
Самый просто способ запустить локальную LLM - это установить ollama или LM Studio. Это быстро и просто, но вы теряете и в скорости, и в качестве. Почему UD_Q4_K_XL лучше при том же размере, почему квант Q3 может быть медленнее чем Q4. Хорошая ли идея взять REAP для вырезания ненужных экспертов из MoE. Кто быстрее, Linux или Windows. В общем как выжать больше из локальных LLM на домашнем железе.
Что означает 35B и что означает A3B
Для MoE моделей основной шаблон именования это Qwen3.6-35B-A3B.
Qwen3.6 - имя модели и её версия. Число до точки - это мажорное обновление, часто связано с каким-то существенным обновлением архитектуры, число после точки - обновление внутри архитектуры.
35B - общее количество параметров модели. B - это Billion, то есть 35 миллиардов параметров.
A3B - количество активных параметров, сокращение от Active 3B.
Чем больше параметров активно во время генерации нового токена, тем лучше качество результата, но требуется больше вычислений, значит медленнее генерация и ниже t/s.
У Dense моделей всегда активны все параметры, при прочих равных такие модели будут "умнее" MoE версий, но скорость генерации в разы ниже. У MoE наоборот, скорость работы выше, но качество ответов может плавать даже в рамках одной сессии.

Избыточный размер моделей, почему BF16 это FP32, а не FP16
LLM состоит из слоев, каждый слой состоит из набора чисел, числа сгруппированы в матрицы-тензоры, тензоры разделены на 2 блока: блок Внимания (Attention) и блок FFN. Параметры модели - это суммарное количество чисел из которых состоят матрицы.
Если числа нужно как-то хранить, если их хранить в формате float32, который занимает 32 бита или 4 байта, то если посчитать вес модели размером 35B, 35 млрд умножить на 32 бита, то такая модель будет весить 35.000.000.000 * 32 = 1.120.000.000.000 бит или 130 Гб.
И это маленькая модель 35B, а учитывая, что модели могут доходить до 700B (DeepSeek R1/V3.1, GLM-5.1) и даже до 1T (Kimi K2.5, Qwen3.6-Plus), то такой объем не просто большой, он огромен, нужно как-то его уменьшить.
GPU умеют быстро перемножать матрицы float32 и float16, а для LLM и нужно перемножать много таких матриц, поэтому выбор был из этих двух форматов. Но если float32 такой большой, то почему не взять за основу float16, что уменьшит размер моделей в 2 раза?
Для того, чтобы понять это, надо посмотреть как распределены биты в f32 и f16.
В f32 за диапазон отвечает экспонента размером в 8 бит, а за точность мантисса, которой отведено 23 бита.

В f16 экспонента урезана до 5 бит, а мантисса до 10 бит. Диапазон урезан, а точность сохранена высокой.

В этом и есть проблема. Для нейросетей важнее ширина диапазона значений, а не его точность. Во время обучения происходит перераспределение весов, создаются группы со значениями выше, а другая группа со значениями ниже, кроме этого происходят выбросы, во время градиентного спуска спускаемся до порядков 10^-7 или даже 10^-8. Функция активации не должна возвращать бесконечность если числа выходят за границы, и алгоритм backpropagation мог корректировать малыми шагами сдвиги весов.
Для того, чтобы это работало, числа должны иметь очень широкий диапазон принимаемых значений. В f32 за счет экспоненты в 8 бит обеспечивался нужны диапазон. В f16 экспоненту урезали до 5 бит, и во время обучения это приводило к тому, что обучение застревало, веса не корректировались, backpropagation не мог их сдвинуть, или они уходили в NaN из-за бесконечности на активации. Чтобы использовать f16 приходилось применять различные ухищрения, смешивать fp32 и fp16 обучаясь в Mixed Precision, что приводило к дополнительному увеличение расхода памяти даже выше чем было на fp32, скорость обучения падала. Снижался расход на инференс, так как веса теперь были в fp16, но сложность обучения вырастала.
Простым архитектурным решением этой проблемы было бы в том, что если в 16-битном формате сохранить экспоненту 8 бит, как и была в fp32, а урезать мантиссу, тогда бы точность осталась как и было в fp32, обучение бы проходило гладко, а размер уменьшился бы в 2 раза.
Так появился формат BF16, ширина диапазона сохранилась, а точности для обучения хватало.

Квантование моделей
Инференс намного проще чем обучение, и если развить идею, что диапазон важнее точности, то можно применить такое квантование. Все числа с плавающей точкой преобразовать в целые числа с учетом масштабирования пожертвовав равномерностью шага, но сохранив расстояние между числами. Таким образом квантование в Int8 выглядело бы вот так:

Если приглядеться, то можно заметить разницу, но тут сохранено главное, масштаб и структура, поэтому на качестве инференса это почти не сказалось. Если идти дальше, то самый простой способ это квантовать всё до Int4, тут уже разницу заметить куда проще, но структура в целом сохранена.
Так работал квант Q4_0 в llama.cpp, он не сохранял качество Q8, но работал очень быстро на CPU, поэтому такой квант до сих пор выпускают.
Если идти ещё дальше, то можно дойти до квантования уровня 1.58-бита, то есть будет всего 3 значения [-1, 0, 1]. Это тоже работает, есть целые проекты которые занимаются 1-битными моделями.
Примером такой 1-битной модели LLM Bonsai 8B 1-Bit.

Текст связный, код запускается, скорость для Dense 8B модели на 4060 высокая. Но вот над качество нужно ещё поработать.

