This post is part two of a two-part series (read part one here, if you haven’t yet) brought to you by DY Labs, an initiative by members of our Product and R&D departments who have a passion for experimentation and building developer resources for the greater digital marketing and engineering communities. This series focuses on the cohort’s latest project, Funnel Rocket, which is a serverless query engine optimized for complex user-centric queries at scale. In part two, Elad Rosenheim, our VP of Technology, walks through the inception of Funnel Rocket, how it works, and the potential applications it can be used for.
An earlier version of this post was previously published by Elad on Medium.
Funnel Rocket is a serverless query engine optimized for complex user-centric queries at scale. It allows companies to look for users matching a nuanced set of conditions over time and glean fine-grained statistics so they can better understand a given group of users and take action. It was built at Dynamic Yield to answer on-demand interactive queries quickly and cost-efficiently and is now open-sourced for use by the wider developer community. With Funnel Rocket, you can build custom ad-hoc analytics capabilities over big datasets of user activity – at a large scale and with minimal overhead in terms of operations and resource usage. Below, learn about the challenges we set out to solve with Funnel Rocket, what the building process looked like, how the engine can be a solution for engineers looking to overcome similar challenges, and if cloud native actually means anything.
As a SaaS vendor, success is defined by how many teams install or use your product for their websites and apps. Whether you’re selling tools for analytics, recommendations, personalization, guided onboarding, surveys, media serving, etc., one crucial feature for your customers is the ability to freely explore the complexities of end-user behavior. This requires understanding the makeup and value of distinct user groups and evolving the site accordingly, potentially tailoring different experiences on their site to different user groups (Note: this is also achievable without tracking people across the web or storing their personal info).
Marketers onboarding software for this purpose are looking for a UI that enables ad-hoc exploration, giving them the ability to look for users who’ve met a nuanced set of conditions over time, perhaps those who have completed a specific sequence of actions in a particular order. Afterward, they want to be able to access detailed analytics showing not only the size of the group but also detailed metrics on how this audience group stands out from the rest of their user base.
For a glimpse of what this type of feature looks like in the Dynamic Yield platform, jump to minute 0:27 in the video.
Such interactive queries are a challenge to pull off using existing tools — using SQL or NoSQL. Getting the query syntax right is cumbersome, but the main issue centers around performance at scale. Consider what it takes to implement this as a GROUP BY <USER ID> query.
No query engine I know will let you define in one step the whole sequence of actions that each group (i.e. each user) should match, in order. You will need to break this into multiple sub-queries, passing intermediate data between them, requiring multiple passes through the engine. In each pass, the engine will search (per each user) for a row whose timestamp is later than the row found in the last step, for that specific user. Such complex cases are typically expressed via composition, by design. Therefore, the query engine doesn’t always offer the simplest shortcut for every imaginable need.
There’s a performance cost to that complexity, however. On a small scale, it will work fine. However, take a dataset of 20 million users and that’s 20 million groups per query. Is it doable? Yes, assuming the user activity data is bucketed in the right way. Is it any fun, fast, or cheap? Not really. (Remember, I set some lofty goals at the end of my previous post: I want maximum processing speed just when I need it and to pay for exactly the needed compute resources).
Managed query engines (e.g. Amazon’s Athena, Google’s BigQuery) do offer on-demand pricing by the amount of data actually scanned. Your queries are executed behind the scenes by a small slice of their vast army of workers. This option was simply not available when we started, and thus we’ve built our homegrown solution to this problem with Elasticsearch + custom plugins. It was cool for a period of time, but overtime became an operational and maintenance burden.
Considering the managed tools available to us now, there were some things I was looking for:
The user-centric query feature is a core element of the Dynamic Yield platform, so it was important to us to have control of our capabilities, meaning that a “build” option was on the table. Of course, we didn’t set out to match the extensive feature-set of general-purpose query engines – we set out to solve one problem well. The result? Funnel Rocket.
Here’s a glance at some of the core components of the solution we set out to build:
To merge all of these together, we wrote an API server and task worker components in Python 3 that are pretty lightweight. The API server has endpoints for managing datasets and running queries, expressed in JSON format. It takes care to validate a given query, invoke the needed workers, track their progress, retry tasks as necessary, and aggregate the results back to the client. Additionally, the client has the option to ask for progress updates via HTTP streaming.
