多组件, 多模块, 多数据源构成; 涉及用户, 物品, 行为, 上下文等数据;
计算形式包括大数据平台上的批量计算/挖掘/训练, 流式数据的实时处理, 线上的实时服务;
核心目的: 为用户找当前场景下最具相关性的物品或物品集合;
以用户兴趣为轴:
\[P(item|user)=\sum_{interest} (P(item|interest) × P(interest|user)) \]
用户与物品的相关性拆解为: 用户与兴趣的相关性和兴趣与物品的相关性的乘积;
\(P(item|interest)\) 和 \(P(interest|user)\) 任何一个为零, 乘积即为零;
用户感兴趣的点+兴趣点下物品的相关性;
三段式逻辑: 用户兴趣+相关性召回+融合排序
召回算法=>重排序=>业务干预
召回算法的关注点:
相关性
核心, 重排和业务干预层均不会引入新的候选物品, 只有召回层决定了用户可见物品的候选集; 如果召回相关性较差的物品, 不仅浪费计算力, 也增加了重排序层的工作负担(需要用更复杂的算法将相关性差的物品排在后面);
多样性
覆盖率
推荐算法能为多少用户/物品计算出相关物品;
实时性
将用户的实时行为用于推荐逻辑的计算, 对推荐结果产生影响, 并让用户感知到变化;
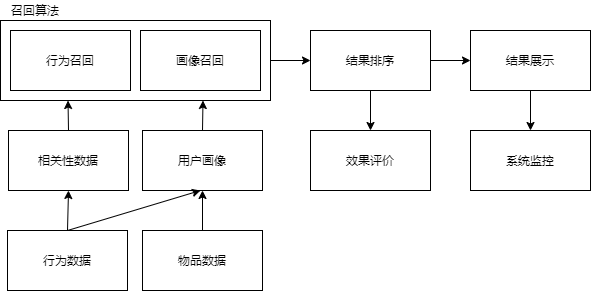
召回算法分为:
相关性数据挖掘, 依赖于:
用户画像建设工作的核心点:
物品画像是用户画像的基础, 首先提取物品层面的多维度描述, 再通过用户对物品的行为关系, 计算出用户在这些维度上的描述;
结果指标, 用来最终衡量推荐系统好坏的指标;
过程指标, 对结果指标的分解, 分解为几个可具体操作的维度, 好处是对结果指标的把控, 以及出现问题时的分析处理;
短期指标
长期指标
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。