最近刷到 Lxxxxt 新功能的時候,我是震驚的。它可以:
✅ 一鍵拆分圖片圖層
✅ 一鍵拆分文字元素
✅ 文字可直接編輯內容、字體、顏色、對齊方式
第一眼看上去我的反應是:
"哇塞!太厲害了!怎麼做到的!"
第二眼看上去我的反應是:
"作為一個零付費用戶,好用的功能我都要自己擁有!"
哎喲,然後就讓我看到拆分圖層後的文字,其實和原始圖片中的文字字體和顏色並不一致……
哈哈哈,再加上被同事寫PPT的思路(讓AI生圖畫色塊,再在上面疊加文本框)點亮了靈感,我就想出了下面的方案。
當然,完全不保證Lxxxxt就是這麼做的,只能說效果上有些類似。
復現的代碼已經上傳到Github:poster-text-editor。
模型部分文字識別和圖像編輯使用的模型只能大家去代碼裡看了,審核不讓說,都是用的老張NLP中轉站(好處就是可以各取所長,三大巨頭每家模型都各有所長)。
但是項目需要大家自己提供Key才能使用——哈哈畢竟我只充值了30塊(老張廣告費請結算一下)~
Step 1: 用Gxxxxx2生成一個有很多文字的圖片
Step 2: 使用Lxxxxxt編輯元素,就會得到下面擁有圖層拆分的文件

Step 3: 文字部分支持內容、字體、顏色、對齊方式的調整
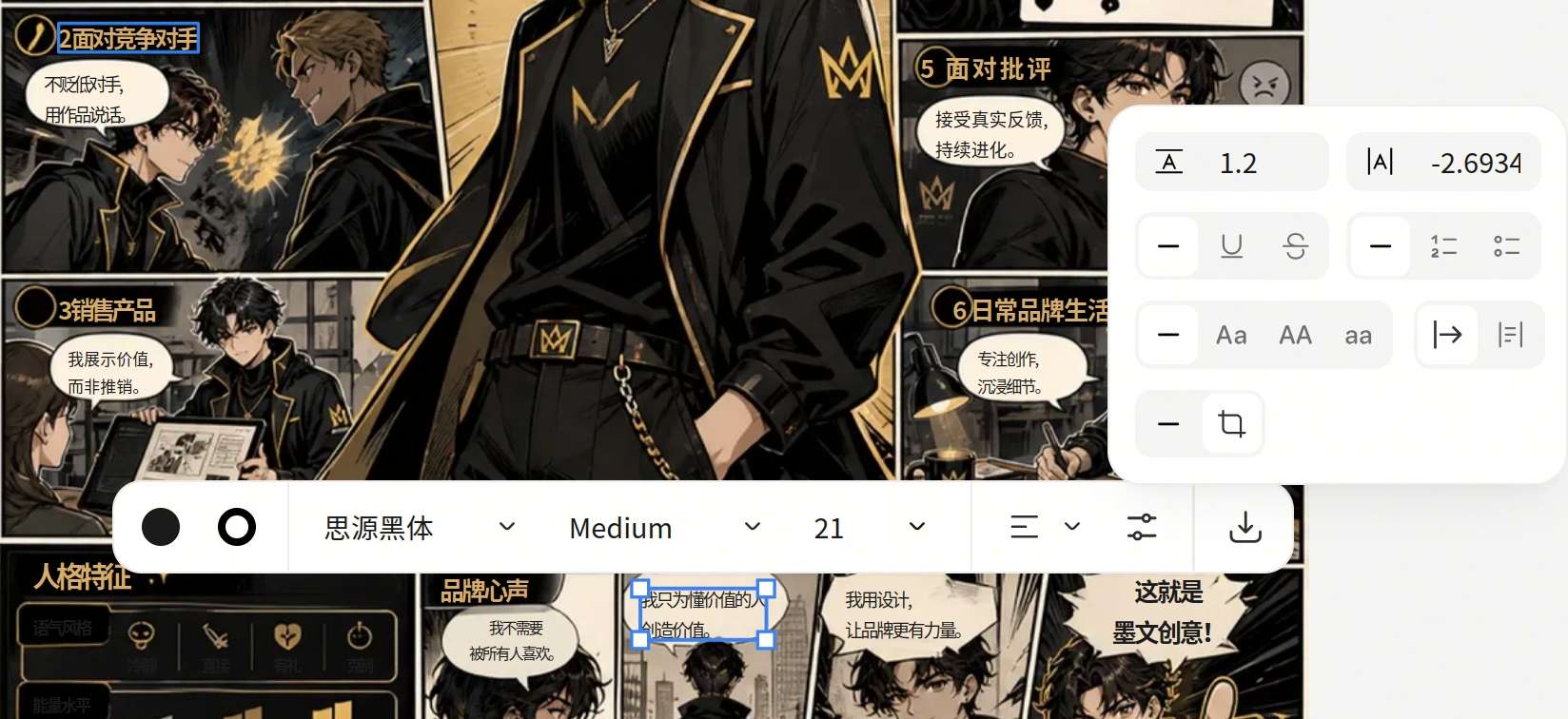
有了思路做就很快了,和CC一起整了1個多小時,就有了下面的效果。
一個簡易的網站,提供:
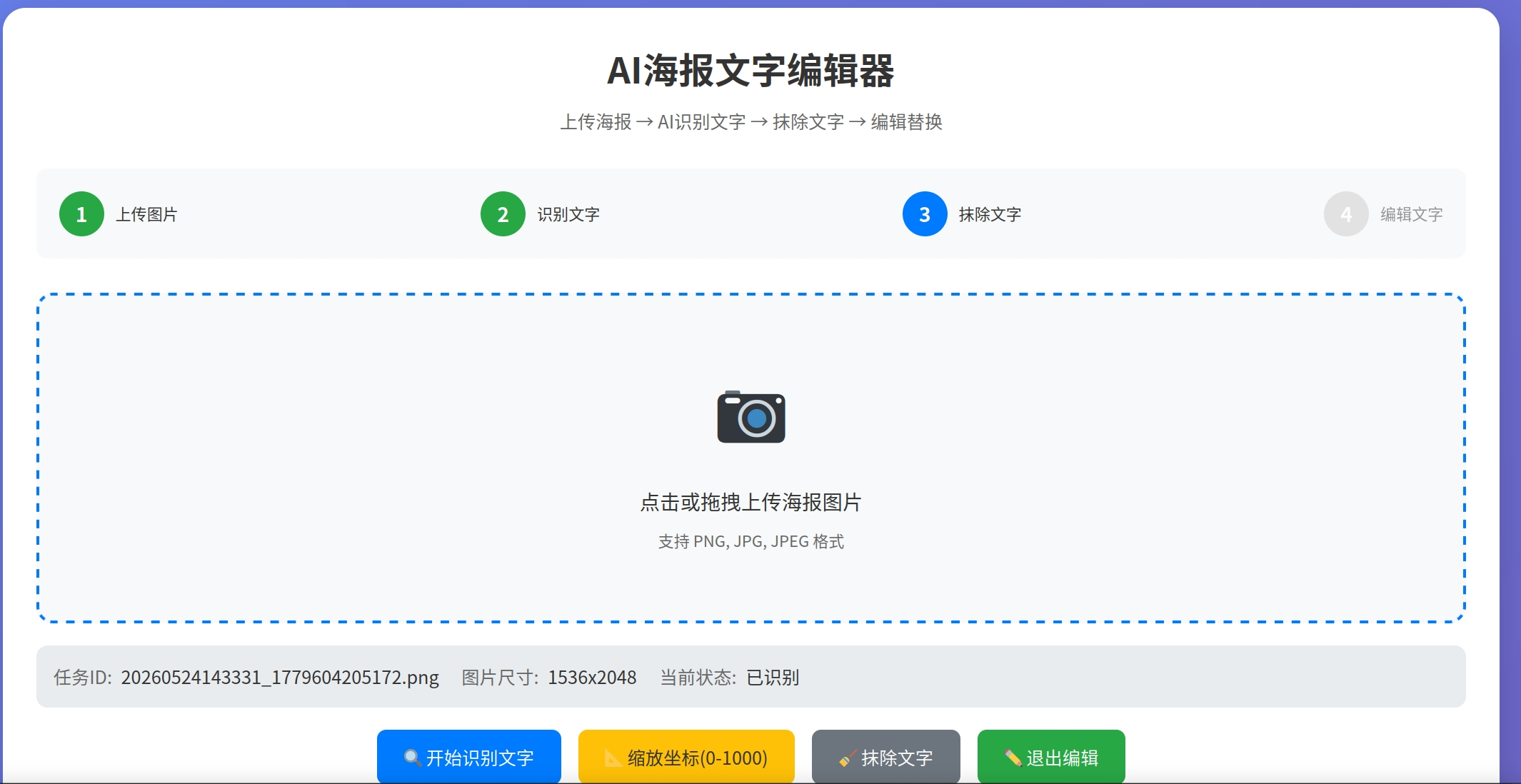
下面是效果
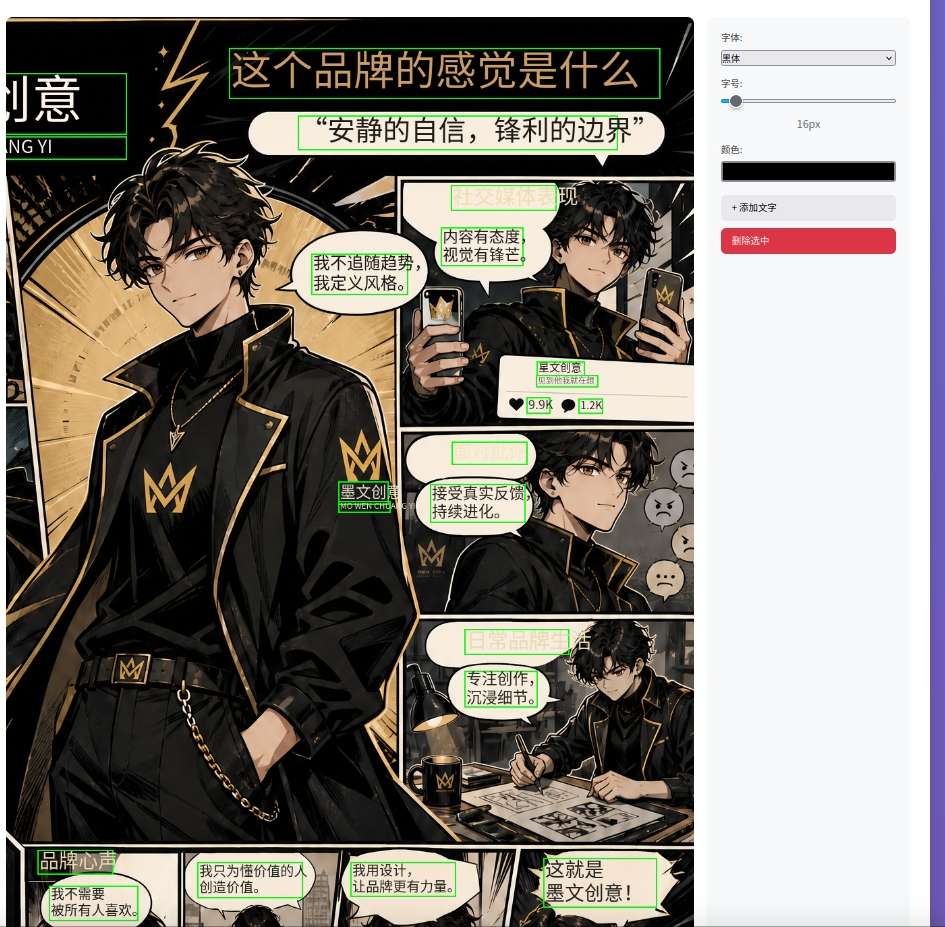
Lxxxxxt 很可能並不是在“真的拆圖層”。它可能是在:
✅ 識別文字
✅ 把原文字抹掉
✅ 在前端疊加新的文字層