Квантовать в лоб не самое эффективное решение. В какой-то момент к проекту llama.cpp присоединился ikawrakow, создатель K-квантов и i-квантов, и он занялся этим вопросом, что в итоге перевело качество квантования на новый уровень.
Можно выделить 3 основные вещи, кроме самих алгоритмов квантования, которые позволяют сильнее, но сохранять качество:
Блочное квантование. Модель разбивается на блоки, в каждом блоке применяется свой коэффициент scale. Это повышает точность отдельных блоков, а так как модель не однородна, то это повышает точность всей модели.
Добавление калибровочной imatrix. Специальный датасет, в котором собрано типовое использование, активирует различные блоки, те блоки, которые откликаются лучше, квантуются меньше, другие сильнее.
Разделение уровня квантования тензоров attn и ffn. Качество "ума" модели напрямую зависит от качества Внимания, если attn квантовать слабее или оставлять оригинал, то несмотря на более агрессивное квантование ffn, общее качество сохраняется на высоком уровне.
ikawrakow добавил новые алгоритмы квантования, новые схемы квантования, и ввел смысловые обозначения таким квантам. Например, Q4_K_M или IQ4_XS:
Q4 - цифра рядом с Q означает какой битностью будет квантовано тело модели FFN.
K или I - это статичный квант или imatrix квант.
M - буква показывает на сколько выше будут квантованы тензоры внимания. Если S - то либо тот же уровень, либо на 1 шаг выше, и так далее. Встречаются обозначения S, M, L, XL.
XS - это алгоритм квантования внимания с использование imatrix. За счёт imatrix i-кванты весят меньше, и по качеству выше, но требуют в 2 раза больше вычислений на деквантование в момент инференса.
Качество квантов росло, улучшались математические алгоритмы, улучшались походы к созданию imatrix, но в какой-то момент ikawrakow рассорился с ggerganov, и ушел из проекта, он создал форк ik_llama.cpp, где продолжает создавать продвинутые SOTA кванты, и уже добился новых успехов. Новый IQK кванты весят меньше, качество выше, скорость лучше.
Такие кванты ik_llama особенно хорошо помогают, когда не хватает несколько Гб чтобы вместить модель целиком на GPU получая огромный буст скорости, так как если модель не влезает целиком в GPU хотя бы 1 слоем, происходит внушительное падение скорости. Или если надо вместить квант в 192 Гб RAM, запуская DeepSeek V3.2 или GLM-5.1 не залезая на диск.
Проблема Q4_K_M
Стандартный квант всегда и везде это Q4_K_M. Он будет предложен по умолчанию в любой среде, например, если запустить ollama run qwen3.6,то загрузится именно Q4_K_M квант.
Тоже самое в LM Studio, вначале будут их варианты квантов в стандартном виде, и по умолчанию будет загружаться Q4_K_M:
Классические кванты Q4_K_M устарели, они и там и там создаются по старой статичной схеме, которая когда-то не плохо работала, но с тех пор выработали более эффективные схемы квантования, которые позволяют либо снизить объем в Гб, либо в те же Гб засунуть больше качества.
Другая проблема ollama в том, что вы никогда не знаете, что именно вы загружаете. Например, выполнив команду ollama run gemma4 вы получите какую-то gemma4, которую они решили делать стандартной. Gemma4 представлена в 4 варианта: E2B, E4B, 26B-A4B, 31B, и в большинстве случаев интересна будет 26B-A4B, а не слабая E4B. Тоже касается и ollama run qwen3.5, так как qwen3.5 представлена в 7 вариантах.
Для конкретной версии нужно использовать команду ollama run gemma4:26b, но это не решает проблему с выбором кванта.
Динамическое квантование
Когда созданные кванты начали активно сравнивать по показателям PPL и KLD, то начали искать новые схемы квантования, основываясь не на четкую структуру создания, а были динамичную. Теперь через один слой ffn_down может квантоваться сильнее, а ffn_up наоборот. Общие эксперты, которых в MoE моделях от 0 до 3-4 штук квантуются высоко, в Q6 или Q8, а MoE эксперты квантуются сильнее. И так далее.
Основные создатели квантов Unsloth, Ubergarm, Bartowski, mradermacher начали создавать свои рецепты и свои imatrix калибровочные датасеты, в то время как LM Studio, GGML, ollama придерживаются старой статичной схемы квантования.
Динамическое квантование позволяет зайти ниже квантов Q4, и дальше мы посмотрим на что способно квантование UD-Q2_K_XL.
UD-Q4_K_XL лучше чем Q4_K_M
Для замеров на сколько квант деградировал используют метрики KLD.
Сравнить нужно с BF16 версией, так как нам интересно на сколько кванты деградировали по сравнению с оригиналом, а не на сколько дрейфуют относительно друг друга.
Нужен какой-то тестовый бенчмарк из которого нужно извлечь все логиты:
.\llama-perplexity -m "Qwen3.6-35B-A3B-BF16-00001-of-00002.gguf" -f "prompt.txt" --save-all-logits "ref_logits.bin" --ctx-size 4096
Вместо prompt.txt можно использовать стандартный wiki.test.raw, либо свой датасет. Для BF16 нужно 65 Гб видеопамяти, запускать придется в режиме fit, который активирует ncmoe, из-за этого процесс создания логитов займет минут 25-30, а сам файл с логитами будет весить 70 Гб.
Само сравнение уже происходит быстрее, такой командой:
.\llama-perplexity -m "Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf" -f "prompt.txt" --kl-divergence --kl-divergence-base "ref_logits.bin" --ctx-size 4096
Проведем сравнение интересующих нас квантов Qwen3.6 35B-A3B:

Классический Q4_K_M выступает на уровне UD-Q3_K_XL, который легче на 4.4 Гб.
UD-Q4_K_XL обходит классический Q4_K_M, но весит на 1.2 Гб больше.
UD-Q2_K_XL при равном весе показывает себя лучше чем IQ2_M.

