Having written a lot of model release blog posts, there’s something much harder about reviewing open models when they drop relative to closed models, especially in 2026. In recent years, there were so few open models, so when Llama 3 was released most people were still doing research on Llama 2 and super happy to get an update. When Qwen 3 was released, the Llama 4 fiasco had just gone down, and a whole research community was emerging to study RL on Qwen 2.5 — it was a no brainer to upgrade.
Today, when an open model releases, it’s competing with Qwen 3.5, Kimi K2.5, GLM 5, MiniMax M2.5, GPT-OSS, Arcee Large, Nemotron 3, Olmo 3, and others. The space is populated, but still feels full of hidden opportunity. The potential of open models feels like a dark matter, a potential we know is huge, but few clear recipes and examples for how to unlock it are out there. Agentic AI, OpenClaw, and everything brewing in that space is going to spur mass experimentation in open models to complement the likes of Claude and Codex, not replace them.
Especially with open models, the benchmarks at release are an extremely incomplete story. In some ways this is exciting, as new open models have a much higher variance and ability to surprise, but it also points at some structural reasons that make building businesses and great AI experiences around open models harder than the closed alternatives. When a new Claude Opus or GPT drops, spending a few hours with them in my agentic workflows is genuinely a good vibe test. For open models, putting them through this test is a category error.
Something else to be said about open models in the era of agents is that they get out of the debate of integration, harnesses, and tools and let us see close to the ground on what exactly is the ability of just a model. Of course, we can’t test some things like search abilities without some tool, but being able to measure exactly the pace of progress of the model alone is a welcome simplification to a systematically opaque AI space.
The list of factors I’d use to assess a new open-weight model I’m considering investing in includes:
Model performance (and size) — how this model performs on benchmarks I care about and how it compares to other models of a similar size.
Country of origin — some businesses care deeply about provenance, and if a model was built in China or not.
Model license — if a model needs legal approval for use, uptake will be slower at mid-sized and large companies.
Tooling at release — many models release with half-broken, or at least substantially slower, implementations in popular software like vLLM, Transformers, SGLANG, etc due to pushing the envelope of architectures or tools.
Model fine-tunability — how easy or hard it is to modify the given model to your use-case when you actually try and use it.
The core problem is that some of these are immediately available at release, e.g. general performance, license, origin, etc. but others such as tooling take day(s) to week(s) to stabilize, and others are open research questions — with no group systematically monitoring fine-tunability.
In the early era of open models, the days of Llama 2 or 3 and Qwen pre v3.5, the architectures were fairly simple and the models tended to work out of the box. Some of this was due to the extremely hard work of the Llama, Qwen, Mistral, etc. developer teams. Some is due to the new models being genuinely harder to work with. When it comes to something like Qwen 3.5 or Nemotron 3, with hybrid models (either gated delta net or mamba layers), the tooling is very rough at release. Things you would expect to “just work” often don’t.
I’ve been following this area closely since we released Olmo Hybrid with a similar architecture, and Qwen 3.5 is just starting to work well in the various open-source tools that need to all play nice together for RL research. That’s 1.5 months after the release date! This is just to start really investing more into understanding the behavior of the models. Of course, others started working on these models sooner by investing more engineering resources or relying on partially closed software. The fully open and distributed ecosystem takes a long time to get going on some new models.
All of this is lead-in for the most important question for open models — how easy is it to adapt to specific use-cases? This is a different problem for different model sizes. Large MoE open-weight models may be used by entities like Cursor who need complex capabilities in their domain, e.g. Composer 2 trained on Kimi K2.5. Other applications can be built on much smaller models, such as Chroma’s Context-1 model for agentic search, built on GPT-OSS 20B.
The question of “which models are fine-tunable” is largely background knowledge known by engineers across the industry. There should be a thriving research area here to support the open ecosystem model. The first step is to understand characteristics of different base and post-trained models to understand what they look like. The second step is to tune pretraining recipes for open models so they’re more flexible.
For The ATOM Project and other Interconnects endeavors, we’ve put in substantial effort to measuring adoption trends in the open ecosystem. Everything takes a long time to unfold after a model is first publicly available — and adaptability is why. What we know for sure now, when Qwen has been going from strength to strength with its releases, is that technical staff across the industry has gotten comfortable working with Qwen models. Countless research methods and datasets were made to work with Qwen. It’ll take patience for any other model family to get to this point — a patience I’m not sure many open model builders have.
This takes us to Gemma 4, Google’s latest open models. Gemma 3 was released more than a year ago, in March of 2025, and is a bit underrated. Gemma 4 comes in 4 sizes for now, with a bigger, MoE model of over 100B total parameters rumored but not released yet. The models we have today come in sizes of ~5B dense, 8B dense, 26B total 4B active MoE, and 31B dense.
I’m most excited that they’re finally adopting a standard Apache 2.0 open source license. This’ll massively boost adoption. The standard of better licenses for strong open-weight LLMs was set by mostly Chinese open model labs in the last 1-2 years, and now U.S. companies are following suit. I will personally be so happy if the horrible Llama licenses and Gemma terms of service were an ~18-month transient dynamic of the industry being nervous about releasing strong open models.