——一種“假圖層編輯”。
這個任務的核心其實是大家很熟悉的目標檢測任務。
關鍵看當前的多模態模型能否對文字位置進行精準識別。
需要注意的點:
這裡需要剔除一些圖片化文字。
本質上,所有無法直接用"字體 + 字號 + 顏色"直接還原的文字,是不應該出現在文字編輯任務中的。
模型選型:
測試了下,至少Gxxxxx3.0以上的模型進行Bounding Box目標檢測輸出,準確率還是很高的。
不排除指令的影響因素,但在我測試的範圍內,Gxxxx5+的效果並不如Gxxxx3。
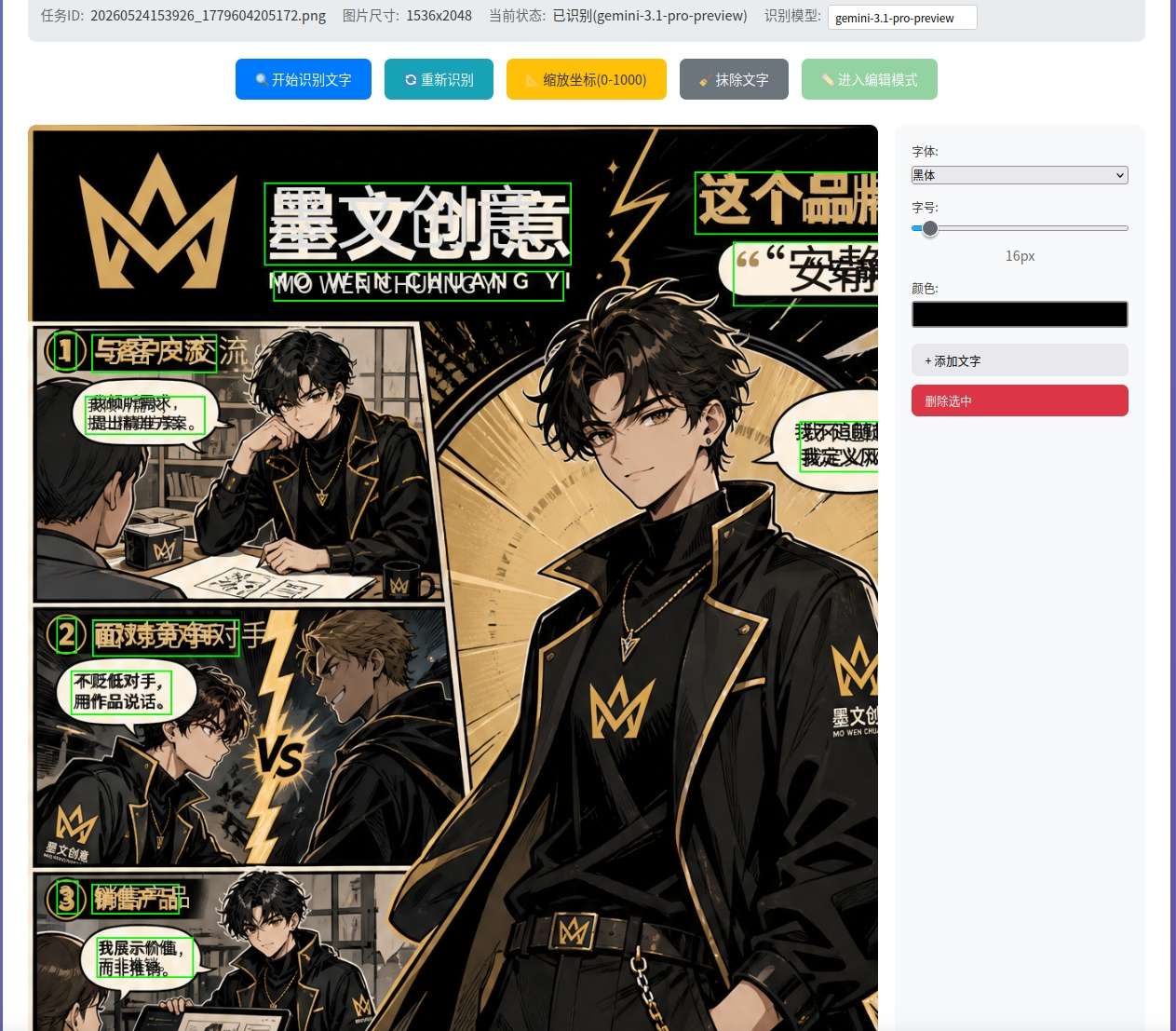
下面是多模型的效果對比:
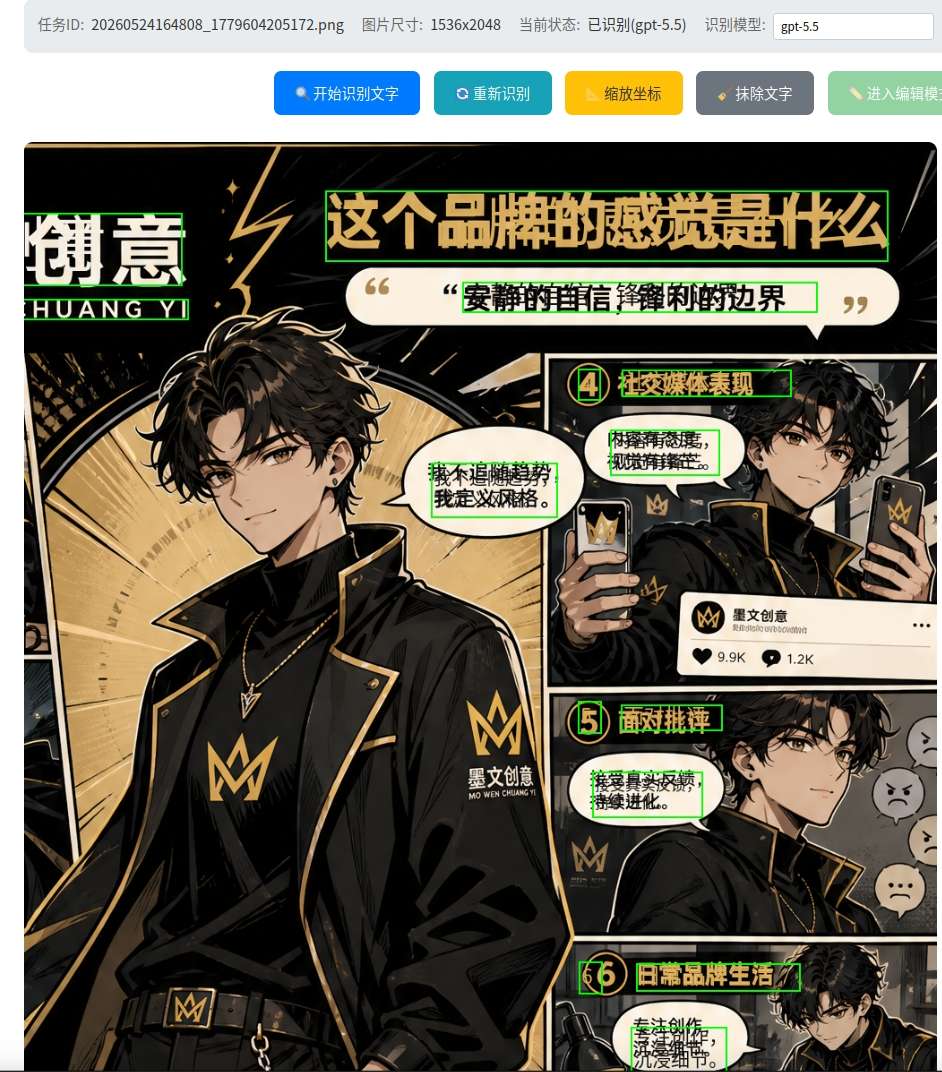
技術細節補充:Bounding Box座標輸出的兩種格式
這裡在頁面上增加了"縮放按鈕",因為Bounding Box的座標輸出有兩種形式:
| 格式 | 說明 | 需要處理 |
|---|---|---|
| 相對位置 | 標準化到0-1000的相對位置 | 需要根據圖片像素進行縮放 |
| 絕對位置 | 直接輸出和圖片大小一致的絕對位置 | 無需額外處理 |
不同模型,甚至不同版本的模型處理方式都不完全一致,所以需要做好兼容。
為文字補充字體+顏色+字號等相關信息。
需要承認的是,多模態模型在這些任務中有一定的侷限性,準確率並不算高。
| 屬性 | 模型推理準確率 | 我的方案 |
|---|---|---|
| 顏色 | 一般 | 更好的方案是使用取色器 |
| 字體 | 較低 | 需要人工調整 |
| 字號 | 很不準 | 直接根據Bounding Box的尺寸和文字數量計算得到,不讓模型推理 |
相關論文推薦:
最近有篇論文對多模態模型在設計領域的很多相關任務都做了評測,可以先去看看,瞭解下當前多模態模型在設計領域的邊界:不過也不用太著急——畢竟每過幾個月邊界就會大幅向前推動。
Graphic-Design-Bench: A Comprehensive Benchmark for Evaluating AI on Graphic Design Tasks
使用 Gxxxxxxx2 對原始圖片中對應文字進行抹除。
為了和前面LLM識別的文字框保持一致,這裡需要傳入Bounding Box識別到的文字信息。
如果想做得更加精細:可以把文字內容和位置信息都傳入(避免圖片中不同位置存在相同內容時的誤抹除)。
把抹除圖片的文字,和bounding box識別出的文本框疊加在一起,看起來就有點像是Lxxxxxt文字元素識別的效果啦
這裡只是一個初步的Demo,還有一些需要額外處理的細節:
最近發現一個很有意思的點:
不僅模型有思維慣性,人也有思維慣性。
之前設計的工作模式,是"先出設計稿,然後通過PS進行修改"。
於是在針對"如何修改圖片上文字"這個任務時,我們第一時間想到的也是 "圖片編輯"任務。
但是,這一定是個圖片編輯任務嗎?
哈哈,當然不一定是。
之所以要做圖片編輯,無外乎兩點:
所以針對以上兩點,我們可以分別想另外兩種歪著
最近測試發現,Gxxxxxx2對於結構化的繪圖指令,有很好的實現效果。
舉個之前看到很火的城市結構圖的例子:

繪圖指令如下
{
"type": "complex urban systems atlas infographic",