Here’s how it works, from the ground up:

Icon credit: Noun Project
Pandas and its concept of DataFrames are widely used in the data engineering/science communities. Pandas itself is a library embedded within a single process, and we planned for each worker process to handle one file at a time out of the whole dataset, rather than worrying about any larger context. Additionally, Pandas is fairly performant and feature-rich out of the box. If it doesn’t offer some needed functionality, you can have it run Python code (though that’s pretty slow). On the other end, you can use Numba to generate optimized LLVM-compiled code from carefully written Python functions. In my experience, that does deliver the (performance) goods.
We use Apache Arrow to augment Pandas with excellent support for Parquet files and will probably use it much more going forward. Unlike Pandas, it supports nested data structures natively and has a growing feature set for computation and querying of its own. When a worker process is allocated a task, it transforms the JSON query syntax into a series of in-memory operations over a DataFrame and returns the aggregated results for the single file it was assigned to process. But for each worker to process independently, files in the dataset must already be partitioned (or “bucketed”) by user ID into a set of “n files,” so that each file holds data about a distinct set of users, as well as guarantee each user’s data is gathering in a single file. That shuffling stage is arguably the biggest performance pain in big data. However, this is only executed when a dataset is being created / updated, rather than for each query.
Serverless is quite polarizing, I know; the whole paradigm, the proprietary implementations, the latency, the constraints… I did not come into this project sold on the idea, to be honest. For this use-case, however, AWS Lambda did prove itself to be reliable, fast, and (gasp) cost-efficient. Additionally, 99% of the code is agnostic to it and can be easily extended to support other implementations.
There are several reasons why it works well for Funnel Rocket:
Latency
Queries in Funnel Rocket are measured in seconds, not milliseconds. When Lambda function instances are cold, they will normally take ±3 – 5 seconds to get to the point where the handler function starts running (that time does include running all imports in the handler’s source file).
Luckily, Funnel Rocket serves a rather “power user” feature, so while there tends to be few customers concurrently using the feature, each user typically runs multiple iterations of a query over their own dataset, progressively tweaking conditions to zoom in on the user population. This means that for most queries, not only are Lambda functions warm, but performance can further benefit from local caching of data files — if you can make that work for serverless. More on that in a bit…
Cost
The per/second cost is indeed higher than all less-managed options. It’s a spectrum, really: from spot instances, through reserved VMs to on-demand ones, to Fargate, etc. — the more you need to worry about, the less you pay in compute (and more in operations). However, you only pay for actual processing time, from the exact millisecond your entry point starts execution until the millisecond it ends. That excludes the bootstrap time and the function instance staying warm for a while to be reused. We found this model to fit our query patterns well: maximum scale when there’s a query, zero resources, and cost at all other times. As a side effect, the cost is directly correlated to milliseconds of compute used — for each query request Funnel Rocket returns the exact cost back.
Ease of invocation
Funnel Rocket uses the asynchronous Lambda invocation API, making it easier to launch hundreds of jobs (or more) quickly, without needing to block waiting on all API calls to complete. Internally, AWS manages such calls with a queue, but we’ve found that it adds no meaningful latency in normal operation. This mode has an important extra benefit: in moments of momentary pressure, you mostly avoid rate limiting on concurrent function executions.
Serverless, however, is not the only way to fly. I wanted the ability to have a small army of workers that can run locally, on physical machines, VMs, or containers — while still making it easy to scale up or down, distribute work, handle failures, etc. That’s where Redis comes in.
Two traits of Redis, taken together, make it a natural choice for a wide range of functionality:
Redis is used by Funnel Rocket to:
In the case of repeated queries over the same dataset, how do we make warm functions work on the same file they’ve downloaded before? There is no direct way to call a specific warm instance. Instead, the API server lets the workers choose for themselves which file to work on. When a query starts, it publishes the list of files as a Redis set. Then it invokes workers, asking them to each take one file from the set. Those with matching local files will attempt to grab that same file again. Others will grab a part at random. This mechanism is not guaranteed to always have maximum efficiency, but it does reduce orchestration needs to a minimum. The API server meanwhile, knows nothing.
Multiple API server instances can run concurrently, only sharing the list of registered datasets between them. A portion may run ad-hoc queries via serverless workers, while others run batch work through cheap spot-instances at scheduled times. Both deployment options push much of the complexity into battle-tested tools and have Redis as their single stateful component.
As a basic benchmark, I’ve created a dataset that mimics user behavioral data (page views, events, clicks on campaigns, etc.) to reflect real data we collect in Dynamic Yield as closely as possible.
I’ve made two versions of the dataset: a smaller one with 100 million rows, the other with 500 million. Each row holds a user ID, a timestamp, the type of activity and related data fields (URLs, browser type, country, event type, product SKU, etc.).