Unsloth постоянно работают над оптимизацией своих квантов, у них собран хороший датасет для imatrix и гибкая схема динамического квантования Unsloth Dynamic 2.0.
Они ввели новую категорию XL (extra Large) для квантования attn, оставляя Внимание ближе к оригиналу, без сильного квантования. И добавляют к имени квантов UD там, где распределение квантования следует их рецепту создания, а не стандартному.
Так же провели масштабное исследование на Qwen3.5 по замерам качества квантов, чтобы найти лучший рецепт: https://unsloth.ai/docs/models/qwen3.5/gguf-benchmarks
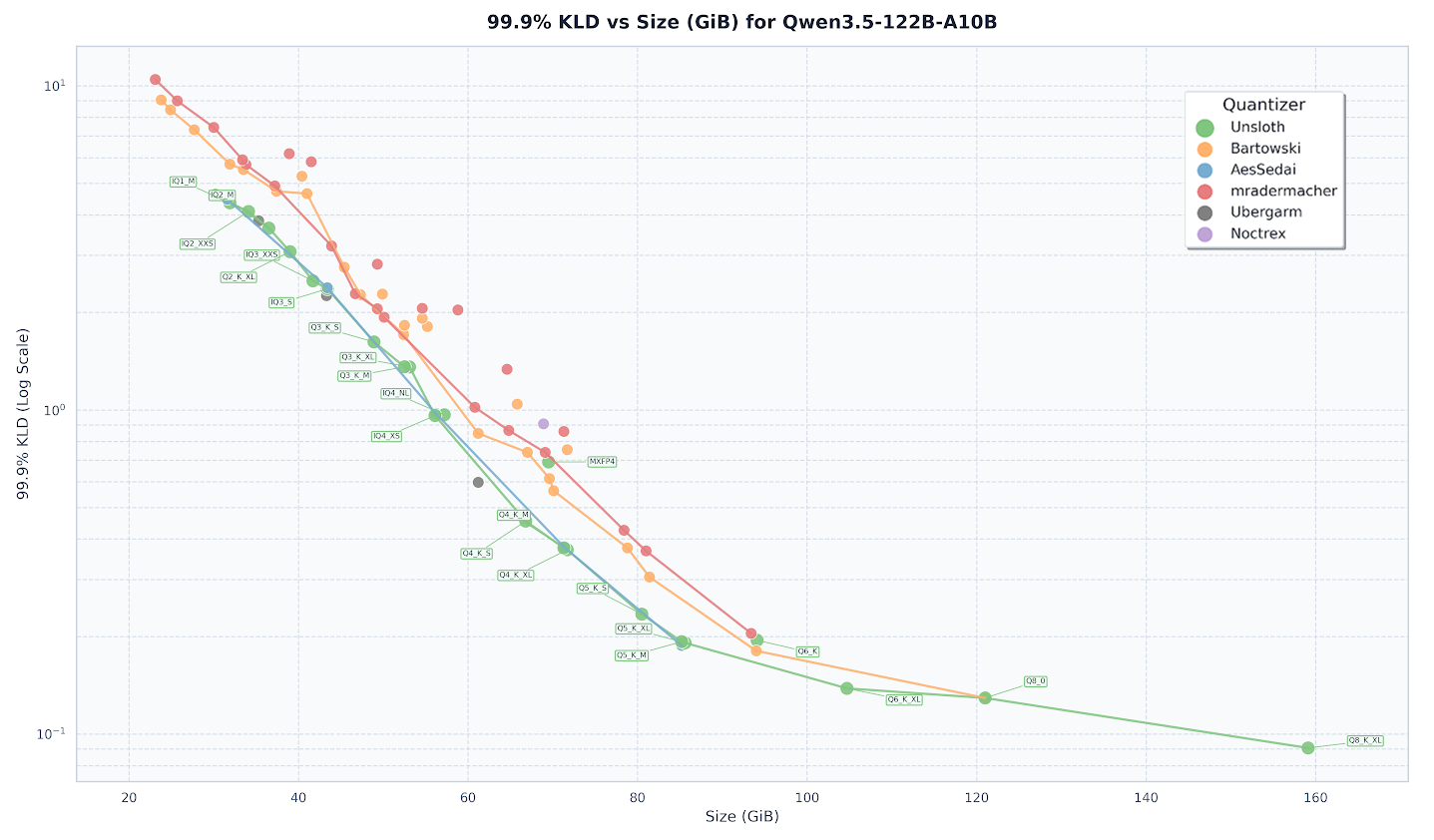
Вначале, они выпускали UD квант только в размере UD-...-XL, но с недавнего времени они начали выпускать UD для всех вариантов квантования.
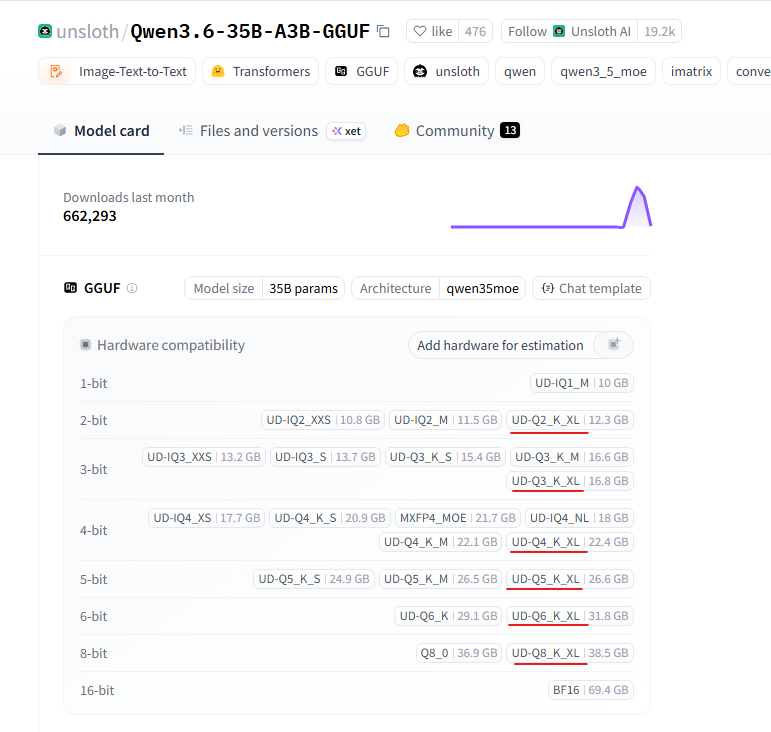
В LM Studio можно найти эти кванты, добавляя в строке поиска "unsloth", по умолчанию квант будет не XL, поэтому нужно будет выбрать его из списка. Не отключаемая функция в LM Studio это загрузка Vision, который нужен не всегда, но он будет занимать память.
Где скачать llama.cpp и как запустить на AMD и Nvidia
Ollama и LM Studio устанавливают глобально с систему, а llama.cpp поставляется в виде portable архивов, поэтому нужно скачать и разархивировать, чтобы получить доступ к exe файлам.
Скачать в официальном репозитории: https://github.com/ggml-org/llama.cpp/releases

Для Nvidia видеокарт нужно скачать CUDA 12 версию и CUDA 12.4 DDLs.
Для Nvidia 5000 серии лучше скачать CUDA 13 и CUDA 13.1 DDLs, если драйвера свежие.
Для AMD и Intel нужно скачать Vulkan, DLL не требуются.
Также стоит обновить драйвера, без этого могут быть просадки до 30-40% в генерации.
Для AMD всё просто, нужно скачать только Vulkan архив и разархивировать его, для для CUDA версии нужно скачать дополнительные DLL и разархивировать их в папку с llama.cpp.
Для RTX 5000 серии лучше использовать драйвера CUDA 12.8 и выше, там лучше поддержка архитектуры blackwell.
Когда вы скачали 2 архива для CUDA, один с llama.cpp, другой с DLL, то разархивировать их:

После чего перенести cublast DLLs в папке с llama.cpp
Дальше нужно открыть папку с llama.cpp в терминале, или открыть через Windows Terminal, либо в строке пути написать pwsh или cmd.
Все модели находятся на huggingface: https://huggingface.co/
Например, Qwen3.6-35B-A3B: https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF
Там будет список квантов, их размер и кнопка Use this model где будет список, среди которого будет llama.cpp, откуда можно взять команду для скачивания и запуска. Эта команда скачает модель по пути C:\Users\user\.cache\huggingface\hub\
.\llama-server.exe -hf unsloth/Qwen3.6-35B-A3B-GGUF:UD-Q4_K_M
Либо можно запускать любые уже скачанные gguf файлы указывая -m путь
.\llama-server.exe -m "T:\models\Qwen3.6-28B-REAP20-A3B-Q4_K_M.gguf"
Либо указать путь ко всей папке, указав, что за раз нужна 1 модель (по умолчанию 4):
.\llama-server.exe --models-dir "T:\models\" --models-max 1
Сервер запускается в режиме OpenAI-compatible API, этот сервер теперь можно использовать в любом приложение где можно указать Custom URL для OpenAI.
Также запускается Web-клиент по адресу http://127.0.0.1:8080
В настройках можно выбрать тему, отображение статистики и настроить сэмплинг.

Нажатием на глазик рядом с кодом открывается предпросмотр html.

