Kafka is the default answer for event-driven microservices. It’s also massively overused. NATS and Redis Streams solve a large category of messaging problems with a fraction of the operational burden. This comparison gives Java architects a decision framework based on durability requirements, latency SLAs, and team operational capacity — not just throughput benchmarks.
Ask any Java architect “what should we use for messaging?” and the answer comes back almost reflexively: Kafka. It’s the safe choice, the well-documented choice, the LinkedIn-impressive choice. But safety and correctness are not the same thing, and for a surprisingly large number of real-world microservice use cases, Kafka is the equivalent of renting a cargo ship to cross a river.
The truth is that NATS and Redis Streams have quietly matured into serious production-grade messaging options — with dramatically lower operational footprints. Moreover, as of Kafka 4.0 (released March 2025), Kafka itself has simplified considerably with the full removal of ZooKeeper in favour of KRaft. So the whole landscape has shifted. That makes this an ideal moment to revisit the question with fresh eyes and ask: which tool actually fits your situation?

Throughout this article, we’ll move through each system’s core character, look at real performance data, and ultimately build a decision framework you can put in front of a team today. Let’s start with the foundation.
1. Understanding the Design Philosophy of Each System
Before comparing features or numbers, it’s worth spending a moment on philosophy. Each of these three systems was built to solve a slightly different problem, and that origin story shapes everything about how they behave under load and pressure.
1.1 Apache Kafka: The Durable Log
Kafka’s mental model is a distributed, immutable, partitioned log. Producers append messages to the end; consumers read at their own pace by tracking an offset. Nothing is deleted until a configurable retention policy kicks in. This design makes Kafka extraordinary at things like audit trails, event sourcing, and stream processing — workloads where you need to replay history, fan out to many independent consumers, or handle millions of messages per second with full durability. Additionally, Kafka 4.0’s KRaft mode eliminated the long-standing ZooKeeper dependency, making it a single-binary deployment for the first time.
However, that power comes with weight. Even in its simplified 2025 form, a properly HA Kafka cluster still means at least three broker nodes, careful partition planning, consumer group rebalance tuning, and a team that genuinely understands Kafka internals. That’s a real ongoing cost, and it’s worth asking whether every project truly justifies it.
1.2 NATS & JetStream: The Lightweight Cloud-Native Messenger
NATS was built from the ground up for cloud-native environments — low latency, minimal overhead, and extreme simplicity of operation. Core NATS is strictly fire-and-forget publish/subscribe: if no subscriber is listening, the message is gone. That’s fine for many service-to-service communication patterns. For anything requiring durability, JetStream — NATS’s built-in persistence layer — enters the picture. JetStream adds persistent streams, durable consumers, at-least-once delivery, and replay capabilities, all within the same single-binary NATS server.
The critical advantage here is operational simplicity. A clustered NATS deployment with JetStream is dramatically lighter than Kafka, and the Java client library — nats.java — has been actively maintained with a modernised pull consumer API as of late 2024.
1.3 Redis Streams: The Pragmatist’s Choice
Redis Streams, introduced in Redis 5.0, is a persistent, append-only log structure baked directly into a data store your team almost certainly already runs. Consumer groups, acknowledgements, pending entry tracking, and dead-letter-queue patterns are all natively supported. If your team already operates Redis for caching, adding Streams for messaging means zero additional infrastructure — which is a compelling argument that throughput benchmarks simply cannot capture.