I’ve run a basic funnel query, the results of which you can see below: find the users who have performed a pageview, then added a product to cart, then made a purchase — and return the matching user count at each step.
For both datasets, I measured the time-to-run and compute cost in two scenarios: when all Lambda function instances are cold, and when all are warm. Each scenario ran 10 times.
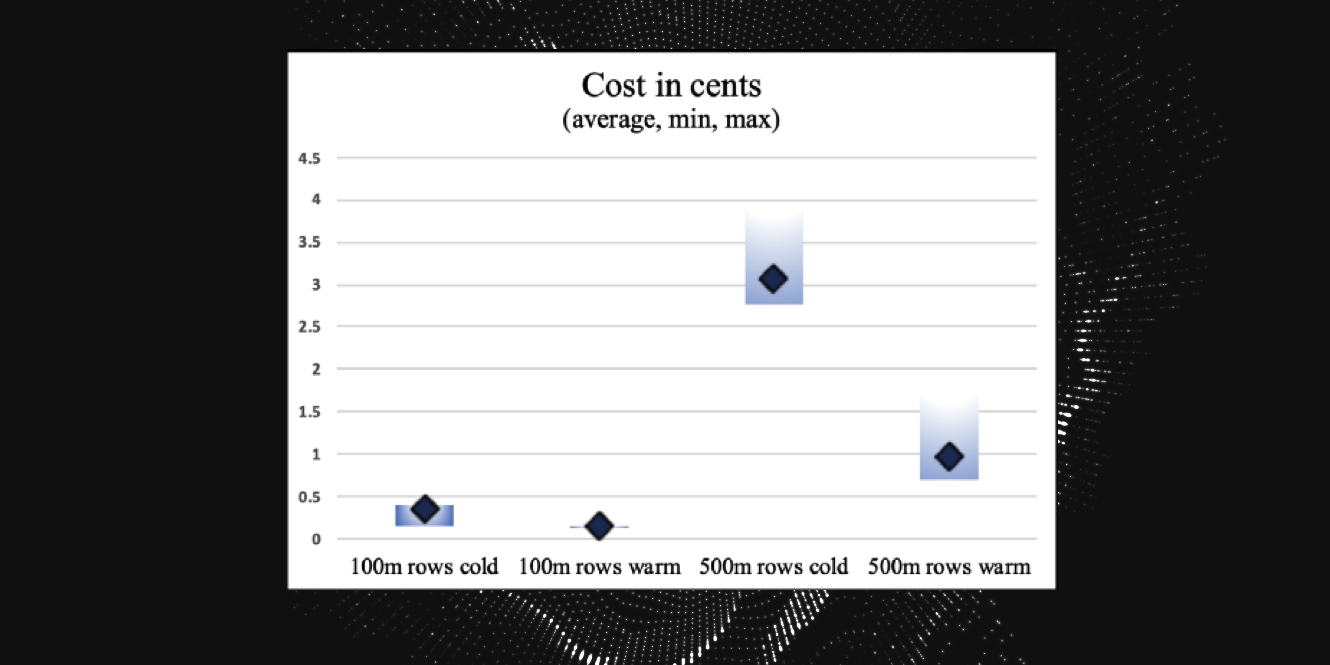

For 100 million rows:
Scenario | Min Time | Max Time | Avg Time | Min Cost | Max Cost | Avg Cost |
| All Cold | 2.3 secs | 6.5 secs | 5.43 secs | 0.15 cents | 0.4 cents | 0.35 cents |
| All Warm | 1.78 secs | 4.56 secs | 2.2 secs | 0.13 cents | 0.146 cents | 0.14 cents |
For 500 million rows:
Scenario | Min Time | Max Time | Avg Time | Min Cost | Max Cost | Avg Cost |
| All Cold | 8.56 secs | 10.39 secs | 9.17 secs | 2.77 cents | 3.93 cents | 3.08 cents |
| All Warm | 3.42 secs | 5.51 secs | 4.34 secs | 0.7 cents | 1.7 cents | 0.98 cents |
Things to note:
Building Funnel Rocket has left me with a lingering thought: Is “cloud native” a real thing? It was personally exciting for me to see all of this working in practice. Of course, there are missing features to wish for, surely a few bugs, and a bunch of optimizations and improvements yet to done (see the high-level roadmap). But all-in-all, I believe the software that resulted encapsulates what “cloud native” is about:
This exercise has led me to finally believe in cloud native, and if you’re interested in learning more about Funnel Rocket and playing around with it yourself, access it on Github. And if you’re interested in joining our growing Product and R&D teams, here at Dynamic Yield, check out our open roles.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。