Через параметр -c N задается размер контекста, через $env:CUDA_VISIBLE_DEVICES = "1" можно выбрать какая GPU будет работать с этим сервером, если GPU несколько.
OpenAI-compatible API доступен по стандартному адресу http://127.0.0.1:8080/v1
Помимо OpenAI API, поднимается Anthropic Messages API, так что этот сервер можно использовать с Claude Code. Другие агенты вроде OpenCode, Qwen Code, Pi Coding Agent работают по OpenAI-compatible API.
Почему llama.cpp быстрее чем ollama
Чтобы не повторяться, у меня уже есть статья где есть необходимые подробности как и за счет чего получается ускорение: Запускаем GPT-OSS-120B на 6 Гб GPU и ускоряем до 30 t/s. Вам нужна RAM, а не VRAM. Параметр -cmoe для ускорения MoE LLM

Таким же образом я запускал DeepSeek R1: Запускаем настоящую DeepSeek R1 671B на игровом ПК и смотрим вменяемая ли она на огромном контексте (160к)
Если коротко, то MoE модели разрежены, поэтому GPU будет простаивать, если эти "дыры" попали на GPU, нужно сделать так, чтобы GPU всегда была загружена на 100%, для этого надо перераспределить выгрузку тензоров.
Стандартный способ выгрузить слои, это способ ngl. Просто указывается количество слоев, которые попадут на GPU.
Способ который выгружает не слои, а точечно тензоры, перераспределяя то, что попадет на GPU можно назвать cmoe или ncmoe, от cpu-moe.
Если воспользоваться способом ngl, и выгрузить 10 слоев на GPU, то мы забьем всю память GPU, но её эффективность будет 30%, если воспользуемся способом ncmoe, то выгрузим 100% тензоров Внимания и 5 слоев на GPU. Тоже забьем всю память, но эффективность GPU будет 100%.
Есть 3 вариант, когда мы загружаем лишь 3гб VRAM, оставляя много памяти под контекст или другие задачи, и всё равно получаем получаем ускорение в 2 раза, так как эффективность GPU будет 75%, что меньше 100%, но больше 30%. Это режим cmoe.
Итого есть 3 режима работы:
-ngl или --n-gpu-layers
-cmoe или --cpu-moe
-ncmoe или --n-cpu-moe
На сколько ollama медленнее llama.cpp
Проведем немного тестов и сравним скорость. Запускать будем на 4060 16 Гб модель Qwen3.6-35B-A3B, размер кванта Q4_K_M ~22 Гб, он не влезает целиком на GPU.
Для начала замерим выставив настройки на 4k контекста. В ollama можно запустить модель с ключом --verbose, чтобы увидеть статистику генерации.
ollama run qwen3.6 --verbose
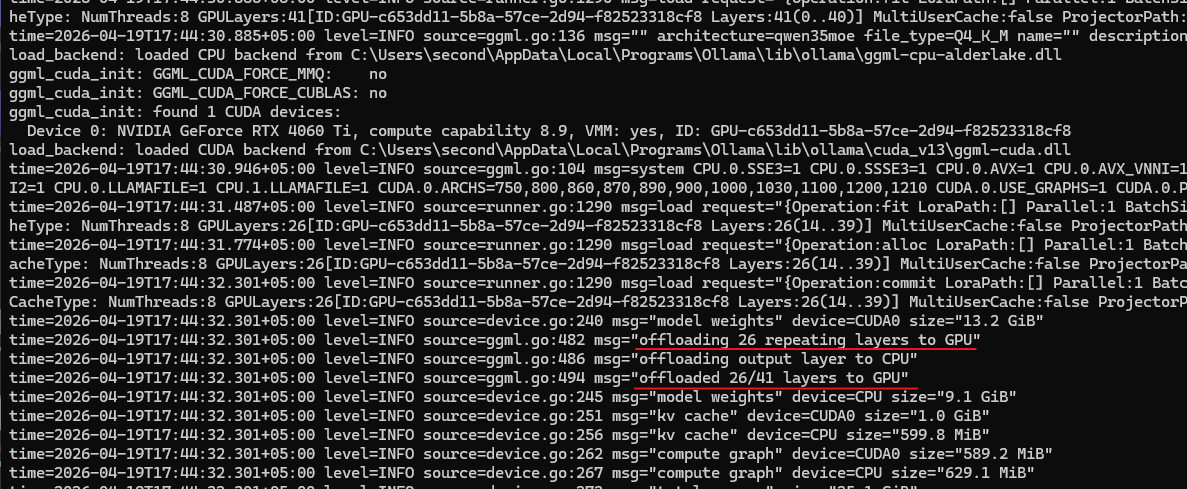
Первое, что можно заметить, что ollama работает в режиме ngl, она пытается выгружать целые слои на GPU, и так как на GPU не хватает памяти, то выгружены будут только 26 слоев из 41 и все 16 Гб полностью забиты.
Теперь посмотрим на скорость:

Несмотря на то, что вся видеопамять занята, и кажется что GPU должна работать на полную, мы получаем всего 16 t/s. Это, в целом не плохая скорость, но ожидания были выше.
Теперь очередь llama.cpp, запустим UD-Q4_K_XL, контекст тоже 4k контекст. llama.cpp тоже занял все 16 Гб, но во время загрузки можно заметить, что он переключился на режим ncmoe, так как распознал, что перед нами MoE модель.
./llama-server -m Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -c 4096

Теперь посмотрим на скорость генерации:

И сходу 45 t/s. Это в 2.8 раза быстрее чем на ollama. Учитывая, что все 16 Гб заняты, а 4060 довольно медленная карта, это очень хороший результат, который не требует ни апгрейда, ни каких-то сложных шаманств.
4к контекста это мало, увеличим до 32000. В llama.cpp это делается через параметр -с 32000

Чем больше контекст, тем ниже скорость, это вполне нормальное поведение. В ollama на таком же размере скорость упала до 11 t/s, то есть скорость в llama.cpp выше уже в 3.2 раза.
Почему ollama в 3 раза медленнее
Ollama под капотом использует движок GGML от llama.cpp, поэтому у них есть возможность активировать режим ncmoe, но они этого не делают. Они используют режим ngl для любых моделей, будь то Dense, где ngl подходит лучше всего, и будь то MoE. Когда они добавят ncmoe, скорость увеличится и на ollama.
Режим -fit в llama.cpp
Для упрощения работы с режимами ngl, cmoe и ncmoe в llama.cpp добавили режим fit.
fit включен по умолчанию и сам определяет оптимальные параметры загрузки моделей. Для MoE он включает ncmoe, для Dense ngl, явным указанием -cmoe можно указать, что нужен cmoe, вместо ncmoe.
Этот режим сам рассчитает сколько памяти нужно под контекст и сколько под слои или тензоры, и оставит свободным 1 Гб VRAM. Параметром --fit-target 1024 можно указать, сколько видеопамяти нужно оставлять свободной после автоматического рассчета.
Например, сочетание -fit, которое не нужно указывать, и -cmoe вместе с -c 262144 выставленным на максимальный контекст в 256k, займет всего 8.5 Гб.
./llama-server -m Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -c 262144 -cmoe