"style": "{argument name=\"color palette\" default=\"dark background with glowing blue, gold, and purple accents\"}, highly detailed technical illustration, 3D isometric cutaway",
"header": {
"title": "{argument name=\"chinese city name\" default=\"上海\"}城市系統剖面 {argument name=\"english city name\" default=\"SHANGHAI\"} URBAN SYSTEMS ATLAS",
"subtitles": [
"地表之上,是城市;地表之下,是秩序 {argument name=\"english subtitle\" default=\"Beneath the skyline lies the machine.\"}",
"一座城市如何運轉 How a Megacity Actually Works"
]
},
"layout": {
"top_left": "Compass rose and city map labeled '上海市域位置 SHANGHAI LOCATION'",
"top_right": "Data table titled '城市數據 CITY DATA' with 7 rows of statistics",
"centerpiece": {
"description": "{argument name=\"centerpiece style\" default=\"highly detailed 3D isometric cutaway render\"} of a megacity river landscape",
"layers": [
"地面層 SURFACE",
"排水層 DRAINAGE LAYER",
"電力層 POWER LAYER",
"通信層 COMMUNICATION LAYER",
"軌道交通層 METRO LAYER",
"道路隧道層 ROAD TUNNEL LAYER",
"管廊綜合層 UTILITY CORRIDOR LAYER"
]
},
"side_panels": [
{ "id": "01", "title": "城市主骨架 URBAN SKELETON", "elements": "Map with 8 legend items" },
{ "id": "02", "title": "排水與地下水網 DRAINAGE + STORMWATER", "elements": "Cross-section diagram '典型排水剖面 DRAINAGE SECTION' with 5 legend items" },
{ "id": "03", "title": "電網與能源分配 POWER GRID + ENERGY", "elements": "Cross-section diagram '典型變電站剖面 SUBSTATION SECTION' with 6 legend items" },
{ "id": "04", "title": "通信與網絡骨幹 TELECOM + INTERNET", "elements": "Cross-section diagram '數據中心剖面 DATA CENTER SECTION' with 6 legend items" },
