
物品覆盖率: 系统中有多少物品出现在推荐结果中; 提醒开发者关注未被推荐的物品, 解决长尾物品的流量问题;
动销率: 门店中所有商品种类中有销量的商品种类总数, 除以门店中所有商品种类总数, 得到的比例值;
\(cov_{item} = M_{rec}/M_{total}\)
不活跃物品: 没有得到足够的曝光; 一个物品出现在多少次推荐中或覆盖多少个用户才算得到有效覆盖;
与以点击率为代表的准确性指标相背离, 但是关系到系统的长期健康发展, 是平衡短期利益和长期利益的一个重要方面;
多样性主题, 常用的是类别, 又分一级类, 二级类, 三级类等;
多样性计算方法,
基于信息熵, 将每个用户的推荐列表收集起来, 计算出属于不同类别的物品所占的比例, 记为 \(p_i\), 所有类别构成了一个离散随机变量, 信息熵的计算方法为: \(\sum_i p(i)logp(i)\), 信息熵越大说明多样性越高;
计数, 数在推荐列表中所有物品的两两组合中, 有多少组合中两个物品的类别不同;
\[Diversity = \frac{2\sum_{i,j}I(cate(i) == cate(j))}{|L| * (|L|-1)} \]
L 代表推荐列表, I 表示指示函数, 其参数为真时取1, 否则取0; 计算结果多样性取值在 [0,1];
实际应用场景中, 对多样性设置一个下限, 周期性对多样性指标进行评测计算, 保证不低于这个水平即可;
新颖代表着多样, 反之不然;
多样性是推荐系统长期发展的底线, 新颖是长期发展的突破口;
选择标签作为新颖性的主体:
\[Novelty = \frac{N}{|L|} \]
L 代表推荐列表, N 为列表中用户此前没有见过的标签对应的物品数量;
对结果排序好坏评测的指标;
NDCG(Normalized Discounted Comulative Gain)
\[DCG = \sum_{j=1}^J \frac{rel_j}{log_2(j+1)} \\ NDCG = \frac{DCG}{IDCG} \]
\(rel_j\): 第 j 位上物品的相关性;
\(log_2(j+1)\): discount 函数, 用来衡量位置的重要性;
IDCG: 理想(ideal)的DCG, 将列表按照相关性的大小从高到低排列, 然后计算理想列表的DCG;
计算出每个列表的 NDCG 后, 可以综合汇总每个列表的结果得出整个系统的 NDCG; 汇总方法包括计算所有结果的平均值, 或者按用户划分(按照喜好品类, 新老用户, 活跃程度等不同维度), 分片评测;
MAP(Mean Average Precision)
mean: 在所有用户或请求上做平均(AP);
AP: 在每一个被点击的位置上, 计算 precision, 即计算该位置之前(包括该位置)所有被点击的物品数量除以该位置之前所有的物品数量;
eg: 100111, AP=(1/1+2/4+3/5+4/6)/4≈0.69;
AP的直观解释: 若AP=x, 表示平均每 1/x 个位置上会出现一个相关物品;
实际应用场景, 截取列表前几位来计算 MAP, 即 MAP@k
最直接方法:
这是一套有偏差的评测方法, 因为列表 A 并没有真实展示给用户, 里面有好东西用户并没有看到, 对新算法是吃亏的;
部分标签问题(partial-label problem)
核心是将列表 B 换成随机生成的无偏结果数据作为基准;