“It’s unfair to compare Kafka with something like NATS or Redis since they are very different. But it’s also worth pointing out that the former is much more operationally complex.”— Brave New Geek, Benchmarking Message Queue Latency
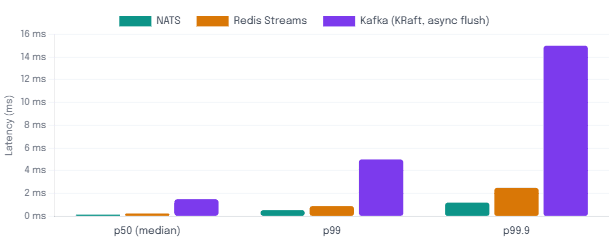
Latency Distribution: p50, p99, p99.9 at 3,000 req/s (1 KB payload)
2. Performance in Context: The Numbers That Actually Matter
Most messaging comparisons lead with throughput: “Kafka can handle a million messages per second!” That number is real, but it’s also irrelevant for the majority of Java microservice deployments, which rarely exceed a few thousand messages per second per service. The numbers that do matter for most teams are tail latencies and behaviour under sustained load.
According to benchmarks from Brave New Geek and Synadia, NATS delivers sub-millisecond latency up to roughly the 99.7th percentile for small payloads. Redis performs similarly, though it is more sensitive to memory pressure. Kafka, on the other hand, holds tight latencies up to around the 94th percentile before disk persistence costs start surfacing in the tail — a well-known trade-off when optimising for throughput and durability simultaneously.
Key Insight If your service has a latency SLA tighter than ~5 ms at p99.9 — think real-time bidding, gaming, or financial pricing feeds — NATS is the strongest candidate. If the SLA is 50–200 ms, all three systems are well within range and operational factors dominate.
Furthermore, large message payloads shift the story. For payloads above 1 MB, Kafka and RabbitMQ actually handle them better than NATS or Redis, which are optimised for many small messages. If your Java services are exchanging large binary payloads or serialised objects, Kafka’s batching and sequential I/O model becomes a genuine advantage.
Operational Complexity Score Across Key Dimensions
3. Durability: What “Message Not Lost” Actually Means for Each System
Durability is often treated as binary — either a system guarantees delivery or it doesn’t. In practice, it’s a spectrum, and where each system sits on that spectrum directly affects which workloads it suits.
| Dimension | Kafka (4.0, KRaft) | NATS JetStream | Redis Streams |
|---|---|---|---|
| Default delivery guarantee | At-least-once | At-least-once (JetStream) / At-most-once (Core) | At-least-once |
| Exactly-once support | Yes (idempotent producers + transactions) | Partial (dedup window) | No (consumer-side idempotency needed) |
| Message replay | Full (by offset, up to retention window) | Full (by seq, time, or policy) | Full (by stream ID) |
| Persistence storage | Disk (sequential write, replication) | Memory or File (configurable) | Memory + optional AOF/RDB to disk |
| Data loss risk | Very low with replication factor ≥ 3 | Low with file storage + replicas | Moderate — depends on AOF/RDB config |
| Long-term retention | Days to weeks (configurable, cost-effective) | Hours to days (disk space limited) | Hours (memory cost limits retention) |
| Dead letter queue | Manual (redirect to DLQ topic) | Native advisory messages on max delivery | Native via XAUTOCLAIM + pending entries |
The takeaway from this table is both obvious and often ignored: Kafka is genuinely superior for long-term durability and large-scale event sourcing. If you need weeks of message history, the ability to replay from day one, or strong exactly-once semantics across complex transactional pipelines, the operational cost of Kafka pays for itself. On the other hand, if your use case is service-to-service notifications, lightweight task distribution, or real-time command dispatch where messages older than an hour are useless, then Kafka’s durability model is solving a problem you don’t have.
Redis Streams Durability Warning: Redis Streams durability depends entirely on your Redis persistence configuration. With default settings (RDB snapshots only), a crash can lose up to several minutes of messages. For anything business-critical, always enable
appendonly yes(AOF) in your Redis config and test recovery behaviour explicitly.
4. Java Integration: What the Code Actually Looks Like
Architecture decisions don’t live in vacuum — they live in code that junior and mid-level engineers need to understand and maintain. So let’s look briefly at what each integration feels like from a Java developer’s perspective.
4.1 NATS JetStream (Java)
The official nats.java client is idiomatic, well-documented, and as of late 2024 provides a clean new pull consumer API. The following example is fully runnable with a local NATS server started via docker run -p 4222:4222 nats -js.