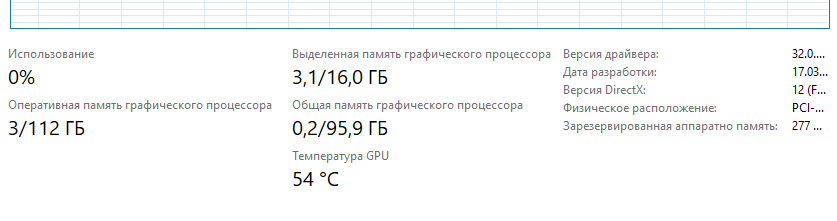
Для 30к контекста нужно 3 Гб:
Почему UD-Q3_K_XL работает медленнее чем UD-Q4_K_XL
Чтобы вместить побольше данных на GPU, можно взять квант меньшего размера, и тут может случиться такое, что такой квант наоборот, будет работать медленнее, чем более крупный.
На днях возникла такая ситуация. Модель была загружена в режиме cmoe, значит все MoE параметры считались на процессоре i5-11600K, остальное работало на 3070 8 Гб, контекст 128к, квантование KV-кэша ctk и ctv Q8_0.
Скорость PP (prompt processing) не так важна, её можно разогнать через увеличение -ub -b параметров, а вот TG (token generation) на кванте Q3 оказался медленнее чем на Q4:
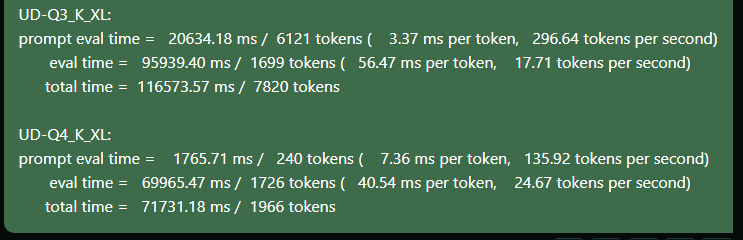
Это не очень очевидно, почему такое может происходить. Чтобы разобраться, нужно посмотреть на структуру квантов и найти в чем отличие:
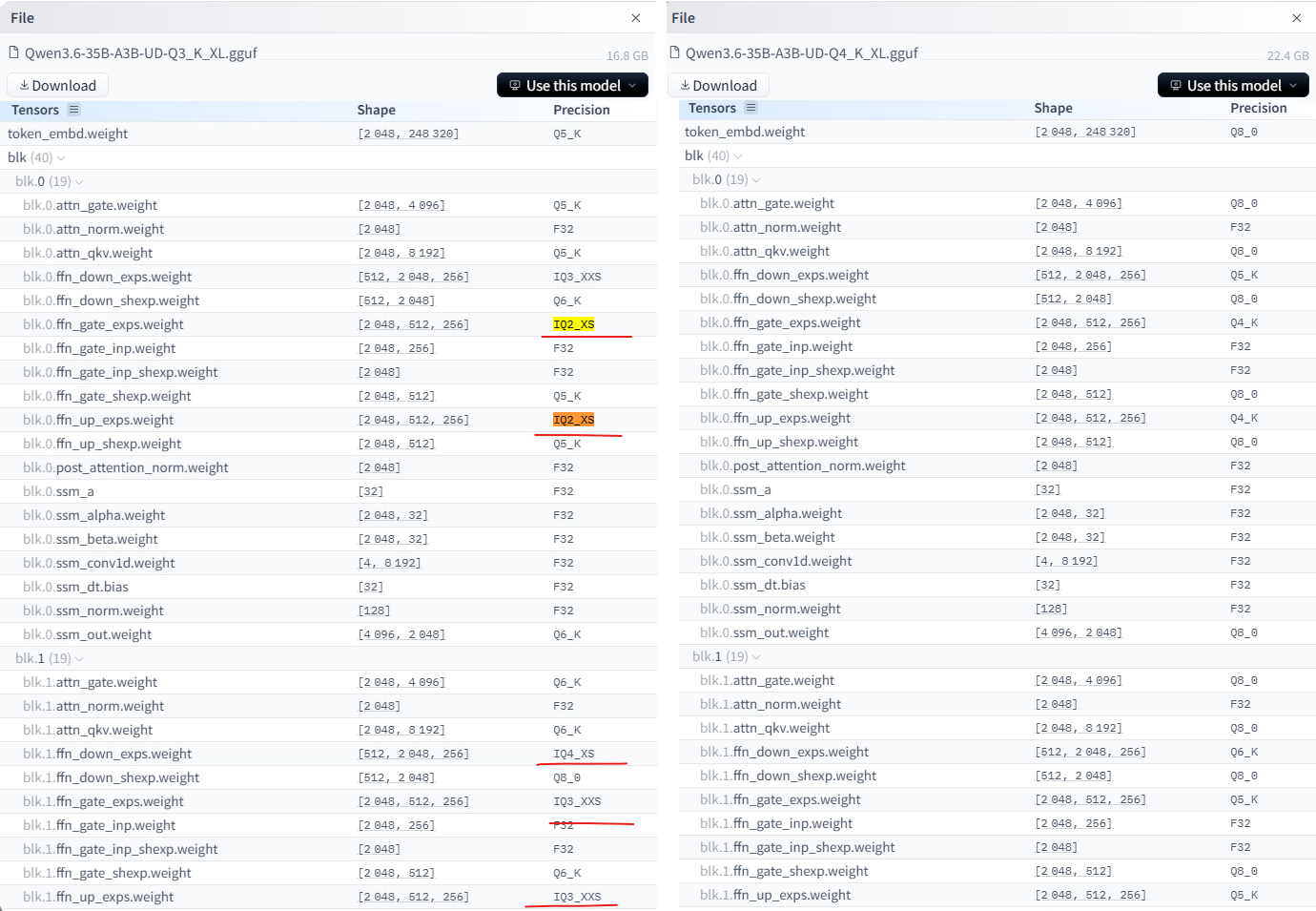
Видим, что квант UD-Q3_K_XL содержит i-кванты, в то время как UD-Q4_K_XL состоит только из статичных K-квантов.
Теперь всё ясно, i-кванты примерно в 2 раза сложнее для вычислений, и так как вся работа по MoE-экспертам осталась на 6 ядерный CPU, то у него не хватило мощности справится с такой нагрузкой, отсюда и произошла просадка tg.