The Gemma 4 scores look very solid, the small models have incredible benchmark scores (especially in general domains like LMArena) and the 31B model rivals the recent Qwen 3.5 27B, which is the leading member of that class. The ~30B size range is an important one, as it’s accessible both to researchers and to enterprises looking to deploy the model in real use-cases. Where the 7B model scale is the default for tinkering and research, a 30B model is the default for seeing if an open model can unlock substantial value in your specific workflow — a good mix of intelligence, low price, tractability for downstream training, etc.
This takes us back to the above adoption criteria I mentioned for open models and the bigger question — do I think Gemma 4 will be an overwhelming success? Previous Gemma models have been plagued by tooling issues and poorer performance when being finetuned.
Gemma 4’s success is going to be entirely determined by ease of use, to a point where a 5-10% swing on benchmarks wouldn’t matter at all. It’s strong enough, small enough, with the right license, and from the U.S., so many companies are going to slot it in.
I’m cautiously optimistic that Gemma 4 is going to work better here. Winds are shifting for open models built in America. We saw GPT-OSS go through a bumpy launch to become an overwhelming success. There’s a collective energy around the likes of Reflection, Arcee, Nemotron, Gemma, Olmo, and peers that show substantial demand for building new stacks around open models. There’s capital to be spent on AI stacks across the economy by those who want more ownership of everything, including the model.
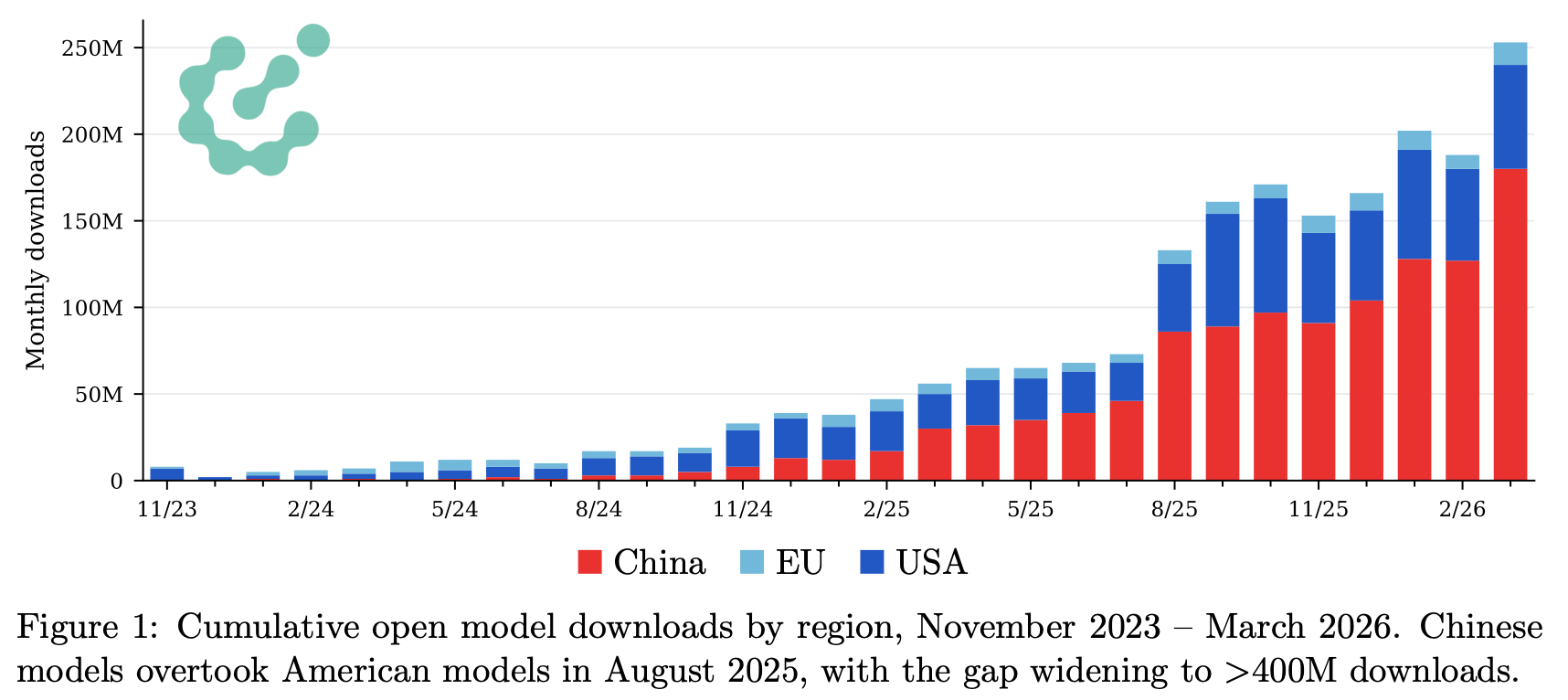
After launching The ATOM Project 240 days ago, the conversation is shifting into the next stage. Summer of 2025 was a crisis moment where the U.S. AI scene realized it can’t wait and figure out open models after building AGI. The two markets will capture different areas and proceed in parallel. Now that more companies in the U.S. are releasing strong models, we need to improve the ecosystem so that these models are easy to use, understand, and build value around. It’s the hard work to build another inflection point in these adoption plots I’ve been updating consistently, but that’s the work to be done. Join me in it.
More data coming soon! Here’s a sneak peek:
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。