Maven dependency — nats.java
<dependency>
<groupId>io.nats</groupId>
<artifactId>jnats</artifactId>
<version>2.20.0</version>
</dependency>
JetStream durable pull consumer (Java)
// Requires: nats-server running with -js flag
// Start with: docker run -p 4222:4222 nats -js
import io.nats.client.*;
import io.nats.client.api.*;
Connection nc = Nats.connect("nats://localhost:4222");
JetStream js = nc.jetStream();
JetStreamManagement jsm = nc.jetStreamManagement();
// Create a durable stream on subject "orders.>"
StreamConfiguration streamCfg = StreamConfiguration.builder()
.name("ORDERS")
.subjects("orders.>")
.storageType(StorageType.File)
.build();
jsm.addStream(streamCfg);
// Publish a message
js.publish("orders.created", "order-123".getBytes());
// Create a durable pull consumer
ConsumerConfiguration consumerCfg = ConsumerConfiguration.builder()
.durable("order-processor")
.ackPolicy(AckPolicy.Explicit)
.build();
jsm.addOrUpdateConsumer("ORDERS", consumerCfg);
// Pull and process messages
StreamContext streamCtx = nc.getStreamContext("ORDERS");
ConsumerContext consumerCtx = streamCtx.getConsumerContext("order-processor");
consumerCtx.consume(msg -> {
System.out.println("Processing: " + new String(msg.getData()));
msg.ack();
});
4.2 Redis Streams (Lettuce + Spring Data)
Redis Streams integrate cleanly into existing Spring Boot projects via Spring Data Redis. If your team already uses Lettuce or Jedis, the learning curve is minimal.
Redis Streams consumer group (Spring Data Redis)
// Requires: Redis running with: docker run -p 6379:6379 redis
// Spring Data Redis is included in spring-boot-starter-data-redis
import org.springframework.data.redis.connection.stream.*;
import org.springframework.data.redis.core.RedisTemplate;
// Create stream + consumer group (idempotent)
redisTemplate.opsForStream()
.createGroup("orders", ReadOffset.from("0"), "order-processors");
// Publish a message
Map<String, String> body = Map.of("orderId", "order-123", "status", "CREATED");
redisTemplate.opsForStream().add("orders", body);
// Read pending messages for this consumer
List<MapRecord<String, String, String>> messages = redisTemplate
.opsForStream()
.read(Consumer.from("order-processors", "instance-1"),
StreamReadOptions.empty().count(10),
StreamOffset.create("orders", ReadOffset.lastConsumed()));
for (MapRecord<String, String, String> msg : messages) {
System.out.println("Processing: " + msg.getValue());
// Acknowledge after successful processing
redisTemplate.opsForStream().acknowledge("orders", "order-processors", msg.getId());
}
Spring Kafka (for completeness): Kafka’s Java integration through Spring for Apache Kafka is the most mature of the three — excellent tooling, deep Spring Boot auto-configuration, Micrometer metrics, and a large community. If your team is already in the Spring ecosystem and Kafka fits your use case, the developer experience is first-class. The cost is the infrastructure, not the code.
5. Operational Capacity: The Factor Teams Underestimate Most
Here is the dimension that almost never appears in benchmark articles but probably matters most in practice: does your team have the operational capacity to run this system reliably? There is no shame in the answer being “no” — it’s just a fact that needs to inform the decision.
NATS / JetStream
- Single binary, no external deps
- Cluster via supercluster config
- Built-in Prometheus metrics
- Kubernetes-native (Helm chart ready)
- Minimal tuning required
Redis Streams
- Uses existing Redis infra
- Redis Sentinel or Cluster for HA
- Memory sizing is critical
- Monitor pending entry backlog
- AOF configuration needed for durability
Apache Kafka
- KRaft: no ZooKeeper (since 4.0)
- Still needs 3+ brokers for HA
- Partition planning is an art
- Consumer rebalances need tuning
- Schema registry often needed
Consequently, for small-to-medium engineering teams — say, fewer than 20 engineers with no dedicated platform team — Kafka’s ongoing operational demands are a meaningful tax. Conversely, if you already run a managed Kafka service like Confluent Cloud or Amazon MSK, that tax is largely offloaded. The managed-vs-self-hosted dimension is therefore one of the first questions in any honest decision conversation.