Попробуем повторить и провести эксперимент. Под рукой есть i7-14700, этот процессор мощнее, чем i5-11600K, поэтому искусственно зададим всего 2 ядра, вместо 6, с помощью -t 2 -cmoe
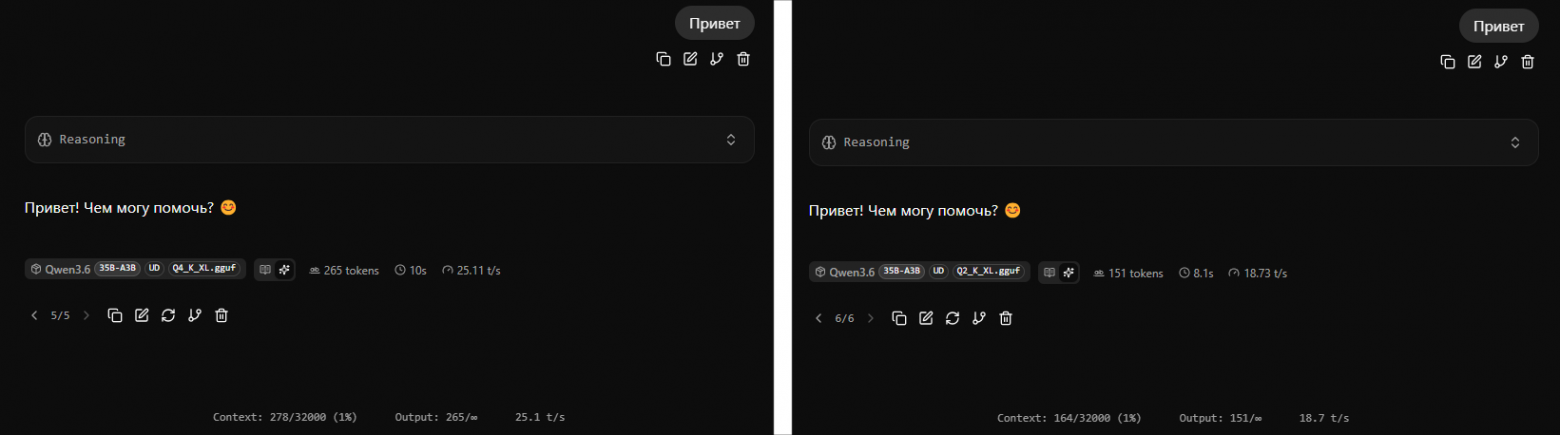
Скорость UD-Q4_K_XL оказалась и правда выше, чем UD-Q2_K_XL. 25 t/s против 18 t/s.
На что способно квантование UD-Q2_K_XL
Принято считать, что и Q2 и особенно Q2 квантование не стоит внимания, слишком сильная деградация кванта и очень низкое общее качество. Это справедливо для классический стандартных квантов, но динамическое квантование или SOTA кванты позволяют использовать UD-Q2 или IQ2_KS.
Модель Qwen3.6-35B-A3B в кванте Q8 весит 36.9 Гб. Q4_K_M - 21.2 Гб, UD-Q3_K_XL - 16.8 Гб, UD-Q2_K_XL - 12.3 Гб.
4060 Ti 16 Гб медленная, скорость памяти всего 288 Гб/с, а скорость LLM напрямую зависит от скорости памяти. Квант UD-Q2_K_XL влезает в 4060 16 Гб целиком, что даст большой буст к скорости, и компенсирует общую медленность карты. Скорость tg составляет 68 t/s.
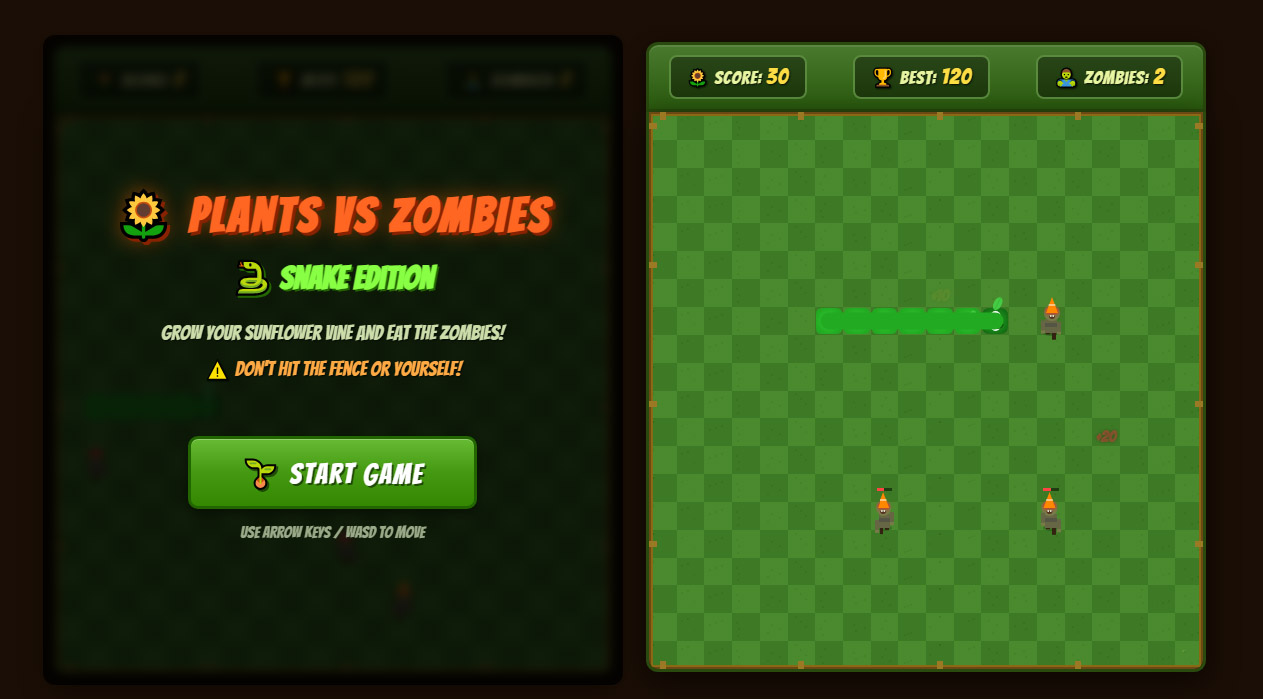
Сначала простое задание, змейка в стиле Plants Vs Zombie. Модель взяла шрифт в стиле игры, и это единственный внешний ресурс, остальное создала оформление из смеси эмодзи.
Теперь посложнее. Создать реплику Win 11. Результат выглядит похоже, весь интерактив присутствует, окна открываются, двигаются, закрываются, пуск с анимацией и так далее:

Усложняем сильнее. Рабочий клон Minecraft. Запрещено использовать внешние ресурсы, только процедурная генерация. Тут пришлось перейти из браузере в агента, так как требует модульная структура проекта, много файлов, много мелких правок разных файлов.
На создание первичной структуры, модулей и первого прототипа у модели через агента ушло где-то 40 минут. В качестве агента qwen code подключенный к локальной llama.cpp.
Вначале было много багов:

У модели есть Vision, поэтому можно сделать скриншот и показать то, как она изобразила снег не соответствует действительности:

На доработку, ремонт багов, создания различного функционала ушло ещё где-то 2 часа. В итоге модель Qwen3.6-35B-A3B в кванте UD-Q2_K_XL починила все баги и довела прототип до рабочего состояния.
Блоки разрушаются и ставятся, существует несколько биомов, вода растекается, графика и звуки процедурно генерируются. Под травой земля, дальше камни, можно копать вглубь.

Пещер и алмазов пока нет. Добавить их будет хорошим заданием для REAP версии.
REAP - вырезать лишних экспертов из модели и сбросить вес
Идея в том, что в MoE моделях много экспертов, экспертам стараются давать максимум специализации, поэтому часть из них нужна только для каких-то конкретных вещей, например, умению составлять таблицу високосных годов. В других сценариях, например, в программировании, эти эксперты не задействуются, но ресурсы на них уже были потрачены.
REAP (Router-weighted Expert Activation Pruning) вырезает наименее активных экспертов, которые не нужны в конкретных сценариях. Сценарий определяется подготовленным датасетом, поэтому можно создать свою версию REAP заточенную под ваш конкретный сценарий вырезая 25%, 50%, 75% лишних экспертов.
В основном упор REAP делают на программирование, и готовые версии можно найти добавляя REAP к имени: https://huggingface.co/models?search=reap
Например, Qwen3.6 имеет размер 35B-A3B, REAP 20 версия 28B-A3B, на 20% легче.
REAP довольно новая техника, и не так распространена и пока для неё редко делают динамические кванты, поэтому для тестов Q4_K_M. В REAP 20 вырезали не так много, запросы и ответы работают на русском, хотя уже чувствуется, что не так хорошо, как оригинал:
REAP разучилась понимать, кто такой Чапай:
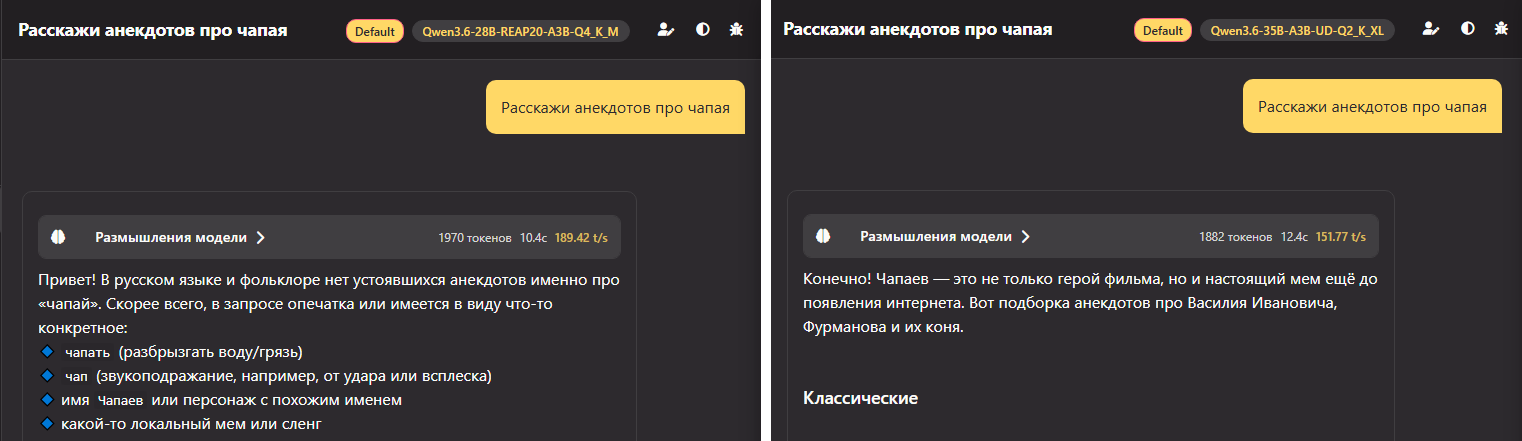
Несмотря на то, что русский язык работает, возможно, будет лучше работать с REAP на английском.

Результат:

Проверить агентный режим, продолжим работу над Minecraft в браузере, нужно добавить пещеры и алмазы.
Инструменты REAP версия не разучилась вызывать. Задание было, алмазы повыше, чтобы глубоко и долго не копать, и сгенерировать какое-нибудь строение.

В целом REAP работает, на сколько хорошо или плохо, нужно проводить больше тестов. Такие версии актуальны не только для небольших моделей, чтобы вместить их в GPU, но и для преобразования больших, например, GLM-5.1 744B-A40B в GLM-5.1 444B-A14B.
Маленькая модель как черновик, чтобы ускорить большую
Спекулятивное декодирование - способ ускорить большую модель за счет использования маленькой модели черновика. Хорошо работает для структурированных данных, вроде программирования или перевода с размышлениями.
Работает если разница между активными параметрами большой модели, особенно если это Dense модель, и размером черновой модели будет больше чем в 3 раза, чтобы накладные расходы на работу маленькой модели не съедали весь эффект.
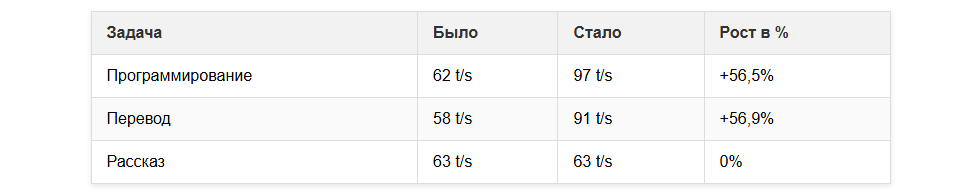
Gemma4 31B UD-Q4_K_XL без черновика, скорость 62 t/s на задачи программирования:
.\llama-server -m "gemma-4-31B-it-UD-Q4_K_XL.gguf" -ngl 99

Подключим черновик gemma-4-E2B-it-UD-Q4_K_XL, теперь скорость 97 t/s:
.\llama-server -m "gemma-4-31B-it-UD-Q4_K_XL.gguf" -md "gemma-4-E2B-it-UD-Q4_K_XL.gguf" -ngl 99 -ngld 99 --parallel 1
--parallel 1 нужно указать 1, так как в авто режиме будет выделено в 4 раза больше памяти.

Процент принятия черновой модели ~55%. Для кода ускорение в 1.5 раза.
Для задачи перевода ускорение тоже работает, а для рассказа эффект отсутствует. Можно попробовать настроить draft-max и draft-min, это даст эффект, но особого смысла в этом нет.
Ускорение обработки контекста
Агенты постоянно подгружают в контекст содержимое многих исходных файлов, это не генерация новых токенов TG, а обработка контекст PP.
Если модель не влезает целиком на GPU и работает в режиме cmoe, то скорость обработки контекста PP будет не достаточно быстрой, её можно разогнать через указание размеров пакетов -ub -b, например -ub 4096 -b 4096
Сравним 2 команды бенчмарка:
.\llama-bench -m "Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf" -p 4096 -ncmoe 24
.\llama-bench -m "Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf" -ub 4096 -b 4096 -p 4096 -ncmoe 24

ik_llama
ik_llama не универсальный проект замены llama.cpp, например, тут кванты mxfp4 будут медленнее чем на llama.cpp, так как их поддержка не реализована в полной мере. Тоже самое касается vulkan и rocm, здесь они если и запустятся, то будет сильная просадка скорости.
Ubergram делает кванты специально для ik_llama используя их продвинутые IQK кванты, и тоже применяет динамическое квантование, получая качественный результат.
Для Qwen3.6 пока нет квантов, поэтому протестируем модель Qwen3.5-35B-A3B, кванты:
Unsloth UD-Q4_K_XL
Ubergarm IQ4_KS
LM Studio Q4_K_M

