
At a glance
- Today’s AI agent benchmarks test one task at a time, while real workplace productivity requires managing dozens of interdependent tasks at once. To reflect this, we created a setting called Multi-Horizon Task Environments (MHTEs).
- Under multi-task loads, leading computer-using agents degrade sharply, with completion rates dropping from 16.7% to 8.7%.
- CORPGEN introduces digital employees, with hierarchical planning, memory isolation, and experiential learning, delivering up to 3.5 times higher completion rates than baselines across three independent agent backends.
- Because CORPGEN is architecture-agnostic and modular, its gains come from system design rather than any single base model, and it benefits directly as underlying models improve.
By mid-morning, a typical knowledge worker is already juggling a client report, a budget spreadsheet, a slide deck, and an email backlog, all interdependent and all demanding attention at once. For AI agents to be genuinely useful in that environment, they will need to operate the same way, but today’s best models are evaluated one task at a time, not dozens at once.
In our paper, “CORPGEN: Simulating Corporate Environments with Autonomous Digital Employees in Multi-Horizon Task Environments,” we propose an agent framework that equips AI with the memory, planning, and learning capabilities to close that gap.
Introducing Multi-Horizon Task Environments
Replicating the reality of workplace multitasking requires a new kind of evaluation environment. In response, we developed Multi-Horizon Task Environments (MHTEs), settings where an agent must manage multiple complex tasks simultaneously. Each task requires 10 to 30 dependent steps within a single session spanning five hours.
To determine what a benchmark would need to test, we ran MHTEs at scale on some of today’s leading AI agents, exposing four weaknesses. First, memory fills up. An agent cannot hold details for multiple active tasks at once. Second, information from one task interferes with reasoning about another. Third, tasks don’t depend on each other in simple sequences. They form complex webs where an agent must constantly check whether upstream work is finished before it can move forward on anything downstream. Fourth, every action cycle requires reprioritizing across all active tasks, not simply resuming where the agent left off.
We also tested three independent agent systems under increasing loads. As the number of concurrent tasks rose from 12 to 46, completion rates fell from 16.7% to 8.7% across all systems.
CORPGEN’s architecture
CORPGEN introduces digital employees: LLM-powered AI agents with persistent identities, role-specific expertise, and realistic work schedules. They operate Microsoft Office applications through GUI automation and perform consistently within MHTEs over hours of continuous activity. Figure 1 illustrates how a digital employee moves through a full workday.
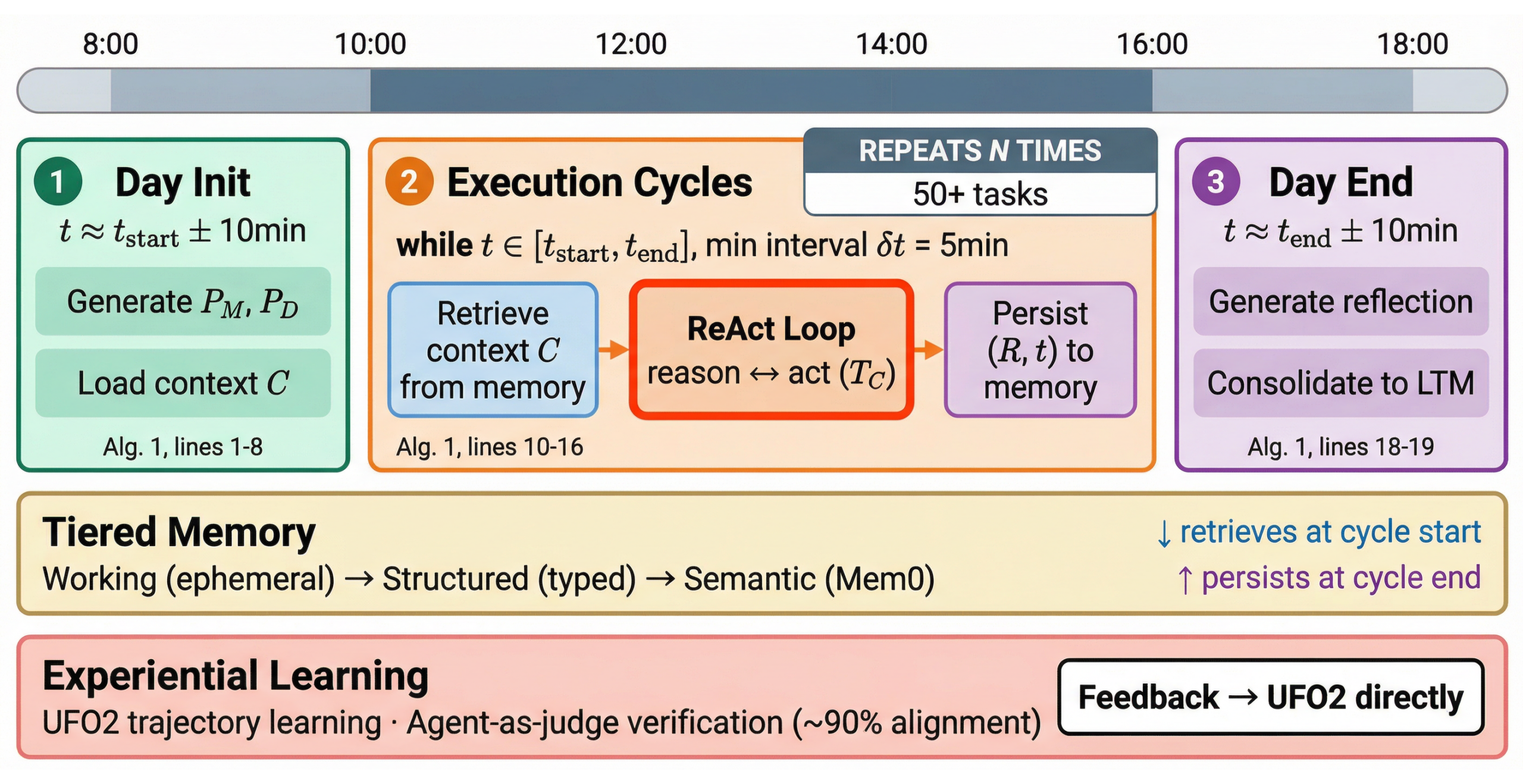
CORPGEN addresses each of the four weaknesses of concurrent task execution—memory overload, cross-task interference, dependency complexity, and reprioritization—in a targeted way. Hierarchical planning breaks objectives into daily goals and then into moment-to-moment decisions, allowing the agent to act from a structured plan instead of reviewing all available tasks before each step.
Subagents perform complex operations like web research in isolated contexts, preventing cross-task contamination. A tiered memory system enables selective recall of task-related information rather than retaining everything in active context. Adaptive summarization compresses routine observations while preserving critical information, keeping memory growth controlled.
Because these mechanisms are not tied to a specific base model, we tested CORPGEN across three different agents. In each case, we observed consistent gains. The improvements came from the architecture, not from the strength of any particular model. Figure 2 shows how they fit together within CORPGEN’s architecture.