6. The Decision Framework: Three Questions Before You Choose
Rather than offering a single prescriptive answer, the most useful thing this article can leave you with is a repeatable set of questions to ask before committing to a technology. Specifically, the following three questions narrow the field in order of importance.
6.1 Ask These Three Questions First

With those three lenses, the comparison table below becomes a quick reference rather than a full research exercise — because in practice, the right answer almost always emerges from the intersection of those three constraints, not from a sixth decimal of throughput data.
| Use Case | Best Fit | Why |
|---|---|---|
| Internal service command dispatch (fire-and-forget) | Core NATS | Minimal overhead, sub-ms latency, no infra needed |
| Task queue with retry + DLQ, < 1M msgs/day | Redis Streams | Native consumer groups, zero extra infra if Redis already running |
| Durable microservice events, need replay | NATS JetStream | At-least-once, replay by sequence, single binary, low ops overhead |
| Event sourcing / audit trail (long retention) | Kafka | Immutable log, weeks of retention, exactly-once semantics |
| Stream processing (Flink, ksqlDB, Kafka Streams) | Kafka | Ecosystem integration — no realistic alternative |
| IoT telemetry / edge messaging at high fan-out | NATS JetStream | Lightweight client, wildcard subjects, edge-cluster support |
| Real-time analytics ingestion (> 1M msgs/s) | Kafka | Sequential disk I/O, partitioned throughput designed for this |
| Microservice integration on a small team, existing Redis | Redis Streams | No additional infra cost — operational leverage is real |
6.2 The Honest Verdict
Kafka earns its place — for the workloads it was designed for. If you’re building real-time data pipelines, event sourcing systems, or stream-processing architectures that integrate with Flink or Kafka Streams, it remains the gold standard. The Kafka 4.0 KRaft migration meaningfully reduces operational friction, so the “too complex” argument has weakened. That said, the question is not whether Kafka is good — it clearly is. The question is whether it is proportionate to your specific problem. For the majority of Java microservice communication patterns — service events, task queues, command dispatch, notification flows — NATS JetStream and Redis Streams solve the problem with a fraction of the infrastructure cost. The simpler tool wins when the simpler tool is sufficient. And more often than architects admit, it is.
7. What We Have Learned
Throughout this comparison, a clear and repeatable pattern emerges. The right messaging tool is not the most powerful one — it’s the most proportionate one. Kafka’s architectural maturity, especially post-4.0 with KRaft fully replacing ZooKeeper, makes it a genuine single-binary event streaming platform with excellent Java ecosystem support. However, it still demands partition planning, consumer group tuning, and a team that understands distributed log semantics. For workloads where those capabilities are genuinely needed — long retention, replay, stream processing, millions of messages per second — that investment is justified.
NATS JetStream, on the other hand, delivers sub-millisecond tail latencies, durable at-least-once semantics, and a dramatically simpler operational footprint. It is the strongest choice for microservice architectures that need messaging without the infrastructure weight — particularly on smaller teams or in edge/IoT scenarios. The Java client has matured significantly and integrates well with Spring Boot.
Redis Streams occupies a pragmatic middle ground: if your team already runs Redis, you have a fully functional consumer-group message stream available at zero additional infrastructure cost. It is not the right choice for long-term retention or high-volume event sourcing, but it solves a very large category of internal messaging problems elegantly and with tooling your team already knows.
The decision framework presented here — durability requirements, latency SLA, team operational capacity — gives you the three lenses that matter most in practice. Apply them before defaulting to Kafka, and you may well find that the simpler answer is also the better one.