2016-06-21
4 min read
We would like to share more details with our customers and readers on the internet outages that occurred this morning and earlier in the week, and what we are doing to prevent these from happening again.
June 17 incident
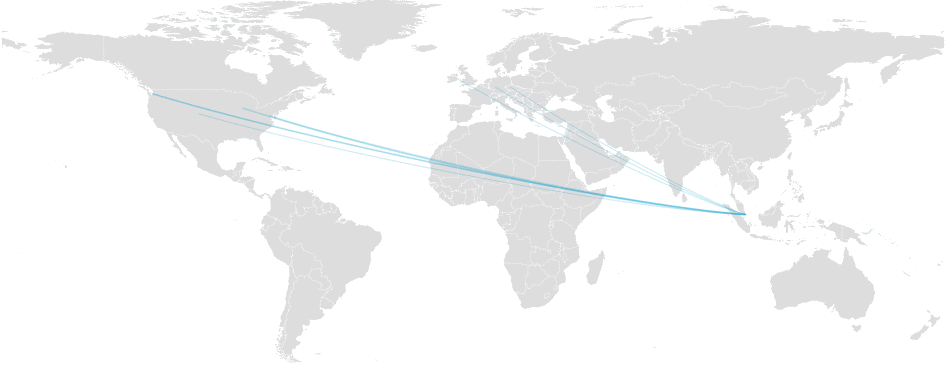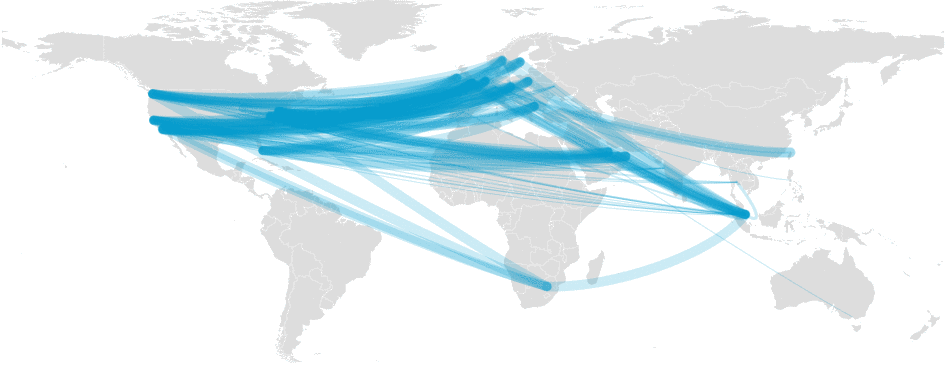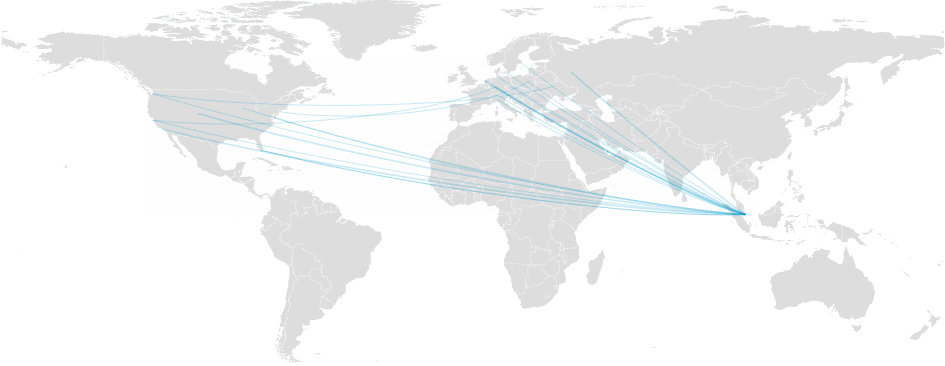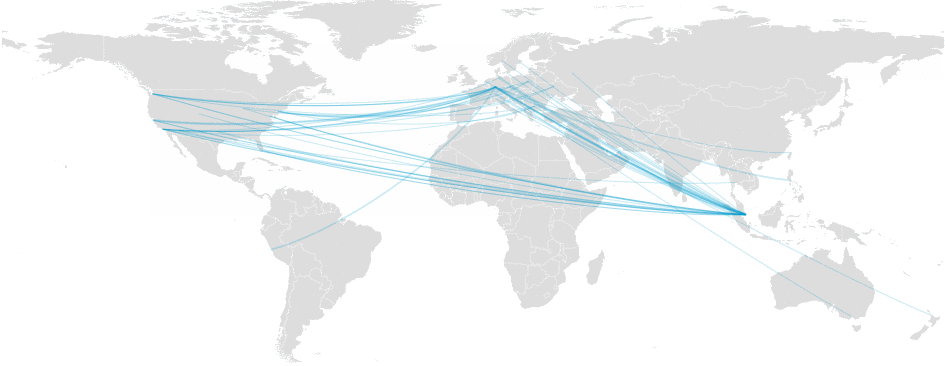
On June 17, at 08:32 UTC, our systems detected a significant packet loss between multiple destinations on one of our major transit provider backbone networks, Telia Carrier.In the timeframe where the incident was being analysed by our engineers, the loss became intermittent and finally disappeared.