IQ4_KS и UD-Q4_K_XL примерно равны по качество, но UD-Q4_K_XL весит больше на 1 Гб.
IQ4_KS и Q4_K_M весят одинаково, но Q4_K_M значительно хуже по качеству.
Q4_K_M имеет KLD в 3 раза хуже.
Квант IQ4_KS и меньше весит и имеет лучшее качество, и для больших моделей это становиться ещё более ощутимым, где выигрыш уже составляет 20-30+ Гб, что может быть очень кстати.
ik_llama: https://github.com/ikawrakow/ik_llama.cpp
Windows сборки ik_llama: https://github.com/Thireus/ik_llama.cpp
gguf кванты для ik_llama: https://huggingface.co/ubergarm
ik_llama не универсальная замена, какие минусы
Над ik_llama работает только один человек, поэтому со временем расхождение между llama.cpp и ik_llama увеличиваются, оптимизации из одного проекта не перетекают в другой, поэтому это не универсальная замена, нужно понимать плюсы и минусы.
В ik_llama основной упор делается на новые кванты и скорость PP и оптимизация расхода памяти на контекст, на длинном контексте скорость PP падает в раз меньше чем на llama.cpp, есть поддержка новых размеров квантования KV-кэша Q6, хорошая поддержка AVX512 и так далее.
При этом скорость TG может быть даже ниже, чем в llama.cpp, особенно для кванта mxfp4, где скорость будет в 2-3 раза ниже так как нет полной поддержки этого кванта. И родные для ik_llama кванты по скорости tg могут быть медленнее, чем аналогичные по размеру в llama.cpp. Это может зависит от версии ОС, от конкретного процессора, и так далее. Также тут нет поддержки Vulkan и AMD видеокарт, они запустятся, но скорость на порядок будет ниже.
Я проводил сравнение на железе Intel i7-14700, DDR5-4800, Manjaro, Nvidia, но на вашем железе относительные цифры могут отличаться, так как в ik_llama делаются оптимизации под конкретное железо и процессоры, и на AMD всё может работать лучше. Не стоит сразу брать ik_llama не проверив скорость в llama.cpp.

Скорость PP в 4 раза выше при стандартных значениях -ub -b. На llama.cpp чтобы получить такую скорость нужно увеличить -ub -b, что приводит к расходу дополнительных 3 Гб VRAM.
Linux vs Windows замеры скорости. 4060 vs 5090
Для RTX 5000 серии для максимальной производительности надо ставить CUDA 12.8 и выше, лучше 13.1. В llama.cpp есть 2 версии, это cuda12.4 и cuda13.1 - вторая заработает только со свежими драйверами, те которые Windows по умолчанию устанавливает не подойдут, нужны с сайта Nvidia.
В linux нужно обновить cuda и драйвера, убедиться, что в toolkit и в драйверах нужная cuda.
> nvcc --versionCuda compilation tools, release 13.1, V13.1.115> nvidia-smiNVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1
Если нужна поддержка 4000 и 5000 серии, то добавить 2 архитектуры у компилятора:
cmake -B ./build -DGGML_CUDA=ON -DGGML_BLAS=OFF -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_IQK_FORCE_BF16=1 -DLLAMA_OPENSSL=ON -DCMAKE_CUDA_ARCHITECTURES="89;120"cmake --build build --config Release -j20
Сравним модели MoE Qwen3.6-35B-A3B и Dense Qwen3.6-27B. Linux - Manjaro.

Использовать встройку чтобы высвободить VRAM
Windows под свою работу, браузеры под свою, клиенты под свою - все они тратят видеопамять, в общем сложности отбирая 2-3 Гб у нейросетей.
Благодаря системе общей памяти в Windows если немного выйти за пределы VRAM, то скорость упадет в разы или порядки, и очень сложно понять, что произошло: вчера всё работало быстро, а сегодня ничего не работает.
Если у вас есть встройка, переключите мониторы на неё. Для игр это не будет проблемой, так как современные Windows и Linux автоматически активируют GPU для тяжелых программ.
Без переключения тоже можно, можно вручную перекинуть конкретные приложения на встройку или наоборот, со встройки на GPU. В Windows надо найти в настройках дисплея "Настройки графики". Там будет небольшое меню, которое позволит указать путь до exe файла и явно указать где ему работать.
В диспетчере задач на вкладке "Подробности" можно посмотреть какие приложения используют VRAM и там же открыть расположение exe файла.

Если несколько видеокарт, то в Windows 11 есть возможность выбирать какая именно GPU будет по умолчанию, даже если мониторы подключены к другой:

Список локальных LLM начала 2026
Зачастую подборки списков вроде "Лучшие локальные модели LLM 2026" представляю собой не список новинок, а список очень старых моделей, которые были актуальны несколько лет назад.
И чаще всего в таких списках Mistral 7B, самая древняя из возможных моделей, древнее только GPT-2 и Llama 2. Даже в 2023, когда и вышла Mistral 7B, она была скорее качественной основой для файнтюнов, а сама по себе была слаба. Новые модели выходят каждые пол года или чаще, новые модели лучше удерживают контекст, лучше следуют промпту, в целом лучше справляются с заданиями. Поэтому правило выбора LLM - это посмотреть на дату выхода, вначале проверить год, а потом месяц.
Например модель qwen3 вышла вначале 2025 года, а летом они представили qwen3 2507, и 2507 была значительно лучше, чем просто qwen3. Сейчас тоже самое произошло с Qwen3.5, которая вышла 2 месяца назад, а неделю назад вышла Qwen3.6.
Новые модели, в отличии от старых, часто мультимодальные, умеют работать с изображениями. Некоторые модели умеют что-то дополнительное, например, Qwen умеет работать с видео, а Gemma4 E4B с аудио. Поддержку аудио недавно добавили в llama.cpp:

Вот небольшой список новинок начала 2026 или "лучшие локальные LLM 2026", потому что пока что-то новее не вышло:
Для дома:
Для дома+:
В рамках одной модели может быть несколько размеров:
Gemma4 представлена в 4 вариантах: легкие E4B и E2B, MoE модель 26B-A4B, и Dense 31B
Qwen3.5 в 8 вариантах: 0.8B, 2B, 4B, 9B, 27B, 35B-A3B, 122B-A10B, 397B-A17B
Для слабых ПК или телефонов подходят новинки размером 4B (Qwen3.5 4B) или оптимизированные E4B (Gemma4 E4B и E2B). Эти новинки для своего размера не плохи.
Монолитная Gemma4 31B походит и для программирования и для творческих задач, а вот MoE Gemma4 26B-A4B, которая в программировании в разы хуже, уже не на столько универсальна, и тут лучше подойдет свежая Qwen3.6 35B-A3B, а на днях вышла Qwen3.6 27B.

Заключение
Ollama медленнее llama.cpp в 3 раз на 4060 для MoE модели.
Динамический квант UD-Q4_K_XL лучше чем стандартный Q4_K_M, а весит столько же.
Q4_K_M по уровню соответствует UD-Q3_K_XL.
Новый квант IQ4_KS ещё лучше, но работает только в ik_llama.
Квант UD-Q2_K_XL написал и отладил клон Minecraft с процедурно-генерируемой графикой.
Технология REAP работает, но не идеально, позволяет сэкономит >20% размера.
Спекулятивное декодирование ускоряет Dense модели в 1.5 раза в коде и переводе.
Переключение на встройку позволит высвободить 2-3 Гб VRAM.
ik_llama имеет минусы, но может сэкономить VRAM и ускорить PP
Сравнение скорости Linux vs Windows, 4060 vs 5090
Если у вас есть другие способы получить больше скорости или больше качества, то делитесь ими в комментариях, многим будет полезно и интересно.