Yahoo! 无偏的离线评测算法:
算法实体包括:
S 中的物品时通过对该部分用户随机展示物品得到的, 这是无偏的关键
算法流程:
replay 方法, 通过使用小部分线上流量进行随机展示, 收集到公平无偏的评测集合来做无偏的评测;
离线评测优点:
缺点:
基础理论
在流量分配层面, 遵循同分布原则, 1) 本身随机生成的用户 ID, 2) 根据 ID 对流量进行等概率分配的函数(取模函数);
在对比结果解释方面, 考虑支撑数据指标的数据量, 利用概率统计中的假设检验思想;
逻辑工程架构
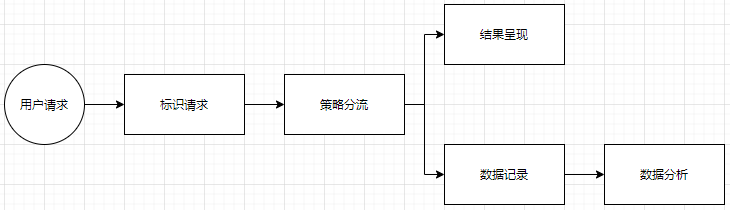
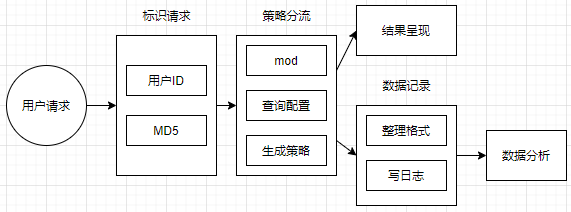
复杂度体现在 策略分流 部分和 数据分析 部分;
最小可用的 AB 实验系统
策略分流复杂度:
最小可用版本 = 支持两种策略同时上线 + 只处理一个层级;
分流主体, eg: 用户为主体(每个用户的所有请求), 或请求为主体(每个用户的每个请求);
留意使用注册用户 ID 时, 会流失未注册用户全部无法参与实验;
用户 ID 来源于不同系统, 通过 MD5 操作统一随机性, 后面基于 MD5 操作之后的结果进行策略分流;
隐含假设: 所有待实验策略均对所有用户无差别进行分流; 如果是有差别分流, 需要在标识请求处进行用户区分;
请求日志由推荐服务记录, 记录策略版本信息;
曝光日志和点击日志由展示端记录;
三份日志由一个共同的请求 ID 串联起来;
切记注意: 静默失败(silent failure)
多层重叠的在线实验系统
谷歌在线实验系统为例, 引入三个概念:
发布层(launch layer), 位于流程最前端, 每个发布层拥有全部流量, 发布层中的配置通常是指完成了 AB 实验并被认为优于对照组的配置;
一个请求在某组配置上的优先级:
层和域可相互嵌套;
公平的多层实验:
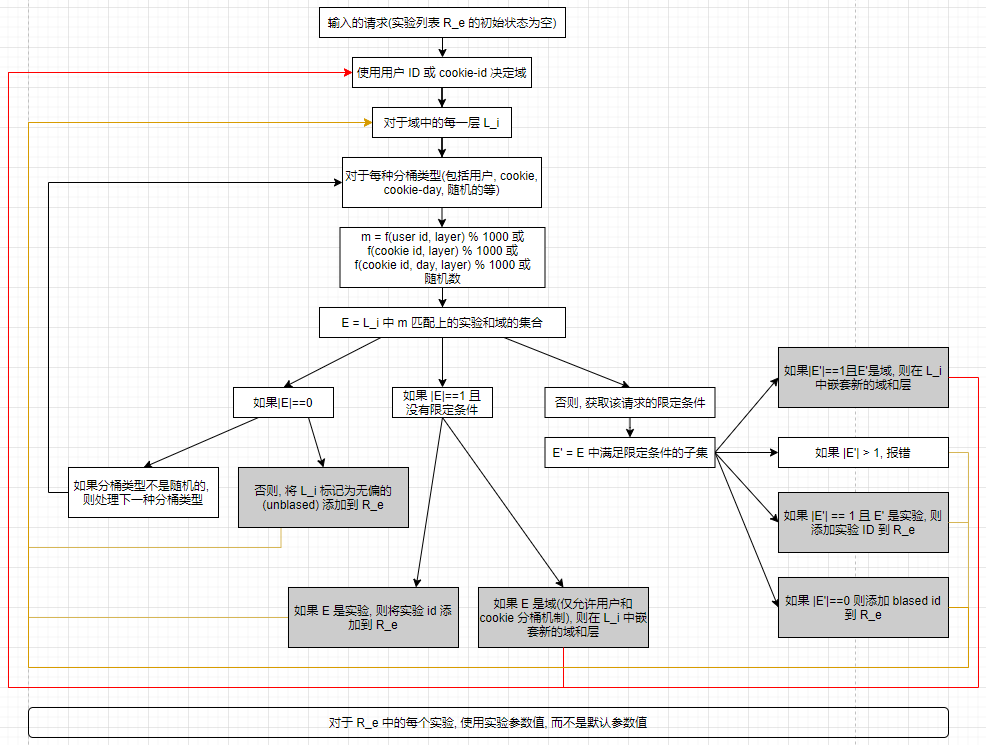
最终, 实验列表 \(R_e\) 每个元素对应着每一层要做的实验;
这套逻辑封装成共享库, 保证所有参与 AB 实验的业务逻辑一致;
AB 实验缺点:
辅助 AB 实验:
AB 实验, 每个用户会固定划分到一个组, 只接受某一种固定策略;
交叉实验, 每个用户都同时呈现多种策略结果;
选秀式方法(team draft), 随机选择策略, 每个策略里选取剩下最好的, 依次交替策略, 直到列表满足条件或策略池空;
交叉实验可以作为 AB 实验的前置筛选方法, 加快实验和迭代速度;
交叉实验缺点:
| 整体 | 分策略 | 分群体 | 分位置 | |
|---|---|---|---|---|
| 结果数 | 整体返回结果数 | 重点策略返回结果数 | 重点群体返回结果数 | NA |
| 点击率 | 整体点击率 | 重点策略点击数 | 重点群体点击率 | 头部位置点击率 |
| 覆盖率 | 整体覆盖率 | 重点策略覆盖率 | 重点群体覆盖率 | 头部位置覆盖率 |
| 排序位置 | NA | 重点策略平均排序位置 | NA | NA |
监控内容包括数据量和细分;
对机器学习系统重要环节的监控: 样本, 特征和参数;
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。