Packet loss on Telia Carrier (AS1299)
Today’s incident
Today, Jun 20, at 12:10 UTC, our systems again detected massive packet loss on one of our major transit provider backbone networks: Telia Carrier.
Packet loss on Telia Carrier (AS1299)
Typically, transit providers are very reliable and transport all of our packets from one point of the globe to the other without loss - that’s what we pay them for. In this case, our packets (and that of other Telia customers), were being dropped.
While Internet users usually take it for granted that they can reach any destination in the world from their homes and businesses, the reality is harsher than that. Our planet is big, and the Internet pipes are not always reliable. Fortunately, the Internet is mostly built on the TCP protocol which allows lost packets to be retransmitted. That is especially useful on lossy links. In most cases, you won’t notice these packets being lost and retransmitted, however, when the loss is too significant, as was the case this morning, your browser can’t do much.
Our systems caught the problem instantly and recorded it. Here is an animated map of the packet loss being detected during the event:
CloudFlare detects packet loss (denoted by thickness)
Because transit providers are usually reliable, they tend to fix their problems rather quickly. In this case, that did not happen and we had to take our ports down with Telia at 12:30 UTC. Because we are interconnected with most Tier 1 providers, we are able to shift traffic away from one problematic provider and let others, who are performing better, take care of transporting our packets.
Impact on our customers
We saw a big increase in our 522s errors. A 522 HTTP error indicates that our servers are unable to reach the origin servers of our customers. You can see the spike and the breakdown here:
Spike in 522 errors across PoPs (in reaching origin servers)
On our communication
Communicating in this kind of incident is crucial and difficult at the same time. Our customers understandably expect prompt, accurate information and want the impact to stop as soon as possible. In today’s incident, we identified weaknesses in our communication: the scope of the incident was incorrectly identified in Europe only, and our response time was not adequate. We want to reassure you that we are taking all the steps to improve our communication, including implementation of automated detection and mitigation systems that can react much more quickly than any human operator. We already have such systems in place for our smaller data centers and are actively testing their accuracy and efficacy before turning them on for larger PoPs.
Taking down an important transit provider globally is not an easy decision, and many cautious steps are to be taken before doing it. The Internet and its associated protocols are a community based on mutual trust. Any weak link in the chain will cause the entire chain to fail and requires collaboration and cooperation from all parties to make it successful.
We know how important it is to communicate on our status page. We heard from our customers and took the necessary steps to improve on our communication. Our support team is working on improvements in how we update our status page and reviewing the content for accuracy as well as transparency.
Building a resilient network
Even as CloudFlare has grown to become critical Internet infrastructure sitting in front of four million Internet-facing applications, investing in greater resiliency continues to be a work-in-progress. This is achieved through a combination of greater interconnection, automated mitigation, and increased failover capacity.
We fill our cache from the public Internet using multiple transit providers (such as Telia), and deliver traffic to local eyeball networks using transit providers and multiple peering relationships. To the extent possible, we maintain buffer capacity with our providers to allow them to bear the impact of potential failures on multiple other networks. Spreading out traffic across providers allows for diversity and reduces the impact of potential outages from our upstream providers. Even so, today’s incident impacted a significant fraction of traffic that relied on the Telia backbone.
_Traffic switching from one provider to the other after we reroute_
Where possible, we try to failover traffic to a redundant provider or data center while keeping traffic within the same country.
BGP is the protocol used to route packets between autonomous networks on the Internet. While it is doing a great job at keeping interconnections alive, it has no mechanism built in to detect packet loss and performance issues on a path.
We have been working on building a mechanism (which augments BGP) to proactively detect packet loss and move traffic away from providers experiencing packet loss. Because this system is currently activated only for our most remote and smallest locations, it didn't trigger in this morning’s incident. We plan to extend the capability in the next 2 weeks to switch from a manual reaction to an automatic one in all our POPs. For example, in this screenshot, you can see our POP in Johannesburg being automatically removed from our network because of problems detected when connecting to origin servers:
Johannesburg PoP gracefully fails over to nearest PoP
Summary
We understand how critical our infrastructure is for our customers’ businesses, and so we will continue to move towards completely automated systems to deal with this type of incident. Our goal is to minimize disruptions and outages for our customers regardless of the origin of the issue.