How digital employees collaborate
When multiple digital employees operate in the same environment, collaboration takes shape through standard communication channels, without predefined coordination rules. One employee sends an email requesting data; another picks it up in the next cycle, uses its memory to process it, and responds. This exchange mirrors real workplace communication.
There is no shared internal state between agents. Coordination occurs entirely through email and Microsoft Teams, the same channels many workers use. Over time, these independent exchanges form recognizable organizational patterns. Some agents take on leadership roles; others provide support; shared documents become the connective tissue.
When a communication path breaks, such as an email delivery error, agents reroute messages through alternate channels to keep work moving. The result is a virtual organization that behaves like a real one without being explicitly programmed to do so.
Evaluating CORPGEN
We evaluated CORPGEN on a multi-task benchmark that combined up to 46 tasks into a single six-hour session. Three findings stood out.
Baselines degrade as load increases; CORPGEN does not. All three baseline agent systems showed steady performance declines as task load rose. CORPGEN, by contrast, maintained or improved its completion rates at higher loads. At 46 tasks, CORPGEN completed 15.2% of tasks, compared with 4.3% for the baselines, roughly 3.5 times more.
Experiential learning drives the largest gains. We introduced CORPGEN’s components sequentially: first the orchestration layer, then cognitive tools, and finally experiential learning. The first two produced moderate improvements. Experiential learning, in which agents store records of completed tasks and reuse them when they encounter structurally similar work, produced the largest increase, raising completion rates from 8.7% to 15.2%.
Evaluation methodology changes the picture. When we inspected the actual output files produced by agents, the results agreed with human judgements roughly 90% of the time. Evaluation based on screenshots and action logs agreed only about 40% of the time. This gap suggests that common evaluation approaches may underestimate what agents actually accomplish in practice.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Implications and looking forward
The results suggest that memory and retrieval, not just raw model capability, may be a key bottleneck in getting agents to work in the real world. The largest gains came from experiential learning. Agents that learn from prior successes and apply those patterns to structurally similar tasks build an advantage over systems that respond to each task in isolation.
CORPGEN also opens a new lens on how AI agents collaborate. Next steps include testing whether agents can maintain memory across multiple workdays and how they coordinate when working in teams. We are also exploring ways to make agents faster and more reliable by combining different methods of interacting with software.
Acknowledgments
This work is a result of a collaboration between the Office of the CTO at Microsoft and the Microsoft AI Development Accelerator Program (MAIDAP). We would like to thank the Microsoft Security Research team for providing resources that supported this research. We also thank the members of the Microsoft UFO2 (opens in new tab) team and the Mem0 (opens in new tab) project for their open-source contributions, which enabled key components of the CORPGEN architecture, and the OSWorld team for the benchmark that served as the foundation for our multi-task evaluation.
Finally, we thank the many contributors to this research: Charlotte Siska, Manuel Raúl Meléndez Luján, Anthony Twum-Barimah, and Mauricio Velazco.