{ "id": "05", "title": "地鐵與地下交通 METRO + SUBSURFACE MOBILITY", "elements": "Cross-section diagram '人民廣場站剖面 PEOPLE'S SQUARE STATION' with 6 legend items" },
{ "id": "06", "title": "道路、高架與循環 ROADS + ELEVATED MOBILITY", "elements": "Cross-section diagram '南浦大橋剖面 NANPU BRIDGE SECTION' with 6 legend items" },
{ "id": "07", "title": "管廊與地下設施 UTILITY CORRIDORS + PLUMBING", "elements": "Cross-section diagram '綜合管廊 UTILITY CORRIDOR' with 8 legend items" },
{ "id": "08", "title": "城市流量與系統協同 URBAN FLOWS + COORDINATION", "elements": "Map diagram '城市運行指揮中心 CITY OPERATIONS CENTER' with 6 legend items" }
],
"bottom_panels": {
"system_logic": {
"title": "城市系統協同邏輯 SYSTEM COORDINATION LOGIC",
"steps": 4,
"labels": ["感知層 SENSING LAYER", "網絡層 NETWORK LAYER", "平臺層 PLATFORM LAYER", "應用層 APPLICATION LAYER"]
},
"city_brain": {
"title": "城市大腦 CITY BRAIN",
"central_node": 1,
"peripheral_nodes": 8
},
"references": {
"depth_scale": { "title": "深度與尺度 DEPTH & SCALE REFERENCE", "icons": 5 },
"map_scale": { "title": "比例尺 SCALE", "markers": 4 }
}
}
}
}
結構化指令的核心優勢:
所以,當不需要考慮保證每次生圖完全一致,還在前期創意生圖階段時:
文本任務請在文本階段完成,何必進入圖像任務呢?
針對已經進入最後精修階段,不能接受圖片有大範圍變化的情況,那隻能考慮使用圖像編輯功能了。
Gxxxxxx2的圖像編輯機制:
支持上傳和圖片大小相同的遮罩層(Mask),進行圖像編輯。
需要注意:
實現本質上依舊是圖像生成任務。
所以官方已經說明:無法保證圖像編輯前後,非遮罩的位置完全不變。
不過我初步嘗試,感覺只修改局部文字,似乎對圖片影響很小。
當然肯定存在很多人眼無法觀測的變化,但太誇張的改變我也還沒試出來過。

這一章就聊這麼多了。
至於網傳Cxxxx可以拆分PSD文件——哈哈我也已經有思路了。
還是那句話:
當你擺脫"圖像編輯"任務的桎梏,天高海闊~
當然,進一步提高Bounding Box準確率、字體準確率,在當前模型能力下,可以進一步使用Agent來實現效果優化:
比如後面接一個多模態模型對比字體差異,給出優化建議,然後進入iteration的優化環節, 用更多token、更多校驗邏輯、更長的延時來換取更好的效果。關鍵還是看業務場景
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。